WebGPT
- paper: WebGPT:Browser-assisted question-answering with human feedback
- Demo: https://openaipublic.blob.core.windows.net/webgpt-answer-viewer/index.html
webgpt的论文发表最早,但论文本身写的比较"高山仰止",可能先读完webcpm再来读webgpt,会更容易理解些,只看收集交互式搜索数据使用的界面,就会发现二者非常相似。
webgpt的问题以ELI5为主,混合了少量TriviaQA,AI2,手写问题等其他问题。搜索引擎也是使用了Bing API。和webcpm相同,为了避免直接找到答案简化搜索流程,webgpt过滤了Reddit,quora等类知乎的站点信息,提高任务难度。
多数细节和webcpm比较类似,最大的不同是webgpt除了使用指令微调,还加入了强化学习/拒绝采样的偏好打分方案。
数据收集
webgpt的数据收集分成两部分:
- Demonstrations:和webcpm的全流程搜索数据类似,从键入query,搜索,摘要,到问题回答,收集人类的交互数据,这里不再细说
- Comparison: 同一个query模型生成的两个回答的偏好数据,用于训练偏好模型。webgpt开源了这部分的数据
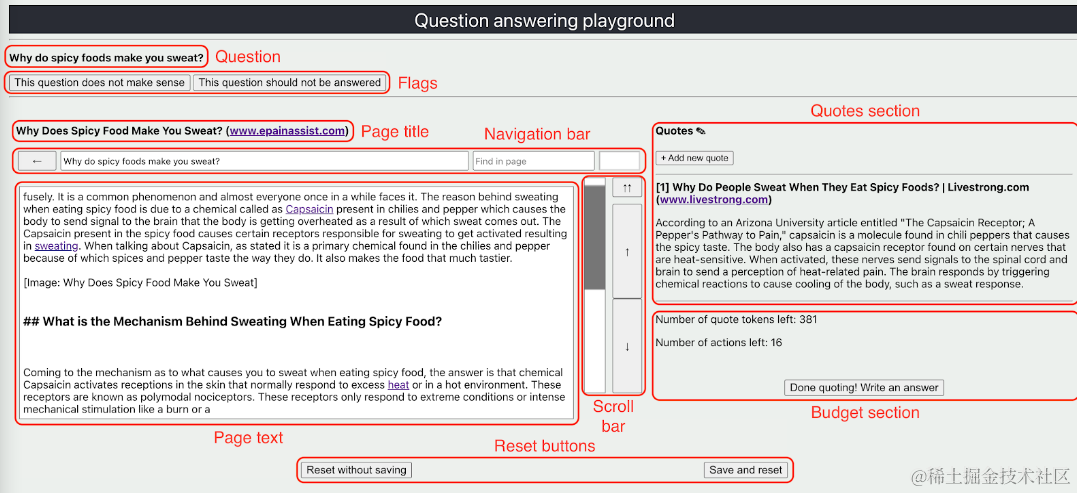
以下我们细说下Comparison的数据集构建。为了降低偏好标注的噪音,和人类偏好主观性的影响,webgpt只使用引用源来判断模型回答的优劣,具体标注步骤如下
- Flags:剔除不合理,争议性问题
- Trustworthiness:先对模型引用的数据源进行标注:分为Trustworthy,Netural, Suspicious三挡,区分不同网页的权威性和真实性
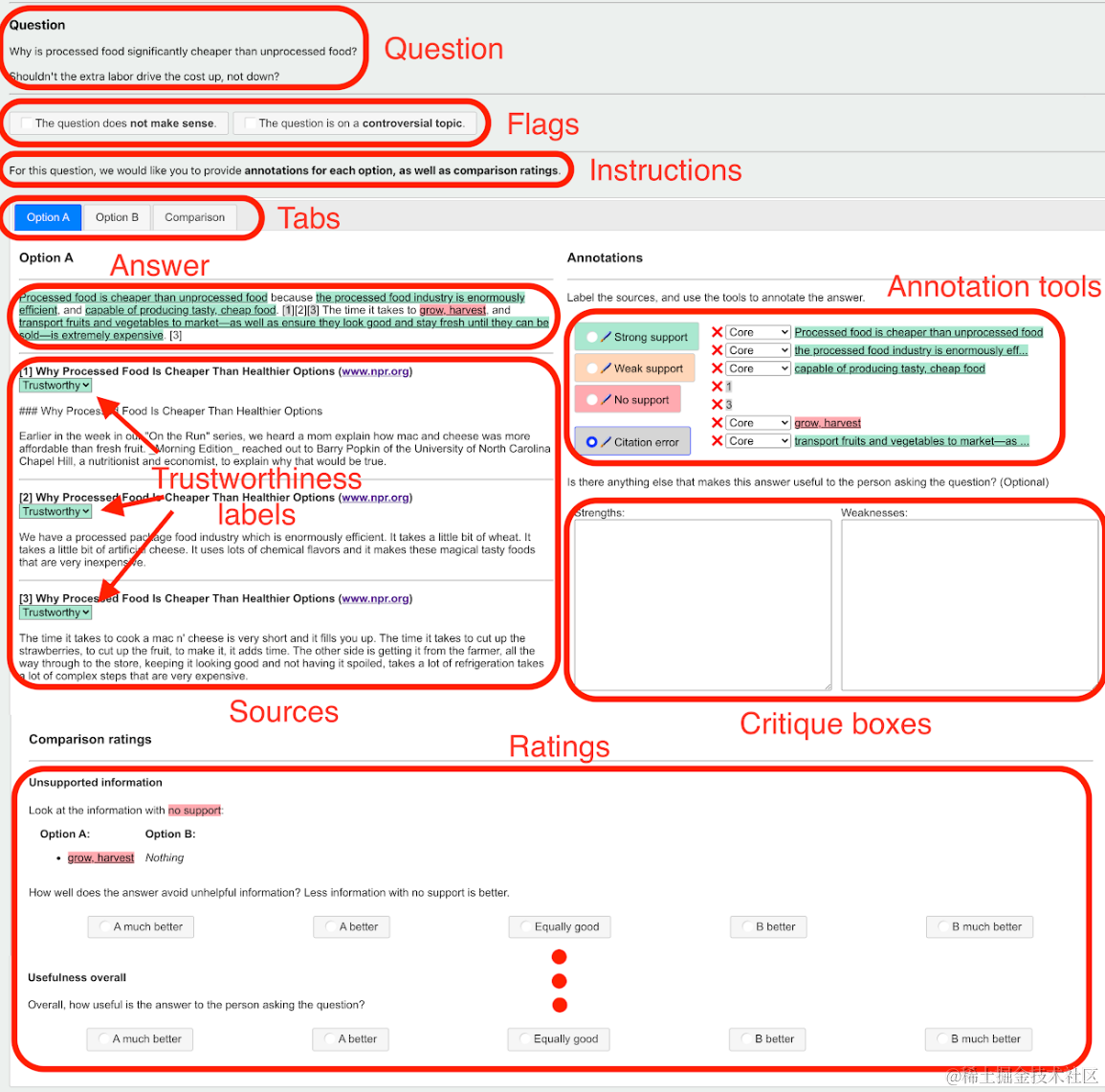
- Annotations:选定模型回答的每一个观点(高亮),根据该观点是否有引用支持,以及支持该观点的引用在以上的权威性分类中属于哪一档,来综合评价每个观点。也分为三挡strong support, weak support, no support。同时需要标注每个观点对于回答最终提问的重要性,有core,side,irrelevant三挡。
- Ratings:分别对模型采样生成的AB两个答案标注完以上3步之后,才到对比打分的环节。webgpt给出了很详细的如何综合每个观点的重要性和是否有支撑,对AB答案进行觉得打分,再对比两个打分得到相对打分,此处有无数人工智能中智能的人工…详见论文中的标注文档链接~
训练
