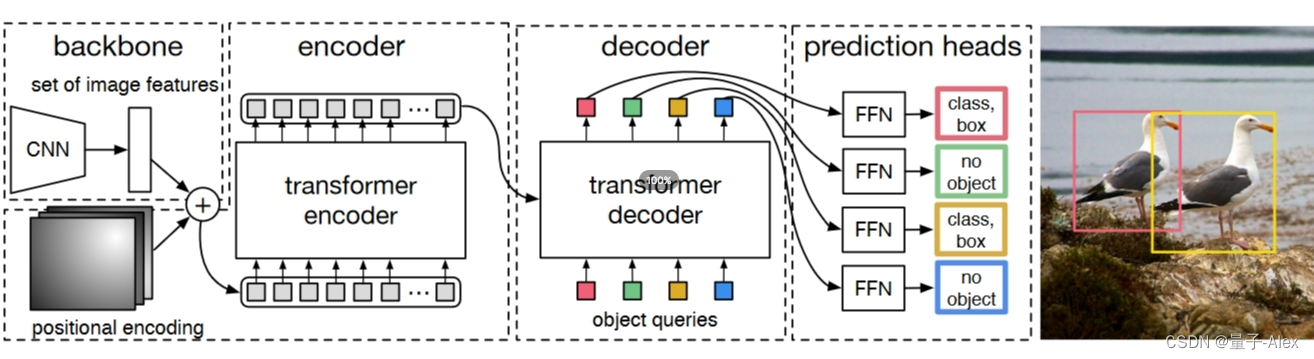
1 DETR算法概述

①端到端
②Transformer-model
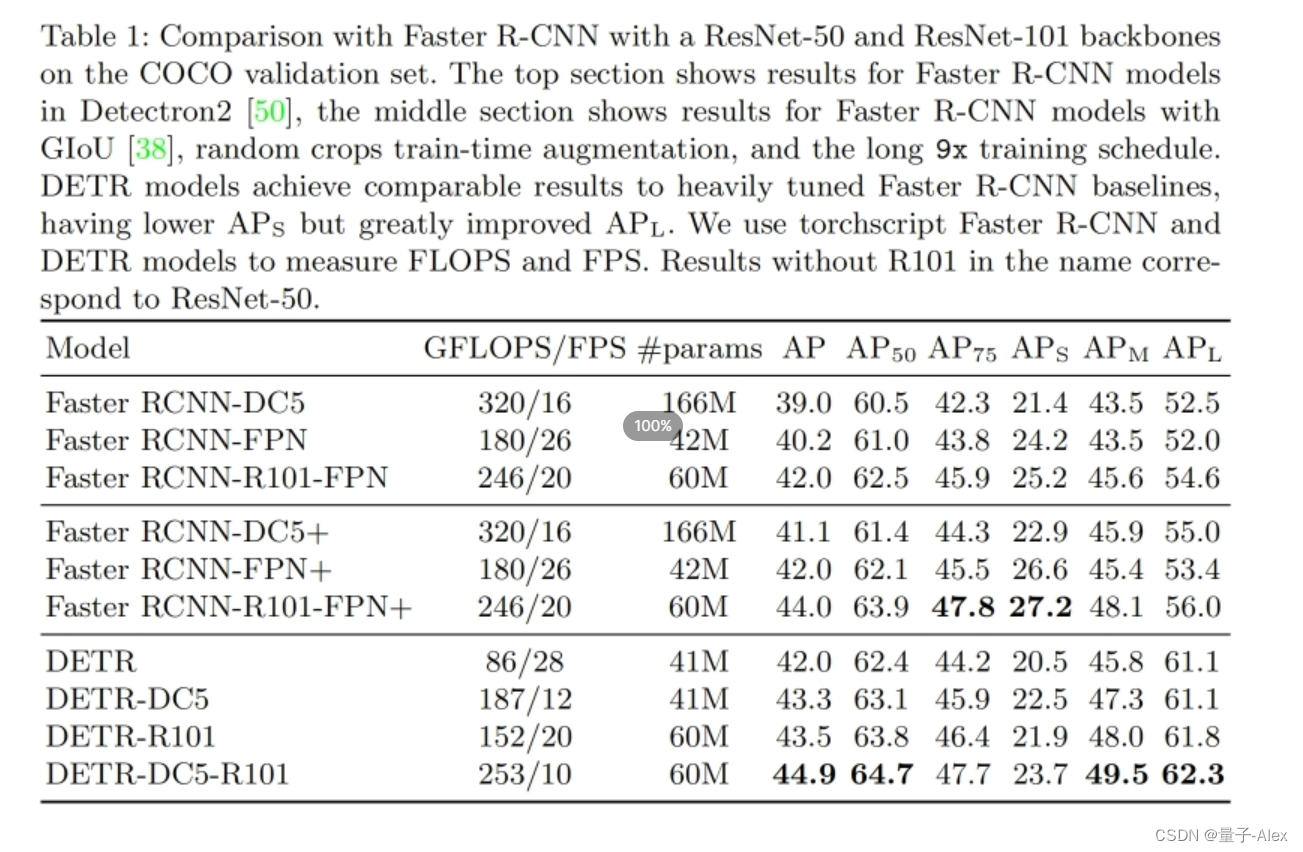
之前的方法都需要进行NMS操作去掉冗余的bounding box或者手工设计anchor, 这就需要了解先验知识,增加从超参数anchor的数量,
1.1 训练测试框架
一次从图像中预测n个object的类别
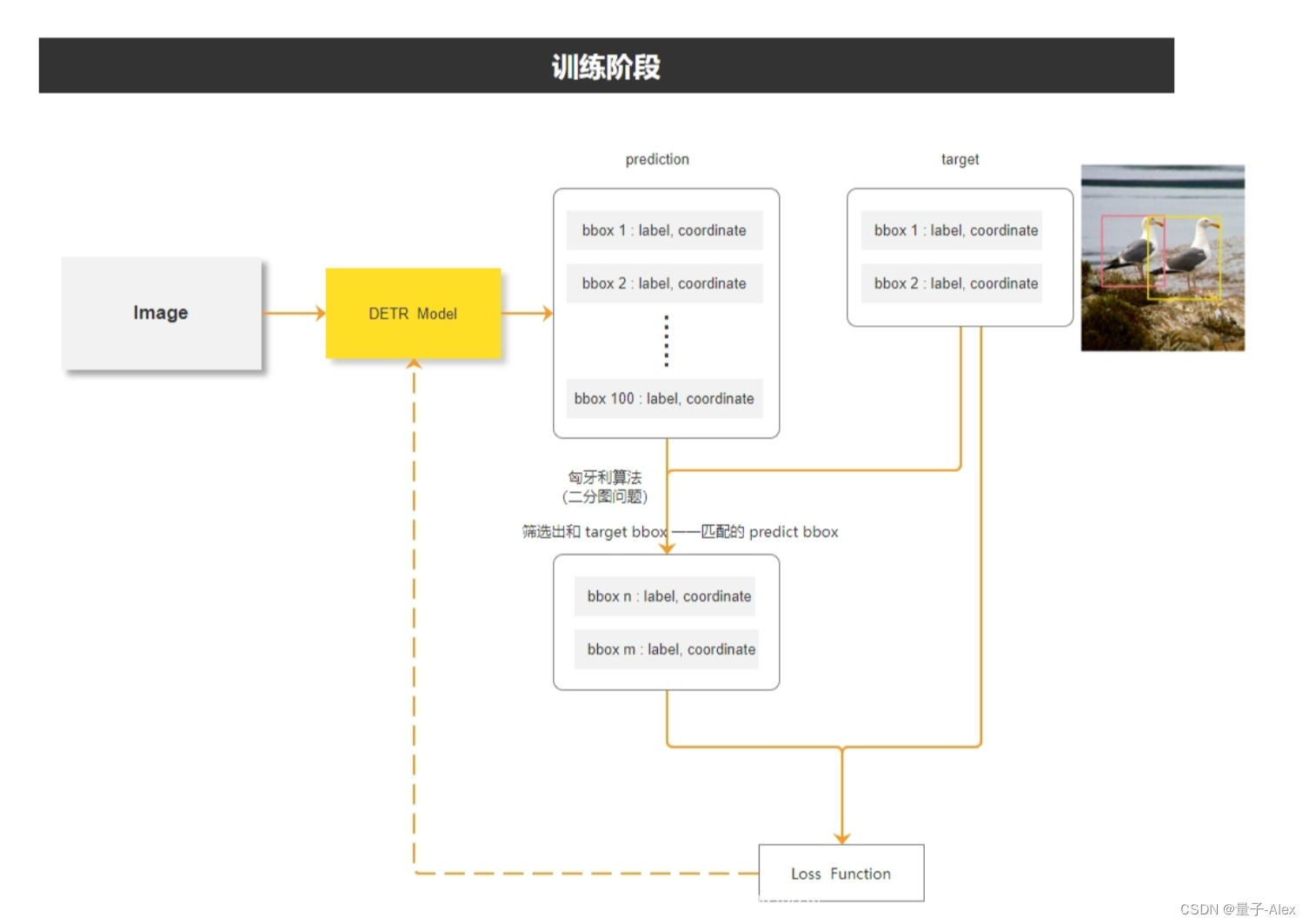
训练阶段我们将一张图像喂入DETR模型,会得到100个bounding box,并且得到这些预测框的类别信息和坐标信息
100个是超参数,因为大部分的图像中的object的数量不会超过100个
通过label我们知道图像中有2个object
然后使用匈牙利算法从预测出的100个候选框中筛选出2个预测框,与两个标注框一起计算损失,然后反向传播,优化模型参数
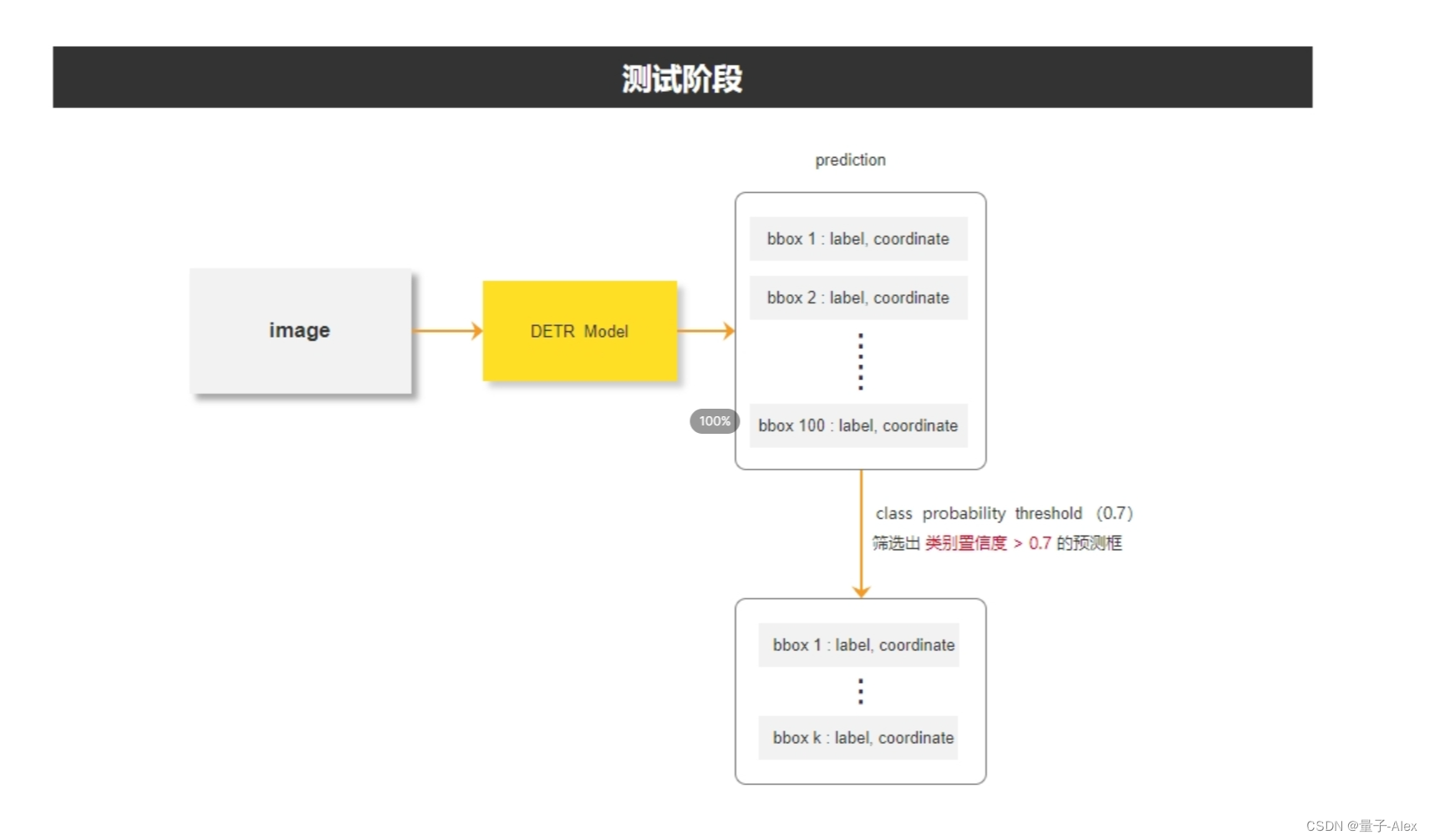
