Relational Embedding for Few-Shot Classification (ICCV 2021)
一、摘要
该研究提出了一种针对少样本分类问题的新方法,通过元学习策略来学习“观察什么”和“在哪里关注”。这种方法依赖于两个关键模块:自相关表示(SCR)和交叉相关注意力(CCA),来分别处理图像内部和图像之间的关系模式。
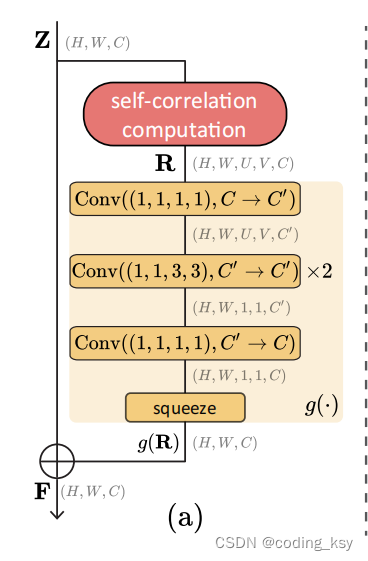
- 自相关表示(SCR)模块:用于捕捉单个图像内的结构化模式,通过转换基础特征图为自相关张量,从而提取出图像内部的关系信息。
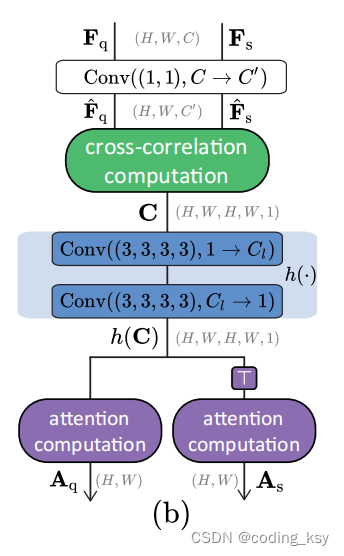
- 交叉相关注意力(CCA)模块:旨在学习不同图像之间的关系,通过计算和学习两个图像表示之间的交叉相关性,以及它们之间的共同注意力。
这两个模块被集成在关系嵌入网络(RENet)中,该网络能够端到端地学习图像的关系嵌入。这种关系嵌入有助于在处理少样本学习任务时,更好地识别和分类图像。
在四个广泛使用的少样本分类基准数据集(miniImageNet, tieredImageNet, CUB-200-2011, 和CIFAR-FS)上的实验评估显示,该方法与现有的最先进方法相比,取得了一致的性能提升。
简而言之,这项研究通过深入挖掘图像内外的关系模式,为解决少样本分类问题提供了一种新的视角和有效方法。
二、引言
该研究针对少样本图像分类问题,提出了一种基于关系模式学习的新方法。这种方法通过元学习深度嵌入函数来解决从极少量样本中学习新视觉概念的挑战,同时克服了传统方法中的过拟合问题。研究的核心理念是,相比于单个特征模式,关系模式(即元模式)具有更好的泛化能力,因为一个项目的意义是通过与系统中其他项目的比较来获得的。基于这个原理,提出了从关系角度学习“观察什么”和“在哪里关注”的策略,并将其融合以生成少样本学习的关系嵌入。
解决方案主要包含两个模块:
- 自相关表示(SCR)模块:转换基础表示为自相关张量,并学习从中提取结构化模式,捕获特征图中每个激活与其邻域的相关性,从而编码丰富的语义结构。
- 交叉相关注意力(CCA)模块:计算两个图像表示之间的交叉相关性,并从中学习产生共注意力,捕捉两图像间的语义对应关系。
这两个模块的结合,以端到端的方式学习关系嵌入,旨在图像内部提取自相关模式(通过SCR),在图像之间生成关系注意力(通过CCA),并整合这些信息来产生用于少样本分类的嵌入。通过在几个标准数据集上的实验验证,该方法有效地提高了少样本图像分类的准确性,展示了利用图像内部和图像间关系模式的强大能力。
三、相关工作
在“相关工作”部分,作者概述了针对少样本分类问题的现有方法,并将这些方法大致分为三类:基于度量的方法、基于优化的方法和基于迁移学习的方法。此外,该部分还特别讨论了自相关和交叉相关的概念及其在视觉任务中的应用,从而为提出的方法提供了理论和技术背景。
少样本分类方法的三种主要方向:
- 基于度量的方法:旨在学习将图像映射到一个度量空间的嵌入函数,其中图像对的相关性基于它们之间的距离来区分。这是作者所采用的方法。
- 基于优化的方法:通过元学习的方式,学习如何根据少量支持样本在线快速更新模型。
- 基于迁移学习的方法:表明通过早期的预训练和随后的微调,标准的迁移学习程序对于使用深度骨干网络进行少样本学习是一个强大的基线。
特殊关注的技术概念:
- 自相关(Self-correlation):通过测量图像内局部区域与其邻域的相似性,揭示图像的结构布局。近期的工作将自相关作为深度神经网络中的中间特征转换,证明它有助于学习有效的语义对应、图像翻译和视频理解的表示。
- 交叉相关(Cross-correlation):长期以来被用作计算机视觉中广泛的对应相关问题的核心组件。近期的少样本分类方法采用查询和每个支持之间的交叉相关,以识别分类的相关区域,但这些方法常常受到外观变化大导致的不可靠相关的影响。
本文贡献的总结:
- 提出了用于少样本分类的自相关表示方法,从图像内部提取可迁移的结构模式。
- 提出了用于少样本分类的交叉相关注意力模块,通过卷积滤波学习图像之间的可靠共注意力。
- 在四个标准基准数据集上的实验显示,本文方法达到了最先进的水平,且通过消融研究验证了组件的有效性。
