无向图创建邻接矩阵、深度优先遍历和广度优先遍历
- 一、概念解析:
-
- (1)无向图:
- (2)邻接矩阵:
- 二、创建邻接矩阵:
- 三、深度遍历、广度遍历
-
- (1)深度遍历概念:
- (2)广度遍历概念:
- 四、实例展示
一、概念解析:
(1)无向图:
假设图G由两个集合V和E组成,记为G={V , E}。其中V是顶点的有限集合,E是连接V中两个不同顶点的边的有限集合。如果E中的顶点对是有序的,即E中的每条边都是有方向的,则称G是有向图。如果顶点对是无序的,则称G是无向图


(2)邻接矩阵:
邻接矩阵主要由:二维数组 实现
如图

转换成邻接矩阵为:

二、创建邻接矩阵:
基本每一步都有注释,详细观看,建议画图理解
代码如下:
#define MAXSIZE 100
// 邻接矩阵
typedef struct Matrix{int V_Data; // 顶点数据域 int E_Data; // 边数数据域int Node[MAXSIZE]; // 存放顶点数据,也就是顶点表 int Weight[MAXSIZE][MAXSIZE]; // 存放权重,为矩阵中两点有边的标记符号 }MaTrix,*MATRIX;// 邻接矩阵数据结构体
typedef struct Edge{int v1; // 用来存放第一个顶点 int v2; // 用来存放第二个顶点int weight; // 用来存放两点之间的标记符,即为权
}*EDGE;//******************** 邻接矩阵*******************//
// 邻接矩阵、顶点和边初始化
void Init_Matrix(MATRIX S,int Vertex)
{ S->E_Data = 0; // 初始化为0条边 S->V_Data = Vertex; // 初始化顶点数 int i,j;for(i=0;i<Vertex;i++){for(j=0;j<Vertex;j++){S->Weight[i][j] = 0;}}
}// 开始插入边的权重,即为两个顶点之间边的标记符
void InSerData(MATRIX S,EDGE E)
{// 将输入的顶点v1、v2之间的边,用权作为标记,在矩阵中表示// 这里是无向图,所以边没有方向,需要做标记两次(为v1-v2和v2-v1) S->Weight[E->v1][E->v2] = E->weight; S->Weight[E->v2][E->v1] = E->weight;
} // 开始插入数据
void InSerEdge_Data(MATRIX S,int edge,int V)
{int i,j;if(edge>0) // 边数大于0的时候才插入数据 {printf("请输入顶点和权重(空格分隔!)\n");for(i=0;i<edge;i++){ EDGE E; //分配内存,接受顶点v1,v2和权重(标记符) E = (EDGE)malloc(sizeof(struct Edge)); scanf("%d %d %d",&(E->v1),&(E->v2),&(E->weight));if(E->v1 ==E->v2){printf("无向图邻接矩阵对角线为0,输入错误,结束运行\n");exit(-1); }InSerData(S,E);} printf("请输入要定义的顶点,填入顶点表中: \n");for(j=0;j<V;j++){scanf("%d",&(S->Node[j]));} }else{ printf("输入的边数错误"); }
}
三、深度遍历、广度遍历
(1)深度遍历概念:


定义的结构体、数组可看上面代码
深度遍历代码解析:
//***************** 深度优先遍历算法—邻接矩阵 *****************//
void DFS_Begin(MATRIX P,int k,int V)
