目录
ElasticSearch聚合操作
基本语法
聚合的分类
后续示例数据
Metric Aggregation
Bucket Aggregation
ES聚合分析不精准原因分析
提高聚合精确度
ElasticSearch聚合操作
Elasticsearch除搜索以外,提供了针对ES 数据进行统计分析的功能。聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
什么品牌的手机最受欢迎?
这些手机的平均价格、最高价格、最低价格?
这些手机每月的销售情况如何?
基本语法
聚合查询的语法结构与其他查询相似,通常包含以下部分:
查询条件:指定需要聚合的文档,可以使用标准的 Elasticsearch 查询语法,如 term、match、range 等等。
聚合函数:指定要执行的聚合操作,如 sum、avg、min、max、terms、date_histogram 等等。每个聚合命令都会生成一个聚合结果。
聚合嵌套:聚合命令可以嵌套,以便更细粒度地分析数据。
GET <index_name>/_search
{"aggs": {"<aggs_name>": { // 聚合名称需要自己定义"<agg_type>": {"field": "<field_name>"}}}
}aggs_name:聚合函数的名称
agg_type:聚合种类,比如是桶聚合(terms)或者是指标聚合(avg、sum、min、max等)
field_name:字段名称或者叫域名。
聚合的分类
Metric Aggregation:—些数学运算,可以对文档字段进行统计分析,类比Mysql中的 min(), max(), sum() 操作。
SELECT MIN(price), MAX(price) FROM products
#Metric聚合的DSL类比实现:
{"aggs":{"avg_price":{"avg":{"field":"price"}}}
}Bucket Aggregation: 一些满足特定条件的文档的集合放置到一个桶里,每一个桶关联一个key,类比Mysql中的group by操作。
SELECT size COUNT(*) FROM products GROUP BY size
#bucket聚合的DSL类比实现:
{"aggs": {"by_size": {"terms": {"field": "size"}}
}后续示例数据
DELETE /employees
#创建索引库
PUT /employees
{"mappings": {"properties": {"age":{"type": "integer"},"gender":{"type": "keyword"},"job":{"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 50}}},"name":{"type": "keyword"},"salary":{"type": "integer"}}}
}PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "index" : { "_id" : "11" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "index" : { "_id" : "12" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "index" : { "_id" : "13" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "index" : { "_id" : "14" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "index" : { "_id" : "15" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "index" : { "_id" : "16" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "17" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "index" : { "_id" : "18" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "index" : { "_id" : "19" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "index" : { "_id" : "20" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}Metric Aggregation
