工作场景
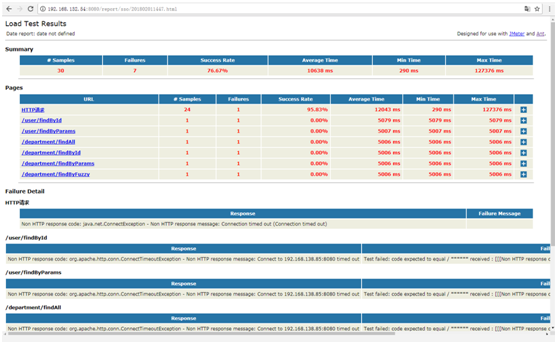
本次我们开发了一个新功能,为了验证它是否合理,我们需要从线上导出一批真实的用户数据来进行模拟请求,以此来验证功能的完整性。
例如一个很简单的功能,我们是一个对学生成绩进行数据分析的系统,各学校会将学生成绩作为原始数据导入并保存在我们的后台管理系统。我们新增了一个在导入过程中通过某些学科成绩计算指标的功能(功能不做具体解析)。
导出文件格式
假设我们从后台导出的csv文件格式如下: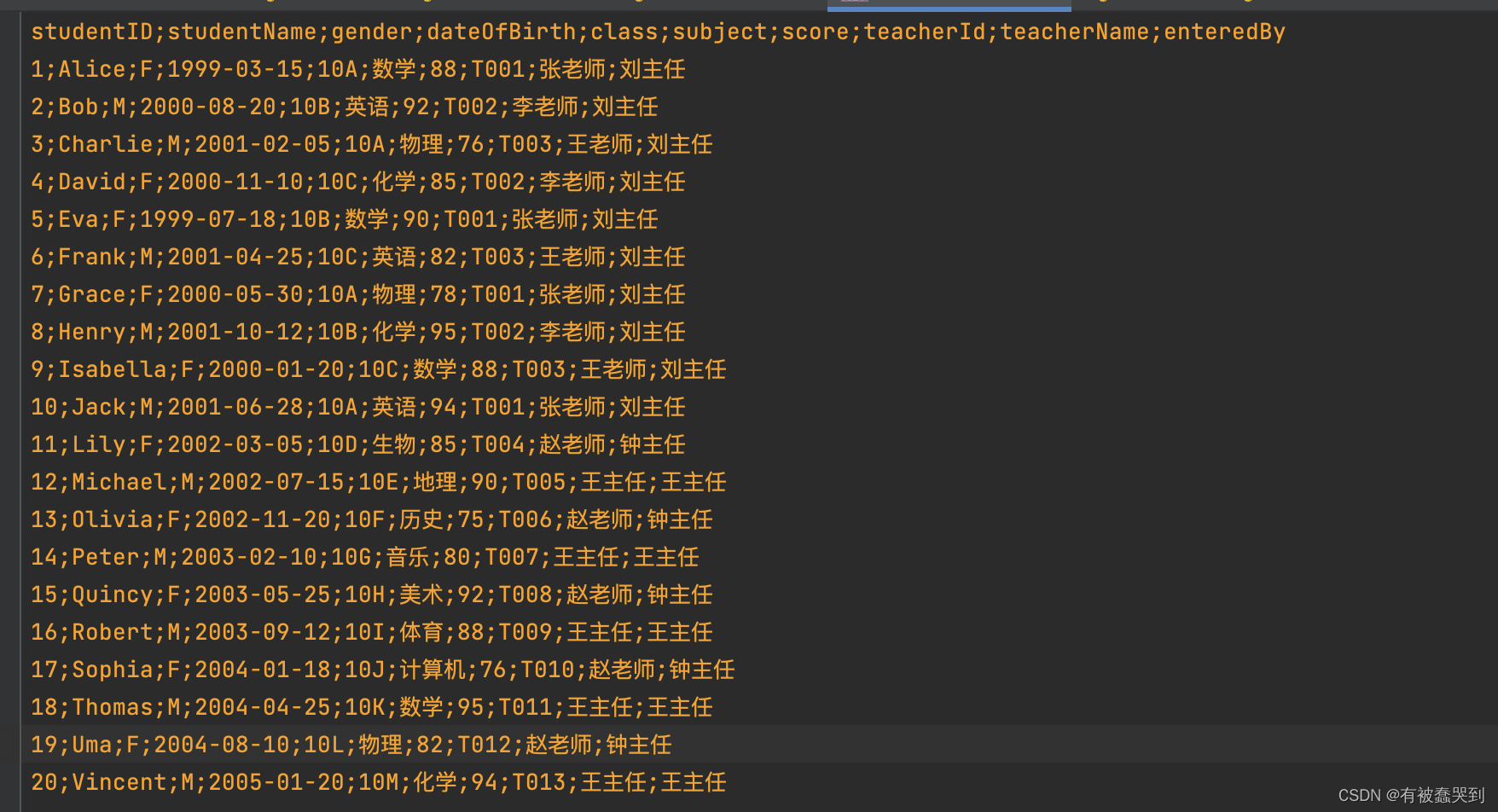
studentID;studentName;gender;dateOfBirth;class;subject;score;teacherId;teacherName;enteredBy
1;Alice;F;1999-03-15;10A;数学;88;T001;张老师;刘主任
2;Bob;M;2000-08-20;10B;英语;92;T002;李老师;刘主任
3;Charlie;M;2001-02-05;10A;物理;76;T003;王老师;刘主任
4;David;F;2000-11-10;10C;化学;85;T002;李老师;刘主任
5;Eva;F;1999-07-18;10B;数学;90;T001;张老师;刘主任
6;Frank;M;2001-04-25;10C;英语;82;T003;王老师;刘主任
7;Grace;F;2000-05-30;10A;物理;78;T001;张老师;刘主任
8;Henry;M;2001-10-12;10B;化学;95;T002;李老师;刘主任
9;Isabella;F;2000-01-20;10C;数学;88;T003;王老师;刘主任
10;Jack;M;2001-06-28;10A;英语;94;T001;张老师;刘主任
11;Lily;F;2002-03-05;10D;生物;85;T004;赵老师;钟主任
12;Michael;M;2002-07-15;10E;地理;90;T005;王主任;王主任
13;Olivia;F;2002-11-20;10F;历史;75;T006;赵老师;钟主任
14;Peter;M;2003-02-10;10G;音乐;80;T007;王主任;王主任
15;Quincy;F;2003-05-25;10H;美术;92;T008;赵老师;钟主任
16;Robert;M;2003-09-12;10I;体育;88;T009;王主任;王主任
17;Sophia;F;2004-01-18;10J;计算机;76;T010;赵老师;钟主任
18;Thomas;M;2004-04-25;10K;数学;95;T011;王主任;王主任
19;Uma;F;2004-08-10;10L;物理;82;T012;赵老师;钟主任
20;Vincent;M;2005-01-20;10M;化学;94;T013;王主任;王主任
接口请求格式
假设我们接口的请求格式如下:
