old dockerfile
# syntax=docker/dockerfile:1FROM node:18-alpine
WORKDIR /app
RUN yarn install --production
COPY . .
CMD ["node", "src/index.js"]
EXPOSE 3000
# syntax=docker/dockerfile:1是 Dockerfile 的一个解析器指令,它用于声明构建时使用的 Dockerfile 语法版本。如果你不指定这个指令,BuildKit 将使用它内置的 Dockerfile 前端版本。声明一个语法版本可以让你自动使用最新的 Dockerfile 版本,而无需升级 BuildKit 或 Docker Engine,甚至可以使用自定义的 Dockerfile 实现。
大多数用户会将这个解析器指令设置为
docker/dockerfile:1,这会让 BuildKit 在构建前拉取 Dockerfile 语法的最新稳定版本。在你的 Dockerfile 中,
# syntax=docker/dockerfile:1指令告诉 Docker 使用最新稳定版本的 Dockerfile 语法来解析和构建这个 Dockerfile。
note 1 :
EXPOSE 3000 和 docker run -dp 127.0.0.1:3001:3000 getting-started-2 的关联
Dockerfile 中的
EXPOSE指令只是声明了应用程序在容器内部监听的端口,它并不会自动映射这个端口到宿主机。如果你想让应用程序可以从宿主机访问,你需要在启动容器时使用-p或--publish参数来映射端口。容器启动时映射的端口并不一定要和
EXPOSE指令声明的端口相同。例如,你的 Dockerfile 中有EXPOSE 3000,但你可以在启动容器时使用-p xxxx:3000来将容器的 3000 端口映射到宿主机的 xxxx 端口。但是,如果你的应用程序在容器内部监听的端口和
EXPOSE指令声明的端口不同,那么EXPOSE指令就没有意义了。因为EXPOSE指令的主要目的就是告诉使用这个镜像的人,应用程序在哪个端口提供服务。镜像就是一个模版,可以同时生成多个容器实例服务这样就相当于你可以将启动多个主机端口 映射同样的实例服务
3001 -> 3000 3002 -> 3000
note 2 : caching of the dependencies
watching the old dockerFile command line 。 at some circumstance , we will recreated image when update code ,but it will download dependencies again 。 that's terrible , please following to optimize the dockerFile 。
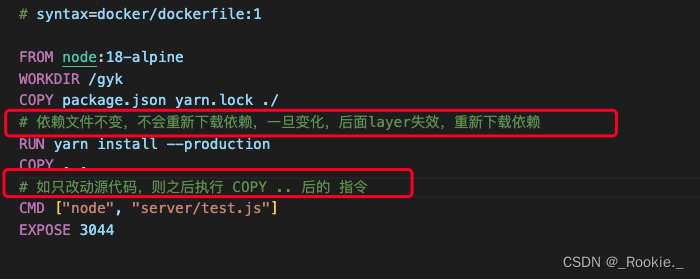
# syntax=docker/dockerfile:1FROM node:18-alpine
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn install --production
COPY . .