测试阶段:通过网络预测出100个预测框,把这100个预测框的置信度去和阈值进行比较,大于阈值的预测框保留。
这样在DETR里面是没有用到anchor也没有NMS操作的
算法的两个重点:一是基于集合的全局损失,通过二分类匹配得到与标注框匹配的独一无二的损失;二是引入encoder-decoder框架,
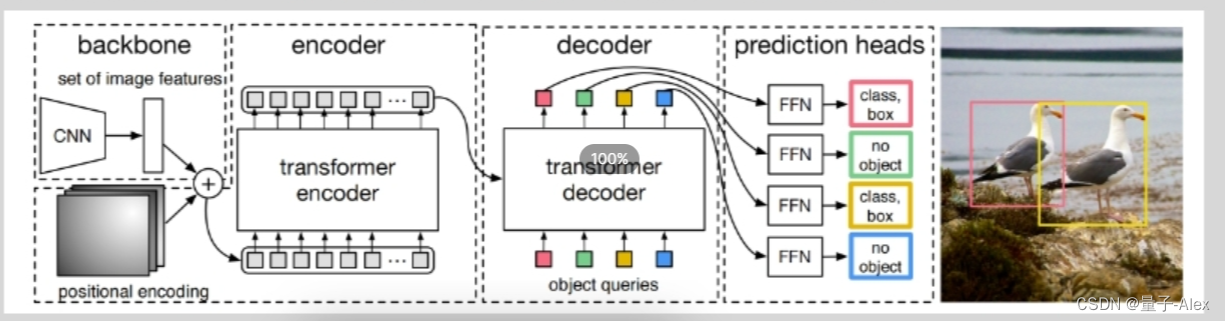
object queries是可学习的参数,通过他的尺寸指定输出的预测框的个数,在transforme中输出的token个数是等于输出的token个数,
没有固定的框架:只要框架能够支持这些,就能支持DETR
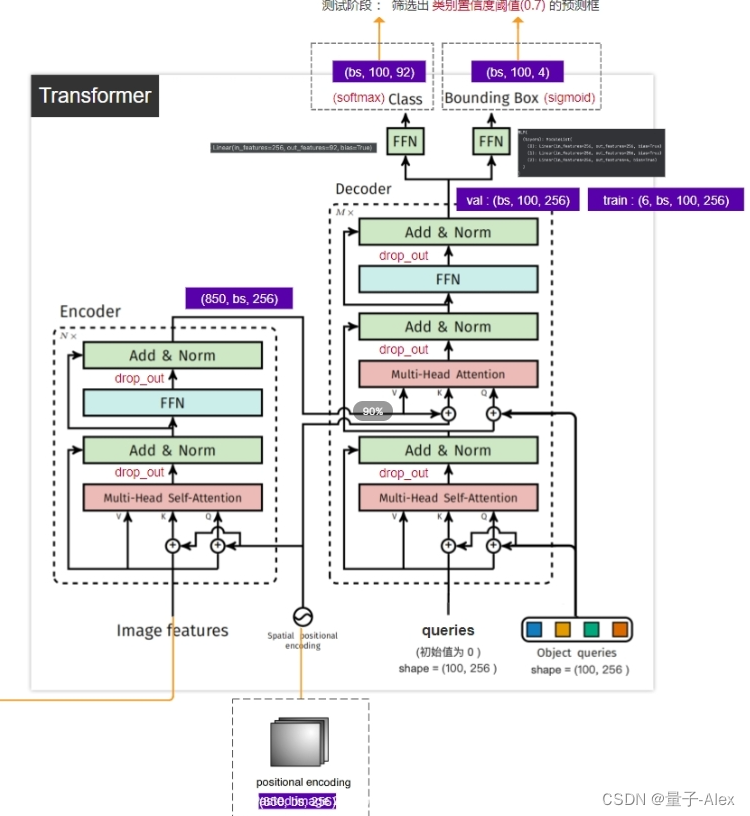
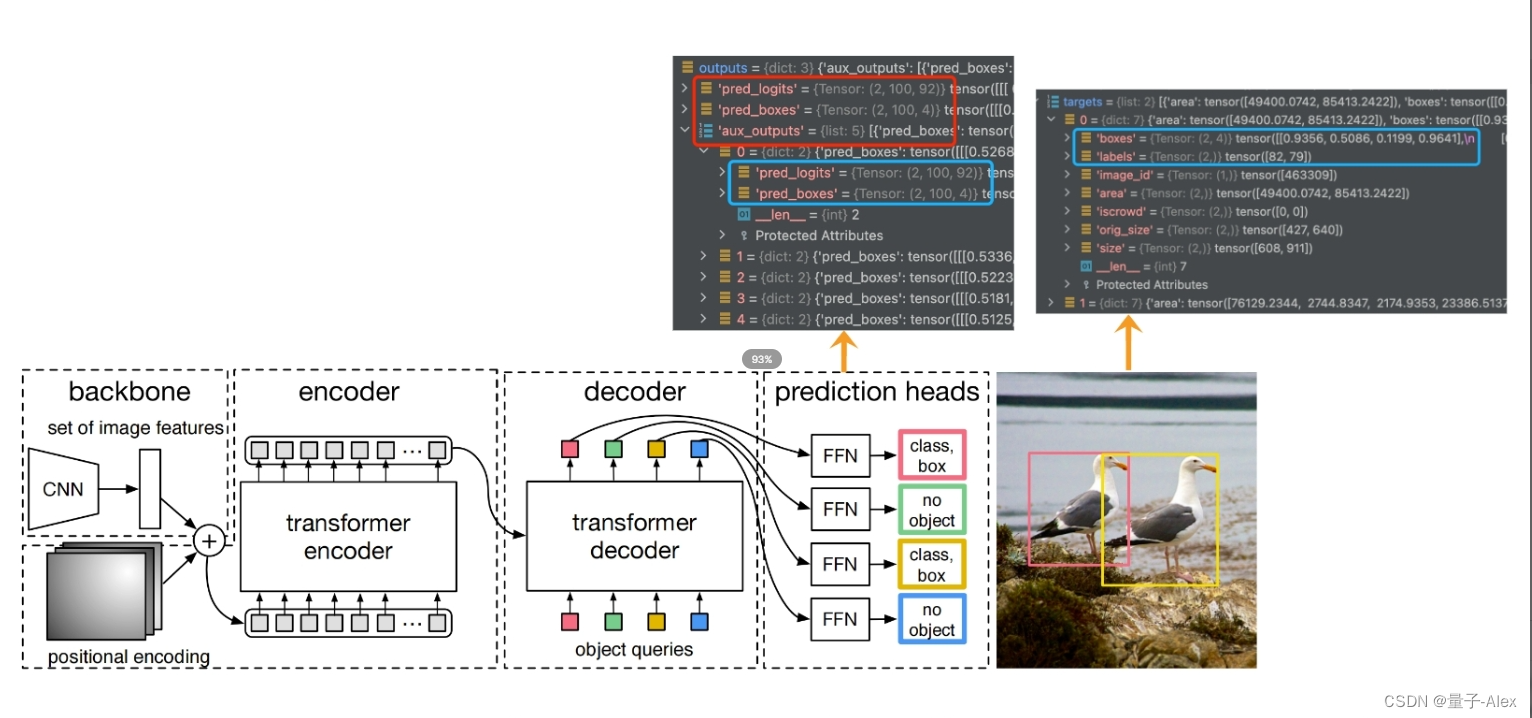
CNN+位置编码+encoder-decoder+MLP
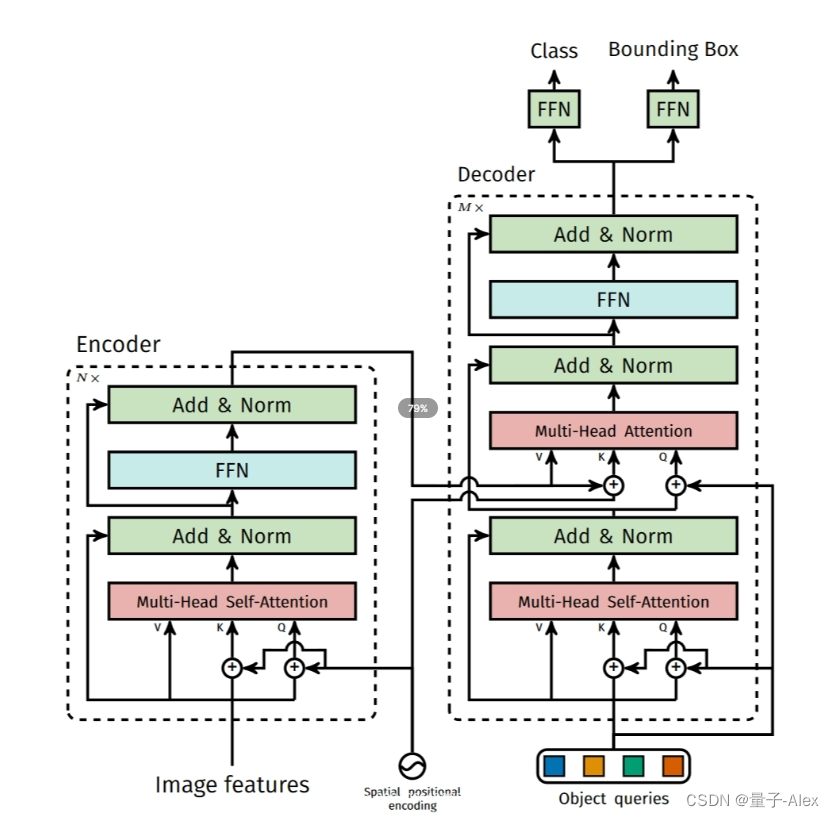
2 DETR模型结构讲解
inference
