Q1. What is Levenshtein Algorithm?
Levenshtein算法,也称为编辑距离算法,是一种量化两个字符串之间差异的方法。它通过计算将一个字符串转换成另一个字符串所需的最少单字符编辑操作次数来实现。这些编辑操作包括插入、删除和替换字符。Levenshtein距离越小,意味着两个字符串越相似;反之,距离越大,则两者越不相似。
例如,将“kitten”转换为“sitting”的Levenshtein距离为3,具体操作如下:
- k -> s (替换 'k' 为 's')
- e -> i (替换 'e' 为 'i')
- 在末尾插入 'g'
Levenshtein算法在多种领域有着广泛的应用,包括拼写检查、生物信息学中的DNA序列比对、自然语言处理中的词语相似性度量,以及任何需要衡量文本相似度的场景。此算法的一个关键特点是它考虑了字符串的所有可能编辑操作,从而提供了一个全面的相似度度量。
Levenshtein distance is a string metric for measuring the difference between two sequences. The Levenshtein distance between two words is the minimum number of single-character edits (i.e. insertions, deletions or substitutions) required to change one word into the other.
By Mathematically, the Levenshtein distance between the two strings a, b (of length |a| and |b| respectively) is given by the leva, b( |a| , |b| ) where :
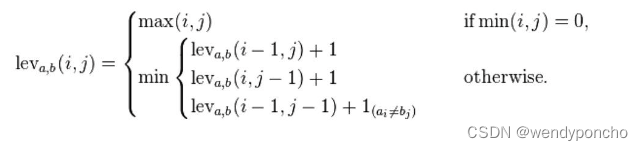
Where, 1 (ai≠bi): This is the indicator function equal to zero when ai≠bi and equal to 1 otherwise, and leva, b(i,j) is the distance between the first i characters of a and the first j characters of b.
Example:
The Levenshtein distance between "HONDA" and "HYUNDAI" is 3, since the following three edits change one into the other, and there is no way to do it with fewer than three edits:
Q2. What is Soundex?
Soundex attempts to find similar names or homophones using phonetic notation. The program retains letters according to detailed equations, to match individual titles for purposes of ample volume research.
Soundex是一种将单词转换为代表其发音的编码系统,主要用于英语。它旨在将同音异字(即发音相同或相似,但拼写不同的单词)编码为相同的表示形式。Soundex最常见的应用是在人名的相似性匹配中,特别是在基因学研究、人口普查数据处理和数据库搜索中,用于处理拼写变体和拼写错误。
Soundex编码的基本规则如下:
- 保留首字母:单词的首字母保持不变,作为Soundex编码的第一个字符。
- 数字代替辅音:接下来的辅音字母根据其发音被转换为数字。通常,相似发音的字母被赋予相同的数字。元音(A, E, I, O, U, H, W, Y)通常被忽略,除非它是单词的首字母。
- 相同数字合并:连续的相同数字会被合并为一个数字。
- 删除非首位的元音和某些辅音:非首字母位置的元音和某些特定辅音(如H和W)通常在编码过程中被忽略。
- 固定长度:Soundex编码通常固定为四个字符,首字母后跟三个数字。不足的用0补齐,过长的则截断。
例如,"Smith"和"Smyth"都会被编码为S530。
Soundex算法简单但有效,尽管它有局限性,比如对于非英语单词和某些复杂发音的处理不够准确。尽管如此,Soundex仍然是人名相似性匹配和音位编码领域的一种重要工具。
Soundex phonetic algorithm: Its indexes strings depend on their English pronunciation. The algorithm is used to describe homophones, words that are pronounced the same, but spelt differently.
Suppose we have the following sourceDF.

Let’s summarize the above results:
-
"two" and "to" both are encoded as T000
-
"break" and "brake" both are encoded as B620
-
"hear" and "here" both are encoded as H600
-
"free" is encoded as F600 and "tree" is encoded as T600: Encodings are similar, but word is different
The Soundex algorithm was often used to compare first names that were spelt differently.
Q3. What is Constituency parse?
