目录
探索命令行
学习使用 man
寻找帮助
控制字符
统计代码行数
统计磁盘使用情况
在Linux下编写 Hello World 程序
使用重定向
使用Makefile管理工程
Unix哲学
探索命令行
Linux命令行中的命令使用格式都是相同的:
命令名称 参数1 参数2 参数3 ...参数之间用任意数量的空白字符分开
Linux新手教程推荐,介绍一些常见的命令:技术|新手指南: Linux 新手应该知道的 26 个命令
最常用的一些命令:
ls用于列出当前目录(即"文件夹")下的所有文件(或目录). 目录会用蓝色显示.ls -l可以显示详细信息.pwd能够列出当前所在的目录.cd DIR可以切换到DIR目录. 在Linux中, 每个目录中都至少包含两个目录:.指向该目录自身,..指向它的上级目录. 文件系统的根是/.touch NEWFILE可以创建一个内容为空的新文件NEWFILE, 若NEWFILE已存在, 其内容不会丢失.cp SOURCE DEST可以将SOURCE文件复制为DEST文件; 如果DEST是一个目录, 则将SOURCE文件复制到该目录下.mv SOURCE DEST可以将SOURCE文件重命名为DEST文件; 如果DEST是一个目录, 则将SOURCE文件移动到该目录下.mkdir DIR能够创建一个DIR目录.rm FILE能够删除FILE文件; 如果使用-r选项则可以递归删除一个目录. 删除后的文件无法恢复, 使用时请谨慎!man可以查看命令的帮助. 例如man ls可以查看ls命令的使用方法. 灵活应用man和互联网搜索, 可以快速学习新的命令.
下面给出一些常用命令使用的例子, 你可以键入每条命令之后使用ls查看命令执行的结果:
$ mkdir temp # 创建一个目录temp
$ cd temp # 切换到目录temp
$ touch newfile # 创建一个空文件newfile
$ mkdir newdir # 创建一个目录newdir
$ cd newdir # 切换到目录newdir
