ChatGPT在综合数据处理中的应用
在实际工作中,一个需求往往需要多个单一操作的组合才能完成。
1.1 案例1: 多条件数据匹配合并
在Excel中,单一条件的匹配合并比较简单,只需一个简单的VLOOKUP函数即可实现。而多条件匹配合并稍微有些难度,仅靠简单的VLOOKUP函数无法实现。来看一个用ChatGPT进行多条件匹配的案例。发送如下内容ChatGPT。

ChatGPT收到上述内容以后,返回如下结果。
表1(商品价格信息)
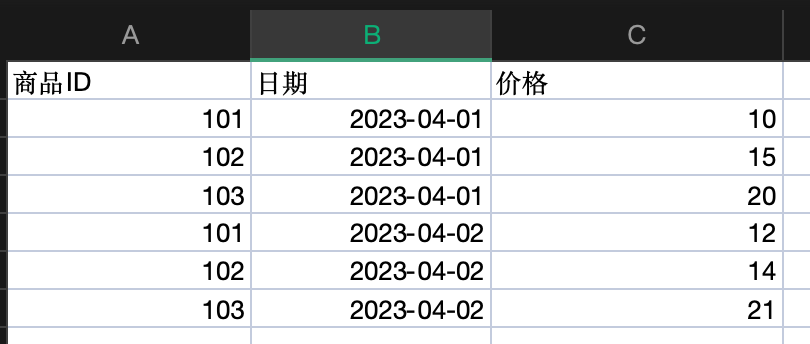
表2(订单信息)
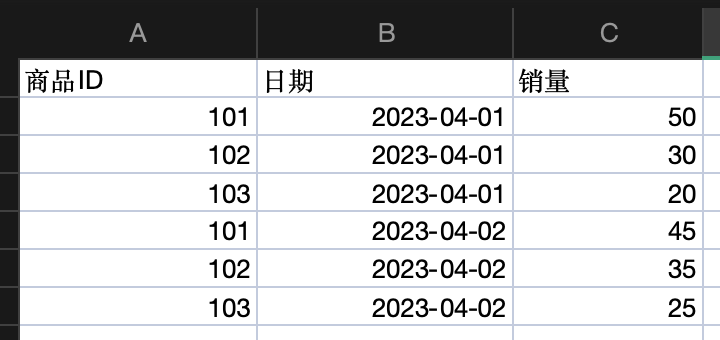
Excel实现步骤使用INDEX和MATCH函数:
-
打开Excel并创建一个新工作表。
-
将表1的商品价格信息(商品ID、日期、价格)和表2的订单信息(商品ID、日期、销量)分别复制粘贴到新工作表中,确保每列数据与对应的表格中列标题一致。
-
在新工作表中创建一个新列标题:“销量”。
-
使用Excel的INDEX和MATCH函数来根据商品ID和日期匹配合并价格和销量信息。在新的“价格”列中输入以下公式,假设商品ID从A2开始,日期从B2开始:
=INDEX(表1!C2:C7, MATCH(表2!A2&表2!B2, 表1!A2:A7&表1!B2:B7, 0))这个公式将根据商品ID和日期从表1中查找匹配的价格。
-
选中价格列中的公式,然后按Ctrl+Shift+Enter组合键,使其成为数组公式。Exce将在公式周围添加大括号({})以表示它是一个数组公式。
-
将价格列中的数组公式向下拖动,使其应用于所有行。
-
最后,在新工作表中应该有四列:商品ID、日期、价格、销量。
-
确保检查所有数据行是否正确匹配,并保存这个新生成的表格。
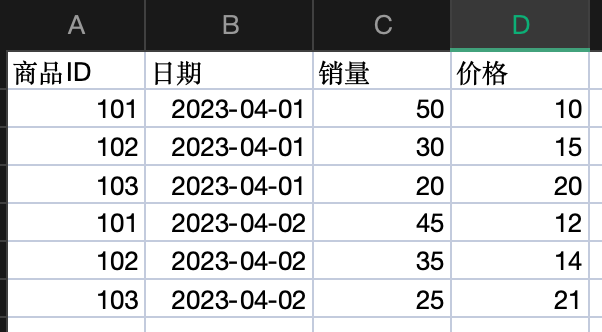
通过以上步骤,你应该能够将两个Excel表格根据商品ID和日期进行匹配合并,生成包含商品ID、日期、价格和销量的新表格,同时使用了INDEX和MATCH函数。希望这次回答符合您的要求。
ChatGPT不仅给出了详细的操作步骤,还给出了相应的样例数据。大家可以跟着实现一遍,得出的结果也是正确的。
1.2 案例2: 多表合并与拆分
多表的合并与拆分也是比较高频的操作。很多时候大家苦于没有好的办法,只能手动处理,效率很低。来看一个用ChatGPT进行多表合并与拆分的案例。发送如下内容给ChatGPT。