成分句法分析(Constituency Parsing),也称为短语结构分析,是自然语言处理(NLP)中的一种方法,用于分析句子的句法结构,将句子分解成其组成部分。这些组成部分是作为句子中单个单位功能的短语。这些成分通常通过一种树状结构表示,称为句法树或解析树,其中每个节点代表一个成分(如名词短语、动词短语等),边代表它们之间的句法关系。
句法树的根通常代表整个句子,树的不同层次代表句子结构的不同层面。例如,一个简单句子可能被分解成主语(名词短语)和谓语(动词短语),而这些短语又可以进一步细分为更小的成分,如定语、宾语等。
成分句法分析的目标是揭示句子的深层句法结构,这对于理解句子的意义、进行句子的自动翻译、信息提取等任务至关重要。成分句法分析是自然语言处理和计算语言学领域的基本任务之一,它为深入理解自然语言提供了重要的句法信息。
A constituency parse tree breaks a text into sub-phrases. Non-terminals in the tree are types of phrases, the terminals are the words in the sentence, and the edges are unlabeled. For a simple sentence, "John sees Bill", a constituency parse would be:
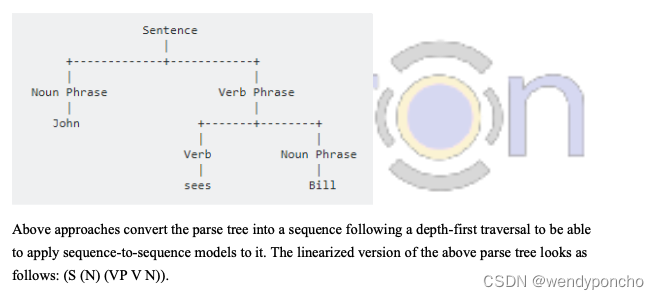
Q4. What is LDA(Latent Dirichlet Allocation)?
隐含狄利克雷分配(Latent Dirichlet Allocation,简称LDA)是一种自然语言处理和文本挖掘中广泛使用的主题模型。它是一种无监督学习技术,用于发现文档集合中的隐含主题。LDA基于这样的假设:每篇文档可以被视为一系列主题的混合,而每个主题则由一组词汇构成。
在LDA模型中,每个文档被认为是从一个潜在的主题集合中随机生成的,其中每个主题又是由一系列词汇的分布来定义的。LDA的目标是确定文档中主题的分布以及主题内词汇的分布,从而揭示文档集合中的主题结构。
LDA的核心组成部分包括:
- 文档中的主题分布:每篇文档都被假设为由多个主题组成,其中每个主题在文档中的比重不同。
- 主题中的词汇分布:每个主题都与特定的词汇分布相关联,这决定了某一主题下特定词汇出现的概率。
- 狄利克雷分布(Dirichlet Distribution):LDA假设文档中的主题分布和每个主题中的词汇分布都遵循狄利克雷分布,这是一种连续多变量概率分布,常用于表达组成比例的不确定性。
通过LDA模型,研究者可以识别出文档集合中的潜在主题,并了解不同文档与这些主题的关联程度。LDA广泛应用于文档分类、信息检索、内容推荐系统以及对大规模文本数据的主题趋势分析等领域。
LDA: It is used to classify text in the document to a specific topic. LDA builds a topic per document model and words per topic model, modelled as Dirichlet distributions.
-
Each document is modeled as a distribution of topics, and each topic is modelled as multinomial distribution of words.
-
LDA assumes that every chunk of text we feed into it will contain words that are somehow related. Therefore choosing the right corpus of data is crucial.
-
It also assumes documents are produced from a mixture of topics. Those topics then generate words based on their probability distribution.
The Bayesian version of PLSA is LDA. It uses Dirichlet priors for the word-topic and document- topic distributions, lending itself to better generalization.
What LDA give us?
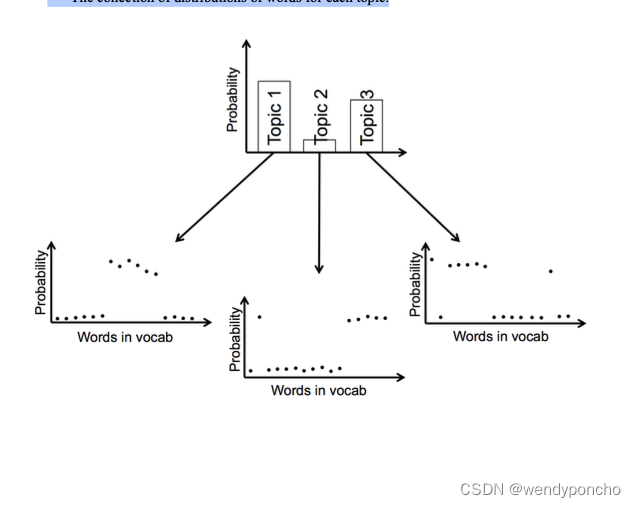
It is a probabilistic method. For every document, the results give us a mixture of topics that make up the document. To be precise, we can get probability distribution over the k topics for every document. Every word in the document is attributed to the particular topic with probability given by distribution.