$ cp ../newfile . # 将上级目录中的文件newfile复制到当前目录下
$ cp newfile aaa # 将文件newfile复制为新文件aaa
$ mv aaa bbb # 将文件aaa重命名为bbb
$ mv bbb .. # 将文件bbb移动到上级目录
$ cd .. # 切换到上级目录
$ rm bbb # 删除文件bbb
$ cd .. # 切换到上级目录
$ rm -r temp # 递归删除目录temp学习使用 man
命令行中输入以下命令
man man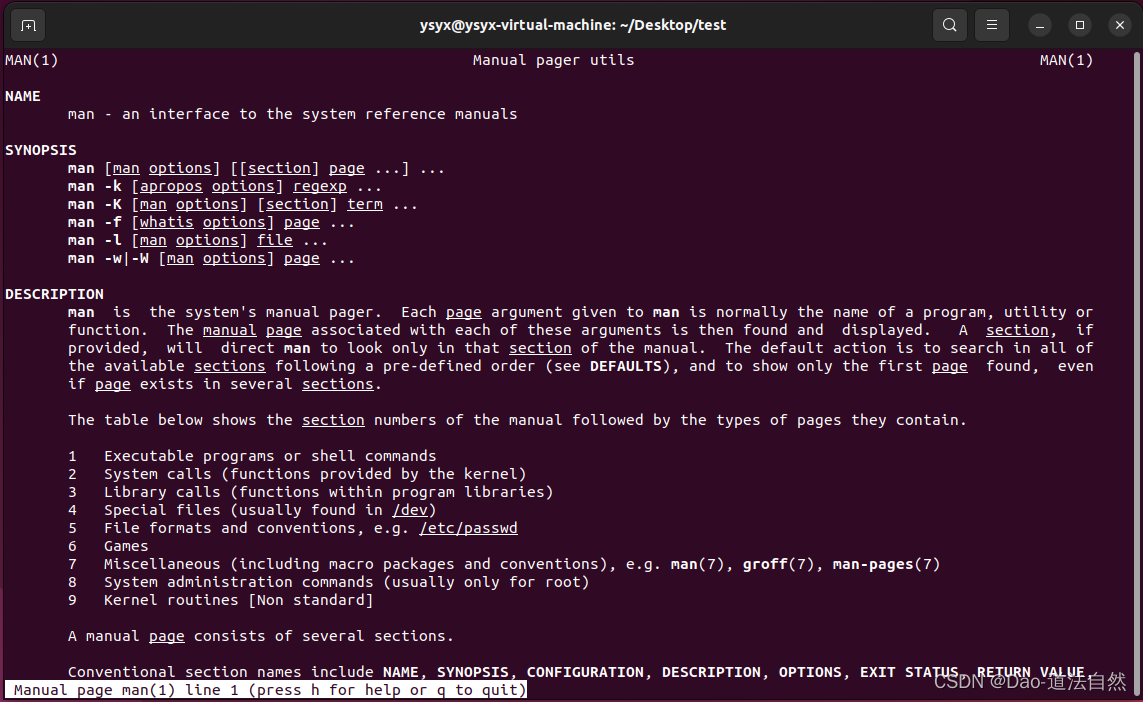
在这里, 你看到整个manual分成9大类, 每个manual page都属于其中的某一类; 你看到了一个manual page主要包含以下的小节:
- NAME - 命令名
- SYNOPSIS - 使用方法大纲
- CONFIGURATION - 配置
- DESCRIPTION - 功能说明
- OPTIONS - 可选参数说明
- EXIT STATUS - 退出状态, 这是一个返回给父进程的值
- RETURN VALUE - 返回值
- ERRORS - 可能出现的错误类型
- ENVIRONMENT - 环境变量
- FILES - 相关配置文件
- VERSIONS - 版本
- CONFORMING TO - 符合的规范
- NOTES - 使用注意事项
- BUGS - 已经发现的bug
- EXAMPLE - 一些例子
- AUTHORS - 作者
- SEE ALSO - 功能或操作对象相近的其它命令
寻找帮助
最后一行,h 寻找帮助;q 退出
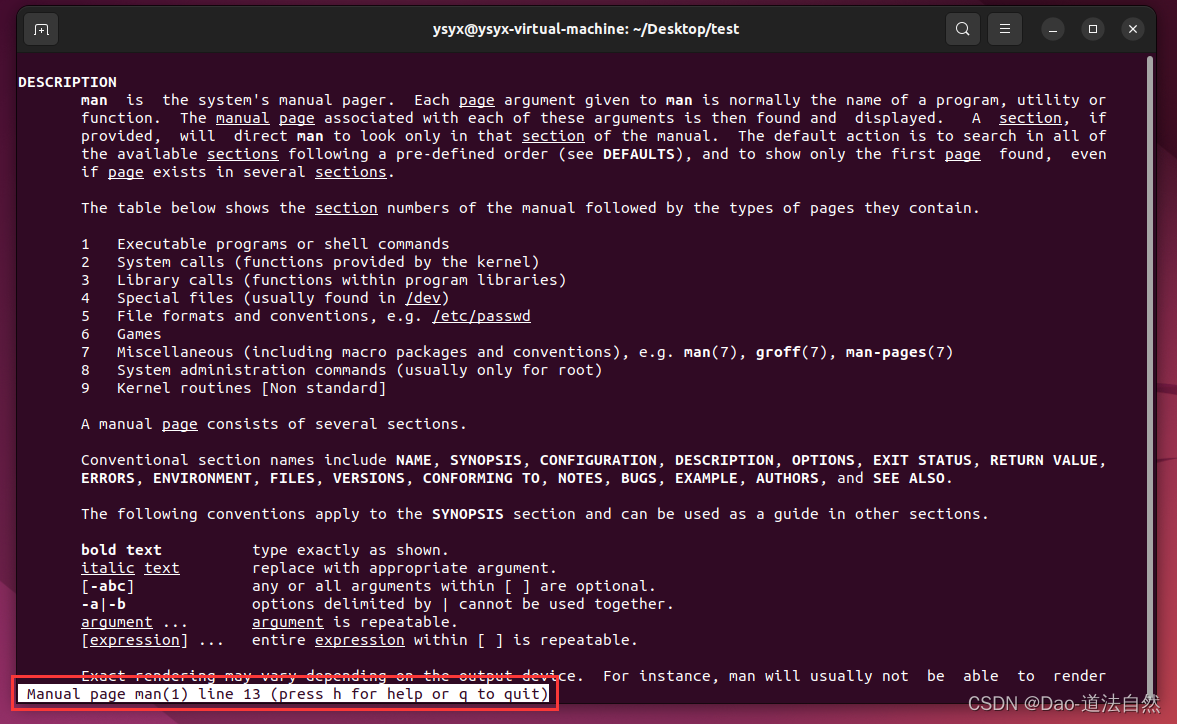
摁下 h 进去看看,这个页面是告诉使用者如何使用man
常用功能-搜索
使用关键字可以快速定位到你关心的内容. 帮助的内容告诉你, 通过按/激活前向搜索模式, 然后输入关键字(可以使用正则表达式), 按下回车就可以看到匹配的内容了.