单值分析︰只输出一个分析结果(min, max, avg, sum等)
多值分析:输出多个分析结果(stats(统计), extended stats等)
查询员工的最低最高和平均工资
#多个 Metric 聚合,找到最低最高和平均工资
POST /employees/_search
{"size": 0, "aggs": {"max_salary": {"max": {"field": "salary"}},"min_salary": {"min": {"field": "salary"}},"avg_salary": {"avg": {"field": "salary"}}}
}对salary进行统计
# 一个聚合,输出多值
POST /employees/_search
{"size": 0,"aggs": {"stats_salary": {"stats": {"field":"salary"}}}
}cardinate对搜索结果去重
POST /employees/_search
{"size": 0,"aggs": {"cardinate": {"cardinality": {"field": "job.keyword"}}}
}Bucket Aggregation
按照一定的规则,将文档分配到不同的桶中,从而达到分类的目的。ES提供的一些常见的 Bucket Aggregation。
Terms,需要字段支持filedata,如果是keyword 默认支持fielddata,如果是text需要在Mapping 中开启fielddata,会按照分词后的结果进行分桶。
数字类型支持Range / Data Range、Histogram(直方图) / Date Histogram。
支持嵌套: 也就在桶里再做分桶。
获取job的分类信息
# 对keword 进行聚合
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword"}}}
}聚合可配置属性有:
field:指定聚合字段。
size:指定聚合结果数量。
order:指定聚合结果排序方式。
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。我们可以指定order属性,自定义聚合的排序方式:
GET /employees/_search
{"size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}限定聚合范围
#只对salary在10000元以上的文档聚合
GET /employees/_search
{"query": {"range": {"salary": {"gte": 10000 }}}, "size": 0,"aggs": {"jobs": {"terms": {"field":"job.keyword","size": 10,"order": {"_count": "desc" }}}}
}ES聚合分析不精准原因分析
ElasticSearch在对海量数据进行聚合分析的时候会损失搜索的精准度来满足实时性的需求。
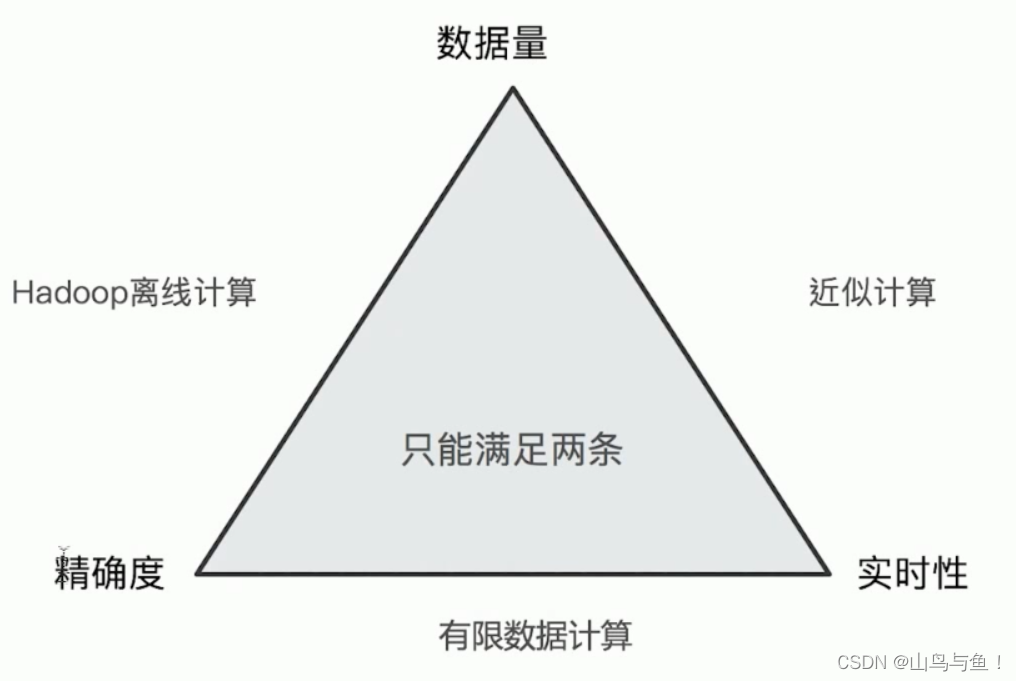
Terms聚合分析的执行流程:
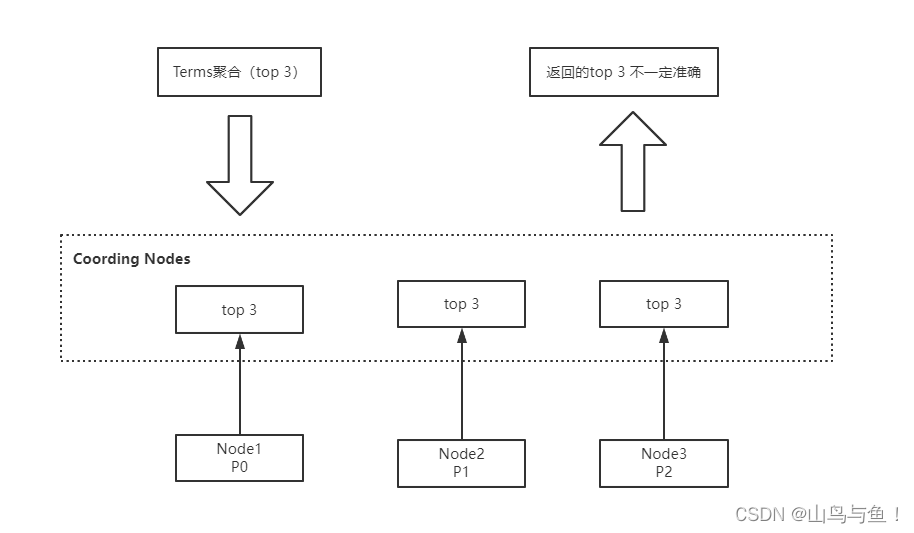
不精准的原因: 数据分散到多个分片,聚合是每个分片的取 Top X,导致结果不精准。ES 可以不每个分片Top X,而是全量聚合,但这会有很大的性能问题。
提高聚合精确度
方案1:设置主分片为1
注意7.x版本已经默认为1。
适用场景:数据量小的小集群规模业务场景。
方案2:调大 shard_size 值
设置 shard_size 为比较大的值,官方推荐:size*1.5+10。shard_size 值越大,结果越趋近于精准聚合结果值。此外,还可以通过show_term_doc_count_error参数显示最差情况下的错误值,用于辅助确定 shard_size 大小。
- size:是聚合结果的返回值,客户期望返回聚合排名前三,size值就是 3。
- shard_size: 每个分片上聚合的数据条数。shard_size 原则上要大于等于 size
适用场景:数据量大、分片数多的集群业务场景。
方案3:使用Clickhouse/ Spark 进行精准聚合
适用场景:数据量非常大、聚合精度要求高、响应速度快的业务场景。