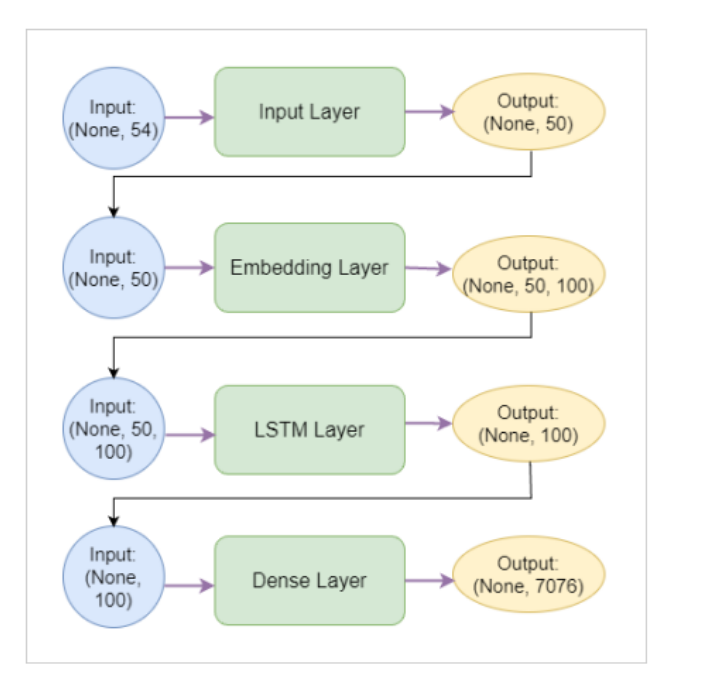
Es数据格式和Mysql对比
ElasticSearch index(索引) Type(类型) Documents(文档) Fields(字段)
MySQL Databases(数据库) Table(表) Row(行) Column(列)
倒排索引
正向索引,在Mysql中使用的索引就是正排索引,索引对应的就是直接的数据
例子:
id content
1 my name is zhangsan
2 my name is lisi
倒排索引,是关键字关联主键ID,ID在去查找文章内容,一个倒排索引是由不同的关键字组成的索引库
强调的是关键字与id的关联
keyword id
name 1,2
zhangsan 1
使用ES
ES基础操作
在ES中,创建Index就相当于创建mysql中的Database
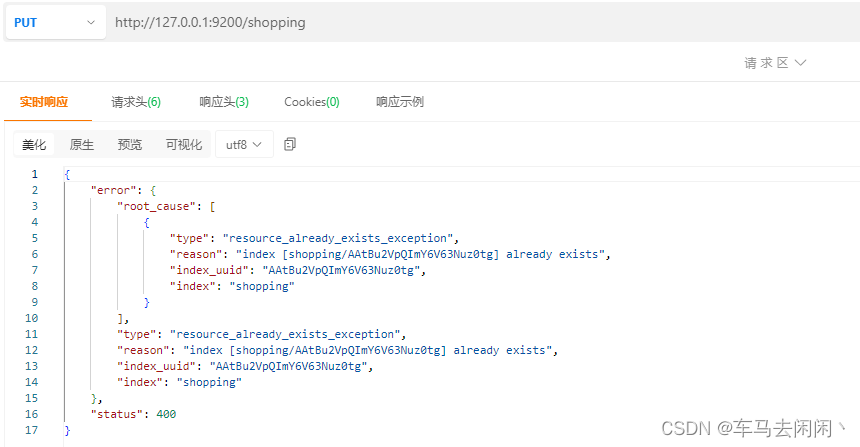
在PsotMan中,向ES服务器发送PUT请求:http://127.0.0.1:9200/shopping
相当与在ES服务器中创建了一个shoppping的数据库