These topics themselves were defined as probability distributions over vocabulary. Our results are two sets of probability distributions:
-
The collection of distributions of topics for each document
-
The collection of distributions of words for each topic.
Q5.What is LSA?
潜在语义分析(Latent Semantic Analysis,简称LSA)是一种自然语言处理和信息检索中使用的技术,用于分析文档集合和词汇之间的关系。LSA的核心思想是通过将词汇和文档映射到一个由潜在概念构成的较低维度的语义空间中,揭示词汇和文档之间的隐含语义结构。
LSA通常涉及以下步骤:
-
构建词-文档矩阵:首先创建一个大型矩阵,其中每一行代表一个唯一的词汇,每一列代表一个文档,矩阵中的每个元素表示该词在相应文档中的出现频率或权重。
-
矩阵分解:使用奇异值分解(Singular Value Decomposition,SVD)技术对词-文档矩阵进行分解。SVD是一种线性代数技术,可以将原始矩阵分解为三个矩阵的乘积,揭示潜在的语义结构。
-
降维:通过保留SVD分解结果中的前k个最大奇异值及其对应的奇异向量,实现将词汇和文档映射到一个较低维度的语义空间。这个过程有助于去除噪音和冗余信息,突出重要的语义特征。
-
语义解释:在降维后的语义空间中,文档和词汇通过它们在潜在语义维度上的位置关联起来,相似的词汇和文档在语义空间中距离更近。
LSA的应用包括但不限于文档相似性分析、文本聚类、信息检索、文档分类以及自动文摘。尽管LSA在揭示词汇和文档之间的隐含关系方面非常有效,但它也有局限性,如对多义词和同义词的处理不足,以及难以解释降维后的潜在维度的具体语义含义。
Latent Semantic Analysis (LSA): It is a theory and the method for extract and represents the contextual usage meaning of words by statistical computation applied to large corpus of texts.
It is an information retrieval technique which analyzes and identifies the pattern in an unstructured collection of text and relationship between them.
Latent Semantic Analysis itself is an unsupervised way of uncovering synonyms in a collection of documents.
Why LSA(Latent Semantic Analysis)?
LSA is a technique for creating vector representation of the document. Having a vector representation of the document gives us a way to compare documents for their similarity by calculating the distance between vectors. In turn, means we can do handy things such as classify documents to find out which of a set knows topics they most likely reside to.
Classification implies we have some known topics that we want to group documents into, and that you have some labelled training data. If you're going to identify natural groupings of the documents without any labelled data, you can use clustering
Q6. What is PLSA?
PLSA stands for Probabilistic Latent Semantic Analysis, uses a probabilistic method instead of SVD to tackle problem. The main idea is to find the probabilistic model with latent topics that we can generate data we observe in our document term matrix. Specifically, we want a model P(D, W) such that for any document d and word w, P(d,w) corresponds to that entry in document-term matrix.
Each document is found in the mixture of topics, and each topic consists of the collection of words. PLSA adds the probabilistic spin to these assumptions:
-
Given document d, topic z is available in that document with the probability P(z|d)
-
Given the topic z, word w is drawn from z with probability P(w|z)

概率潜在语义分析(Probabilistic Latent Semantic Analysis,简称PLSA),也称为概率潜在语义索引(Probabilistic Latent Semantic Indexing,PLSI),是一种统计模型,用于分析文档和词汇之间的关系,特别是用于发现文档集合中的潜在主题。PLSA是潜在语义分析(LSA)的概率扩展,它通过概率模型而不是线性代数技术(如LSA中的奇异值分解)来揭示文档和词汇之间的隐含语义结构。
PLSA的核心思想是假设存在一定数量的潜在主题,每个文档表示为这些潜在主题的混合,而每个主题则通过一组特定的词汇分布来表征。模型的目标是从给定的文档-词汇数据中学习潜在主题的表示,以及每个文档对这些主题的分布。
PLSA的关键组成部分包括:
-
潜在主题:PLSA模型中的每个潜在主题都与一个概率分布相关联,该分布定义了在该主题下每个词汇出现的概率。
-
文档-主题分布:每个文档通过一个概率分布与潜在主题相关联,这个分布指定了构成该文档的各个主题的比例。
-
词汇-主题分布:每个主题都通过一个概率分布与词汇相关联,这个分布定义了在该主题下各个词汇的出现概率。
PLSA通过极大似然估计或期望最大化(EM)算法来估计模型参数,从而最大化观察到的文档-词汇数据的似然概率。
PLSA在文档分类、信息检索、文本聚类以及推荐系统等领域有广泛应用。与LSA相比,PLSA提供了一种更加灵活和直接的方式来建模文档和词汇之间的概率关系,但它也面临过拟合和可扩展性的挑战,特别是在处理大规模数据集时。隐含狄利克雷分配(LDA)模型后来作为PLSA的一个扩展被提出,以解决这些问题。
Q7. What is LDA2Vec?
