使用LangChain结合通义千问API基于自建知识库的多轮对话和流式输出
本文章的第三弹,由于LangChain本文不支持直接使用通义千问API进行多轮对话和流式输出,但是自建知识库呢,还需要LangChain,因此我尝试了一下,自建知识库用LangChain,然后使用自己编写的提示词语句来时间查询。最后也能模拟出一个一样的效果。
调用阿里通义千问大语言模型API-小白新手教程-python
LangChain结合通义千问的自建知识库
文章目录
- 使用LangChain结合通义千问API基于自建知识库的多轮对话和流式输出
- 自建知识库文档
- 使用LangChain构建本地知识库
- 多轮对话和流式输出实现代码
- 总结
自建知识库文档
还是上一篇文章的一小段话
CSDN中浩浩的科研笔记博客的作者是啊浩
博客的地址为 www.chen-hao.blog.csdn.net
其原力等级为5级,在其学习评价中,其技术能力超过了99.6%的同码龄作者,且超过了97.9%的研究生用户。
该博客中包含了,单片机,深度学习,数学建模,优化方法等,相关的博客信息,其中访问量最多的博客是《Arduino 让小车走实现的秘密 增量式PID 直流减速编码电机》。
其个人能力主要分布在Python,和Pytorch方面,其中python相对最为擅长,希望可以早日成为博客专家。
使用LangChain构建本地知识库
在这个代码中,读取切分,使用embedding模型生成词向量直接用一个代码实现,代码如下。
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import time
import numpy as nptime_list = []t = time.time()