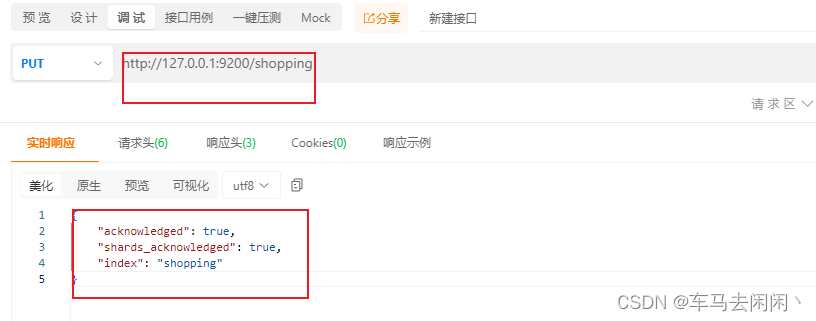
我们的请求是以后幂等性的,在次发送相同的请求的时候,会报错
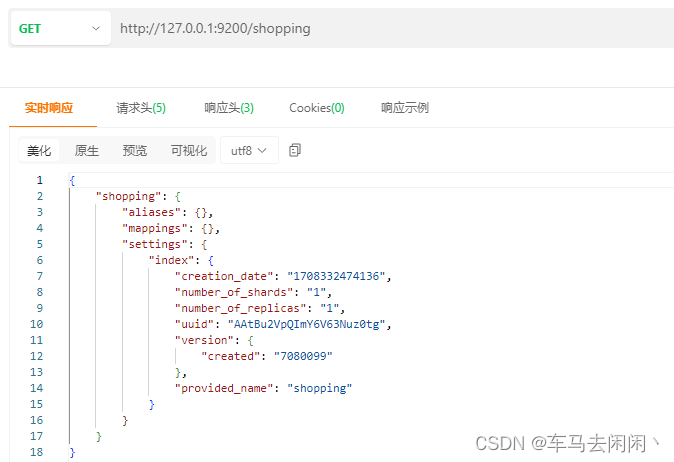
获取索引的相关信息
使用Get进行请求
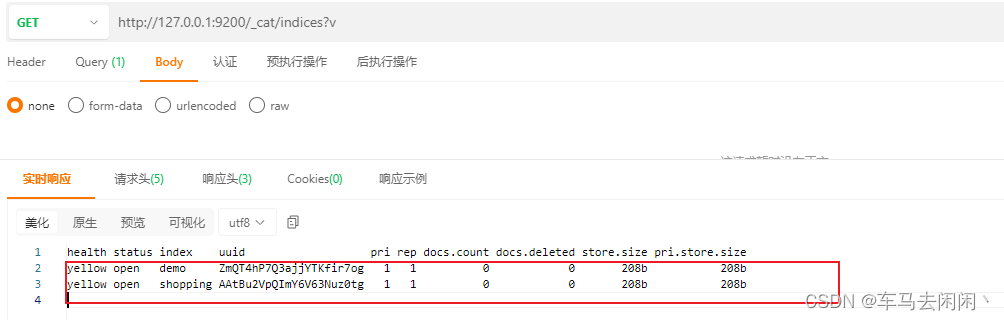
获取所有的索引信息,使用Get进行请求下面的路径
http://127.0.0.1:9200/_cat/indices?v
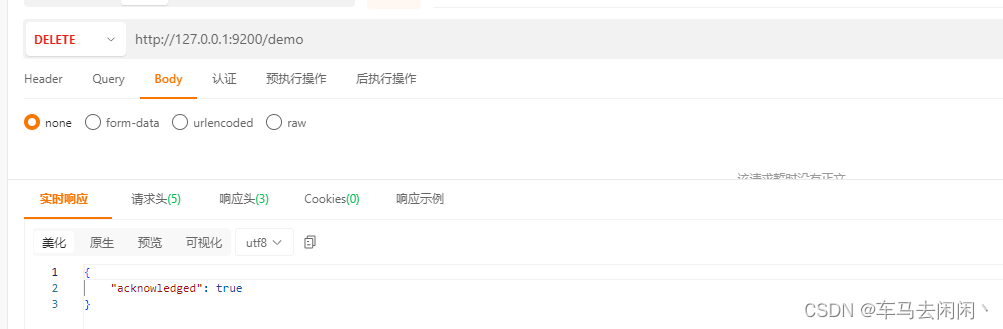
删除索引
使用delete进行请求
http://127.0.0.1:9200/demo
添加数据
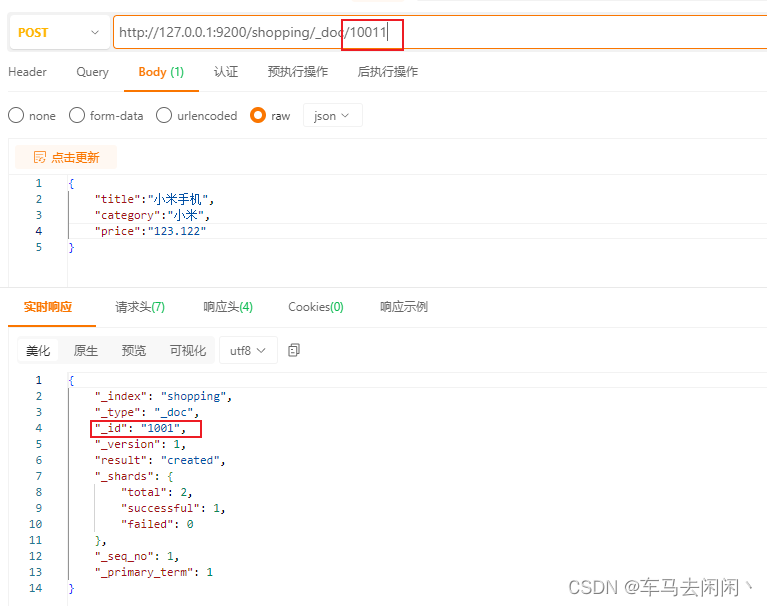
因为在后面的版本中是没有type的概念的,所以添加数据是直接在索引中添加数据,只能使用POST进行插入,再返回的数据中有一个_id,这个id是作为唯一性存储的
两个新增的命令是相同的
http://127.0.0.1:9200/shopping/_doc
http://127.0.0.1:9200/shopping/_create
此路径说明是要向shopping的索引中添加数据,_doc是添加文档,添加的数据格式是JSON格式