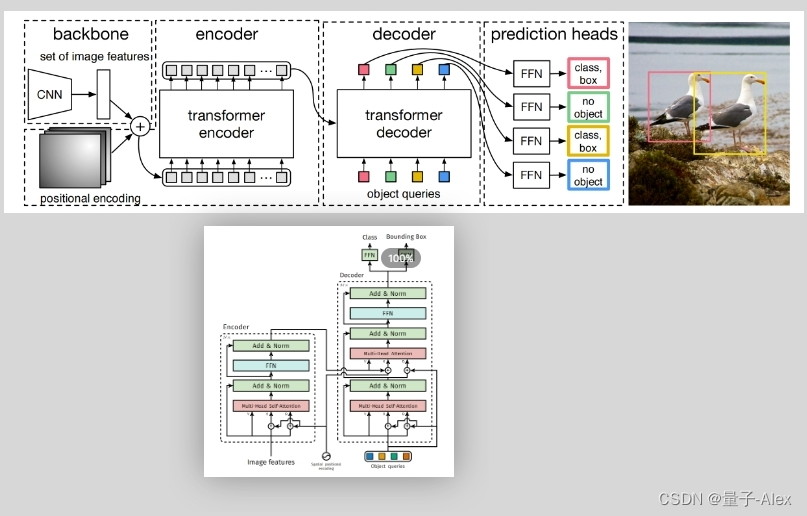
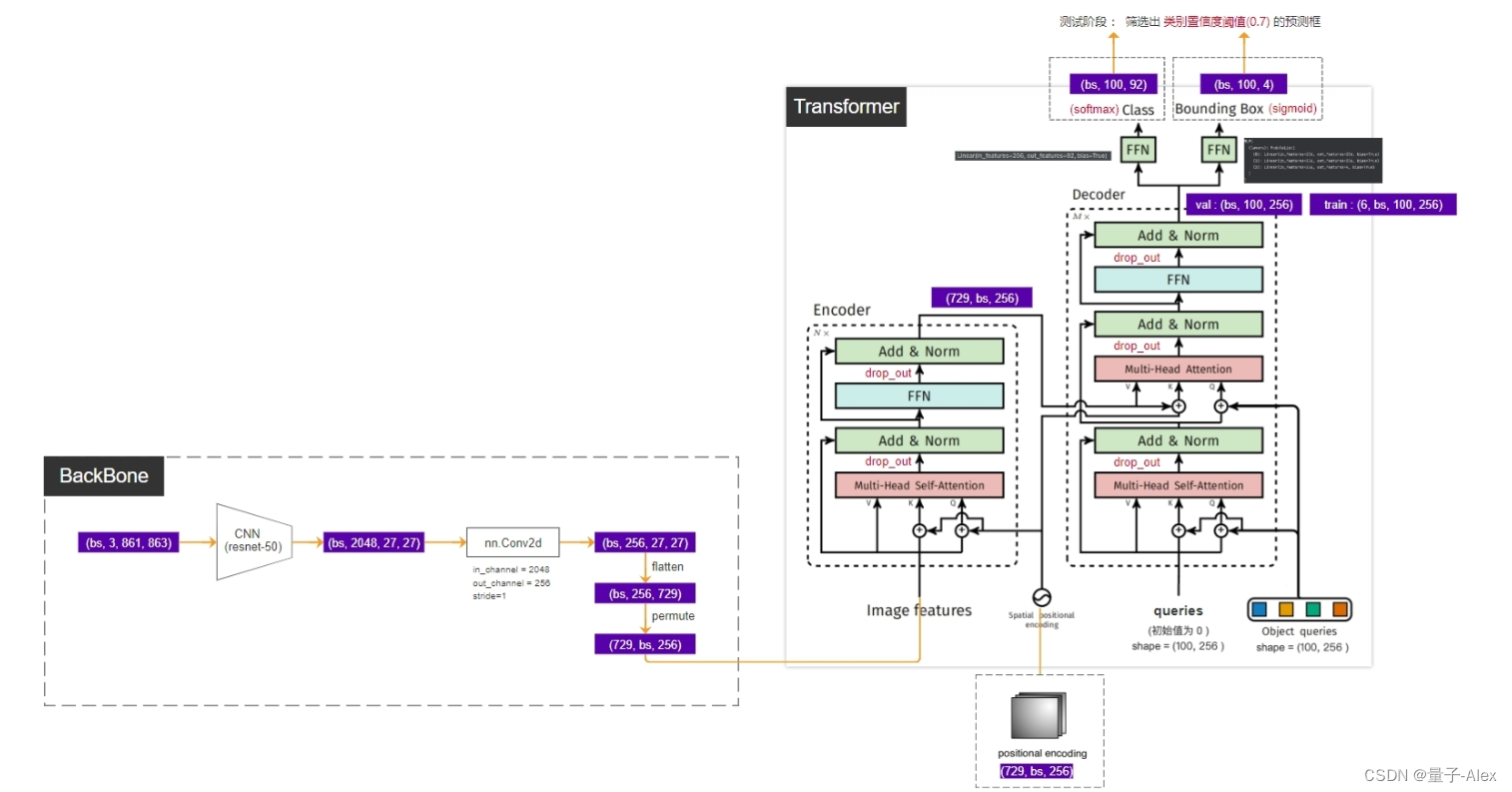
①图像预处理,输入(batch_size,3,800,1066)
②经过CNN的backbone,得到feature map是(batch_size,2048,25,34),下采样了32倍,channel数是2048
③特征图再经过一个1x1的卷积,输入的通道数是2048,输出的通道数是256,这个卷积层的目的就是减少channel数,输出(batch_size,256,25,34)
④维度flatten,得到(batch_size,256,850)
⑤再把维度调换一下,得到(850,batch_size,256),850就是后面transformer的token的个数,256就是每个token的特征向量的长度
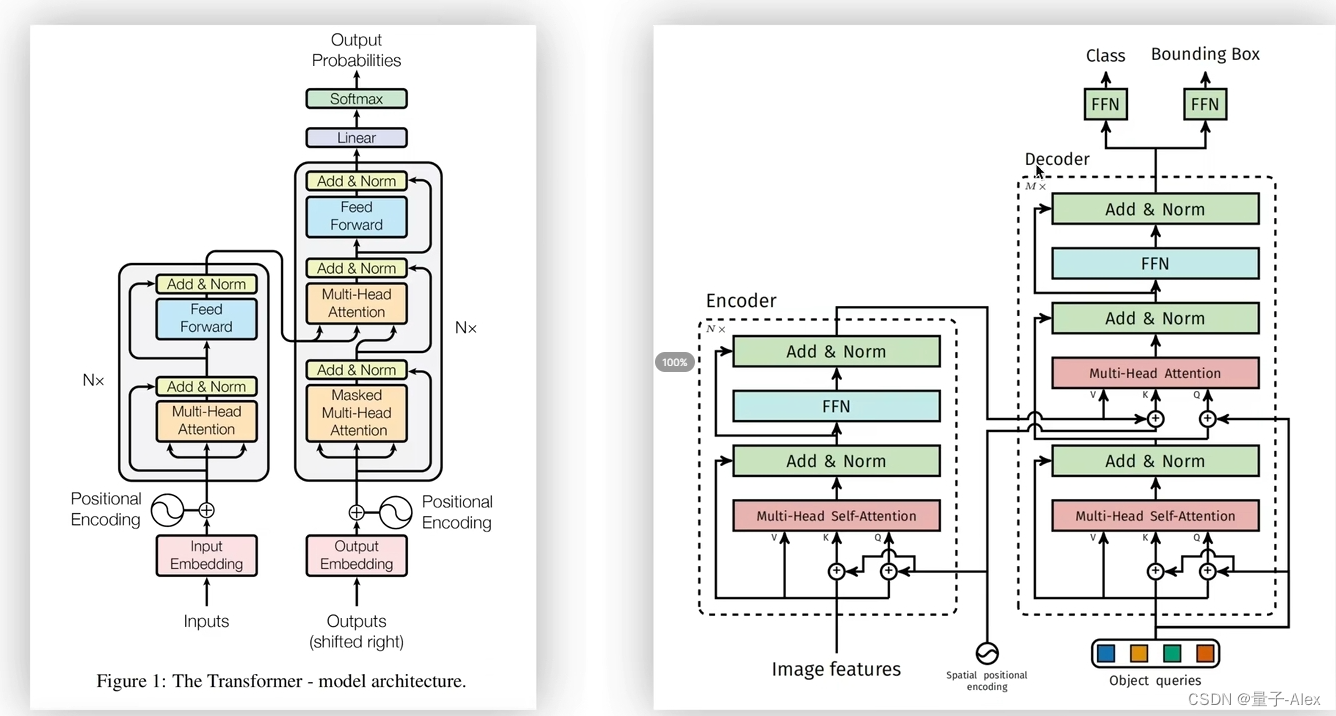