ChatGPT收到上述内容后,返回如下结果。
好的,我将为您生成三个城市的订单数据表,每张表包含订单ID、订单日期、订单城市、订单金额,每个表包含5条数据。
表1 - 城市:New York
订单ID 订单日期 订单城市 订单金额
1001 2024-02-20 New York $150
1002 2024-02-21 New York $200
1003 2024-02-22 New York $180
1004 2024-02-23 New York $220
1005 2024-02-24 New York $250
表2 - 城市:Los Angeles
订单ID 订单日期 订单城市 订单金额
2001 2024-02-20 Los Angeles $120
2002 2024-02-21 Los Angeles $180
2003 2024-02-22 Los Angeles $150
2004 2024-02-23 Los Angeles $190
2005 2024-02-24 Los Angeles $210
表3 - 城市:Chicago
订单ID 订单日期 订单城市 订单金额
3001 2024-02-20 Chicago $100
3002 2024-02-21 Chicago $130
3003 2024-02-22 Chicago $110
3004 2024-02-23 Chicago $140
3005 2024-02-24 Chicago $160
以上是三个城市(New York、Los Angeles、Chicago)各自的订单数据表,每张表包含5条订单信息,包括订单ID、订单日期、订单城市和订单金额。您可以根据需要将这些数据输入到Excel表格中。
接着向ChatGPT提问,发送如下内容。

ChatGPT收到上述内容以后,返回如下结果。
要将三张表合并成一张表,再根据订单城市分拆成三张表,可以按照以下步骤在Excel中实现:
合并三张表为一张表
- 打开Excel,依次将三张表的数据复制到同一个工作表中,确保数据分别位于不同的区域。可以将每张表的数据粘贴到新的行或列中。
拆分合并后的表
-
选中合并后的表格数据。
-
在Excel中,选择“数据”选项卡,然后选择“分类”(或“筛选”)。
-
在分类(或筛选)功能中,选择“分类”(或“高级筛选”)。
-
在分类对话框中,选择“按列”中的“订单城市”列,然后点击“确定”。
-
Excel将根据“订单城市”列中的不同数值,将数据拆分成不同的区域。
-
每个城市的数据将被分到不同的区域中,您可以将每个区域的数据复制到新的工作表中,以得到独立的城市订单数据表。
通过以上步骤,您可以在Excel中将三张表合并成一张表,然后根据订单城市将合并后的表拆分成三张表,每张表包含特定城市的订单数据。这样您就可以轻松管理和分析这些数据了。
ChatGPT可能认为只有三张表,手动处理要比写VBA代码更高效。确实如此,但我们想要的其实是VBA代码。发送如下内容给ChatGPT。