添加自定义ID
只需要在_doc后面添加指定的ID即可
主键查询
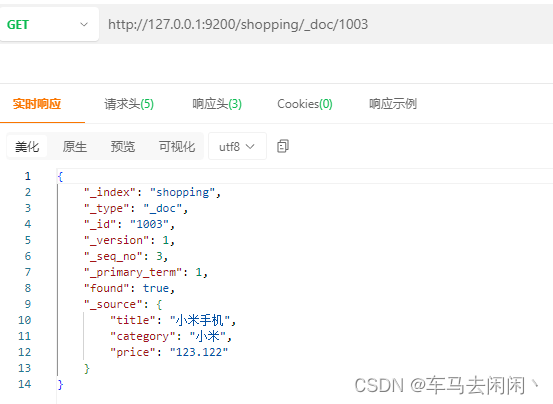
使用Get进行主键查询,在_doc后面添加主键ID,即可查询当前主键的内容,source中的内容就是doc的内容,在关系型数据库中就相当于查询了一行
http://127.0.0.1:9200/shopping/_doc/1003
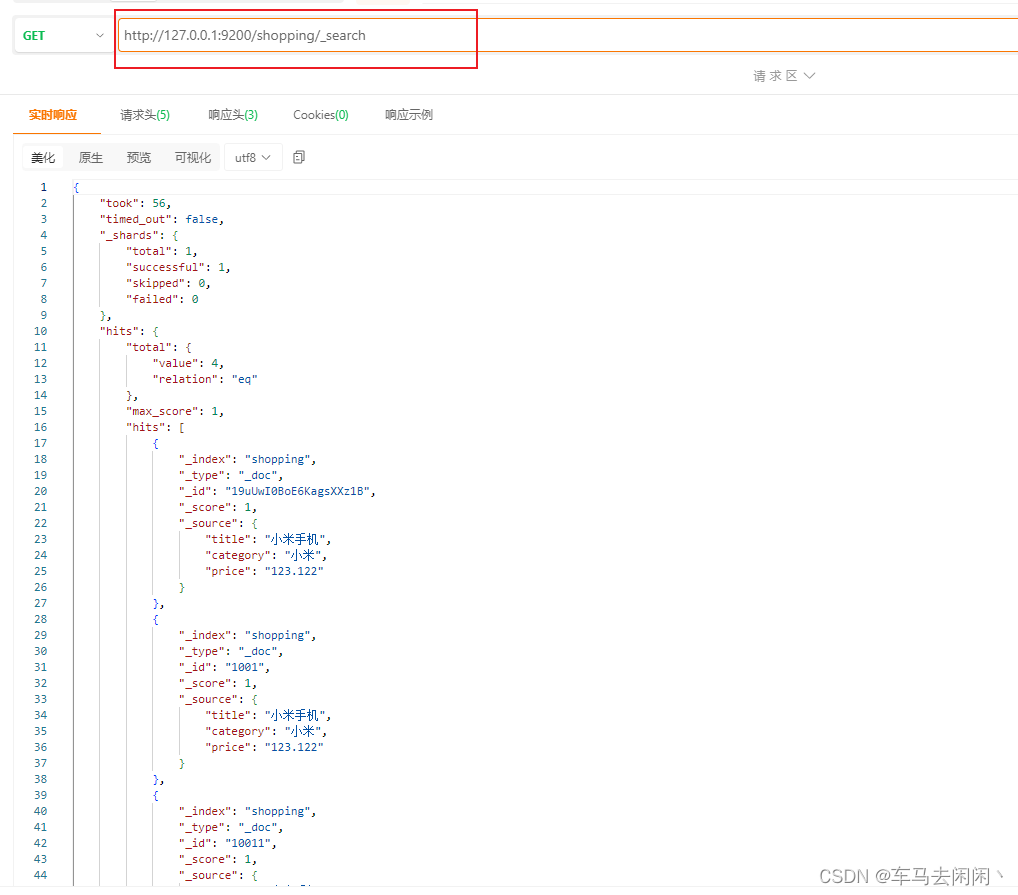
查询当前index下所有的数据
使用_searech
http://127.0.0.1:9200/shopping/_search
返回的数据
查询的毫秒数: “took”: 56,
是否超时: “timed_out”: false,
命中结果 : “hits”: {
“total”: {
“value”: 4, 总数量
“relation”: “eq” 比较
},
…
}
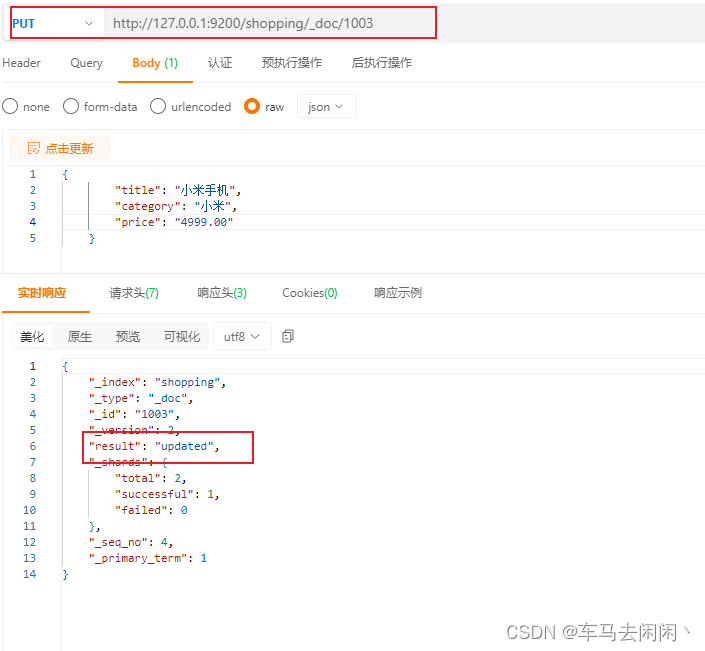
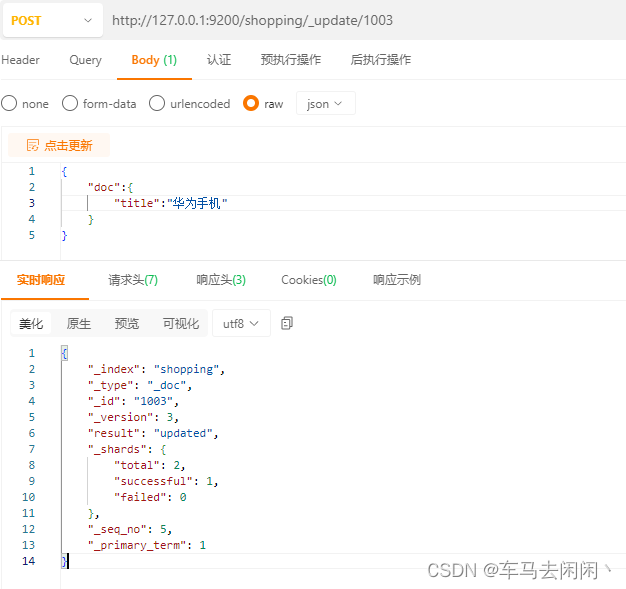
数据修改