{int i;flag[k] = 1; //标记当前顶点,表示已经遍历过printf("%d ",P->Node[k]); // 输出当前顶点 for(i=0;i<V;i++){if(!flag[i] && P->Weight[k][i] != 0)// 如果当前顶点的邻近点存在,且没有遍历过 { // 则继续递归遍历 DFS_Begin(P,i,V); // 递归遍历当前顶点的邻近点 } }
}void Init_DFSMatrix(MATRIX P,int V)
{int i;// 初始化标记符数组,全为0 for(i=0;i<V;i++){flag[i] = 0;}for(i=0;i<V;i++) // 每个顶点都要检查是否遍历到 {if(!flag[i]) // 排除遇到已经遍历的顶点DFS_Begin(P,i,V); // 开始深度遍历 } putchar('\n');
}
(2)广度遍历概念:

这里使用到了链队列(也可以使用数组队列,看个人想法),可以看我之前的博文有讲:
//******************** 队列 *****************//
typedef struct Queue{int data[MAXSIZE]; // 队列大小 int head; // 队头 int wei; // 队尾 }Queue; //***************** 队列 *************************************//
// 队列初始化
void InitQueue(Queue *q)
{q->head= 0; // 初始化队头、队尾 q->wei = 0;
} // 判断队列是否为空
int EmptyQueue(Queue *q)
{if(q->head == q->wei)return 1;else{return 0;}
} // 入队
void PushQueue(Queue *q,int t)
{if((q->wei+1)%MAXSIZE == q->head) // 说明队列已经满了return;else{ q->data[q->wei] = t; q->wei = (q->wei +1)%MAXSIZE; // 队尾后移 }} // 出队
void PopQueue(Queue *q,int *x)
{if(q->wei == q->head) // 出队完毕 return; else{ *x = q->data[q->head];q->head = (q->head + 1)%MAXSIZE; // 队头后移 } } //***************** 广度优先搜索算法—邻接矩阵 ****************//
void Init_Bfs(MATRIX S,int V)
{int i,j;int k;Queue Q;for(i=0;i<V;i++){Vist[i] = 0; // 初始化标记符 }InitQueue(&Q); // 队列初始化 for (i = 0; i < V; i++){if (!Vist[i]) // 判断以这个顶点为基准,有连接的其他顶点 {Vist[i] = 1; // 标记遍历的这个顶点 printf("%d ", S->Node[i]);PushQueue(&Q, i); // 入队 while (!EmptyQueue(&Q)) // 队列中还有数据,说明这个顶点连接的其他顶点还没有遍历完 {PopQueue(&Q,&i); // 出队 for (j = 0; j < V; j++){// 以这个顶点为基准,遍历其他连接的顶点 if (!Vist[j] && S->Weight[i][j] != 0){Vist[j] = 1; // 与之连接的顶点作上标记,便于后序顶点跳过相同的遍历 printf("%d ", S->Node[j]);// 输出与之相邻连接的顶点 PushQueue(&Q, j); // 让与之连接的顶点其位置入队 }}}}}
}
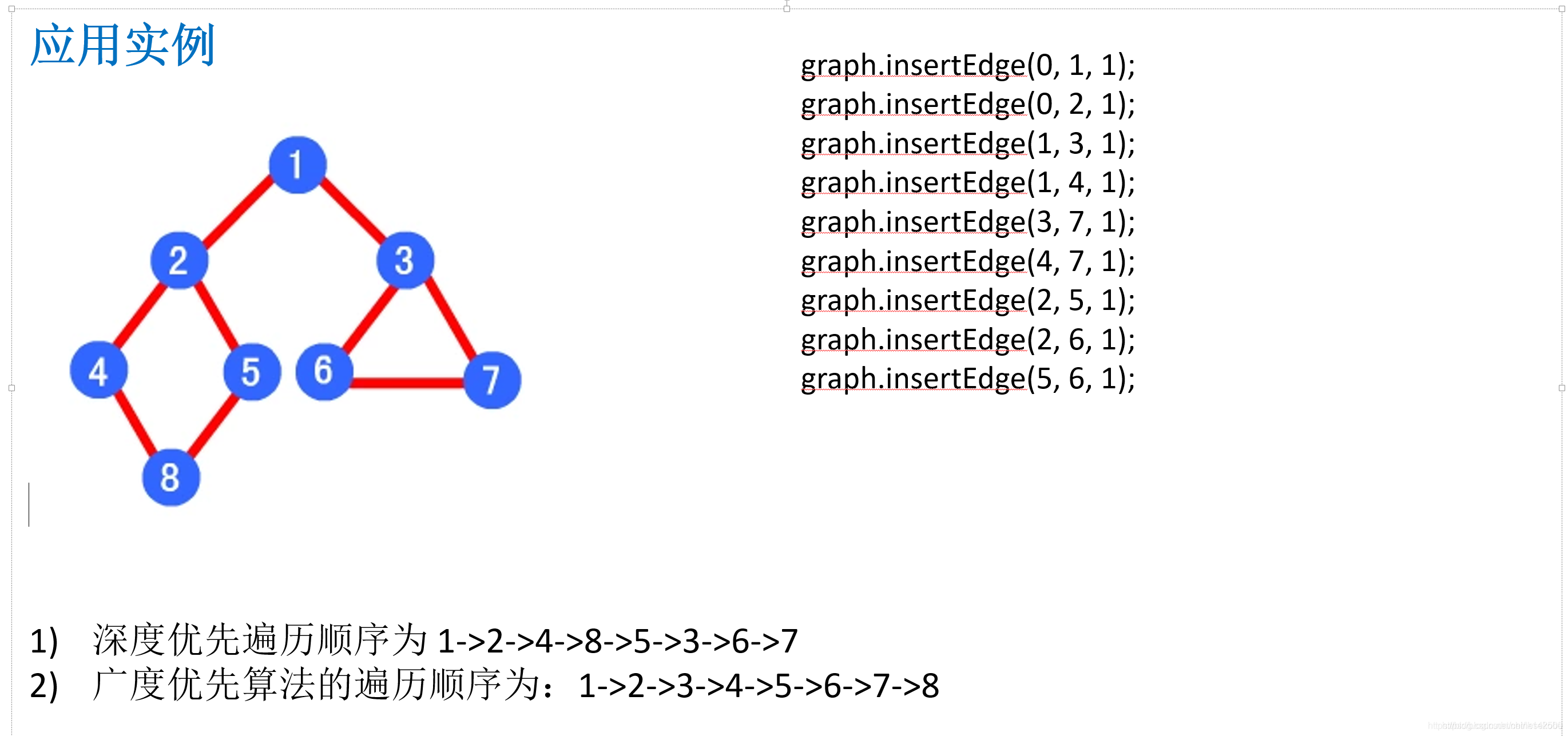
四、实例展示
注意:这里存入数据时,坐标点以原点(0,0)为起点开始!