LDA2Vec是一种结合了隐含狄利克雷分配(LDA)和Word2Vec的自然语言处理模型,旨在结合LDA的主题建模能力和Word2Vec的词嵌入技术。通过这种结合,LDA2Vec不仅能够捕捉词汇的语义信息,即词汇之间的相似性,还能揭示文本数据中的潜在主题结构。
It is inspired by LDA, word2vec model is expanded to simultaneously learn word, document, topic and paragraph topic vectors.
Lda2vec is obtained by modifying the skip-gram word2vec variant. In the original skip-gram method, the model is trained to predict context words based on a pivot word. In lda2vec, the pivot word vector and a document vector are added to obtain a context vector. This context vector is then used to predict context words.
Word2Vec是一种预测模型,用于生成词汇的向量表示,这些向量能够捕捉到丰富的语义关系和词汇之间的相似性。而LDA是一种主题模型,用于从文档集合中发现潜在的主题,并描述文档中主题的分布情况。
LDA2Vec的核心思想包括:
-
词嵌入:LDA2Vec利用类似Word2Vec的机制生成词嵌入,这些嵌入捕捉了词汇的语义信息,即在向量空间中,语义相似的词汇会被映射到相近的位置。
-
文档-主题嵌入:LDA2Vec将文档表示为主题的混合,其中每个主题也通过嵌入来表示,反映了该主题下词汇的分布特征。
-
结合词嵌入和主题嵌入:LDA2Vec通过优化模型,以使得词嵌入不仅反映词汇之间的语义相似性,也与其所属主题的嵌入相协调。
LDA2Vec的优势在于它能够提供更为丰富的文本表示,既包含了词汇的细粒度语义信息,也包括了文档级别的主题信息。这种双重表示使得LDA2Vec在文本分类、主题发现、文本相似性度量以及信息检索等任务中表现出色。然而,与所有深度学习模型一样,LDA2Vec的训练需要大量的数据和计算资源,并且模型的解释性可能不如传统的LDA模型。
At the document level, we know how to represent the text as mixtures of topics. At the word-level, we typically used something like word2vec to obtain vector representations. It is an extension of word2vec and LDA that jointly learns word, document, and topic vectors.
How does it work?
It correctly builds on top of the skip-gram model of word2vec to generate word vectors. Neural net that learns word embedding by trying to use input word to predict enclosing context words.
With Lda2vec, other than using the word vector directly to predict context words, you leverage a context vector to make the predictions. Context vector is created as the sum of two other vectors: the word vector and the document vector.
The same skip-gram word2vec model generates the word vector. The document vector is most impressive. It is a really weighted combination of two other components:
-
the document weight vector, representing the “weights” of each topic in a document
-
Topic matrix represents each topic and its corresponding vector embedding.
Together, a document vector and word vector generate “context” vectors for each word in a document. lda2vec power lies in the fact that it not only learns word embeddings for words; it simultaneously learns topic representations and document representations as well.
Q8. What is Expectation-Maximization Algorithm(EM)?
The Expectation-Maximization Algorithm, in short, EM algorithm, is an approach for maximum likelihood estimation in the presence of latent variables.
This algorithm is an iterative approach that cycles between two modes. The first mode attempts to predict the missing or latent variables called the estimation-step or E-step. The second mode attempts to optimise the parameters of the model to explain the data best called the maximization-step or M- step.
-
E-Step. Estimate the missing variables in the dataset.
-
M-Step. Maximize the parameters of the model in the presence of the data.
The EM algorithm can be applied quite widely, although it is perhaps most well known in machine learning for use in unsupervised learning problems, such as density estimation and clustering.