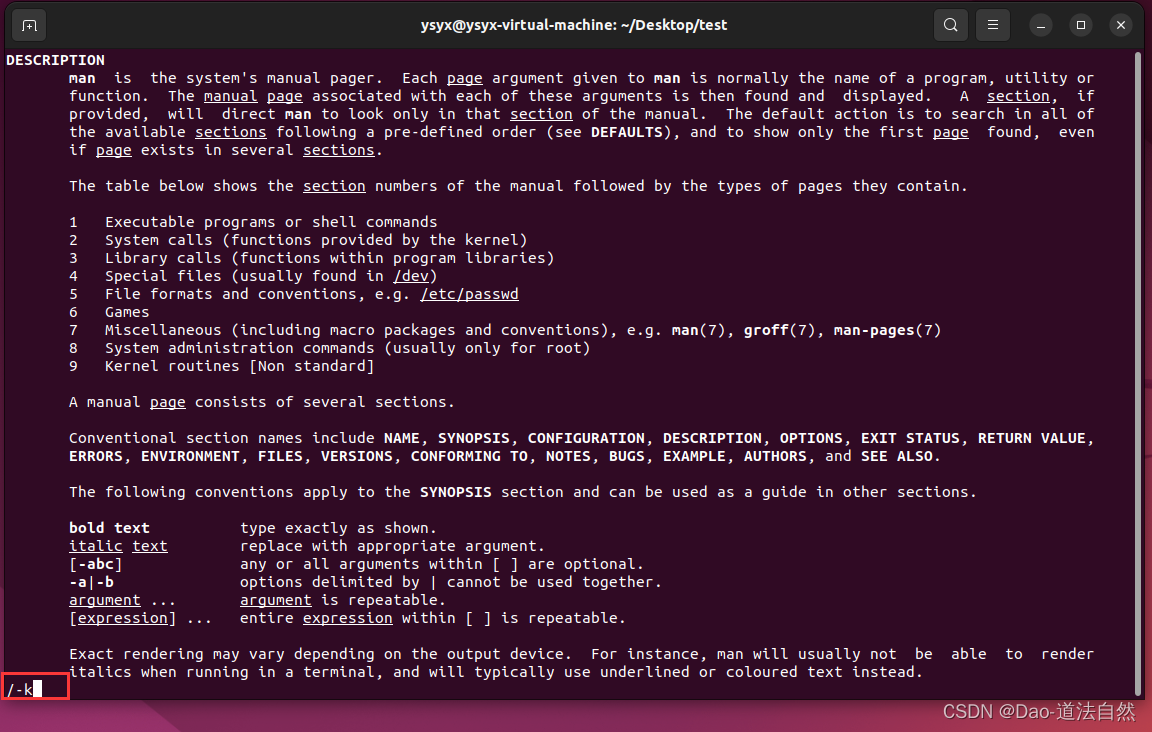
迅速匹配到 -k 参数,并且定位到第一个 -k 位置

摁下 n 可以跳转到下一个匹配结果
为了弄清楚参数-k的含义, 你输入/-k, 按下回车, 并通过n跳过了那些OPTIONS小节之外的-k, 最后大约在第254行找到了-k的解释: 通过关键字来搜索相关功能的manual page. 在EXAMPLES小节中有一个使用-k的例子:
man -k printf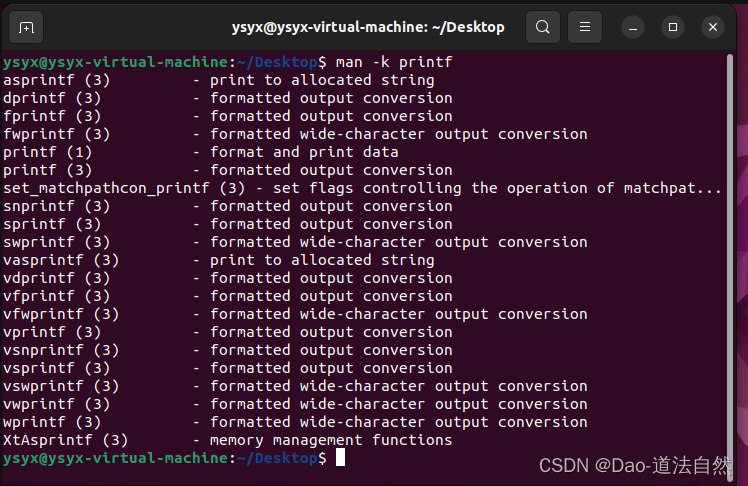
发现输出了很多和printf相关的命令或库函数, 括号里面的数字代表相应的条目属于manual的哪一个大类. 例如printf (1)是一个shell命令, 而printf (3)是一个库函数. 要访问库函数printf的manual page, 你需要在命令行中输入
man 3 printf控制字符
回车是指不向下前进,返回到当前行的行首。这个名字来自打印机的托架,因为在创造这个名字时显示器还很少见。这通常被转义为“\r”,缩写为 CR,并且具有 ASCII 值 13 或 0xD。
\r是回车并将光标向后移动,就像我会做的那样-
printf("stackoverflow\rnine")
ninekoverflow意味着它已将光标移至“stackoverflow”的开头并覆盖开始的四个字符,因为“nine”是四个字符长。
换行表示向下前进到下一行;然而,它已被重新调整用途并重新命名。用作“换行符”,它终止行(通常与分隔行混淆)。这通常被转义为“\n”,缩写为 LF 或 NL,并且具有 ASCII 值 10 或 0xA。CRLF(但不是 CRNL)用于“\r\n”对。