这一部分为读者提供了该研究背景的深入理解,展示了其相对于现有工作的创新点和优势,特别是在处理自相关和交叉相关以提高少样本分类性能方面的新颖贡献。
四、Renet的整体架构
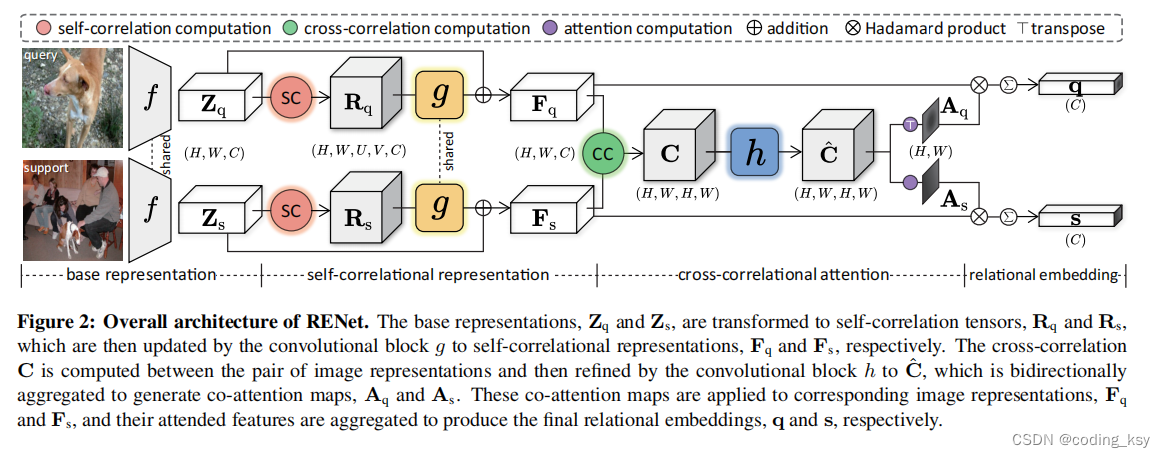
在少样本学习和元学习领域,"episodes"的概念是模仿人类学习方式而设计的一种训练策略。这种策略旨在让模型通过处理多个小任务(即episodes),来提高其对新任务的适应能力,尤其是在数据量有限的情况下。每个episode都旨在模拟一个小的学习任务,包含从多个类别中选取的少量样本,这些样本被分为support set和query set。
Support Set
Support set(支持集合)包含了一定数量的样本和对应的标签,这些样本代表了当前episode中模型需要学习的类别。在N-way K-shot任务中,support set包含了N个类别,每个类别有K个样本,模型使用这些有标签的样本来学习或调整其参数。
Query Set
Query set(查询集合)包含了另外一些样本(不包括在support set中),模型需要使用在support set上学到的知识来预测这些样本的标签。这些样本用于评估模型在学习了support set提供的信息后,对未见过的样本进行分类的能力。
Episodes 的工作流程
-
采样:在训练阶段,从整个训练数据集中随机选择N个类别,并从每个类别中随机选择K个样本构成support set,再选择更多的样本构成query set。
-
学习:模型使用support set中的样本和标签来学习或调整其参数。
-
测试:然后,模型在query set上进行测试,使用它在support set上学到的知识来预测query set中样本的类别。
-
迭代:此过程重复进行,每次都从数据集中采样不同的类别和样本来构建新的episodes,以此方式模型经历了多种不同的学习任务,目的是提高其泛化能力。
为什么使用Episodes
使用episodes的目的是让模型能够适应在只有少量样本可用时对新类别进行学习和分类的场景,即模拟真实世界中经常遇到的学习情况。这种方法尤其适用于少样本学习和元学习任务,因为它强调了模型从每个任务中快速适应和学习的能力,而不是在海量数据上进行长时间的训练。通过这种方式,模型能够在面对新类别时,更好地泛化其之前学到的知识。
五、SCR模块:增强特征
六、CCA模块
七、dataset
在评估中,我们使用四个标准基准数据集来进行小样本分类:miniImageNet、tieredImageNet、CUB-200-2011(简称CUB)和CIFAR-FS。
miniImageNet
- 来源:miniImageNet是ImageNet的一个子集,由72个研究提出。它包含60,000张图像,这些图像均匀分布在100个对象类别中。
- 数据集划分:训练/验证/测试划分分别包含64/16/20个对象类别。
tieredImageNet
- 特点:tieredImageNet是一个挑战性的数据集,由55个研究提出。其训练/验证/测试划分在ImageNet层次结构的超类别上是不相交的,这通常要求比其他数据集更好的泛化能力。
- 数据集划分:各自的训练/验证/测试划分包含20/6/8个超类别,这些超类别是351/97/160个子类别的超集。
CUB-200-2011 (CUB)
- 应用:CUB是用于鸟类细粒度分类的数据集,由73个研究提出。它包含100/50/50个对象类别的训练/验证/测试划分。
- 特殊处理:遵循最近的研究[80, 84],我们使用预裁剪到人工标注的边界框的图像。
CIFAR-FS
- 基础:CIFAR-FS是基于CIFAR-100数据集构建的,由3个研究提出。遵循最近的研究[3],我们使用相同的训练/验证/测试划分,分别包含64/16/20个对象类别。
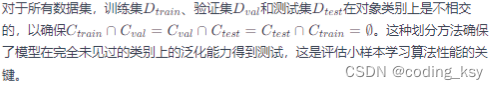
未完待续…






![9 个管理 Windows 硬盘的最佳免费磁盘分区软件 [2024 排名]](https://img-blog.csdnimg.cn/img_convert/f98ff5de2d3886e3573a46df26b4eac6.webp?x-oss-process=image/format,png)