For detail explanation of EM is, let us first consider this example. Say that we are in a school, and interested to learn the height distribution of female and male students in the school. The most sensible thing to do, as we probably would agree with me, is to randomly take a sample of N students of both genders, collect their height information and estimate the mean and standard deviation for male and female separately by way of maximum likelihood method.
Now say that you are not able to know the gender of student while we collect their height information, and so there are two things you have to guess/estimate: (1) whether the individual sample of height information belongs to a male or a female and (2) the parameters (μ, θ) for each gender which is now unobservable. This is tricky because only with the knowledge of who belongs to which group, can we make reasonable estimates of the group parameters separately. Similarly, only if we know the parameters that define the groups, can we assign a subject properly. How do you break out of this infinite loop? Well, EM algorithm just says to start with initial random guesses.
期望最大化算法(Expectation-Maximization Algorithm,简称EM算法)是一种迭代优化算法,用于含有隐变量(潜在变量)的概率模型参数估计问题。EM算法在统计学、机器学习、数据挖掘和自然语言处理等领域有广泛应用,特别适用于模型参数不完全可观测或存在缺失数据的情况。
EM算法的核心思想是通过迭代执行两个步骤来逐步提高似然函数的估计值:
-
E步骤(Expectation Step):在给定当前参数估计的情况下,计算隐变量的条件期望。这一步相当于根据现有的参数估计,计算隐变量的期望值,以揭示数据的隐含结构。
-
M步骤(Maximization Step):根据E步骤得到的隐变量期望,更新模型参数以最大化似然函数。这一步通过优化期望值来更新参数估计,以提高模型对观测数据的拟合度。
EM算法通过反复迭代这两个步骤,直到达到某个停止准则,如参数的变化小于某个阈值或达到最大迭代次数。每次迭代都保证了似然函数的值不会减少,最终EM算法会收敛到局部最优解。
EM算法的优点是框架清晰、应用广泛,能够有效处理含有隐变量的复杂模型,如高斯混合模型、隐马尔可夫模型(HMM)和各种主题模型(如PLSA、LDA)。然而,EM算法也有其局限性,例如可能收敛到局部最优而非全局最优,且收敛速度有时候较慢。此外,EM算法的效果很大程度上依赖于初始参数的选择。
Q9.What is Text classification in NLP?
Text classification is also known as text tagging or text categorization is a process of categorizing text into organized groups. By using NLP, text classification can automatically analyze text and then assign a set of pre-defined tags or categories based on content.
文本分类是自然语言处理(NLP)中的一个核心任务,涉及将文本数据(如文档、邮件、网页内容等)自动分配给一个或多个预定义类别或标签。这个过程依赖于文本的内容和语义信息,目的是让机器能够理解文本并据此做出分类决策。
文本分类的应用非常广泛,包括但不限于:
- 情感分析:判断文本表达的情绪倾向,如正面、负面或中性。
- 垃圾邮件检测:识别和过滤电子邮件中的垃圾邮件。
- 主题分类:将新闻文章、博客帖子等按照主题进行分类,如政治、体育、科技等。
- 意图识别:在对话系统中识别用户的意图,如询问、命令、请求等。
Unstructured text is everywhere on the internet, such as emails, chat conversations, websites, and the social media but it’s hard to extract value from given data unless it’s organized in a certain way. Doing so used to be a difficult and expensive process since it required spending time and resources to manually sort the data or creating handcrafted rules that are difficult to maintain. Text classifiers with NLP have proven to be a great alternative to structure textual data in a fast, cost-effective, and scalable way.
Text classification is becoming an increasingly important part of businesses as it allows us to get insights from data and automate business processes quickly. Some of the mostcommon examples and the use cases for automatic text classification include the following:
-
Sentiment Analysis: It is the process of understanding if a given text is talking positively or negatively about a given subject (e.g. for brand monitoring purposes).
-
Topic Detection: In this, the task of identifying the theme or topic of a piece of text (e.g. know if a product review is about Ease of Use, Customer Support, or Pricing when analysing customer feedback).
-
Language Detection: the procedure of detecting the language of a given text (e.g. know if an incoming support ticket is written in English or Spanish for automatically routing tickets to the appropriate team).