\n是新行字符,它更改行并将光标带到新行的开头,例如 -
printf("stackoverflow\nnine")
stackoverflow
nine换页意味着向下前进到下一个“页面”。它通常用作页面分隔符,但现在也用作部分分隔符。当您“插入分页符”时,文本编辑器可以使用此字符。这通常被转义为“\f”,缩写为 FF,并且具有 ASCII 值 12 或 0xC。
\f是换页符,它的使用已经过时,但它用于提供缩进,例如
printf("stackoverflow\fnine\fgreat")
stackoverflowninegreat统计代码行数
统计一个目录中(包含子目录)中的代码行数. 如果想知道当前目录下究竟有多少行的代码, 就可以在命令行中键入如下命令:
find . | grep '\.c$\|\.h$' | xargs wc -l如果用man find查看find操作的功能, 可以看到find是搜索目录中的文件. Linux中一个点.始终表示Shell当前所在的目录, 因此find .实际能够列出当前目录下的所有文件. 如果在文件很多的地方键入find ., 将会看到过多的文件, 此时可以按CTRL + c退出.
同样, 用man查看grep的功能——"print lines matching a pattern". grep实现了输入的过滤, 我们的grep有一个参数, 它能够匹配以.c或.h结束的文件.
连接起这两个命令的关键就是管道符号|. 这一符号的左右都是Shell命令, A | B的含义是创建两个进程A和B, 并将A进程的标准输出连接到B进程的标准输入. 这样, 将find和grep连接起来就能够筛选出当前目录(.)下所有以.c或.h结尾的文件.
