1.为什么要用线程池?
**1.降低资源消耗,**复用已创建的线程来降低创建和销毁线程的消耗。
2.提高响应速度,任务到达时,可以不需要等待线程的创建立即执行。
3.提高线程的可管理性,使用线程池能够统一的分配、调优和监控。
2.线程池的概述:
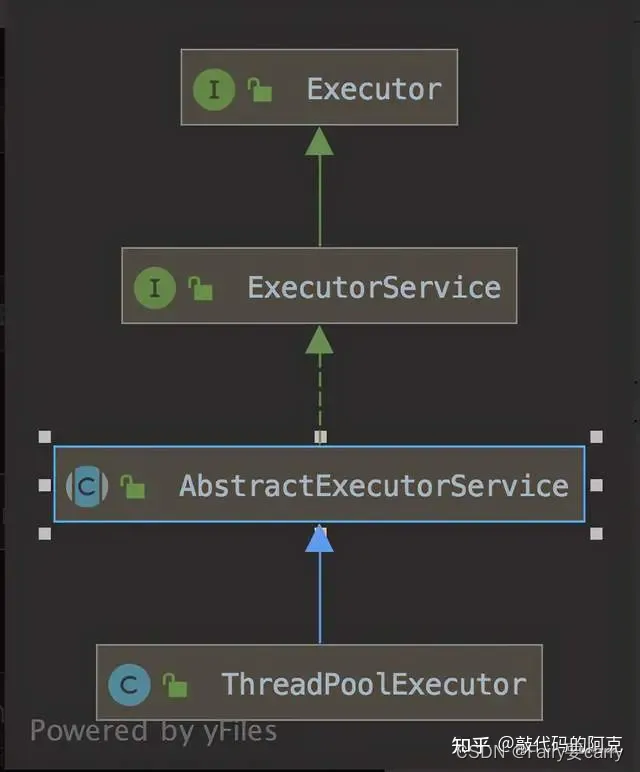
Java中线程池的核心实现类是ThreadPoolExecutor,可以通过该类地构造方法来构造一个线程池,我们先来看下ThreadPoolExecutor的整个继承体系
我们可以通过ThreadPoolExecutor去构造一个线程池
**Executor接口:**提供了将任务的执行和线程的创建以及使用解耦开来的抽象
ExecutorService接口继承了Executor接口,在Executor的基础上,增加了一些关于管理线程池本身的一些方法,比如查看任务的状态、stop/terminal线程池、获取线程池的状态等等。
3.ThreadPoolExcutor的组成
1.corePoolSize:,核心线程数量,决定是否创建新的线程来处理到来的任务
2.maximumPoolSize:,最大线程数量,线程池中允许创建线程地最大数量
3.keepAliveTime:,线程空闲时存活的时间
4.unit:,空闲存活时间单位
5.workQueue:,任务队列,用于存放已提交的任务
6.threadFactory:,线程工厂,用于创建线程执行任务
7.handler:,拒绝策略,当线程池处于饱和时,使用某种策略来拒绝任务提交
重点讲下几个拒绝策略:
1😗*AbortPolicy,**抛出异常,让用户可根据具体任务来做出具体的判断
2😗*DiscardPolicy,**什么也不做,直接丢弃任务
3😗*DiscardOldestPolicy,**将阻塞队列中的任务poll出来,然后执行当前任务
4:CallerRunsPolicy,让提交任务的线程来执行任务
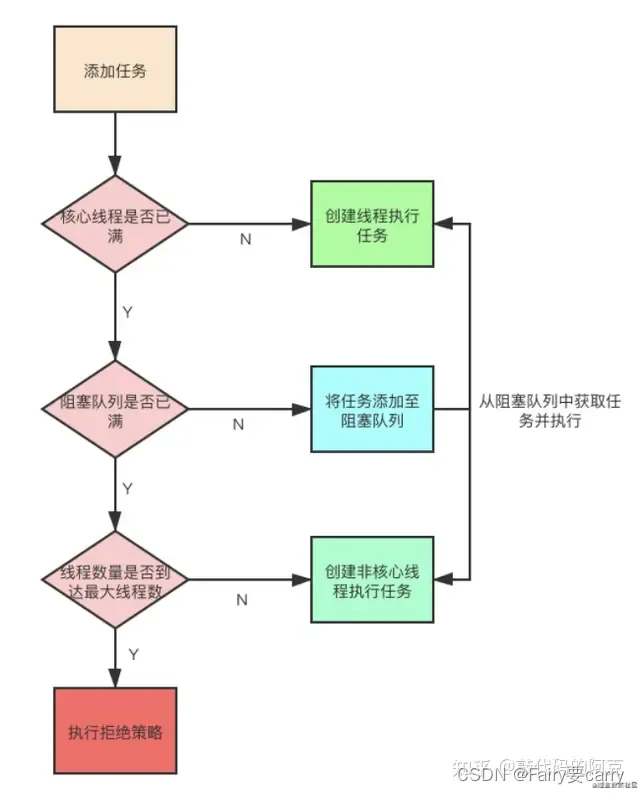
3.1执行流程:
1)如果workerCount < corePoolSize ==> 创建线程执行提交的任务
2)如果workerCount >= corePoolSize && 阻塞队列未满 ==> 添加至阻塞队列,等待后续线程来执行提交地任务
3)如果workerCount >= corePoolSize && workerCount < maxinumPoolSize && 阻塞队列已满 ==> 创建非核心线程执行提交的任务
4)如果workerCount >= maxinumPoolSize && 阻塞队列已满 ==> 执行拒绝策略
4.线程池的几种状态:

5.自定义线程工厂,给线程池与线程统一管理
根据不同的线程池,设置名称,方便管理线程,以及设置他们的名称,当出现异常时,方便定位排查问题
package com.wyh.subject.domain.config;import org.apache.commons.lang3.StringUtils;import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;/*** 自定义线程工厂:1.用于生成具有自定义名称、优先级的线程。* 1.它实现了ThreadFactory接口,并提供了一个构造函数来设置线程名称的前缀。* 2.通过调用newThread方法,可以创建一个新的线程,并设置线程的相关属性,例如线程组、名称、优先级等。这个自定义线程工厂可以在使用线程池时,为线程提供更加可读性和可管理性的名称。*/
public class CustomNameThreadFactory implements ThreadFactory {// 定义一个线程池数量的静态变量,用于生成线程池的序号private static final AtomicInteger poolNumber = new AtomicInteger(1);/*** 线程组的主要作用有:** 1.统一管理和控制:将多个线程归为一个组,可以方便地对这些线程进行批量操作,例如挂起、恢复、中断等。* 2.设置优先级:线程组可以设置一个默认的优先级,所有在该组中创建的线程都将继承这个优先级。* 3.监控状态:通过线程组,可以方便地监控该组中的所有线程的状态和运行情况,从而更加精细地调整程序的运行效率。