K模型与KV模型
在数据结构中,二叉搜索树(BST)的应用通常围绕着两种基本模型:键模型(K模型)和键值对模型(KV模型)。这两种模型定义了树中节点存储数据的方式,以及如何通过这些数据进行查找、插入和删除操作。
K模型(键模型)
在K模型中,每个节点存储一个单一的数据项,称为“键”(Key)。这个模型的核心特性是:
唯一性:树中每个键都是唯一的,不允许重复。
有序性:树中任意节点的左子树只包含键小于该节点的键的节点,其右子树只包含键大于该节点的键的节点。
操作:基本操作包括插入新键、查找键和删除键。所有操作都依赖于键之间的比较。
K模型的二叉搜索树适用于需要快速查找、插入和删除单一数据项的场景,如集合数据类型的实现。
KV模型(键值对模型)
KV模型扩展了K模型,使得每个节点存储两个数据项:一个是“键”(Key),另一个是与键相关联的“值”(Value)。这个模型的特性包括:
键的唯一性和有序性:与K模型相同,键在树中是唯一的,并且树的结构保证了键的有序性。
值的关联性:每个键都关联一个特定的值。值可以是任何类型的数据,如数字、字符串或更复杂的对象。
操作:除了基本的插入、查找和删除操作外,KV模型还支持根据键更新关联值的操作。
KV模型的二叉搜索树广泛应用于实现映射(Map)或字典(Dictionary)数据结构,其中需要根据唯一键快速查找、更新或删除关联的值。
改造二叉搜索树为KV结构
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;template<class K, class V>
struct BSTNode {BSTNode(const K&key = K(), const V& value = V()): _pLeft(nullptr), _pRight(nullptr), _key(key), _value(value) {}BSTNode<K, V>* _pLeft;BSTNode<K, V>* _pRight;K _key;V _value;};template<class K, class V>
class BSTree {typedef BSTNode<K, V> Node;typedef Node* PNode;public:BSTree(): _pRoot(nullptr) {}PNode Find(const K& key) {Node* cur = _pRoot;while (cur) {if (key == cur->_key)return cur;else if (key < cur->_key)cur = cur->_pLeft;elsecur = cur->_pRight;}return nullptr;};bool Insert(const K& key, const V&value) {// 1. 空树---// 新插入的节点应该是跟节点if (nullptr == _pRoot) {_pRoot = new Node(key, value);return true;}// 2. 树非空// a. 找待插入节点在树中的位置--->按照二叉搜索树的性质Node* cur = _pRoot;Node* parent = nullptr;while (cur) {parent = cur;if (key < cur->_key)cur = cur->_pLeft;else if (key > cur->_key)cur = cur->_pRight;elsereturn false;}// 树中不存在值为data的节点// b. 插入新节点cur = new Node(key, value);if (key < parent->_key)parent->_pLeft = cur;elseparent->_pRight = cur;return true;};bool Erase(const K& key) {return false;};void InOrder() {_InOrder(_pRoot);cout << endl;}private:void _InOrder(Node* proot) {if (proot) {_InOrder(proot->_pLeft);cout << proot->_key << " 个数:" << proot->_value << endl;_InOrder(proot->_pRight);}}PNode _pRoot;};void TestBSTree3() {BSTree<string, string> dict;dict.Insert("string", "字符串");dict.Insert("tree", "树");dict.Insert("left", "左边、剩余");dict.Insert("right", "右边");dict.Insert("sort", "排序");string str;while (cin >> str) {if(str[0] == EOF){return;}BSTNode<string, string>* ret = dict.Find(str);if (ret == nullptr) {cout << "单词拼写错误,词库中没有这个单词:" << str << endl;} else {cout << str << "中文翻译:" << ret->_value << endl;}}}void TestBSTree4() {// 统计水果出现的次数string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜","苹果", "香蕉", "苹果", "香蕉"};BSTree<string, int> countTree;for (const auto& str : arr) {