{"enteredBy": "刘主任","studentScoreDetails":[{"studentID": 1,"studentName": "Alice","dateOfBirth": "1999-03-15","score": 88,"gender": "F","subject": "数学","class": "10A","teacherName": "张老师"}]
}
解决方案
注意我们这里需要大量数据来验证,所以请放弃一个一个自己组装的想法,要合理运用工具
- 首先我们先观察我们的csv文件格式,是用
;分隔的,且一行有10条数据,所以我们在读取数据时,还需要过滤无效数据
# 读取 CSV 文件
csv_file = 'studentScore.csv' # 替换为你的文件路径# 初始化一个空列表来保存有效的数据行
valid_lines = []# 打开文件,跳过第一行列名读取并处理数据
with open(csv_file, 'r', encoding='utf-8') as file:for i, line in enumerate(file):if i == 0: # 跳过第一行,即列名行continueline = line.strip()# 按分号分割行数据parts = line.split(';')# 如果数据行有 10 个字段,即有效行,保存到列表中if len(parts) == 10:valid_lines.append(parts)
- 导入pandas库,将已经处理好的数据列表(valid_lines)转换为Pandas的DataFrame对象,valid_lines列表中的每个元素(也就是每个列表)都将作为DataFrame的一行。–
DataFrame是Pandas库中用于存储和操作表格数据的主要数据结构,它类似于一个二维的、大小可变的、有标签的数据结构,可以容纳许多不同类型的数据。
# 创建 DataFrame
data = pd.DataFrame(valid_lines, columns=['studentID', 'studentName', 'gender', 'dateOfBirth', 'class','subject', 'score', 'teacherId', 'teacherName', 'enteredBy'])
- 过滤掉我们不需要的列,并处理一部分列,比如teacherId
# 选择所需的列
selected_columns = ['studentID', 'studentName', 'gender', 'dateOfBirth', 'class','subject', 'score', 'teacherName', 'enteredBy']data = data[selected_columns]# 将日期字符串转换为日期对象
data['dateOfBirth'] = pd.to_datetime(data['dateOfBirth'], format='%Y-%m-%d', errors='coerce')