CMD ["node", "server/test.js"]
EXPOSE 3000原因 :
Once a layer changes, all downstream layers have to be recreated as well
一旦一个图层改变,所有的下游层都会重新构建
Docker 使用一种称为层(layer)的概念来构建和存储镜像。每个 Dockerfile 指令都会创建一个新的层,并在此基础上进行下一步操作。这些层是只读的,但可以被后续的层修改。
Docker 会尽可能地使用缓存来加速镜像构建过程。当 Docker 构建镜像时,它会查看每个指令和之前构建的镜像层。如果 Docker 发现一个指令和一个已经缓存的层完全匹配,那么它就会使用这个缓存的层,而不是重新执行指令。
例如,如果你的 Dockerfile 的前两个指令是
FROM node:18-alpine和WORKDIR /app,并且你之前已经构建过一个使用相同指令的镜像,那么 Docker 就会使用这两个缓存的层。但是,如果一个指令的上下文(例如,被复制的文件)发生了改变,那么 Docker 就不能使用缓存,而必须重新执行指令。这就是为什么在 Dockerfile 中,我们通常先复制
package.json和yarn.lock,然后运行yarn install,最后再复制其余的文件。这样,即使源代码发生改变,只要依赖没有改变,yarn install的步骤就可以使用缓存,从而加速构建过程。
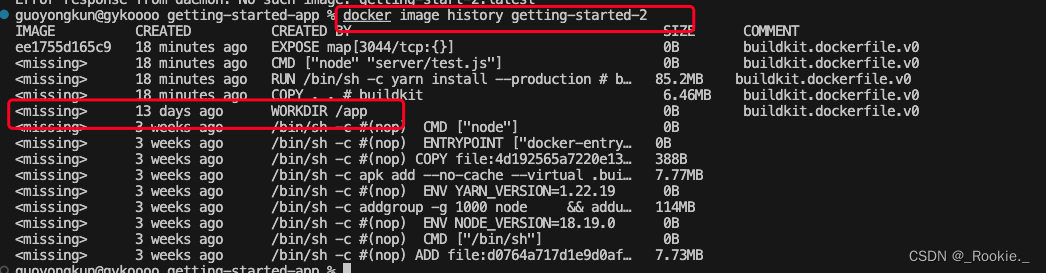
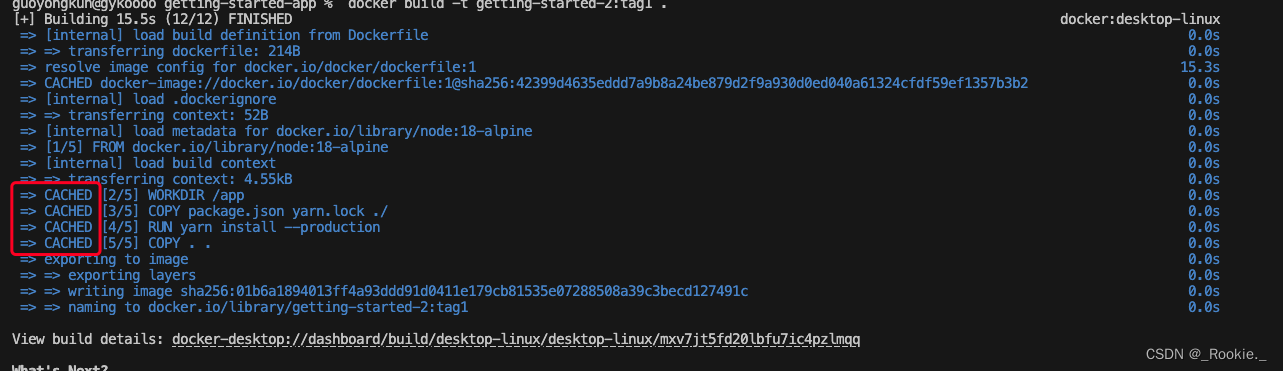
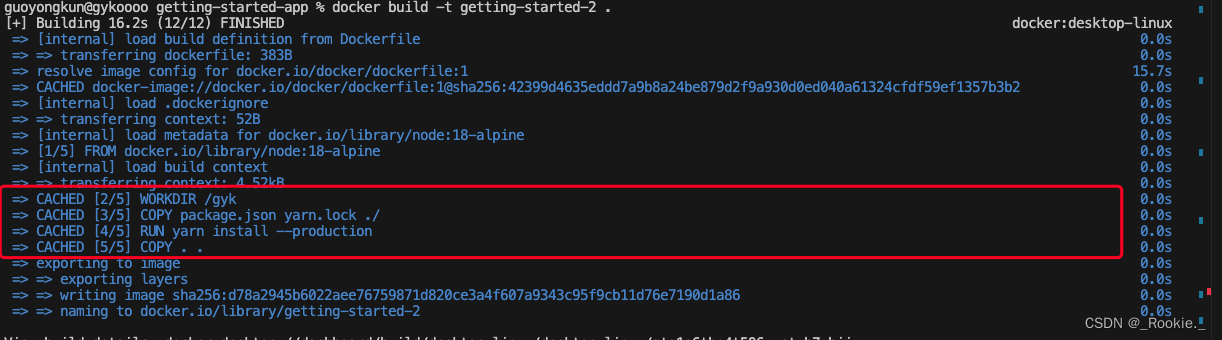
如果指令不变,那么就会用缓存的老的 layer
修改 /app 为 /gyk 后 ,/app 后的所有layer 全部失效。
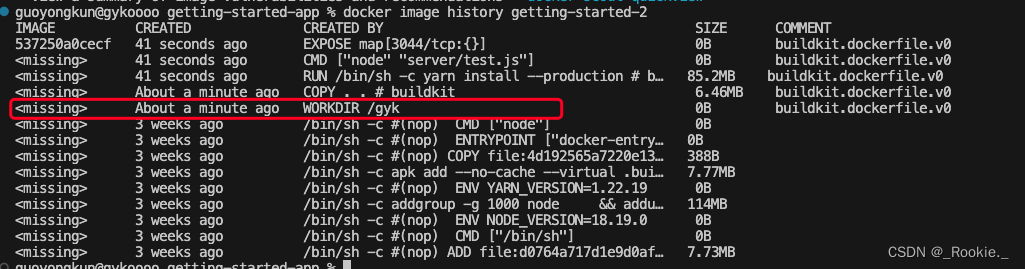