以这个图为样例展示:
全部代码:
#include<stdio.h>
#include<stdlib.h>#define MAXSIZE 100 // 深度遍历标记符
int flag[MAXSIZE]; // 邻接矩阵 // 广度优先遍历标记符
int Vist[MAXSIZE]; // 邻接矩阵//******************** 队列 *****************//
typedef struct Queue{int data[MAXSIZE]; // 队列大小 int head; // 队头 int wei; // 队尾 }Queue; // 邻接矩阵
typedef struct Matrix{int V_Data; // 顶点数据域 int E_Data; // 边数数据域int Node[MAXSIZE]; // 存放顶点数据,也就是顶点表 int Weight[MAXSIZE][MAXSIZE]; // 存放权重,为矩阵中两点有边的标记符号 }MaTrix,*MATRIX;// 邻接矩阵数据结构体
typedef struct Edge{int v1; // 用来存放第一个顶点 int v2; // 用来存放第二个顶点int weight; // 用来存放两点之间的标记符,即为权
}*EDGE;//******************** 邻接矩阵*******************//
// 邻接矩阵、顶点和边初始化
void Init_Matrix(MATRIX S,int Vertex)
{ S->E_Data = 0; // 初始化为0条边 S->V_Data = Vertex; // 初始化顶点数 int i,j;for(i=0;i<Vertex;i++){for(j=0;j<Vertex;j++){S->Weight[i][j] = 0;}}
}// 开始插入边的权重,即为两个顶点之间边的标记符
void InSerData(MATRIX S,EDGE E)
{// 将输入的顶点v1、v2之间的边,用权作为标记,在矩阵中表示// 这里是无向图,所以边没有方向,需要做标记两次(为v1-v2和v2-v1) S->Weight[E->v1][E->v2] = E->weight;S->Weight[E->v2][E->v1] = E->weight;
} //***************** 深度优先遍历算法—邻接矩阵 *****************//
void DFS_Begin(MATRIX P,int k,int V)
{int i;flag[k] = 1; //标记当前顶点,表示已经遍历过printf("%d ",P->Node[k]); // 输出当前顶点 for(i=0;i<V;i++){if(!flag[i] && P->Weight[k][i] != 0)// 如果当前顶点的邻近点存在,且没有遍历过 { // 则继续递归遍历 DFS_Begin(P,i,V); // 递归遍历当前顶点的邻近点 } }
}void Init_DFSMatrix(MATRIX P,int V)
{int i;// 初始化标记符数组,全为0 for(i=0;i<V;i++){flag[i] = 0;}for(i=0;i<V;i++) // 每个顶点都要检查是否遍历到 {if(!flag[i]) // 排除遇到已经遍历的顶点DFS_Begin(P,i,V); // 开始深度遍历 } putchar('\n');}//***************** 队列 *************************************//
// 队列初始化
void InitQueue(Queue *q)
{q->head= 0; // 初始化队头、队尾 q->wei = 0;
} // 判断队列是否为空
int EmptyQueue(Queue *q)
{if(q->head == q->wei)return 1;else{return 0;}
} // 入队
void PushQueue(Queue *q,int t)
{if((q->wei+1)%MAXSIZE == q->head) // 说明队列已经满了return;else{ q->data[q->wei] = t; q->wei = (q->wei +1)%MAXSIZE; // 队尾后移 }} // 出队
void PopQueue(Queue *q,int *x)
{if(q->wei == q->head) // 出队完毕 return; else{*x = q->data[q->head];q->head = (q->head + 1)%MAXSIZE; // 队头后移} } //***************** 广度优先搜索算法—邻接矩阵 ****************//