全量数据更新,操作需要修改的id,再返回的时候,返回类型是updated
单一修改
需要进行post进行请求,在请求时候需要明确标识_update,ID
请求体
{
"doc":{ //进行修改"title":"华为手机" //修改字段和数据
}
}
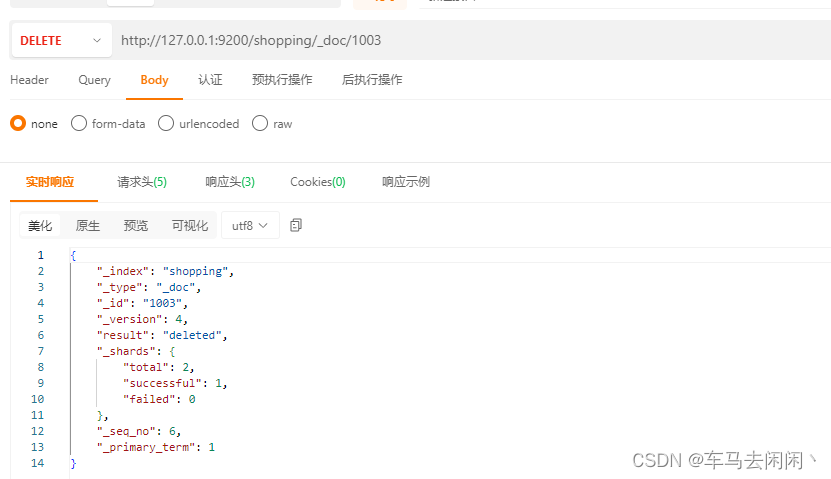
下标删除
使用delete进行删除操作
http://127.0.0.1:9200/shopping/_doc/1003
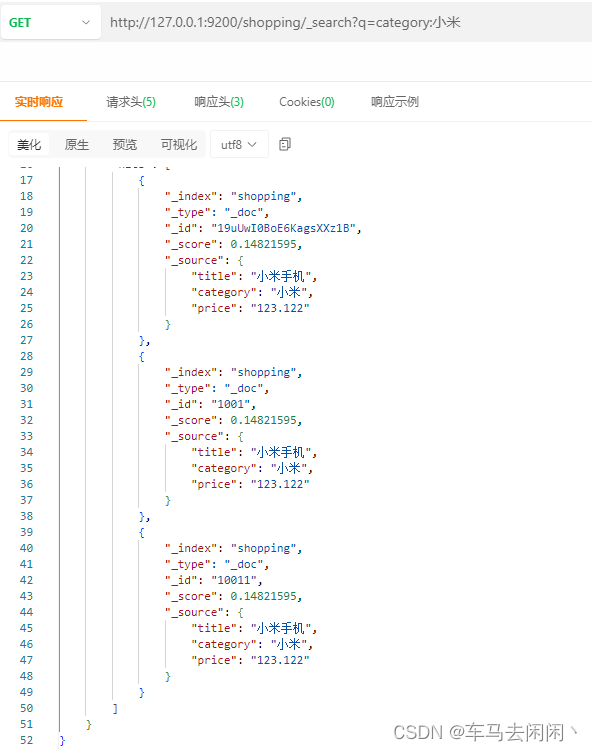
查询操作
查询指定类型的数据
使用URl进行查询
http://127.0.0.1:9200/shopping/_search?q=category:小米
URL分析:查询shopping的数据库,在这个数据库中所有品类为小米的数据
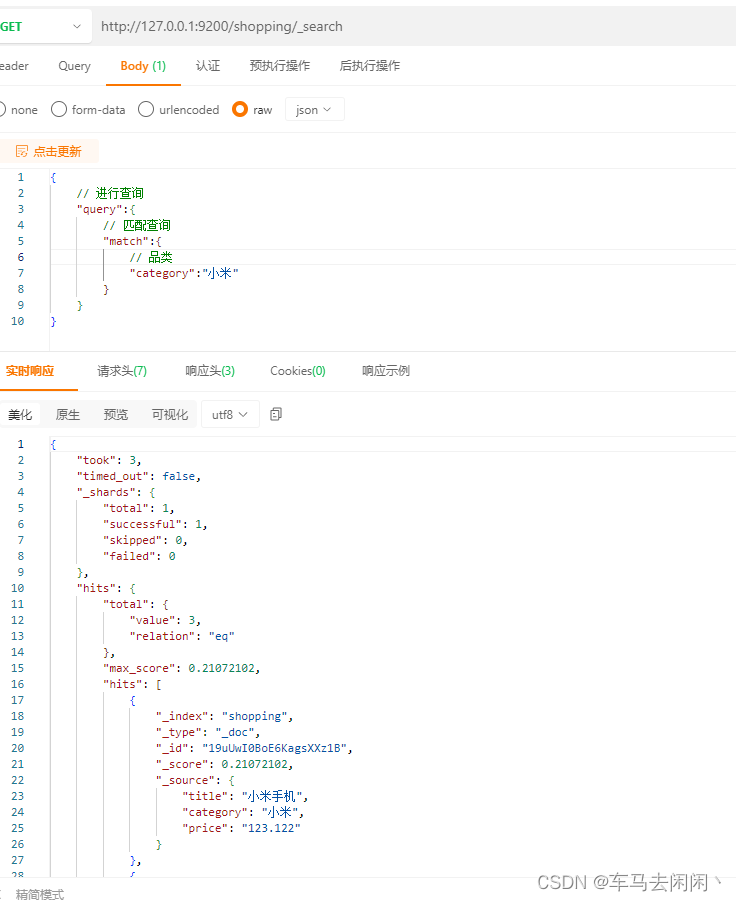
使用请求体查询
请求体内容和介绍
{
// 进行查询
“query”:{
// 匹配查询"match":{ // 品类"category":"小米"}
}
请求体全量查询
{
“query”:{
"match_all":{}}
}