# 将Score转换为数字
data['score'] = pd.to_numeric(data['score'], errors='coerce')
- 按照成绩录入人进行分组
# 按照 成绩录入人 进行分组
grouped = data.groupby('enteredBy')
5.组装json文件
# 根据成绩录入人进行遍历,生成 JSON 数据并保存到文件
for enteredBy, group in grouped:studentScoreDetails = []for index, row in group.iterrows():studentScoreDetail = {"studentID": row['studentID'],"dateOfBirth": row['dateOfBirth'].strftime('%Y-%m-%d') if not pd.isnull(row['dateOfBirth']) else None,"studentName": row['studentName'],"score": float(row['score']),"gender": row['gender'],"subject": row['subject'],"class": row['class'],"teacherName": row['teacherName']}studentScoreDetails.append(studentScoreDetail)json_data = {"enteredBy": enteredBy, # 使用处理后的 成绩录入人"studentScoreDetails": studentScoreDetails}
6.保存结果到文件
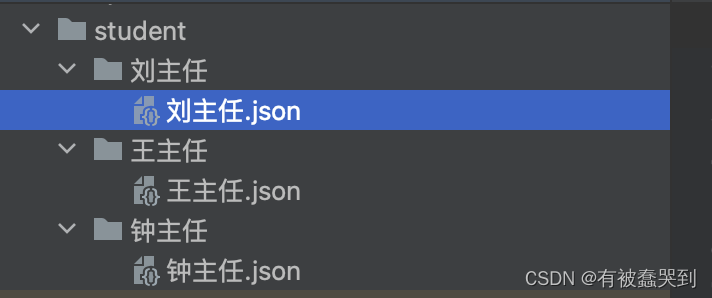
# 创建一个目录用户保存数据output_dir = 'student'folder_path = os.path.join(output_dir, f'{enteredBy}') # 不同的录入人命名josn文件os.makedirs(folder_path, exist_ok=True) # 创建输出目录和子目录,如果它们已经存在则不会引发错误# 保存 JSON 请求数据到对应录入人目录output_file = os.path.join(folder_path, f'{enteredBy}.json')with open(output_file, 'w', encoding='utf-8') as file:json.dump(json_data, file, indent=4, ensure_ascii=False)print(f"{enteredBy}录入数据保存成功")
-
运行代码,最终我们就能得到按不同录入人进行分组的请求文件数据
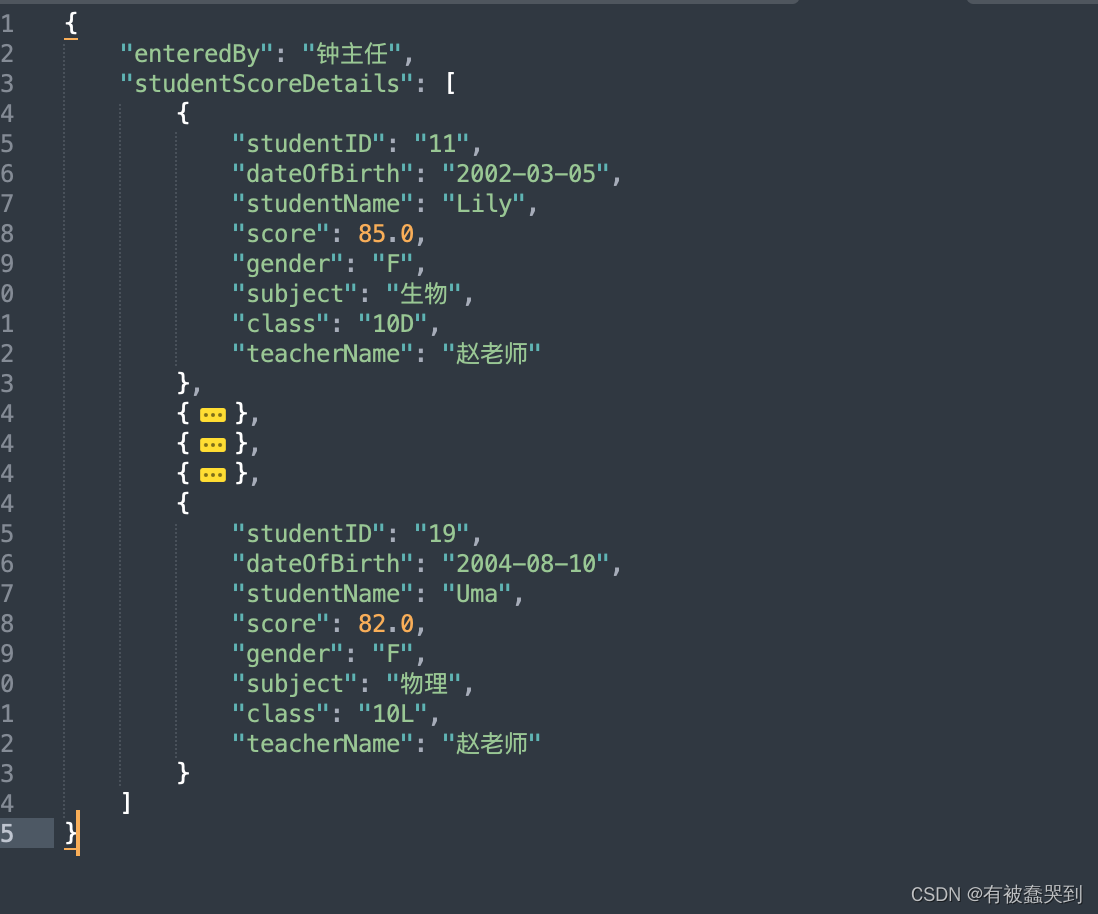
-
然后就可以用这些现成的请求数据直接调接口来验证我们的功能啦,是不是节省了我们很多时间,这里只是举了一个例子,处理方法都差不多,只是数据不一样,大家举一反三拿自己的业务练习练习吧,感谢观看。