ChatGPT收到上述内容后,返回如下结果。
当涉及大量表格数据时,手动合并和拆分可能会变得非常繁琐和耗时。幸运的是,Excel提供了一些自动化工具和功能,可以帮助简化这个过程。您可以尝试使用Excel中的宏(Macro)或Power Query(数据导入和转换)来自动处理大量表格数据。
使用宏(Macro):
-
打开Excel,依次将100张表的数据复制到同一个工作表中,确保数据分别位于不同的区域。
-
在Excel中,选择“开发人员”选项卡。如果未看到此选项卡,请启用开发人员选项卡(通过Excel选项设置)。
-
在“开发人员”选项卡中,点击“录制宏”按钮,然后依次执行合并和拆分的操作。
-
在录制宏过程中,可以使用Excel的功能和快捷键进行操作。
-
完成录制后,停止录制宏,然后保存宏。
-
您可以随时运行这个宏,以自动执行之前录制的操作。
使用Power Query:
-
打开Excel,依次将100张表的数据导入到Power Query中(可以通过数据选项卡中的“获取数据”功能实现)。
-
在Power Query中,合并所有导入的数据表。
-
使用“分组”功能,按照订单城市拆分数据。
-
最后,将每个城市的数据导出到新的工作表中。
这些方法可以帮助您自动化处理大量表格数据,节省时间和提高效率。选择适合您需求的方法,并根据具体情况调整操作步骤。
但是我想用VBA实现这个100张表的合并和拆分的功能。我向ChatGPT发送如下内容。
ChatGPT收到上述内容后,返回如下结果。
当处理大量表格数据时,使用VBA(Visual Basic for Applications)可以帮助自动化这一过程。以下是一个示例VBA代码,演示如何使用VBA在Excel中合并100张表并根据订单城市拆分数据:### VBA代码示例:
Sub MergeAndSplitTables()Dim ws As WorksheetDim wsMerged As WorksheetDim wsCity As WorksheetDim i As Integer' 创建一个新工作表用于合并数据Set wsMerged = ThisWorkbook.Sheets.Add(After:=Sheets(Sheets.Count))wsMerged.Name = "MergedData"' 合并100张表For i = 1 To 100Set ws = ThisWorkbook.Sheets("表" & i) ' 假设表格名称为表1、表2、表3...ws.UsedRange.Copy Destination:=wsMerged.Cells(wsMerged.Rows.Count, 1).End(xlUp).Offset(1)Next i' 创建新工作表用于拆分数据Set wsMerged = ThisWorkbook.Sheets("MergedData")' 按照订单城市拆分数据For i = 2 To wsMerged.UsedRange.Rows.Countcity = wsMerged.Cells(i, 3).Value ' 假设订单城市在第3列Set wsCity = NothingOn Error Resume NextSet wsCity = ThisWorkbook.Sheets(city)On Error GoTo 0If wsCity Is Nothing ThenSet wsCity = ThisWorkbook.Sheets.Add(After:=Sheets(Sheets.Count))wsCity.Name = citywsMerged.Rows(1).Copy Destination:=wsCity.Rows(1)End IfwsMerged.Rows(i).Copy Destination:=wsCity.Cells(wsCity.Rows.Count, 1).End(xlUp).Offset(1)Next i
End Sub### 如何运行 VBA 代码:1. 打开Excel文件,按下 `Alt + F11` 打开 VBA 编辑器。2. 在 VBA 编辑器中,选择 `插入 -> 模块`,将上面的代码粘贴到模块中。3. 关闭 VBA 编辑器,按下 `Alt + F8` 打开宏窗口,选择 `MergeAndSplitTables` 宏并点击运行。这段VBA代码将合并名为“表1”到“表100”的表格数据到一个名为“MergedData”的新工作表中,然后根据订单城市将数据拆分到不同的工作表中。请根据实际情况调整代码中的表格名称、列索引等参数。
可以看到,ChatGPT给出了自动实现合并与拆分的VBA代码,我们只需根据实际情况稍微调整即可。我们还可以让ChatGPT给出相应的Python代码。发送如下内容给ChatGPT。

ChatGPT收到上述内容后,返回如下结果。
您可以使用Python的 pandas 库来处理 Excel 文件。以下是一个示例代码,演示如何使用 Python 在 Excel 中合并 100 张表并根据订单城市拆分数据:import pandas as pd# 读取并合并100张表
dfs = []
for i in range(1, 101):df = pd.read_excel('表{}.xlsx'.format(i)) # 假设表格文件名为 表1.xlsx、表2.xlsx、表3.xlsx...dfs.append(df)merged_df = pd.concat(dfs)# 根据订单城市拆分数据
cities = merged_df['订单城市'].unique() # 假设订单城市列名为 '订单城市'
for city in cities:city_df = merged_df[merged_df['订单城市'] == city]city_df.to_excel('{}.xlsx'.format(city), index=False) # 将每个城市的数据保存到单独的 Excel 文件中### 注意事项:1. 确保安装了 pandas 库。如果尚未安装,可以使用 `pip install pandas` 命令进行安装。2. 确保 Excel 文件的路径和名称与代码中指定的一致。3. 确保 Excel 文件中的表格数据格式正确,包含订单城市列和其他必要列。通过运行上述代码,您可以将 100 张 Excel 表格数据合并到一个 DataFrame 中,然后根据订单城市将数据拆分并保存到单独的 Excel 文件中。您可以根据实际情况调整代码中的列名和文件路径。
案例4: 累计销量计算
直接聚合运算比较简单,比它稍微难一点的是累计聚合运算,我们来问ChatGPT如何实现。发送如下内容给ChatGPT。