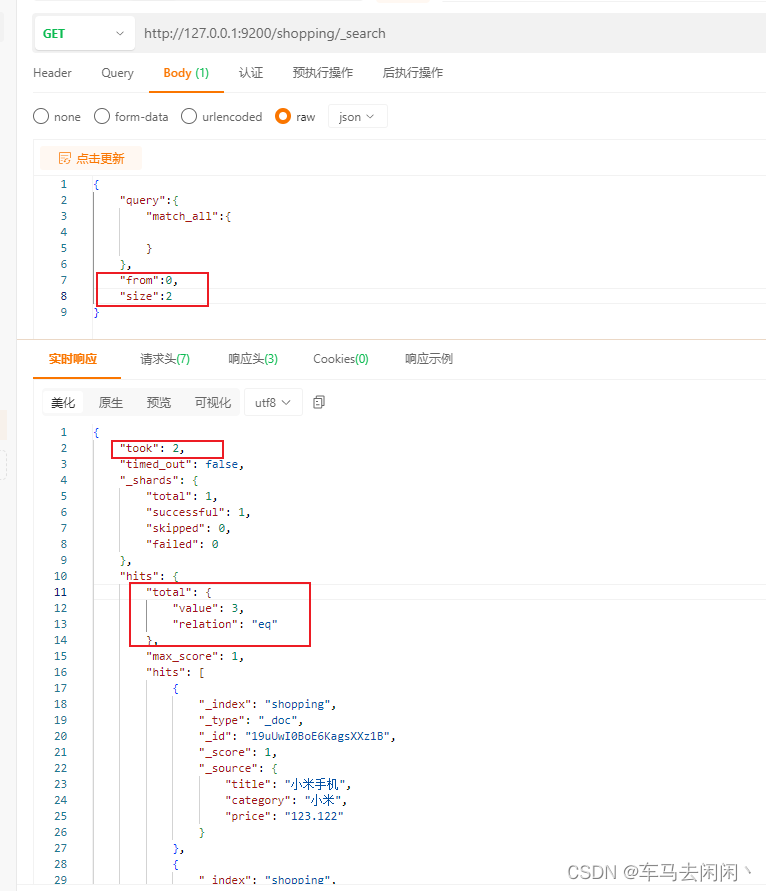
分页查询
分页计算公式: (页码-1) * 每页条数
from:开始位置
size:查询几条
返回的数据中 took表示命中数据,total表示总工有几条
查询指定信息
如果只需要查询想看到的数据,可以通过 _source进行控制

字段排序
这里的字段排序是有问题的,排序对于字段类型有一定的要求,如果是text类型是无法参与排序的
这个错误是来自于Elasticsearch的查询操作,具体是关于字段数据类型的问题。Elasticsearch中的字段可以是多种类型,比如text、keyword、integer等。每种类型都有其特定的用途和优化。
这个错误告诉你,你正在尝试对一个text类型的字段(在这里是price字段)执行聚合(aggregations)或排序(sorting)操作,但这是不被允许的。text字段是为了全文搜索而优化的,它们不是为聚合或排序这类需要每个文档字段数据的操作而优化的。
错误提供了两种解决方案:
- 使用
keyword类型的字段:如果你的price字段实际上是一个固定的值(比如商品的价格),并且你需要对它进行聚合或排序,那么你应该将它定义为keyword类型,而不是text类型。 - 设置