⑥特征图(850,batch_size,256)和位置编码都要传入encoder中,并且位置编码需要在每个多头自注意力层里都要加到key和query上,这就和标准的transformer不一样了。对比标准的transformer结构,位置编码是直接加到输入上的,但是DETR的encoder的位置编码,在每个堆叠的encoder-decoder中都要使用位置编码
⑦query的初始值是0,(100,256),object query也是(100,256),encoder的输出包含了图像提取的全局信息,通过两个检测头得到预测框的坐标和类别
⑧decoder的下面部分可以理解为在学习anchor特征 ,decoder的上面部分可以理解为在得到encoder输出的全局信息后,以及anchor的特征基础上,学习和预测bounding box的坐标和目标的类别
代码
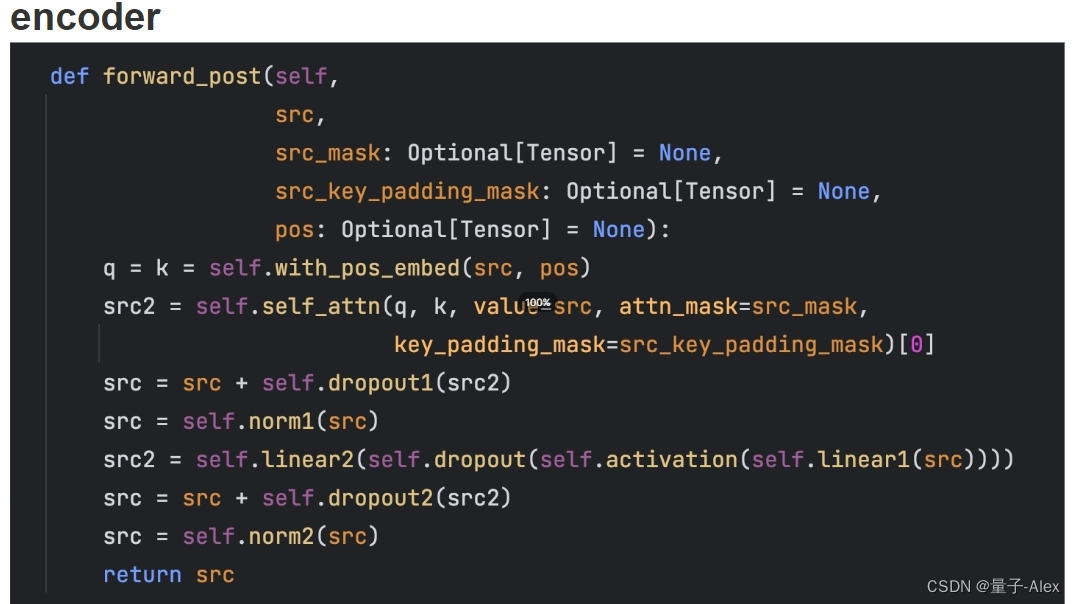
输入包括了两个参数:①src:从backbone里面得到的 image features ②pos 就是位置编码
两种位置编码方法:
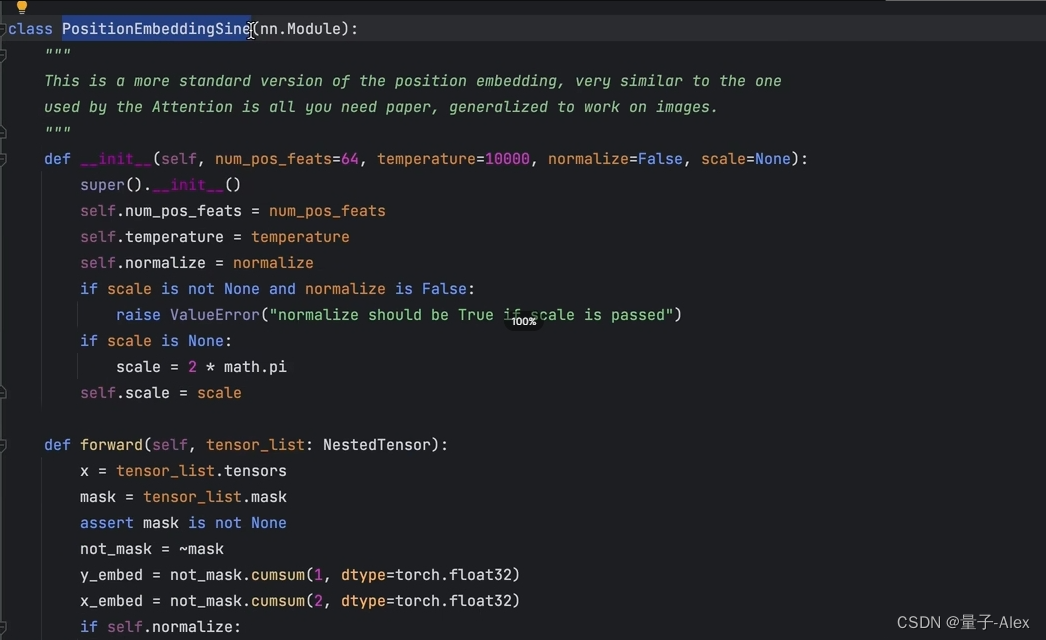
