在微调时,模型显存占用主要包括模型参数、参数梯度、优化器和中间结果四个部分。
对于一个 6B 参数量的模型,它的模型参数占用为:

将模型参数视为基准,模型梯度占用量与模型参数相同。
优化器主采用 Adam Optimizer ,它核心计算公式如下:
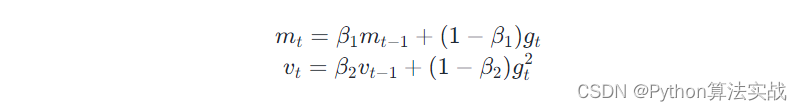 由于需要保存 m 和 v,而 m 和 v 规模与参数梯度相同,因此优化器需要两倍显存容量。
由于需要保存 m 和 v,而 m 和 v 规模与参数梯度相同,因此优化器需要两倍显存容量。
同时,在计算中得到的中间结果需要保存在显存中,以便反向传播时计算梯度。 对于每一个中间结果,其数据形状为 [Batch, SeqLen, Dim]。
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远.
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
GPU 显存分析

Collective Operations
为了节省显存,可以将模型或者数据分配到不同的显卡上,显卡之间有如下几种 Collective Operations
Broadcast

The Broadcast operation copies an N-element buffer on the root rank to all ranks.
广播操作将一张显卡上数据广播到所有显卡。
AllReduce、Reduce、ReduceScatter



The AllReduce operation is performing reductions on data (for example, sum, min, max) across devices and writing the result in the receive buffers of every rank.
The Reduce operation is performing the same operation as AllReduce, but writes the result only in the receive buffers of a specified root rank.
The ReduceScatter operation performs the same operation as the Reduce operation, except the result is scattered in equal blocks between ranks, each rank getting a chunk of data based on its rank index.
AllReduce 操作将所有显卡上数据进行聚合如求和、取最大值或取最小值,并将结果写入所有显卡。
Reduce 只会将结果写入一张显卡。
ReduceScatter 则将结果分散在所有显卡中。
AllGather

The AllGather operation gathers N values from k ranks into an output of size k*N, and distributes that result to all ranks.
AllGather 操作会收集所有显卡数据,并写入所有显卡中。
数据并行
数据并行是将数据分成若干份,装载到不同节点上进行计算。

数据并行计算流程如下:
- 有个参数服务器保存模型参数。
- 参数被复制到不同的设备中,构成若干 replicas。每个 replica 处理一部分数据,进行前向传播和反向传播。
- 每个设备得到梯度进行 Reduce 操作,得到最终梯度,并按照这个梯度更新参数服务器中的模型参数。
- 在后向传播时,每计算完一层的梯度,就可以进行 Reduce 操作,提高并行性。
分布式数据并行

分布式数据并行中不存在参数服务器,其计算流程如下:
- 每个 replica 都保存模型参数,但是分别计算部分数据,进行前向传播和反向传播。
- 每个设备都得到梯度后进行 AllReduce 操作,将梯度写入所有设备,每个设备根据自己的优化器和梯度更新参数。
分布式数据并行中,每个设备显存占用情况如图:

其中每个设备仍需要保存模型参数、梯度和优化器参数。
模型并行
由于模型越来越大,单个设备保存模型参数、梯度和优化器越来越难。因为深度学习主要是矩阵计算,而矩阵计算可以分块计算,因此可以将模型参数拆成若干份,每份单独计算,以减少显存占用。
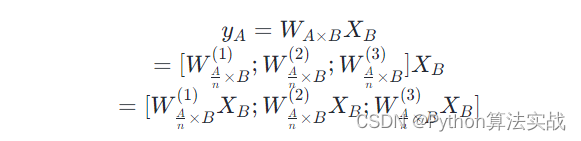

其计算流程如下:
- 将参数矩阵分成若干子矩阵,分发到不同设备中。
- 每个设备计算不同矩阵,然后将结果收集起来。
模型并行后,显存占用如下:

由于每个设备处理所有数据,因此中间结果都会保存在所有设备中。
ZeRO
在分布式数据并行中,最后梯度更新在不同设备进行的操作相同,多个设备中参数相同,梯度相同,优化器状态相同,存在大量冗余。
ZeRO-1 对优化器状态进行分片。

ZeRO-1 计算流程如下:
- 每个 replica 处理一部分数据输入。
- 独立进行前向传播。
- 独立进行反向传播。
- 得到完整梯度后进行 ReduceScatter,每个 replica 得到对应梯度。
- 每个 replica 更新梯度对应的部分参数。
- 使用 AllGather 同步更新所有参数。
ZeRO-2 计算流程与1基本相同,ZeRO-2在后向传播时,每计算一层梯度,就可以使用 ReduceScatter 进行同步,提高并行度。同时由于不需要完整计算梯度之后进行 ReduceScatter,每个 replica 只需要保存部分梯度即可。
ZeRO-3 在 2 的基础上,将模型参数进行分片。

ZeRO-3 计算流程如下:
- 每个 replica 处理一部分输入。
- 前向传播时,当需要别的层参数,使用 AllGather 获取。
- 反向传播时,当需要别的层参数时,使用 AllGather 获取,同时计算出每一层梯度时,使用 ReduceScatter 分发到对应 replica。
- 每个 replica 用于部分优化器参数和梯度,进行对应参数更新。
不同 ZeRO 对应的显存占用情况:

流水线并行
将模型一层一层分开,不同层放入不同 GPU 进行计算。个人理解与模型并行不同的是,模型并行保留从头到尾每一层的部分参数,输入可以计算出结果。流水线并行需要等前一层计算完毕才能进行计算。

流水线并行显存分析:

混合精度
FP16 相较于 FP32 计算更快,同时占用更少的显存。但同时 FP16 表示的范围小,可能产生溢出错误。
特别的,在权重更新时 gradient * lr 导致下溢出。
混合精度训练的思路在优化器中保留一份 FP32 格式的参数副本,而模型权重、梯度等数据在训练中都是用 FP16 来存储。

优化器中参数更新在 FP32 格式下保证精度,之后转换为 FP16 格式。
Checkpointing
由于模型反向传播需要中间结果计算梯度,大量中间结果占用大量显存。
Checkpointing 思路是保存部分隐藏层的结果(作为检查点),其余的中间结果直接释放。当反向传播需要计算梯度时,从检查点开始重新前向传播计算中间结果,得到梯度后再次释放。