# 导入文本
loader = UnstructuredFileLoader("test.txt")
data = loader.load()# 文本切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=20, chunk_overlap=0)
split_docs = text_splitter.split_documents(data)
print(split_docs)
model_name = r"Model\bce-embedding-vase_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)# 初始化加载器 构建本地知识向量库
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/news_test")
# 持久化
db.persist()# 打印时间##
time_list.append(time.time()-t)
print(time.time()-t)
运行结果如下,这个小段文字的文本使用CPU构建本文知识向量库的话的时间大概在8秒
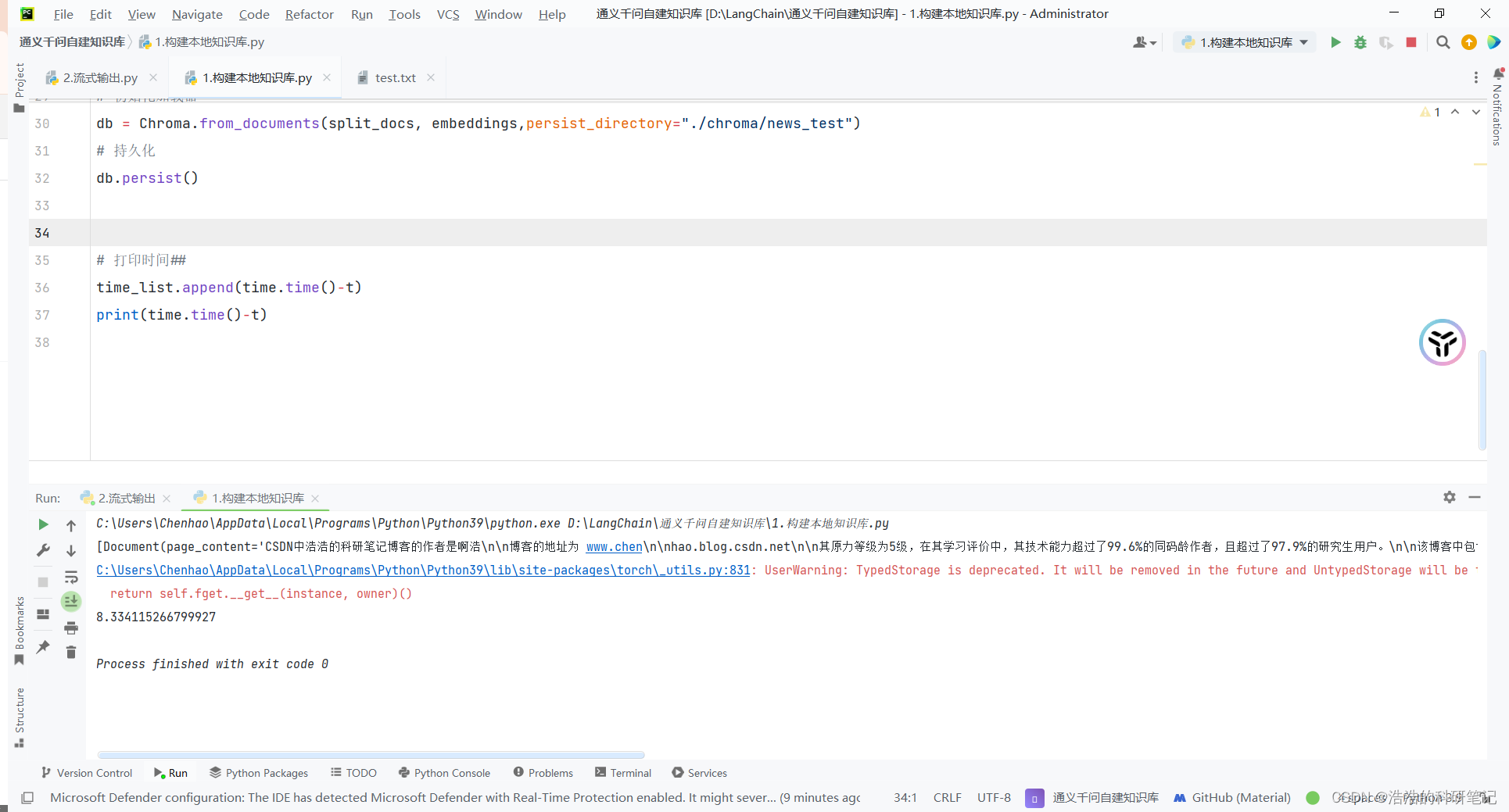
然后这里的chunk_size不要选择太长,2-3句话的大小就可以,这属于适应文档情况的超参数
如果chunk_size设置的过大,可能会导致只生成了2条知识向量库,然后最后再设置查找多少个样本总结的时候,就会出现查找不到多少条的警告,还会导致判断是否无关的提示词逻辑无效,会输出一大堆无关的结果
多轮对话和流式输出实现代码
这里就是最关键的部分,我先给出代码,然后再说一下里卖弄的内容,代码结合了调整知识向量库加载器和通义前问官方的流式输出API的代码。