所以:
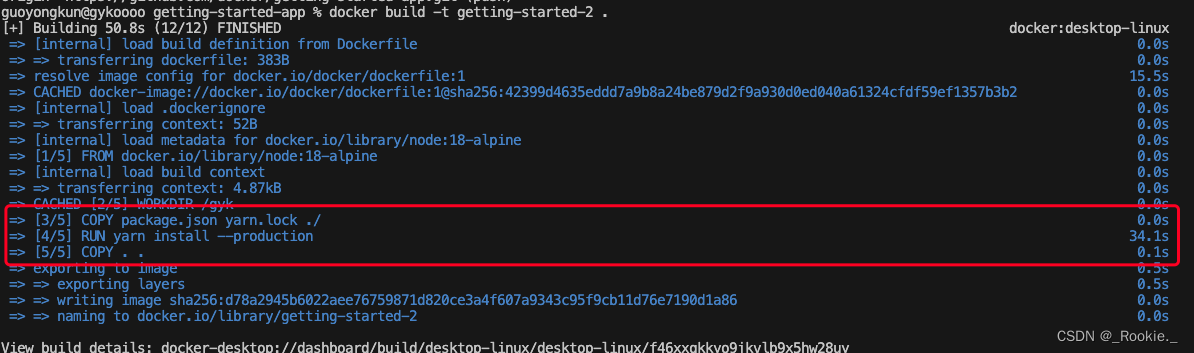
重新 build
note3 .dockerignore
.dockerignore文件用于指定哪些文件或目录应该被 Docker 忽略,不应该被复制到镜像中。这与.gitignore文件的作用类似,但是用于 Docker。在你提供的例子中,
.dockerignore文件的内容是:node_modules
这意味着
node_modules目录不会被复制到 Docker 镜像中。这是因为node_modules目录通常包含大量的文件,而且这些文件在构建过程中会被yarn install或npm install命令重新创建。因此,将node_modules目录复制到镜像中不仅会浪费空间,还可能导致问题,因为它可能会覆盖由RUN步骤创建的文件。
note 4 muti-stage builds 多阶段构建
多阶段构建(Multi-stage builds)是 Docker 提供的一种强大的工具,它允许你在一个 Dockerfile 中定义多个阶段来构建镜像。这有几个优点:
分离构建时依赖和运行时依赖:在构建阶段,你可能需要一些额外的工具和库来编译你的应用程序(例如,编译器,构建工具等)。但是在运行阶段,这些工具和库可能就不再需要了。通过使用多阶段构建,你可以在一个阶段安装和使用这些工具,然后在另一个阶段只复制你的应用程序和它需要的运行时依赖。
减少总体镜像大小:由于你只复制了应用程序和它的运行时依赖,所以最终的镜像会比包含所有构建工具和库的镜像小得多。这可以减少存储和网络传输的开销,使你的应用程序更快地启动,并且减少了安全风险,因为镜像中包含的组件更少。
下面是一个简单的多阶段构建的例子:
# 第一阶段:构建应用程序
FROM node:18-alpine AS build
WORKDIR /app
COPY package.json yarn.lock ./
RUN yarn install
COPY . .