ChatGPT收到上述内容后,返回如下结果。

ChatGPT收到上述内容后,返回如下结果。
在 Hive SQL 中,您可以使用窗口函数(Window Function)来计算随着时间推移每个suid的累计销量。以下是一个示例代码,展示如何在 Hive SQL 中实现这一需求:-- 创建示例表 sale_table
CREATE TABLE sale_table (suid INT,sdate DATE,sales INT
);-- 插入示例数据
INSERT INTO sale_table VALUES
(1, '2024-01-01', 100),
(1, '2024-01-02', 150),
(1, '2024-01-03', 200),
(2, '2024-01-01', 50),
(2, '2024-01-02', 75);-- 使用窗口函数计算每个suid的累计销量
SELECT suid,sdate,sales,SUM(sales) OVER (PARTITION BY suid ORDER BY sdate ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_sales
FROM sale_table
ORDER BY suid, sdate;在上面的示例代码中,首先创建了一个名为 sale_table 的表,包含 suid(销售人员ID)、sdate(日期)、sales(销量)字段。然后插入了示例数据。接着,使用窗口函数 `SUM() OVER (PARTITION BY suid ORDER BY sdate ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)` 来计算每个 suid 的累计销量。窗口函数按照 suid 分区,并按照 sdate 排序,计算从最早日期到当前日期的销量累计值。最后,查询结果会按照 suid 和 sdate 排序,显示每个销售人员在不同日期的销量以及累计销量。您可以根据实际情况调整字段名、表名和数据类型。这样,您就可以在 Hive SQL 中计算每个销售人员随着时间推移的累计销量。
ChatGPT不仅给出了实现代码,还给出了关于代码中各部分的解释说明。
1.5 案例5: 用户留存率计算
留存率是数据分析中一个比较关键的指标,其计算也成了一个高频需求,我们来问ChatGPT如何实现。发送如下内容给ChatGPT。

ChatGPT收到上述内容以后,返回如下结果。
在 Hive SQL 中,您可以使用子查询和连接来计算每天活跃用户的次日留存率、3日留存率和7日留存率。以下是一个示例代码,展示如何在 Hive SQL 中实现这一需求:sql
Copy code-- 创建示例表 user_table
CREATE TABLE user_table (uid INT,actday DATE
);-- 插入示例数据
INSERT INTO user_table VALUES
(1, '2024-01-01'),
(2, '2024-01-01'),
(3, '2024-01-01'),
(1, '2024-01-02'),
(2, '2024-01-02'),
(4, '2024-01-02');-- 计算每天活跃用户的次日留存率、3日留存率和7日留存率
WITH active_users AS (SELECT DISTINCT uid, actday AS active_dateFROM user_table
),
day1_retention AS (SELECT a.active_date AS reference_date,COUNT(DISTINCT b.uid) AS day1_retained_usersFROM active_users aJOIN user_table b ON a.uid = b.uid AND date_add(a.active_date, 1) = b.actdayGROUP BY a.active_date
),
day3_retention AS (SELECT a.active_date AS reference_date,COUNT(DISTINCT b.uid) AS day3_retained_usersFROM active_users aJOIN user_table b ON a.uid = b.uid AND date_add(a.active_date, 3) = b.actdayGROUP BY a.active_date
),
day7_retention AS (SELECT a.active_date AS reference_date,COUNT(DISTINCT b.uid) AS day7_retained_usersFROM active_users aJOIN user_table b ON a.uid = b.uid AND date_add(a.active_date, 7) = b.actdayGROUP BY a.active_date
)
SELECT d1.reference_date,d1.day1_retained_users,d3.day3_retained_users,d7.day7_retained_users
FROM day1_retention d1
LEFT JOIN day3_retention d3 ON d1.reference_date = d3.reference_date
LEFT JOIN day7_retention d7 ON d1.reference_date = d7.reference_date;在上面的示例代码中,首先创建了一个名为 user_table 的表,包含 uid(用户ID)和 actday(活跃日期)字段,并插入了示例数据。然后,通过使用 WITH 子句创建了三个子查询,分别计算次日留存率、3日留存率和7日留存率。每个子查询都是基于活跃用户表 active_users 和原始用户表 user_table 进行连接计算留存用户数。最后,将每天的次日留存率、3日留存率和7日留存率结果连接在一起并输出。您可以根据实际情况调整字段名、表名和数据类型,以计算每天活跃用户的留存率。
ChatGPT给出的结果有点繁琐,代码重复使用,是否应该重构一下?我们给出修改提示,发送如下内容给ChatGPT,内容如下。