// 先查找水果在不在搜索树中// 1、不在,说明水果第一次出现,则插入<水果, 1>// 2、在,则查找到的节点中水果对应的次数++//BSTreeNode<string, int>* ret = countTree.Find(str);auto ret = countTree.Find(str);if (ret == NULL) {countTree.Insert(str, 1);} else {ret->_value++;}}countTree.InOrder();}int main() {TestBSTree3();TestBSTree4();return 0;}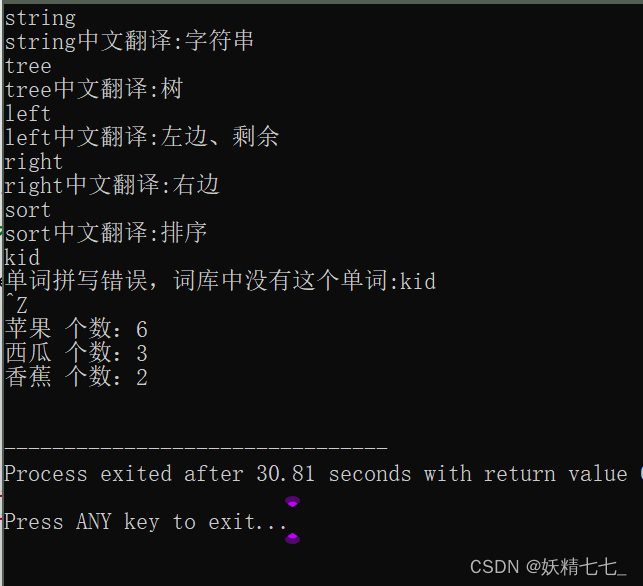
Map、MultMap的探究
Map是一种关联容器,它存储由键值和映射值组成的元素,遵循特定的顺序。
在Map中,键值通常用于对元素进行排序和唯一标识,而映射值存储与该键相关联的内容。键和映射值的类型可能不同,并且被组合在一起作为成员类型value_type,它是一个pair类型,结合了键和映射值:
typedef pair<const Key, T> value_type;
在Map中,元素总是按其键值进行排序,遵循特定的严格弱排序准则,由其内部比较对象(Compare类型)指示。
相比unordered_map容器,Map容器通常访问单个元素时速度较慢,但它们允许根据其顺序直接迭代子集。
在Map中,可以使用方括号运算符(operator[])直接通过其相应的键访问映射值。
Map通常以二叉搜索树的形式实现。
#include <iostream>
using namespace std;#include <map>
#include <string>void TestMap1(){map<string, string> m1;map<string, string> m2{ {"apple","苹果"}, {"orange", "橙子"}, {"banana", "香蕉"} };auto m3 = m2; // 调用拷贝构造map<string, string> m4(m2.begin(), m2.end());}void TestMap2(){map<string, string> m;// 通过insert直接往map中插入键值对pair<string, string> p("orange", "橙子");m.insert(p);m.insert(pair<string, string>("banana", "香蕉"));m.insert(make_pair("apple", "苹果"));cout << m.size() << endl;// m[key]--->表明:返回key对应的valuecout << m["orange"] << endl;// m[key] = newvalue; 使用newvalue给map中key对应的value进行赋值m["orange"] = "橘子";// 如果通过m[key]访问key对应的value时,如果key不存子?// m会使用当前key与一个默认的value构成一个键值对<key, 默认value>插入到m中// 然后将key对应的默认的value返回来cout<<m["peach"]<<endl;m["pair"] = "梨";// map中已经存在orange,在插入一个orange看能否成功m.insert(make_pair("orange", "橙子"));cout << m.size() << endl;// 对map中的元素进行遍历//std::map<std::string, std::string>::iterator it = m.begin();auto it = m.begin();while (it != m.end()){cout << "<" << it->first << "," << it->second << ">" << endl;++it;}cout << endl;// e 就是m中所存在的键值对的别名for (auto& e : m){cout << "<" << e.first << "," << e.second << ">" << endl;}cout << endl;m.erase("apple");it = m.find("orange");if (it != m.end()){m.erase(it);}for (auto& e : m){cout << "<" << e.first << "," << e.second << ">" << endl;}cout << endl;}void TestMultiMap(){multimap<string, string> m;m.insert(make_pair("apple", "苹果"));m.insert(make_pair("apple", "苹果"));m.insert(make_pair("apple", "苹果"));m.insert(make_pair("apple", "苹果"));m.erase("apple");}int main(){TestMap1();TestMap2();TestMultiMap();}Map的创建