RUN yarn build# 第二阶段:运行应用程序
FROM node:18-alpine
WORKDIR /app
COPY --from=build /app/dist ./dist
COPY package.json yarn.lock ./
RUN yarn install --production
CMD ["node", "dist/index.js"]在这个例子中,第一阶段使用
node:18-alpine镜像来安装所有依赖并构建应用程序。然后,第二阶段使用同样的node:18-alpine镜像,但只复制了构建的应用程序和运行时依赖,并安装了这些运行时依赖。这样,最终的镜像就只包含了运行应用程序所需要的东西。
在 Dockerfile 中,
WORKDIR /app指令设置了工作目录为/app。这意味着后续的指令(如COPY,RUN等)都会在这个目录下执行。在你提供的 Dockerfile 的第二阶段中,
COPY --from=build /app/dist ./dist这行指令的作用是从构建阶段(被命名为build)的镜像中复制/app/dist目录到当前工作目录下的dist目录。这里的
./dist是相对于当前的工作目录/app的,所以./dist实际上就是/app/dist。所以,这行指令的效果是将构建阶段生成的应用程序(位于
/app/dist)复制到最终镜像的/app/dist目录下。然后,
CMD ["node", "dist/index.js"]这行指令在容器启动时会运行/app/dist/index.js,也就是你刚刚复制过来的应用程序
React example
When building React applications, you need a Node environment to compile the JS code (typically JSX), SASS stylesheets, and more into static HTML, JS, and CSS. If you aren't doing server-side rendering, you don't even need a Node environment for your production build. You can ship the static resources in a static nginx container.
# syntax=docker/dockerfile:1
FROM node:18 AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run buildFROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html
example:
# syntax=docker/dockerfile:1FROM node:18-alpine AS build
WORKDIR /gyk
COPY package.json yarn.lock ./
# 依赖文件不变,不会重新下载依赖,一旦变化,后面layer失效,重新下载依赖
RUN yarn install --production
COPY . .
# 如只改动源代码,则之后执行 COPY .. 后的 指令
CMD ["node", "server/test.js"]
EXPOSE 3044FROM nginx:alpine
COPY --from=build /gyk/. /usr/share/nginx/html
#/gyk/* 表示 gyk 目录下的所有文件和子目录,如果你想使用 . 来表示 gyk 目录下的所有内容,你可以直接写成 /gyk/.。这样,Docker 就会复制 gyk 目录下的所有文件和子目录,在 Dockerfile 中,COPY 指令不支持 ** 这种形式的通配符。** 通常在 shell 脚本或某些编程语言中用于匹配任意多级的子目录,但在 Dockerfile 的 COPY 指令中,这种语法是不被支持的优化后 43.37 M

在 Docker 的多阶段构建中,每个阶段都必须以
FROM指令开始,这是 Dockerfile 语法的要求。FROM指令用于指定基础镜像,如果你不指定基础镜像,Docker 就不知道如何创建新的镜像。如果你的第二阶段不需要任何特定的镜像,你可以使用一个非常小的基础镜像,如
scratch。scratch是一个特殊的 Docker 镜像,它是空的,不包含任何文件。这通常用于创建非常小的镜像,只包含你的应用程序和它的运行时依赖。
note 5 :node:18-alpine 和 nginx:alpine 的 alpine 是什么意思
alpine是一个轻量级的 Linux 发行版,它的设计目标是尽可能地减小体积。alpine镜像通常只有 5MB 左右,相比其他的 Linux 发行版,如 Ubuntu 或 Debian,它的体积小很多。在 Docker 中,
alpine通常用作基础镜像,用于构建更小的 Docker 镜像。例如,node:18-alpine是一个包含 Node.js 18 版本和 Alpine Linux 的 Docker 镜像,nginx:alpine是一个包含 Nginx 和 Alpine Linux 的 Docker 镜像。使用
alpine作为基础镜像的好处是可以减小最终 Docker 镜像的体积,这可以减少存储和网络传输的开销,使你的应用程序更快地启动,并且减少了安全风险,因为镜像中包含的组件更少




![[极客挑战2019]HTTP](https://img-blog.csdnimg.cn/direct/86be3ad122b343f39c2b72ac4d9f0549.png)