我们最后的任务是统计这些文件所占用的总行数, 此时可以用man查看wc命令. wc命令的-l选项能够计算代码的行数. xargs命令十分特殊, 它能够将标准输入转换为参数, 传送给第一个参数所指定的程序. 所以, 代码中的xargs wc -l就等价于执行wc -l aaa.c bbb.c include/ccc.h ..., 最终完成代码行数统计.
统计磁盘使用情况
以下命令统计/usr/share目录下各个目录所占用的磁盘空间:
du -sc /usr/share/* | sort -nrdu是磁盘空间分析工具, du -sc将目录的大小顺次输出到标准输出, 继而通过管道传送给sort. sort是数据排序工具, 其中的选项-n表示按照数值进行排序, 而-r则表示从大到小输出. sort可以将这些参数连写在一起.
然而我们发现, /usr/share中的目录过多, 无法在一个屏幕内显示. 此时, 我们可以再使用一个命令: more或less.
du -sc /usr/share/* | sort -nr | more此时将会看到输出的前几行结果. more工具使用空格翻页, 并可以用q键在中途退出. less工具则更为强大, 不仅可以向下翻页, 还可以向上翻页, 同样使用q键退出.
在Linux下编写 Hello World 程序
Linux中用户的主目录是/home/用户名称, 如果你的用户名是user, 你的主目录就是/home/user. 用户的home目录可以用波浪符号~替代, 例如临时文件目录/home/user/Templates可以简写为~/Templates. 现在我们就可以进入主目录并编辑文件了. 如果Templates目录不存在, 可以通过mkdir命令创建它:
cd ~
mkdir Templates进入了正确的目录后, 输入相应的命令就能够开始编辑文件. 例如输入
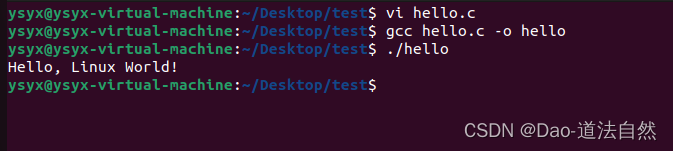
vi hello.c就能开启一个文件编辑. 例如可以键入如下代码(对于首次使用vi或emacs的同学, 键入代码可能会花去一些时间, 在编辑的同时要大量查看网络上的资料):
#include <stdio.h>
int main(void) {printf("Hello, Linux World!\n");return 0;
}保存后就能够看到hello.c的内容了. 终端中可以用cat hello.c查看代码的内容. 如果要将它编译, 可以使用gcc命令:
gcc hello.c -o hellogcc的-o选项指定了输出文件的名称, 如果将-o hello改为-o hi, 将会生成名为hi的可执行文件.
./hello 就能够运行改程序. 命令中的./是不能少的, 点代表了当前目录, 而./hello则表示当前目录下的hello文件. 与Windows不同, Linux系统默认情况下并不查找当前目录, 这是因为Linux下有大量的标准工具(如test等), 很容易与用户自己编写的程序重名, 不搜索当前目录消除了命令访问的歧义
使用重定向
有时我们希望将程序的输出信息保存到文件中, 方便以后查看. 例如你编译了一个程序myprog, 你可以使用以下命令对myprog进行反汇编, 并将反汇编的结果保存到output文件中:
objdump -d myprog > output>是标准输出重定向符号, 可以将前一命令的输出重定向到文件output中. 这样, 你就可以使用文本编辑工具查看output了.
但你会发现, 使用了输出重定向之后, 屏幕上就不会显示myprog输出的任何信息. 如果你希望输出到文件的同时也输出到屏幕上, 你可以使用tee命令:
objdump -d myprog | tee output使用输出重定向还能很方便地实现一些常用的功能, 例如
> empty # 创建一个名为empty的空文件
cat old_file > new_file # 将文件old_file复制一份, 新文件名为new_file如果myprog需要从键盘上读入大量数据(例如一个图的拓扑结构), 当你需要反复对myprog进行测试的时候, 你需要多次键入大量相同的数据. 为了避免这种无意义的重复键入, 你可以使用以下命令:
./myprog < data<是标准输入重定向符号, 可以将前一命令的输入重定向到文件data中. 这样, 你只需要将myprog读入的数据一次性输入到文件data中, myprog就会从文件data中读入数据, 节省了大量的时间.