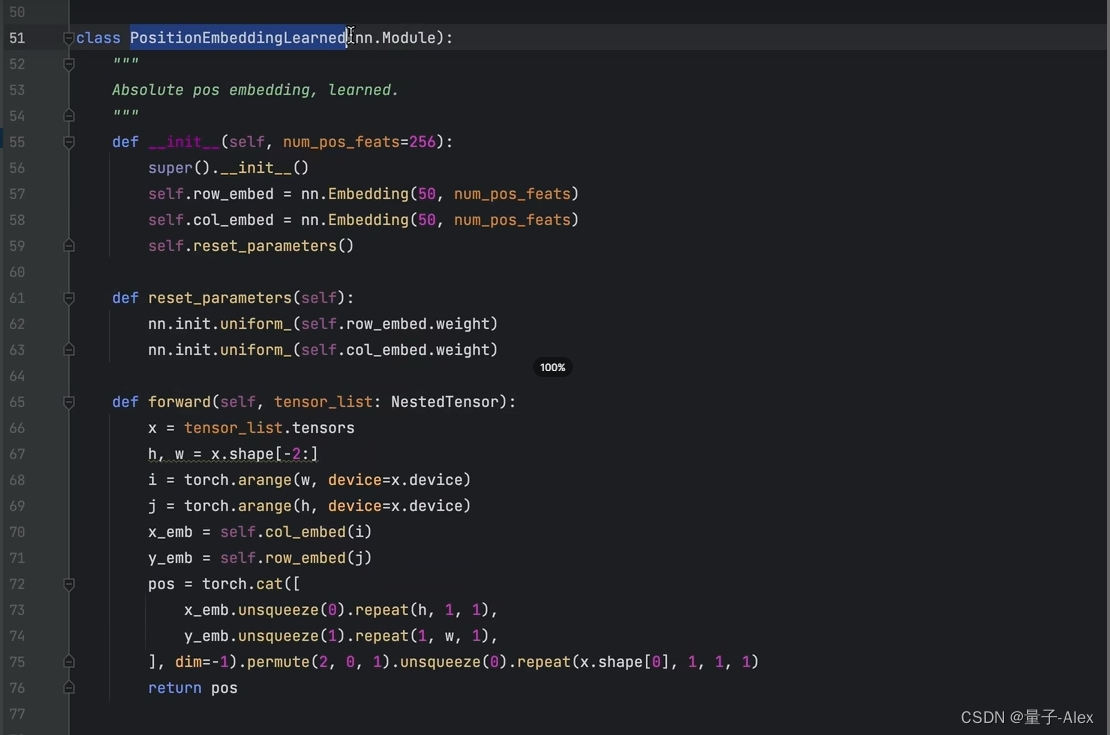
可以二选一
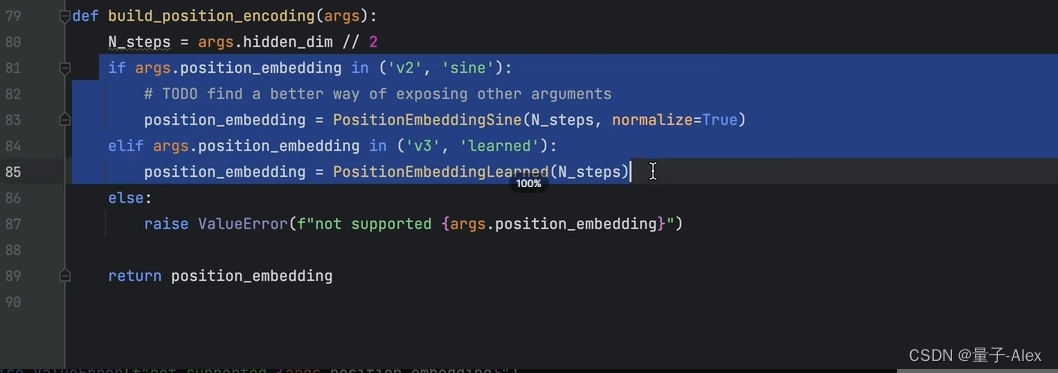
src做dropout和跨层连接,模拟resnet,
src2 是FFN层 再经过relu
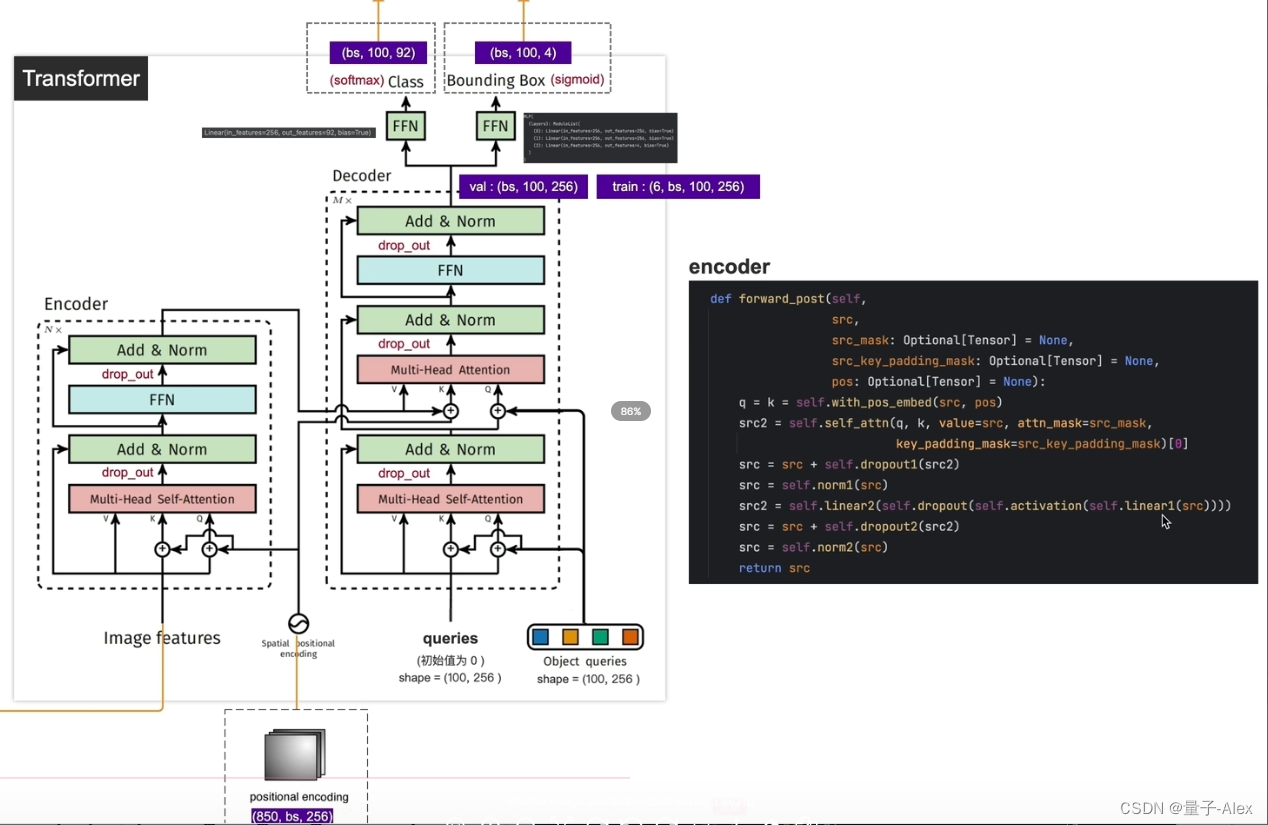
decoder:
参数:①tgt:queries (100,256) ②memory:就是encoder的输出 (850,batch_size,256) ③pos:位置编码 (850,batch_size,256)
④query_pos:就是Object queries (100,256)
①首先用with_pos_embed将queries和Object queries相加得到k,q,v就是queries
②然后对q,k,v进行Self-attention操作
③dropout和残差
④linear_norm1,覆盖tgt
⑤下一个query等于tgt加上Object queries,下一个k等于encoder输出的memory加上位置编码,下一个v就等于encoder输出的memory,再进行Multi-head Self-attention,得到tgt2