对应上面的数据收集,webgpt的训练过程和InstructGPT基本是一致的。先使用Demonstration数据进行指令微调,论文称之为Behaviour Cloning,顾名思义模仿人类的搜索过程(BC)。再基于BC模型,使用Comparison对比数据训练偏好模型(RM)。最后基于偏好模型使用PPO算法微调BC模型得到强化微调后的模型(RL)。训练细节可以直接参考InstructGPT。
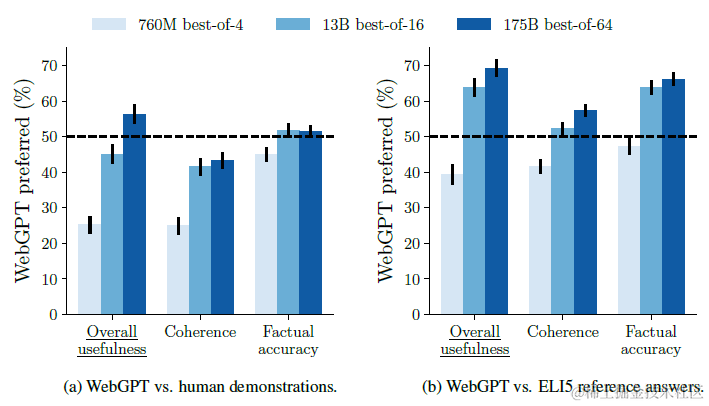
在解密Prompt7. 偏好对齐RLHF-OpenAI·DeepMind·Anthropic对比分析中我们讨论过强化学习的本质之一其实就是拒绝采样,论文也对比了使用BC/RL模型为基座,加入拒绝采样,随机采样4/16/64个模型回答,从中选取偏好模型打分最高的回答作为结果的方案。论文中效果最好的方案是BC+Best of 64拒绝采样。RL模型相比BC略有提升,但提升幅度没有拒绝采样来的高。
评估方案,论文把webgpt生成的结果,和Eli5数据集的原始结果(Reddit上的高赞答案),以及Demonstration中人工标注的答案进行偏好对比,让标注同学选择更偏好的答案。效果上,175B的微调模型,在64个回答中采样RM打分最高的答案,效果上是可以显著超越人工回答的。
WebGLM
- paper: WebGLM: Towards An Efficient Web-Enhanced Question Answering System with Human Preferences
- github: https://github.com/THUDM/WebGLM
webglm介于二者中间,是用google search api, 英文数据做的项目。整个项目数据集构建过程自动化程度更高,人工标注依赖更少,性价比更高一些。这里主要介绍数据集构建上的一些差异,架构和前两者差不多。
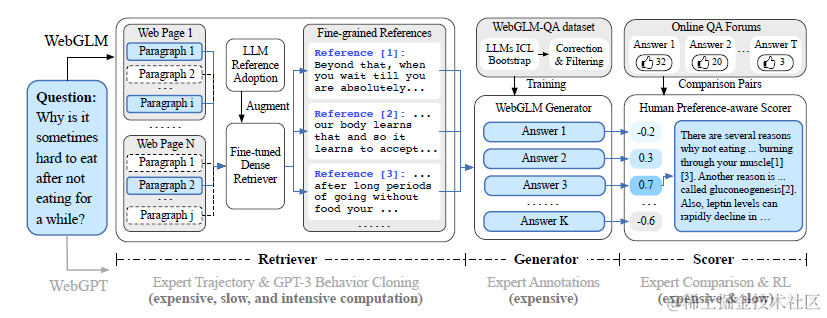
Retriever
和webcpm使用抽取的方案来定位网页内容中和qurery相关的部分不同,webglm采取了先对网页进行分段,然后每个段落和query计算相似度,通过相似度来筛选相关内容的方案。作者选取了基于对比学习的Contriever预训练模型,不过评估准确率只有不到70%。
因此这里使用大模型的阅读理解能力来补充构建了query*reference样本对。论文使用GPT-3 1-shot 。也就是给一个相关段落抽取的case,让大模型来从众多段落中筛选和query相关的。并对模型构建的样本集过滤query-reference相关度较低,大概率是模型发挥的低质量样本。
然后基于大模型构造的样本,使用query和reference embedding的内积作为相似度打分,微调目标是拟合相似度打分的MSE Loss。