void TestMap1(){map<string, string> m1;map<string, string> m2{ {"apple","苹果"}, {"orange", "橙子"}, {"banana", "香蕉"} };auto m3 = m2; // 调用拷贝构造map<string, string> m4(m2.begin(), m2.end());}
map<string, string> m1;:创建了一个空的map容器m1。
map<string, string> m2{ {"apple","苹果"}, {"orange", "橙子"}, {"banana", "香蕉"} };:创建了一个带有初始值的map容器m2,其中包含三个键值对,键为字符串类型,值为字符串类型。
auto m3 = m2;:创建了一个新的map容器m3,并将m2拷贝到m3中。这里使用了auto进行类型推导,实际上调用了拷贝构造函数。
map<string, string> m4(m2.begin(), m2.end());:创建了一个新的map容器m4,并通过迭代器范围初始化,从m2的开始迭代器到结束迭代器,复制了m2的所有元素。
Map的基本使用
void TestMap2(){map<string, string> m;// 通过insert直接往map中插入键值对pair<string, string> p("orange", "橙子");m.insert(p);m.insert(pair<string, string>("banana", "香蕉"));m.insert(make_pair("apple", "苹果"));cout << m.size() << endl;// m[key]--->表明:返回key对应的valuecout << m["orange"] << endl;// m[key] = newvalue; 使用newvalue给map中key对应的value进行赋值m["orange"] = "橘子";// 如果通过m[key]访问key对应的value时,如果key不存子?// m会使用当前key与一个默认的value构成一个键值对<key, 默认value>插入到m中// 然后将key对应的默认的value返回来cout<<m["peach"]<<endl;m["pair"] = "梨";// map中已经存在orange,在插入一个orange看能否成功m.insert(make_pair("orange", "橙子"));cout << m.size() << endl;// 对map中的元素进行遍历//std::map<std::string, std::string>::iterator it = m.begin();auto it = m.begin();while (it != m.end()){cout << "<" << it->first << "," << it->second << ">" << endl;++it;}cout << endl;// e 就是m中所存在的键值对的别名for (auto& e : m){cout << "<" << e.first << "," << e.second << ">" << endl;}cout << endl;m.erase("apple");it = m.find("orange");if (it != m.end()){m.erase(it);}for (auto& e : m){cout << "<" << e.first << "," << e.second << ">" << endl;}cout << endl;}
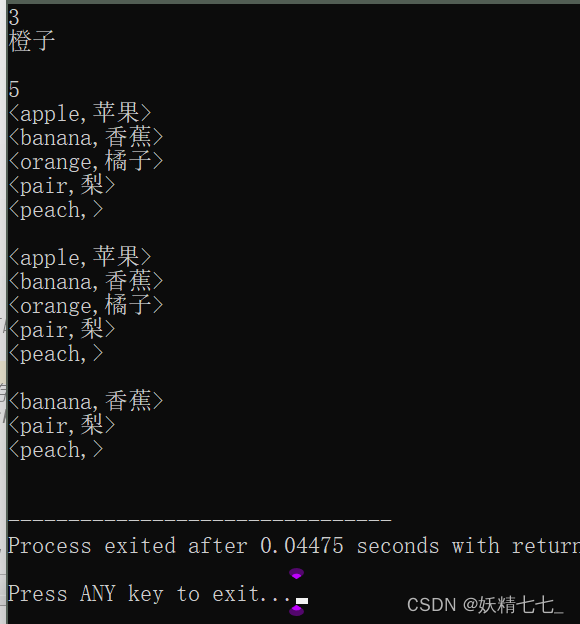
MultiMap
void TestMultiMap(){multimap<string, string> m;m.insert(make_pair("apple", "苹果"));m.insert(make_pair("apple", "苹果"));m.insert(make_pair("apple", "苹果"));m.insert(make_pair("apple", "苹果"));m.erase("apple");}

创建了一个空的multimap容器 m。
使用 insert 函数向multimap容器中插入多个键值对,这些键值对的键都是 "apple",值都是 "苹果"。
使用 erase 函数删除multimap容器中键为 "apple" 的所有键值对。由于multimap容器允许存储相同的键,因此会删除所有键为 "apple" 的键值对,而不仅仅是第一个或最后一个。
Set、MulitSet的探究
集合(Sets)是一种容器,它存储具有唯一性的元素并遵循特定的顺序。
在一个集合中,元素的值也是唯一标识它的(值本身即是键,类型为 T),每个值必须是唯一的。集合中元素的值一旦在容器中,就不能被修改(元素始终是 const),但它们可以被插入或从容器中移除。
在内部,集合中的元素总是按照特定的严格弱排序准则进行排序,这个准则由其内部比较对象(Compare 类型)指示。
相比 unordered_set 容器,集合容器通常访问单个元素时速度较慢,但它们允许根据其顺序直接迭代子集。
集合通常被实现为二叉搜索树。
#include <set>
#include <iostream>
using namespace std;#include <string>
// set使用的场景:去重+排序