*/private final ThreadGroup group;// 定义一个线程数量的静态变量,用于生成线程的序号private final AtomicInteger threadNumber = new AtomicInteger(1);// 定义一个线程名称的前缀private final String namePrefix;// 构造函数,接受一个线程名称作为参数public CustomNameThreadFactory(String name) {// 获取当前线程的安全管理器SecurityManager s = System.getSecurityManager();// 如果存在安全管理器,则将当前线程的线程组设置为安全管理器的线程组group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup();// 如果没有提供线程名称,则使用默认名称 "pool"if (StringUtils.isBlank(name)) {name = "pool";}// 将线程名称的前缀设置为提供的名称和当前线程池的序号namePrefix = name + "-" + poolNumber.getAndIncrement() + "-thread-";}// 重写 newThread() 方法,用于生成具有自定义名称的线程@Overridepublic Thread newThread(Runnable r) {// 创建一个新线程Thread t = new Thread(group, r, namePrefix + threadNumber.getAndIncrement(), 0);// 如果新线程是守护线程,则将其设置为非守护线程if (t.isDaemon()) {t.setDaemon(false);}// 如果新线程的优先级不为常规优先级,则将其设置为常规优先级if (t.getPriority() != Thread.NORM_PRIORITY) {t.setPriority(Thread.NORM_PRIORITY);}// 返回新线程return t;}}
6.如何确定线程池的线程数
1.公式:
CPU核心线程数目标CPU利用率(1+w/c)

2.例子:
如果我期望目标利用率为90%(多核90),那么需要的线程数为:
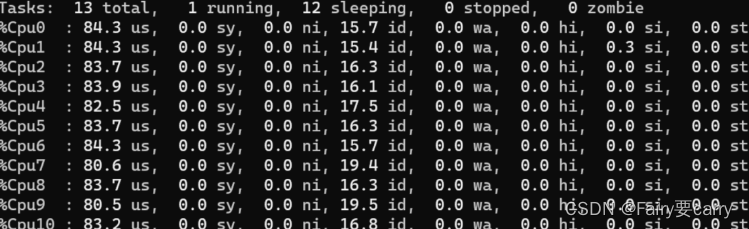
核心数12 * 利用率0.9 * (1 + 50(sleep时间)/50(循环50_000_000耗时)) ≈ 22
现在把线程数调到22,看看结果:
3.但是,所以受环境干扰下,单靠公式很难准确的规划线程数,一定要通过测试来验证。
- 析当前主机上,有没有其他进程干扰(比如其他框架或者库中里面封的线程池)
- 分析当前JVM进程上,有没有其他运行中或可能运行的线程
- 设定目标
- 目标CPU利用率 - 我最高能容忍我的CPU飙到多少?
- 目标GC频率/暂停时间 - 多线程执行后,GC频率会增高,最大能容忍到什么频率,每次暂停时间多少?
因为线程数一增加,系统资源的竞争就会增加,CPU的竞争就会增加,那么就会影响GC的效率,无法获取充分的资源 - 执行效率 - 比如批处理时,我单位时间内要开多少线程才能及时处理完毕
- ……
- 梳理链路关键点,是否有卡脖子的点,因为如果线程数过多,链路上某些节点资源有限可能会导致大量的线程在等待资源(比如三方接口限流,连接池数量有限,RPC调用,中间件压力过大无法支撑等)
- 不断的增加/减少线程数来测试,按最高的要求去测试,最终获得一个“满足要求”的线程数**
所以,我们需要分析以上情况才能真正确定所需线程数
4.策略:
1.逐步增加/减少:首先可以通过逐步增加或减少线程数的方式来测试系统的性能和指标变化。具体来说,可以从一个较小的线程数量开始,逐渐增加线程数,直到达到目标要求或者性能受到影响;或者从一个较大的线程数量开始,逐渐减少线程数,直到达到目标要求或者性能受到影响。这种方法可以帮助找到最优的线程数。
2.监控工具:使用多种监控工具,包括JVM自带的jstat、jconsole、jvisualvm,以及第三方工具如VisualVM、YourKit等,收集系统性能数据,分析线程数对系统性能的影响。去直观地查看线程数、CPU 使用率、内存占用等指标,帮助实时监控系统性能,并调整线程数以优化性能