from dashscope import Generation
from dashscope.api_entities.dashscope_response import Role
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddingsmessages = []model_name = r"Model\bce-embedding-vase_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': False}
embeddings = HuggingFaceEmbeddings(model_name=model_name,model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)
db = Chroma(persist_directory="./chroma/news_test", embedding_function=embeddings)while True:message = input('user:')similarDocs = db.similarity_search(message, k=5)summary_prompt = "".join([doc.page_content for doc in similarDocs])send_message = f"下面的信息({summary_prompt})是否有这个问题({message})有关,如果你觉得无关请告诉我无法根据提供的上下文回答'{message}'这个问题,简要回答即可,否则请根据{summary_prompt}对{message}的问题进行回答"messages.append({'role': Role.USER, 'content': send_message})whole_message = ''# 切换模型responses = Generation.call(Generation.Models.qwen_max, messages=messages, result_format='message', stream=True, incremental_output=True)# responses = Generation.call(Generation.Models.qwen_turbo, messages=messages, result_format='message', stream=True, incremental_output=True)print('system:',end='')for response in responses:whole_message += response.output.choices[0]['message']['content']print(response.output.choices[0]['message']['content'], end='')print()messages.append({'role': 'assistant', 'content': whole_message})
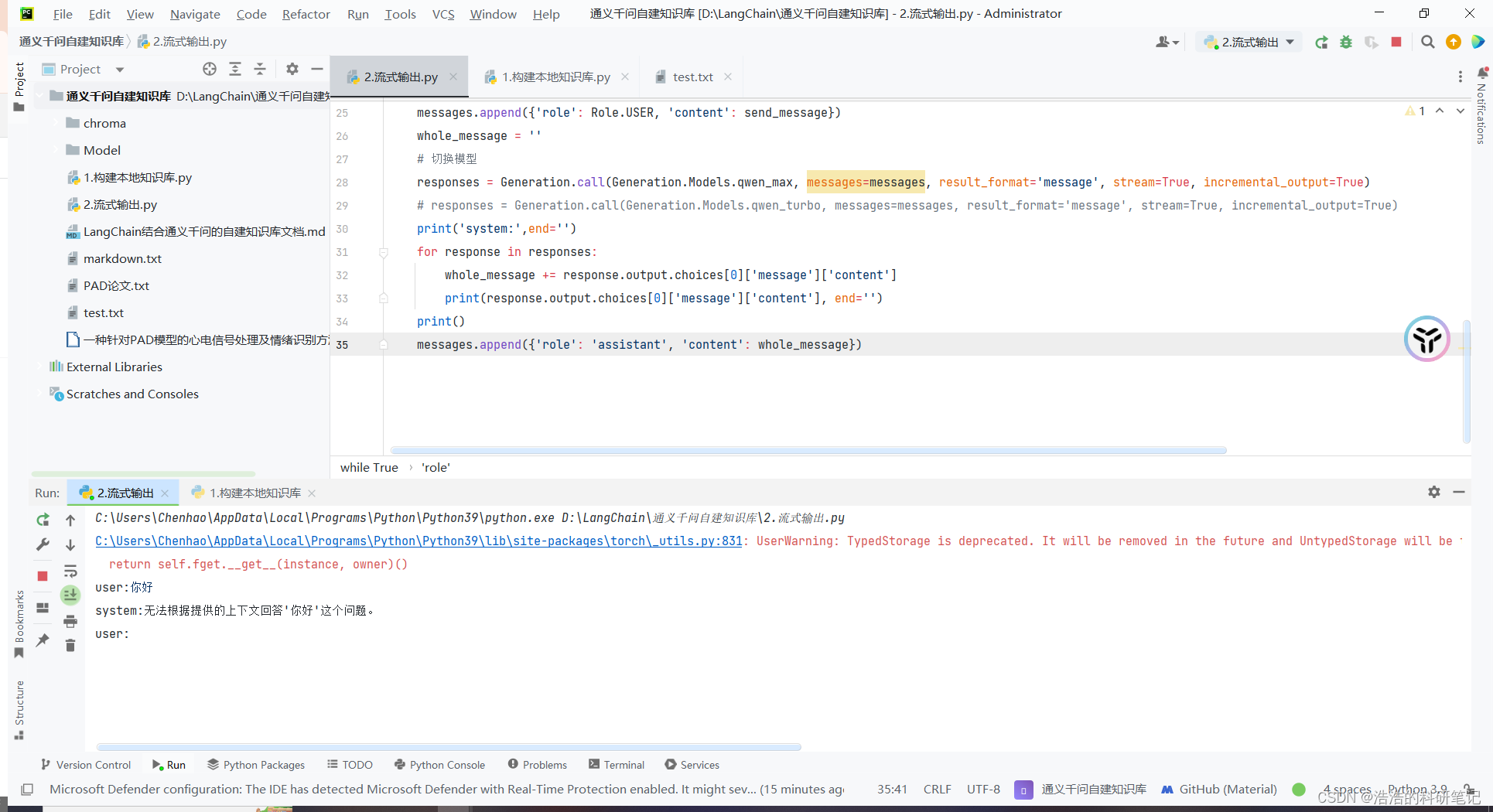
提问你好
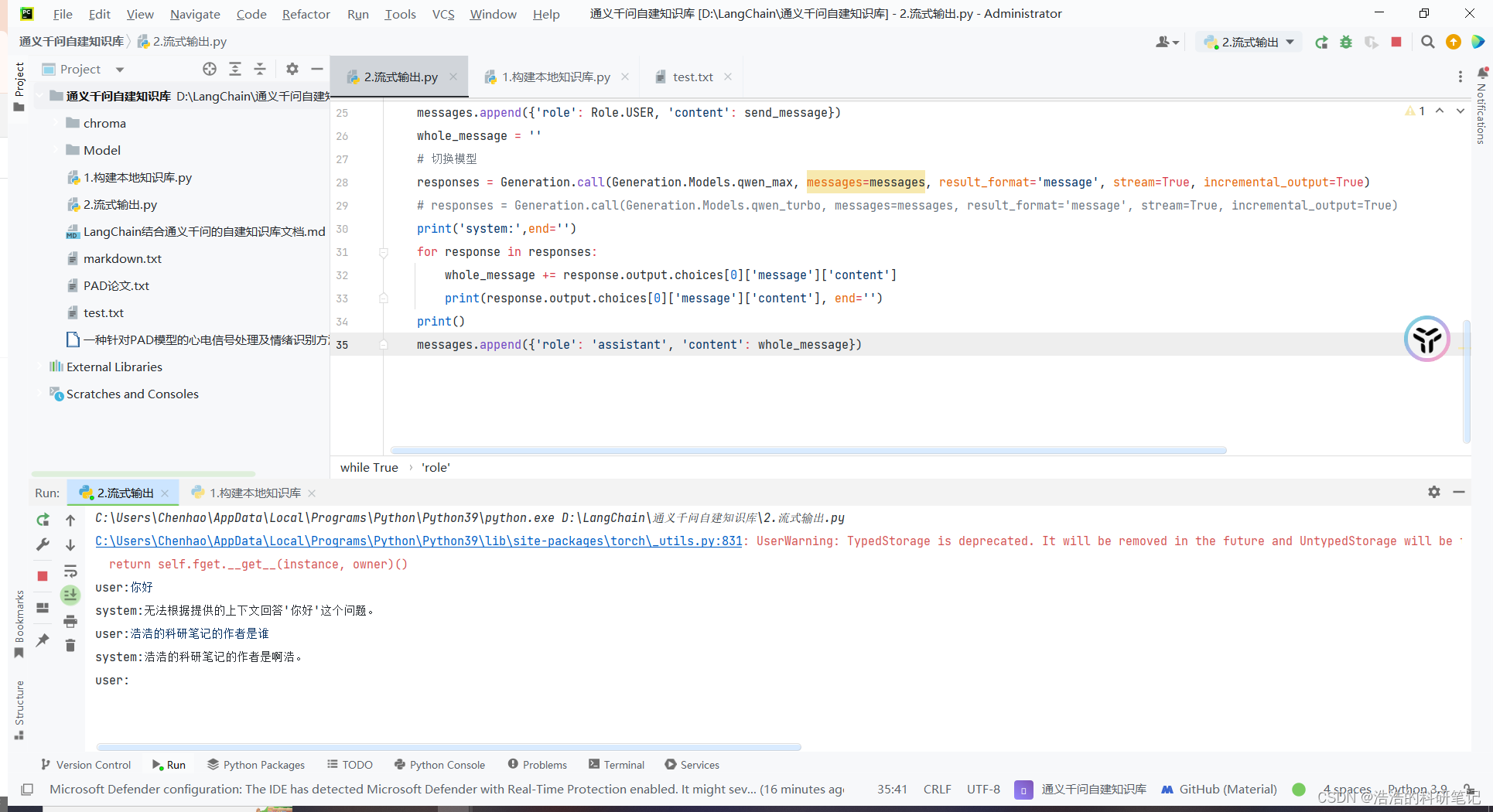
提问浩浩的科研笔记的作者是谁。
总结
后续除了根据文档调chunk_size和k或者提示词之外,想企业应用的话应该需要一些知识图谱相关的逻辑。这个系列目前就到这里,后续有新的发展我会再说。