synthesis
sysnthesis,也就是基于引用内容,大模型进行QA问答的部分,webglm使用davinci-003来进行样本生成, 这里主要包含四个步骤
- 大模型生成指令:这里作者使用了APE的方案,不熟悉的同学看这里# APE+SELF=自动化指令集构建代码实现。输入是Question+Refernce,输出是Answer, 问大模型,什么样的指令可以更好描述这类LFQA任务。大模型给出的指令是:Read the Refernces Provided and answer the corresponding question
- few-shot构造样本:基于生成的instruction,人工编写几个few-shot样本,给大模型更多的query+Reference,让davinci-003来构建推理样本
- 引用校准:论文发现模型生成结果存在引用内容正确,但是引用序号错误的情况,这里作者用Rouge-1进行相似度判断,校准引用的Reference。
- 样本过滤:再强的大模型也是模型,davinci-003造的样本质量参差不齐,部分模型会自己发挥。因此加入了质量过滤模块,主要过滤引用占比较低,引用太少,以及以上引用需要错误率较高的。
通过以上的生成+过滤,最终从模型生成的83K样本过滤得到45K质量更高的LFQA样本用于推理部分的模型微调
RM模型
webglm没有像webgpt一样使用人工标注对比偏好数据,而是使用线上QA论坛的点赞数据作为偏好数据,高赞的是正样本。并通过过滤掉回答较少的问题,对长文本进行截断,以及使用点赞数差异较大的回答构建对比样本对,等数据预处理逻辑,得到质量相对较高,偏好差异较大,长度相对无偏的偏好样本。整体量级是93K个问题,249K个样本对。
其实现在大模型的样本构建往往有两种方案,一个是高质量小样本,另一个就是中低质量大样本,前者直接告诉模型如何做,后者是在质量参差不齐的样本中不断求同存异中让模型抽取共性特征。webglm是后者,而webgpt是前者。
其次RL的初始模型,对标以上webgpt的BC模型。在之前RL的博客中我们有提到过,初始模型需要是有能力生成人类偏好答案的对齐后的模型。这里webglm直接使用Reddit的摘要数据,通过指令微调得到,也没有使用人工标注数据,考虑摘要任务也属于阅读理解的子任务。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


![[职场] 会计学专业学什么 #其他#知识分享#职场发展](https://img-blog.csdnimg.cn/img_convert/8b7b90170669d1244af867a4e03cf6d5.jpeg)