fielddata=true:这将允许你在text字段上执行聚合和排序操作。但是,请注意,这可能会消耗大量的内存,因为Elasticsearch需要为字段的每个唯一值加载数据。
在大多数情况下,建议将价格这样的字段定义为keyword类型,因为价格通常是一个固定的值,而不是需要全文搜索的文本。
如果你正在使用Elasticsearch的映射(mapping)来定义你的索引,那么你可以这样定义price字段:
{ "properties": { "price": { "type": "keyword" } // 其他字段... }
}

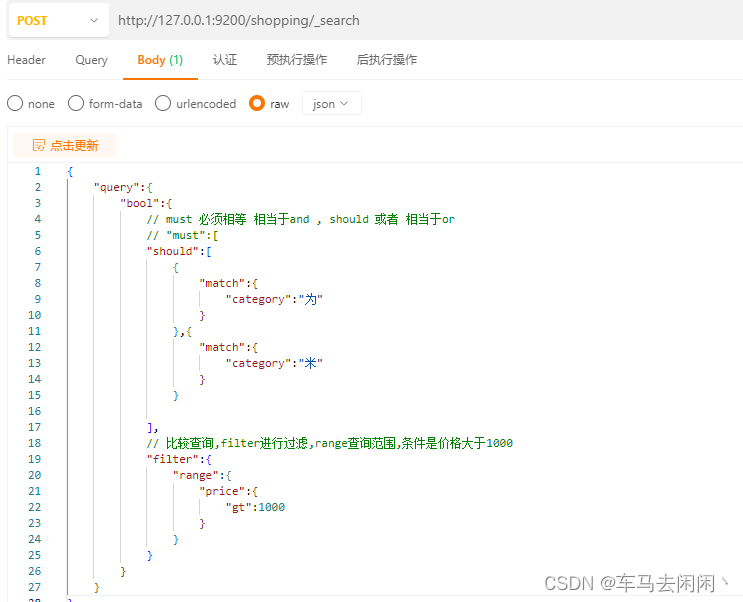
条件查询
"query":{"bool":{// must 必须相等 相当于and 进行全文检索匹配 , should 或者 相当于or// "must":[ "should":[ {"match_phrase":{ // match比较,进行全文检索匹配,match_phrase进行全量匹配"category":"华为"}},{"match":{"category":"小米"}}],// 比较查询,filter进行过滤,range查询范围,条件是价格大于1000"filter":{"range":{"price":{"gt":1000}}}}}
}```
**高亮查询**
```json
{"query":{"match":{"category":"小米" //匹配字段}},"highlight":{ //高亮"fields":{ // 高亮字段"category":{} //具体的高亮字段}}
}

聚合查询
{"aggs":{ //聚合操作"price_group":{"avg":{ // terms 分组 ,avg 平均值"field":"price" //分组字段}}},"size":0 //设置此参数,在查询的时候不会显示额外的数据,只会显示聚合操作完成的数据
}

映射
{"properties":{"name":{"type":"text", // 可以分词"index":true // true 可以被索引查询},"sex":{"type":"keyword", //表示不能被分词"index":true // true 可以被索引查询},"tel":{"type":"keyword", //表示不能被分词"index":false // false 不可以被索引查询}}
}