⑥dropout和残差
⑦linear_norm2,覆盖tgt
⑧FFN层包括一个全连接层,一个relu激活层,一个dropout,一个全连接层,输出tgt2
⑨dropout和残差
⑩linear_norm3
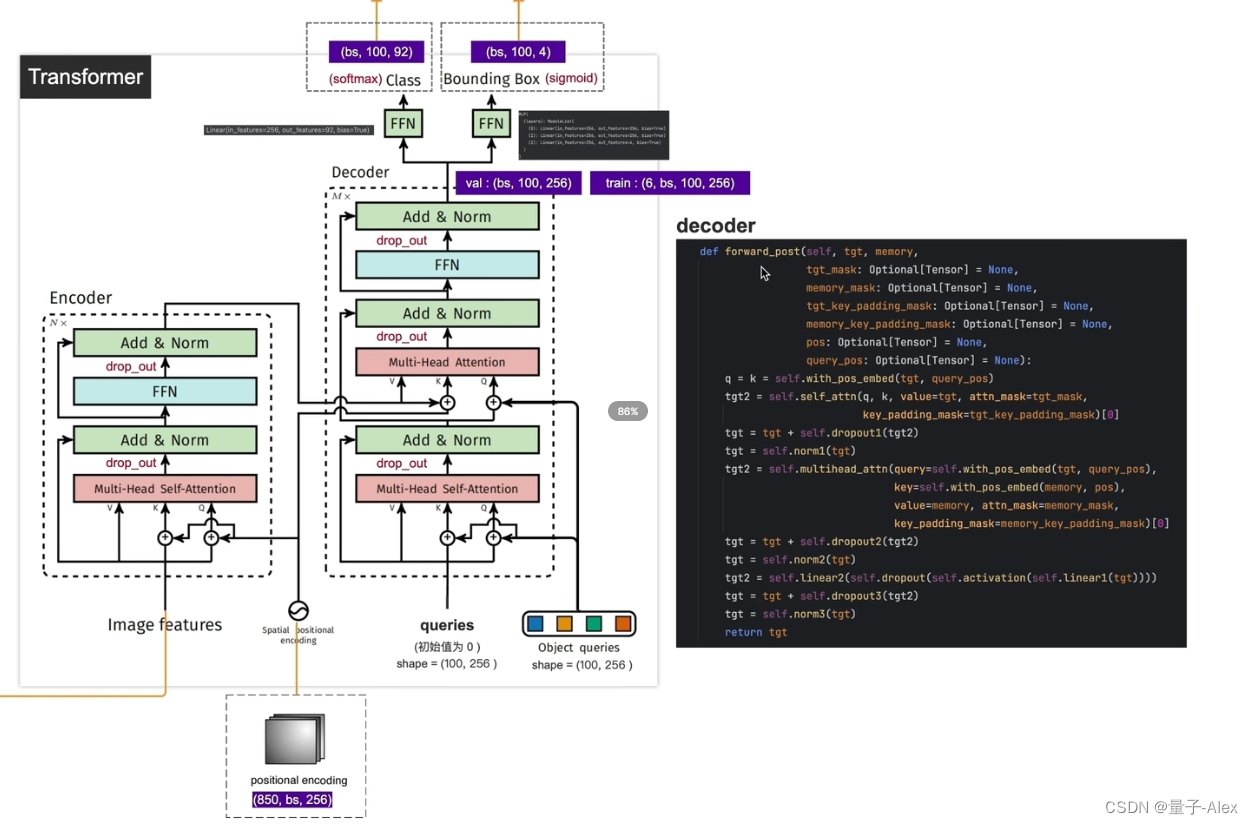
最终输出 (batch_size,100,256)
训练阶段是(6,batch_size,100,256)
因为堆叠了6个encoder-decoder,一次得到了6个
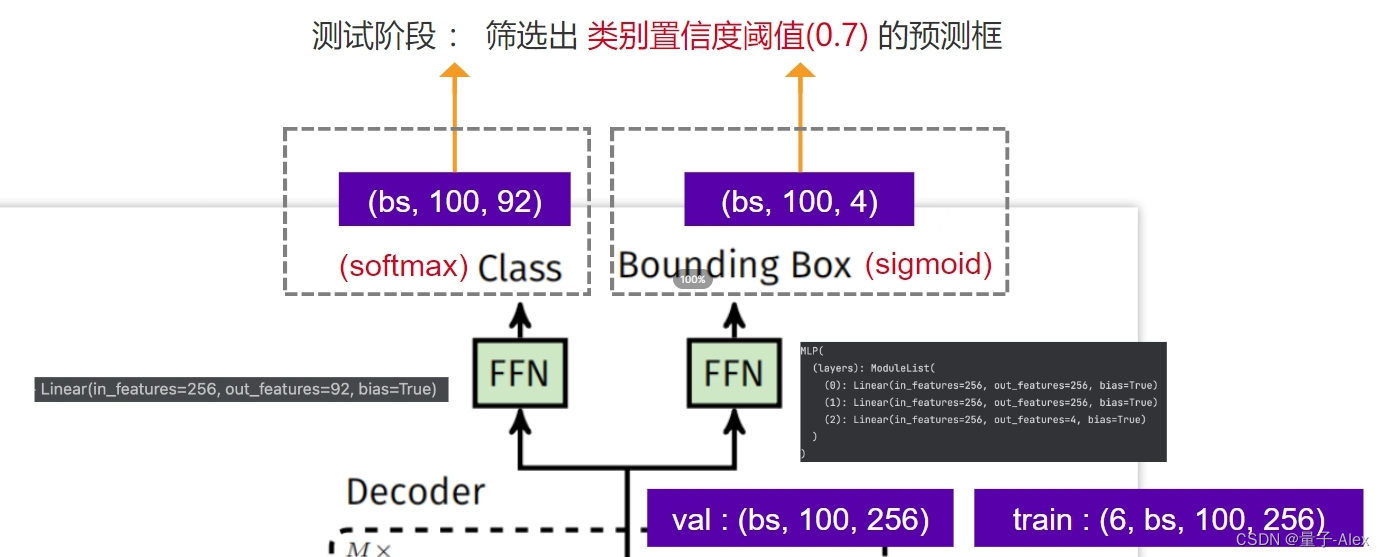
两个检测头,分别预测类别和bounding box的坐标
检测类别的FFN只是一个全连接层,92是因为coco数据集有91个类别,再加一个背景类别
检测bounding box的坐标的FFN是一个MLP,包括3个全连接层,前两个全连接层的输入和输出尺寸都是256,第3个的输入是256,输出是4,4是bounding box的(x,y,w,h),因为是需要相对坐标,所以做一个sigmoid归一化(0,1)