void TestSet(){int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };set<int> s(array, array+sizeof(array)/sizeof(array[0]));for (auto e : s){cout << e << " ";}cout << endl;}// multiset作用:排序
void TestMultiSet(){int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };multiset<int> s(array, array + sizeof(array) / sizeof(array[0]));for (auto e : s){cout << e << " ";}cout << endl;}int main(){TestSet();TestMultiSet();}void TestSet(){int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };set<int> s(array, array+sizeof(array)/sizeof(array[0]));for (auto e : s){cout << e << " ";}cout << endl;}
定义了一个整型数组 array,其中包含了一些整数。
使用数组范围初始化了set容器 s。在初始化时,重复的元素会被自动去重,因此set中不会有重复的元素。
使用范围-based for 循环遍历set容器中的所有元素,并输出它们。由于set容器中的元素是按照一定顺序排列的,因此输出结果也是有序的。
// multiset作用:排序 void TestMultiSet(){int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };multiset<int> s(array, array + sizeof(array) / sizeof(array[0]));for (auto e : s){cout << e << " ";}cout << endl;}
定义了一个整型数组 array,其中包含了一些整数。
使用数组范围初始化了multiset容器 s。在初始化时,重复的元素会被保留,因此multiset中可以包含重复的元素,并且会按照一定顺序排列。
使用范围-based for 循环遍历multiset容器中的所有元素,并输出它们。由于multiset容器中的元素是按照一定顺序排列的,因此输出结果也是有序的。
Map的水果数量问题探究
统计输入的水果中每种水果出现的次数,并输出出现次数最多的前 k 种水果。
#include <vector>
#include<map>#include<iostream>
using namespace std;void GetFavoriteFruit(const vector<string>& fruits,size_t k){map<string, size_t> m;for (auto e : fruits)m[e]++;multimap<size_t, string, greater<int>> mm;for (auto& e : m){mm.insert(make_pair(e.second, e.first));}for (auto& e : mm){if (k == 0)return;cout << e.second << " ";k--;}cout << endl;}int main(){vector<string> fruits{"1111", "2222", "3333", "2222", "4444", "3333", "5555", "9999", "0000", "3333", "1111", "5555", "2222"};GetFavoriteFruit(fruits, 3);return 0;}定义一个map来存储每个水果和它出现的次数:
map<string, size_t> m;:这个map以水果名称为键(string类型),以水果出现次数为值(size_t类型)。
遍历fruits向量,统计每种水果的出现次数:
for (auto e : fruits) m[e]++;:对于fruits向量中的每个元素e,在map m中增加它的计数。
定义一个multimap来按出现次数对水果进行排序:
multimap<size_t, string, greater<int>> mm;:这个multimap以水果出现的次数为键(size_t类型),以水果名称为值(string类型)。greater<int>使得元素按键(出现次数)的降序排序。
将map m中的元素插入到multimap mm中:
for (auto& e : m) { mm.insert(make_pair(e.second, e.first)); }:遍历map m,将每个元素(即每种水果及其出现次数)插入到multimap mm中,键值对颠倒,使得次数成为键,水果名称成为值。
打印出现次数最多的前k个水果:
for (auto& e : mm) { if (k == 0) return; cout << e.second << " "; k--; }:遍历multimap mm,打印出键值对中的值(即水果名称)。每打印一个减少k的值,直到k为0或遍历完成。由于mm是按次数降序排列的,这保证了最先打印的是出现次数最多的水果。
结尾
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!