Datawhale干货
作者:李孝杰,清华大学,Datawhale成员

从openai sora[1]的技术报告首段可以看出sora的野心远远不止视频生成,他们的目标是通过视频数据来学习一个世界模型或者世界模拟器,这才是真正令人兴奋和激动的部分。
1-数据工程
1-1 采用patches统一训练数据格式
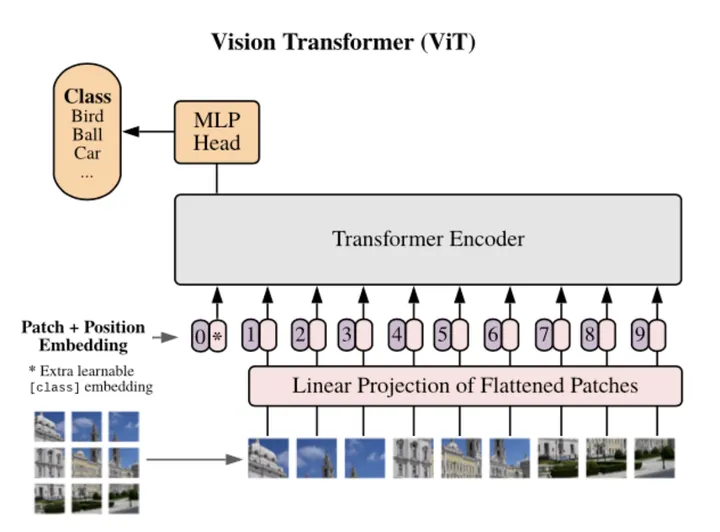
最早在ViT[2]中出现将图片分patch输入给transformer。
Sora的做法会有些不同,首先通过一个encoder【VAE结构】将视频帧压缩到一个低维度隐式空间(包含时间和空间上的压缩),然后展开成序列的形式送入模型训练,同样的模型预测也是隐式的序列,然后用decoder解码器去解码映射回像素空间形成视频。注意在编码成Spacetime latent patches的时候可能用到了ViViT[3]的时空编码方式
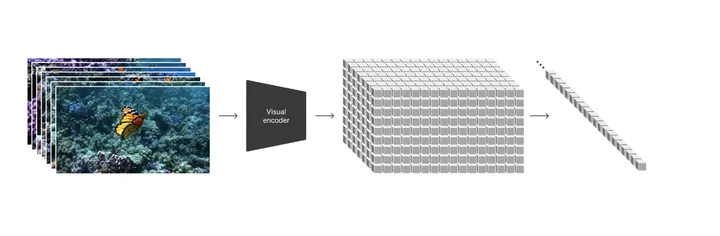
如此一来有两个优势:
统一互联网上不同大小格式的视频和图片数据,统一为patches的格式输入
具有可扩展性,类似于llm中的token,数据格式往往跟网络结构相匹配的
在推理阶段可以通过将patches组合成不同形状从而控制视频生成的尺寸大小
1-2 在原始图片尺寸上训练
优点是使得视频在生成采样时更具有灵活性,可以生成不同尺寸的视频
不需要像2D图片一样去做一些旋转、剪切等数据增强工作,这样反而会影响最终的生成效果,原因可能是因为本来的视频数据是人为拍摄的(具有合理的角度和构图先验),如果去做裁剪,反而破坏了这样的先验信息。从而导致空间的不合理以及时间的不连续。
不需要统一输入的尺寸,因为可以通过encoder将不同尺寸的视频压缩成patches的形式输入
1-3 使用re-captioning获得text-videos对
在训练阶段,将视频按1帧或者隔n帧用DALLE3(CLIP)按照一定的规范形成对应的描述文本,然后输入模型训练。
在推理阶段,首先将用户输入的prompt用GPT4按照一定的规范把它详细化,然后输入模型得到结果。
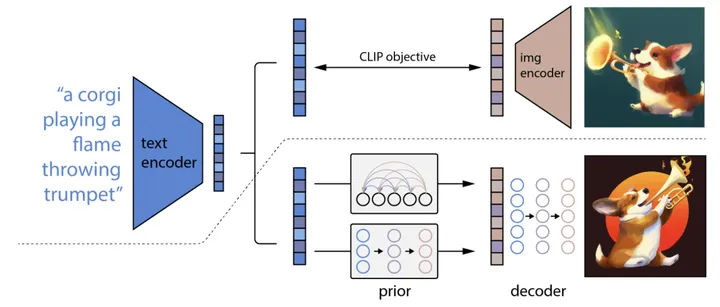
DALLE2结构
2-网络结构
2-1 DiT[4]
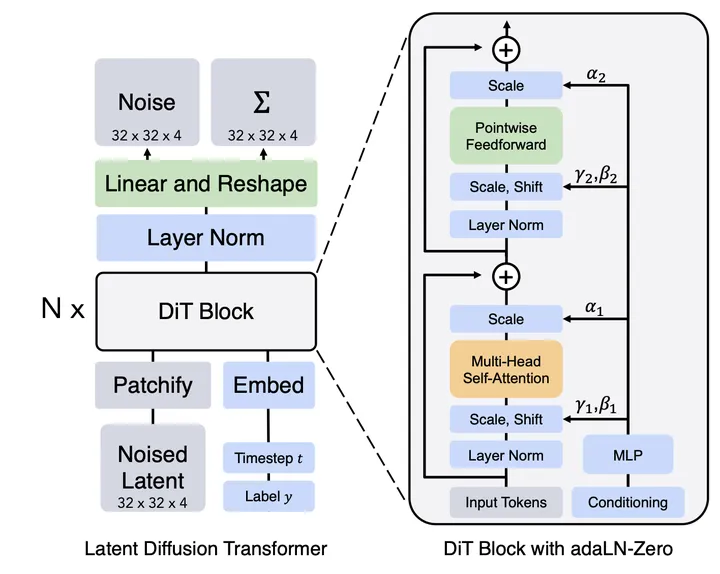
简单来说就是tansformer+ddpm,核心就是用tansformer的结构替换掉stable diffusion中的unet结构,来预测噪声实现去噪。这个替换可以带来以下优势。
随着数据规模或者训练时间的增强,模型表现的效果越好(大力出奇迹的前置条件)
实验表明,模型越大,patches越小,效果越好
2-2 整体结构
参考b站up主ZOMI酱的画的Sora结构[5]。
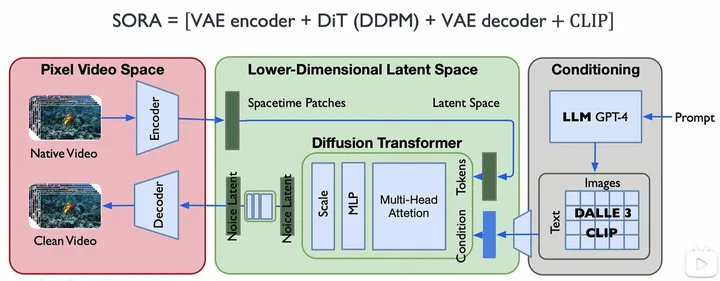
这张图感觉相对完整准确了,这里补充几点可能的改动和补充。
在Conditioning阶段可能不是一帧对应一个文本,而可能是几帧十几帧对应一段文本描述
在编码成Spacetime latent patches的时候可能用到了ViViT[3]的时空编码方式
输入给Decoder的内容应该是去噪之后的patches序列,这里用patches描述比tokens更准确