在测试阶段,设置一个类别置信度阈值,对于100个bounding box取置信度最大的那个类,作为bounding box的类别,
3 DETR损失函数
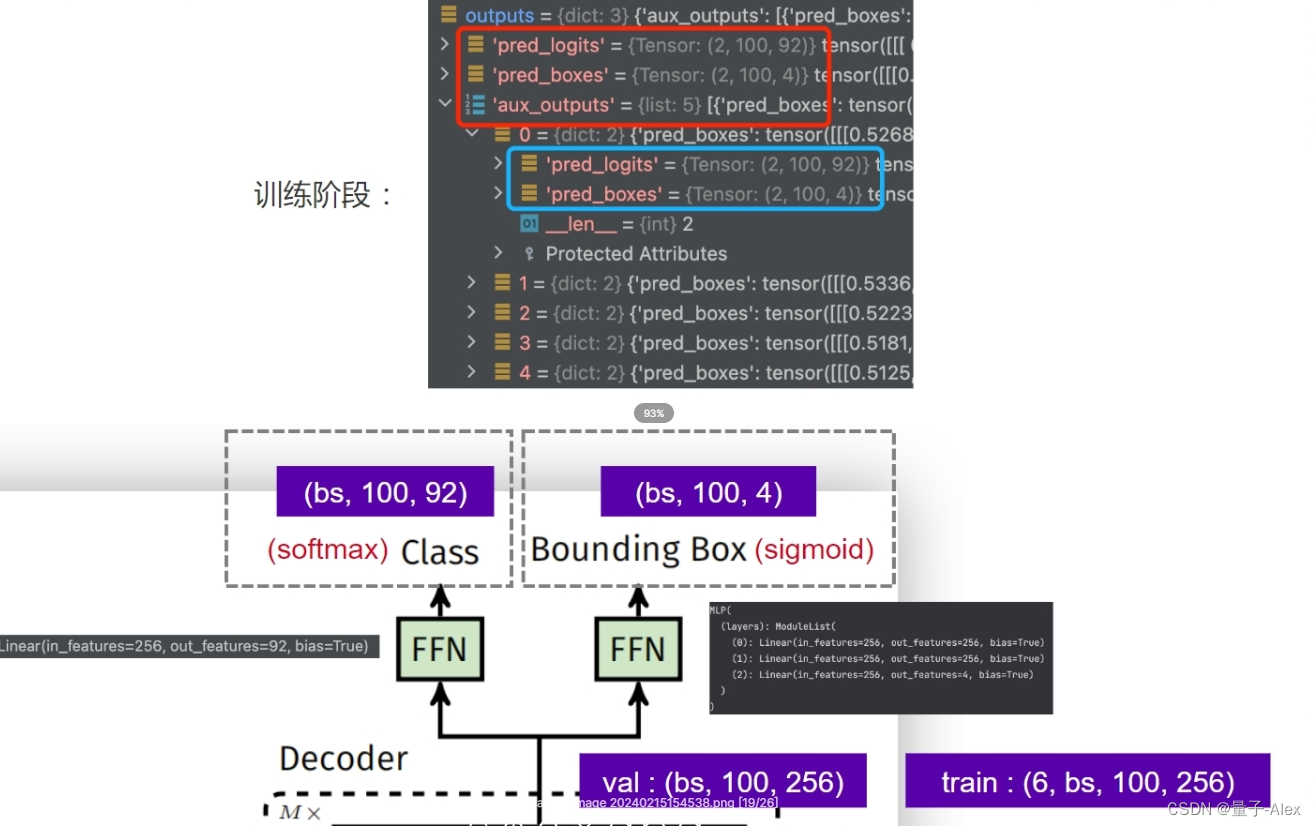
训练阶段能从网络中得到输出:是一个字典,包括了3个部分,
pred_logits和pred_boxes是decoder输出的类别预测和坐标预测结果(batch_size,100,92)和(batch_size,100,4)
batch_size这里被设置为2,aux_outputs是decoder的5个中间层的输出结果,中间层的输出和最终的decoder的检测头是一样的

要往矩阵中填的是预测框与真实的损失,其中包括两个部分,前半部分是类别损失,后半部分是坐标损失, c i c_i ci不为空,表示不计算背景的损失
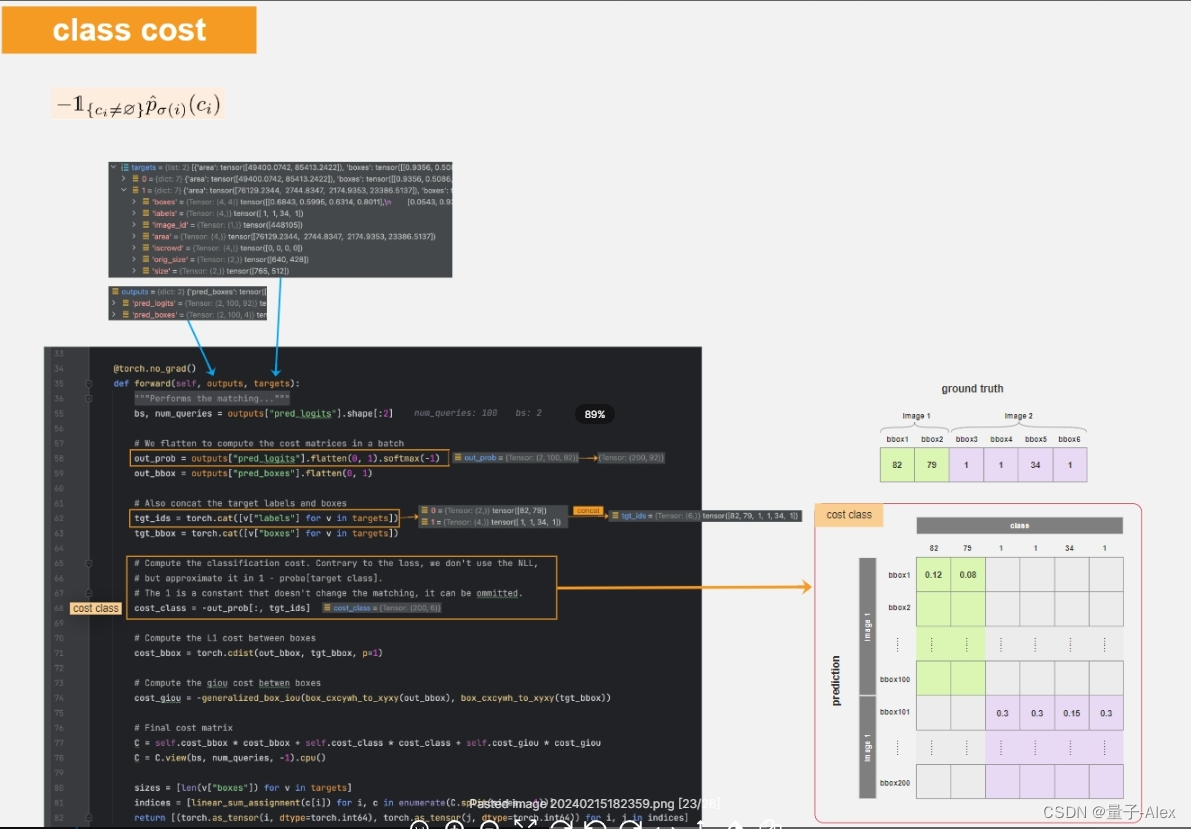