文本分类的过程通常包括以下几个步骤:
- 预处理:对原始文本进行处理,包括去除停用词、词干提取、词形还原等,以减少噪声并减小词汇量。
- 特征提取:将文本转换为机器学习模型可以处理的格式,常用的方法有词袋模型(Bag of Words)、TF-IDF(Term Frequency-Inverse Document Frequency)、词嵌入(Word Embeddings)等。
- 模型训练:使用标注数据训练分类模型,常见的机器学习算法包括朴素贝叶斯、支持向量机(SVM)、随机森林、以及深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)。
- 评估和优化:使用测试数据评估模型的性能,如准确率、召回率和F1分数等指标,并根据结果调整模型参数以优化性能。
随着深度学习技术的发展,基于深度神经网络的文本分类模型,如BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer),已成为该领域的前沿技术,它们能够更好地捕捉文本的语义信息,从而提高分类的准确性和效率。
Q10. What is Word Sense Disambiguation (WSD)?
WSD (Word Sense Disambiguation) is a solution to the ambiguity which arises due to different meaning of words in a different context.
词义消歧(Word Sense Disambiguation,WSD)是自然语言处理(NLP)中的一个重要任务,旨在确定多义词在特定上下文中的确切含义。多义词是指那些具有两个或多个含义的词汇,而词义消歧就是在给定的上下文中识别出这些词汇正确的含义。
例如,英文单词“bank”在不同的上下文中可以指“银行”或“河岸”。如果句子是“我在河边的bank钓鱼”,则“bank”应该被理解为“河岸”;而在“我需要去bank取钱”的上下文中,“bank”则指的是“银行”。
词义消歧的挑战在于语言的复杂性和歧义性,同一个词在不同的语境中可能代表完全不同的概念。有效的词义消歧对于许多NLP应用都至关重要,包括机器翻译、信息检索、问答系统和文本理解等。
词义消歧的方法大致可以分为基于规则的方法、基于监督学习的方法和基于知识的方法:
- 基于规则的方法:依赖手工编写的规则来识别上下文中的线索,判断词义。
- 基于监督学习的方法:利用带有正确词义标注的训练数据来训练模型,然后用训练好的模型对新的上下文中的词义进行预测。
- 基于知识的方法:依赖外部知识库(如WordNet)中的信息来推断词义。这些方法通常利用词义之间的语义关系,如同义词、上下位关系等,来辅助消歧。
随着深度学习的发展,基于上下文的词嵌入技术(如ELMo、BERT等)为词义消歧提供了新的解决方案,这些模型能够捕捉到词汇在不同上下文中的细微语义差异,从而提高消歧的准确性。
In natural language processing, word sense disambiguation (WSD) is the problem of determining which "sense" (meaning) of a word is activated by the use of the word in a particular context, a process which appears to be mostly unconscious in people. WSD is the natural classification problem: Given a word and its possible senses, as defined by the dictionary, classify an occurrence of the word in the context into one or more of its sense classes. The features of the context (such as the neighbouring words) provide the evidence for classification.
For example, consider these two below sentences.
“ The bank will not be accepting the cash on Saturdays. ” “ The river overflowed the bank .”
The word “ bank “ in the given sentence refers to commercial (finance) banks, while in the second sentence, it refers to a riverbank. The uncertainty that arises, due to this is tough for the machine to detect and resolve. Detection of change is the first issue and fixing it and displaying the correct output is the second issue.
将Levenshtein算法(编辑距离)、Soundex算法、成分句法分析、LDA(隐含狄利克雷分配)、LSA(潜在语义分析)、PLSA(概率潜在语义分析)和词义消歧(WSD)这些概念融合,我们可以构建一个综合性的自然语言处理(NLP)系统,该系统能够深入理解和处理文本数据。这个系统可以如下设计:
-
文本预处理:利用Levenshtein算法纠正拼写错误,提高文本质量。同时,Soundex算法可以帮助系统处理同音异字,确保词汇的正确理解。
-
句法和语义分析:通过成分句法分析,系统可以理解句子的结构和组成部分,如名词短语和动词短语等。这为深入的语义理解奠定基础。
-
主题和语义建模:LDA用于从文本集合中发现潜在主题,而LSA和PLSA通过矩阵分解和概率模型揭示文档和词汇之间的潜在语义关系。这些方法共同帮助系统捕捉文本数据中的高级语义信息和主题结构。
-
词义消歧:WSD确保多义词在特定上下文中被正确理解,这对于文本的精确处理和分析至关重要。






![BUUCTF misc 专题(47)[SWPU2019]神奇的二维码](https://img-blog.csdnimg.cn/f5b4278a7ed54b81b250d6807299e460.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAdHRfbnBj,size_20,color_FFFFFF,t_70,g_se,x_16)