void Init_Bfs(MATRIX S,int V)
{int i,j;int k;Queue Q;for(i=0;i<V;i++){Vist[i] = 0; // 初始化标记符 }InitQueue(&Q); // 队列初始化 for (i = 0; i < V; i++){if (!Vist[i]) // 判断以这个顶点为基准,有连接的其他顶点 {Vist[i] = 1; // 标记遍历的这个顶点 printf("%d ", S->Node[i]);PushQueue(&Q, i); // 入队 while (!EmptyQueue(&Q)) // 队列中还有数据,说明这个顶点连接的其他顶点还没有遍历完 {PopQueue(&Q,&i); // 出队 for (j = 0; j < V; j++){// 以这个顶点为基准,遍历其他连接的顶点 if (!Vist[j] && S->Weight[i][j] != 0){Vist[j] = 1; // 与之连接的顶点作上标记,便于后序顶点跳过相同的遍历 printf("%d ", S->Node[j]);// 输出与之相邻连接的顶点 PushQueue(&Q, j); // 让与之连接的顶点其位置入队 }}}}}
} // 初始化顶点个数
int Init_Vertex()
{int Vertex;printf("请输入顶点个数: ");scanf("%d",&Vertex);return Vertex;
}// 初始化边的数量
int Init_Edge()
{int edge;printf("请输入边的数量: ");scanf("%d",&edge);return edge;} // 开始插入数据
void InSerEdge_Data(MATRIX S,int edge,int V)
{int i,j;if(edge>0) // 边数大于0的时候才插入数据 {printf("请输入顶点和权重(空格分隔!)\n");for(i=0;i<edge;i++){ EDGE E; //分配内存,接受顶点v1,v2和权重(标记符) E = (EDGE)malloc(sizeof(struct Edge)); scanf("%d %d %d",&(E->v1),&(E->v2),&(E->weight));if(E->v1 ==E->v2){printf("无向图邻接矩阵对角线为0,输入错误,结束运行\n");exit(-1); }InSerData(S,E);} printf("请输入要定义的顶点,填入顶点表中: \n");for(j=0;j<V;j++){scanf("%d",&(S->Node[j]));}}else{printf("输入的边数错误"); } } // 打印无向图邻接矩阵
void Show_Matrix(MATRIX p,int Vertex)
{int i,j;for(i=0;i<Vertex;i++){for(j=0;j<Vertex;j++){printf("%4d",p->Weight[i][j]); // 打印邻接矩阵 } putchar('\n'); // 换行 }
}int main()
{int val;int Vertex;int edge;MATRIX p; // 邻接矩阵头节点指针// 创建无向图邻接矩阵 Vertex = Init_Vertex();edge = Init_Edge();p = (MATRIX)malloc(sizeof(MaTrix)); //分配内存空间 p->V_Data = Vertex; // 记录顶点个数 p->E_Data = edge; // 记录边的个数 Init_Matrix(p,Vertex); // 初始化邻接矩阵 InSerEdge_Data(p,edge,Vertex); // 插入数据 // 打印无向图的邻接矩阵 printf("无向图邻接矩阵如下:"); printf("\n----------------------------------\n\n");Show_Matrix(p,Vertex);printf("\n----------------------------------\n");// 深度优先遍历—邻接矩阵 printf("深度遍历—邻接矩阵结果为:\n");Init_DFSMatrix(p,Vertex);// 广度优先遍历—邻接矩阵printf("广度优先遍历—邻接矩阵结果为: \n");Init_Bfs(p,Vertex);return 0;
}
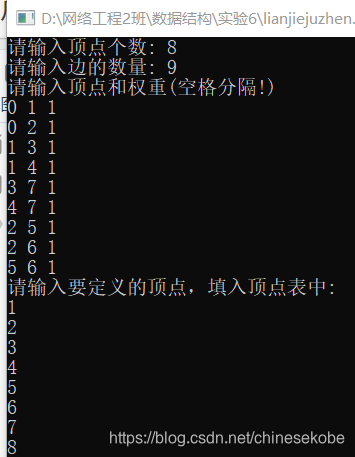
结果图:

![[职场] 实验室科研人员简历范文 #学习方法#职场发展](https://img-blog.csdnimg.cn/img_convert/01d20894e66b61acad4e890dcd2e88c4.jpeg)