outputs是预测值,targets是标注值,先把outputs中的预测类别提取出来,即out_prob(2,100,92) 2是batch_size,100是100个预测框,92是类别,flatten为(200,92)
第62行把标注里面的类别取出来,可以看到第一张图中有两个类别,分别是第82和第79个类别;第二张图中有4个类别,分别是第1、1、34、1个类,
第68行:要从预测的200个bounding box中提取出对应的损失,绿色和紫色分别表示第1和2张图中的类别损失,取负号就是公式的前半部分
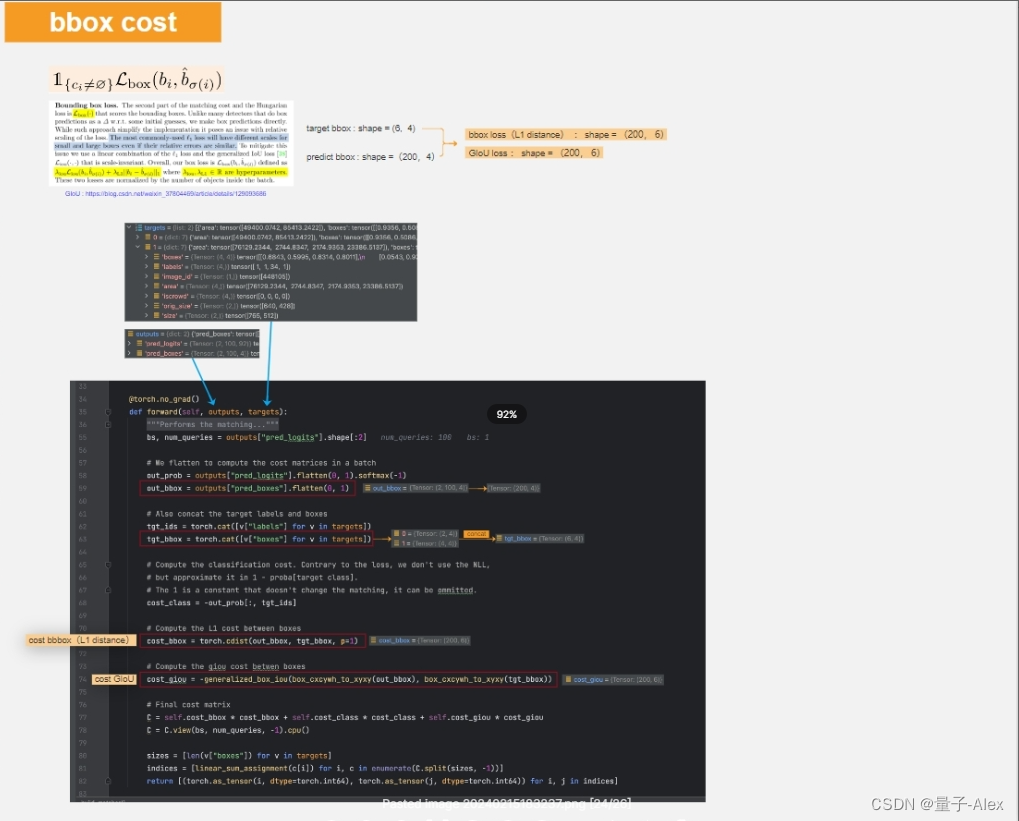
匈牙利算法损失的第二部分是用来给bounding box打分的,传统的L1损失会存在问题:对于不同尺度的box计算的损失是相似的,为了缓解这一问题,采用L1损失和GIoU损失的线性结合,

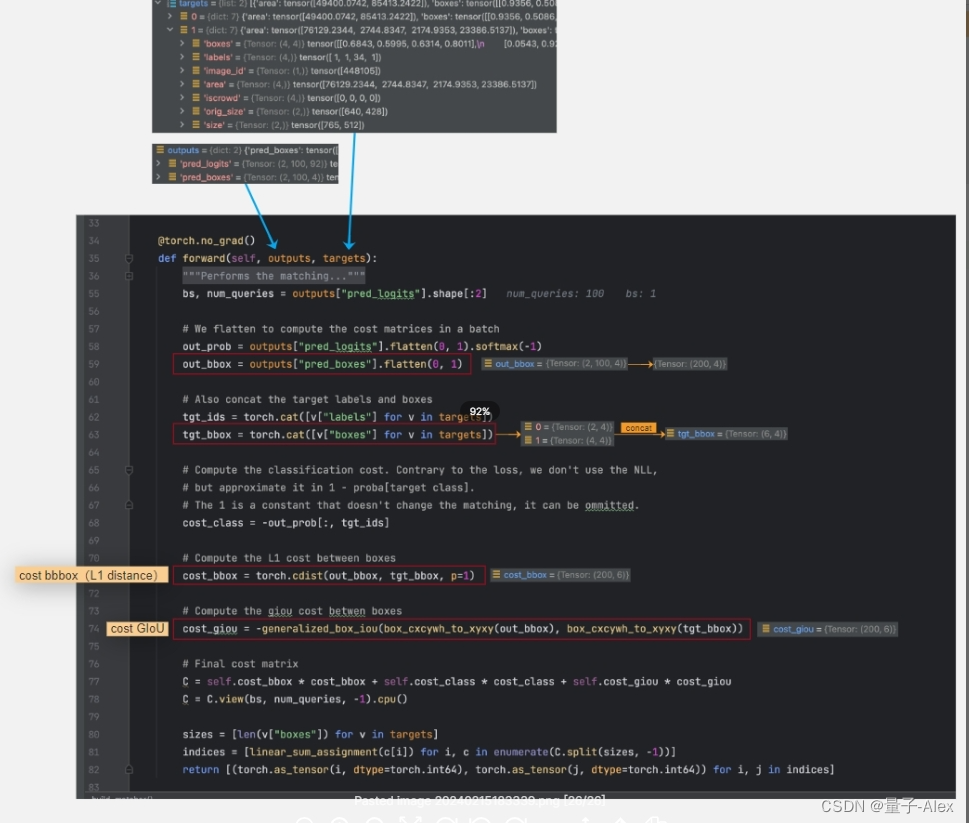
第59行:从预测结果中提出坐标部分,(2,100,4),flatten成(200,4)
第63行:从targets中提出两张图像的标注坐标