下面给出了一个综合使用重定向的例子:
time ./myprog < data | tee output这个命令在运行myprog的同时, 指定其从文件data中读入数据, 并将其输出信息打印到屏幕和文件output中. time工具记录了这一过程所消耗的时间, 最后你会在屏幕上看到myprog运行所需要的时间. 如果你只关心myprog的运行时间, 你可以使用以下命令将myprog的输出过滤掉:
time ./myprog < data > /dev/null/dev/null是一个特殊的文件, 任何试图输出到它的信息都会被丢弃, 你能想到这是怎么实现的吗? 总之, 上面的命令将myprog的输出过滤掉, 保留了time的计时结果, 方便又整洁
使用Makefile管理工程
大规模的工程中通常含有几十甚至成百上千个源文件(Linux内核源码有25000+的源文件), 分别键入命令对它们进行编译是十分低效的. Linux提供了一个高效管理工程文件的工具: GNU Make. 我们首先从一个简单的例子开始, 考虑上文提到的Hello World的例子, 在hello.c所在目录下新建一个文件Makefile, 输入以下内容并保存:
hello:hello.cgcc hello.c -o hello # 注意开头的tab, 而不是空格.PHONY: cleanclean:rm hello # 注意开头的tab, 而不是空格返回命令行, 键入make, 你会发现make程序调用了gcc进行编译. Makefile文件由若干规则组成, 规则的格式一般如下:
目标文件名:依赖文件列表用于生成目标文件的命令序列 # 注意开头的tab, 而不是空格我们来解释一下上文中的hello规则. 这条规则告诉make程序, 需要生成的目标文件是hello, 它依赖于文件hello.c, 通过执行命令gcc hello.c -o hello来生成hello文件.
如果你连续多次执行make, 你会得到"文件已经是最新版本"的提示信息, 这是make程序智能管理的功能. 如果目标文件已经存在, 并且它比所有依赖文件都要"新", 用于生成目标的命令就不会被执行. 你能想到make程序是如何进行"新"和"旧"的判断的吗?
上面例子中的clean规则比较特殊, 它并不是用来生成一个名为clean的文件, 而是用于清除编译结果, 并且它不依赖于其它任何文件. make程序总是希望通过执行命令来生成目标, 但我们给出的命令rm hello并不是用来生成clean文件, 因此这样的命令总是会被执行. 你需要键入make clean命令来告诉make程序执行clean规则, 这是因为make默认执行在Makefile中文本序排在最前面的规则. 但如果很不幸地, 目录下已经存在了一个名为clean的文件, 执行make clean会得到"文件已经是最新版本"的提示. 解决这个问题的方法是在Makefile中加入一行PHONY: clean, 用于指示"clean是一个伪目标". 这样以后, make程序就不会判断目标文件的新旧, 伪目标相应的命令序列总是会被执行.
对于一个规模稍大一点的工程, Makefile文件还会使用变量, 函数, 调用Shell命令, 隐含规则等功能. 如果你希望学习如何更好地编写一个Makefile, 请到互联网上搜索相关资料
Unix哲学
- 每个程序只做一件事, 但做到极致
- 用程序之间的相互协作来解决复杂问题
- 每个程序都采用文本作为输入和输出, 这会使程序更易于使用
一个Linux老手可以用脚本完成各式各样的任务: 在日志中筛选想要的内容, 搭建一个临时HTTP服务器(核心是使用nc工具)等等. 功能齐全的标准工具使Linux成为工程师, 研究员和科学家的最佳搭档.
工具只是工具,学习工具最忌讳本末倒置!
正确学习工具使用观念:只要我们能想到的, 就一定有方便的办法能够办到. 因此当你想要完成某件事却又不知道应该做什么的时候, 请向Google求助.