3-影响
首当其冲当然是影视和短视频行业,之后可能会推出sora的迭代,生成的时间可能更长类比chatgpt不断增大的输入token,可能sora以后可以生成更多更长的patches。比单纯的视频生成更有价值的是这条道路能不能通向大家都神往的AGI。似乎至少出现了苗头~
3-1 世界模型[6]?
大家广泛讨论和关注的是sora到底是不是或者具不具备世界模型的特征。
简单来讲Sora 具有以下几项能力:
3D一致性。Sora可以生成具有动态摄像机运动的视频。随着摄像机的移动和旋转,人物和场景元素在三维空间中保持一致移动。可以认为它具有3D建模和3D生成的能力(可能还不够强,跟3D Gaussain[7]或者NeRF这种需要现实中的带位姿的图片来建模3D场景的能力还有一定细节差距)
长程一致性和物体永久性。对于视频生成系统来说,一个重要的挑战是在采样长视频时保持时间上的一致性。我们发现,Sora通常能够有效地建模短程和长程的依赖关系,尽管并非总是如此。例如,我们的模型可以在人、动物和物体被遮挡或离开画面时仍然保持它们的存在。同样,它可以在一个样本中生成同一角色的多个镜头,并在整个视频中保持它们的外观。
与世界互动。Sora有时可以模拟对世界产生简单影响的动作。例如,画家可以在画布上留下持续存在的新笔触,或者一个人可以吃掉一个汉堡并留下咬痕。可以实现一定程度的物理交互,但是很多时候还是有幻觉或者不准确,但毕竟它竟然可以“实现“!这个能力简直是王炸,CG还需要复杂的光锥模拟、渲染么?还需要复杂的方程和绑定控制么?流体毛发的研究还有价值么?
模拟数字世界。Sora还能够模拟人工过程,一个例子是视频游戏。Sora可以同时使用基本策略控制Minecraft中的玩家,同时以高保真度渲染世界及其动态。通过提示Sora提到“Minecraft”的标题,可以激发这些能力。
很多大佬抨击深度学习不可解释性,可是这种解释性如果在模拟/生成的足够准确的情况下还有没有意义?(sora离足够准确还有一定的距离)
没有学过牛顿力学的人一样可以预测/知道物体自由落体的轨迹;没有学过压力和摩擦力的人一样能预测行驶中的自行车按住刹车的轨迹....对于模型或者机器的学习,是否一定要某个理论或者强制的条件约束?让它只依靠数据经验学习到底可不可行?
3-2 CV大一统?
Sora视频的生成能力同样可以扩展到2D和3D的生成,同样也影响诸如感知、理解等2D/3D任务,如果未来继续迭代变强,似乎能实现CV的大一统,并消灭CG。如果实现CV大一统,那么整个AI都在基于transformer的大力出奇迹的架构下实现了大一统。
参考
[1] https://openai.com/research/video-generation-models-as-world-simulators
[2] https://arxiv.org/abs/2010.11929
[3] abhttps://arxiv.org/pdf/2103.15691.pdf
[4] https://arxiv.org/abs/2212.09748
[5] https://www.bilibili.com/video/BV1Bx4y1k7BQ
[6] https://worldmodels.github.io/
[7] https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/