ChatGPT收到上述内容以后,返回如下结果。
当计算次日留存率、3日留存率和7日留存率时,确实存在一定程度的代码重复。您可以通过创建一个通用的子查询来避免重复,并在查询结果中计算不同的留存率。以下是重构后的代码:-- 创建示例表 user_table
CREATE TABLE user_table (uid INT,actday DATE
);-- 插入示例数据
INSERT INTO user_table VALUES
(1, '2024-01-01'),
(2, '2024-01-01'),
(3, '2024-01-01'),
(1, '2024-01-02'),
(2, '2024-01-02'),
(4, '2024-01-02');-- 计算每天活跃用户的次日留存率、3日留存率和7日留存率
WITH active_users AS (SELECT DISTINCT uid, actday AS active_dateFROM user_table
),
retention_data AS (SELECT a.active_date AS reference_date,COUNT(DISTINCT CASE WHEN b.actday = date_add(a.active_date, 1) THEN b.uid END) AS day1_retained_users,COUNT(DISTINCT CASE WHEN b.actday = date_add(a.active_date, 3) THEN b.uid END) AS day3_retained_users,COUNT(DISTINCT CASE WHEN b.actday = date_add(a.active_date, 7) THEN b.uid END) AS day7_retained_usersFROM active_users aJOIN user_table b ON a.uid = b.uidGROUP BY a.active_date
)
SELECT reference_date,day1_retained_users,day3_retained_users,day7_retained_users
FROM retention_data;在上述代码中,通过创建一个名为 retention_data 的子查询,使用 CASE WHEN 语句对不同的留存天数进行计数,避免了重复代码。子查询中计算了次日留存用户数、3日留存用户数和7日留存用户数,并将结果输出。通过这种方式,您可以更加简洁和高效地计算每天活跃用户的次日留存率、3日留存率和7日留存率,避免了代码重复使用的问题。您可以根据实际情况调整字段名、表名和数据类型。
这个代码好像还有点问题,user_table a 与user_table b 之间是用JOIN连接的,这会忽略那些没有留存的用户,而在计算留存率时,没有留存的应该算在分母里。我们再给出修改提示,发送如下提示内容给ChatGPT。
ChatGPT收到上述内容后,返回如下结果。
在进行自连接时,通常应该使用 LEFT JOIN 而不是 INNER JOIN,以确保即使没有匹配的记录也能够保留左表(自连接中的主表)的所有记录。这样可以避免丢失活跃用户的数据,确保计算留存率时不会漏掉任何活跃用户。使用 LEFT JOIN 还可以更好地处理活跃用户表中可能存在的空数据或者缺失数据的情况。在上面重构后的代码中,使用了 INNER JOIN 进行自连接,这可能会导致在某些情况下丢失部分活跃用户的数据,特别是当某些活跃用户在后续日期没有相应的记录时。因此,建议在这种情况下使用 LEFT JOIN 来确保所有活跃用户的数据都被考虑在内,以计算正确的留存率。以下是修改后的代码示例:-- 计算每天活跃用户的次日留存率、3日留存率和7日留存率
WITH active_users AS (SELECT DISTINCT uid, actday AS active_dateFROM user_table
),
retention_data AS (SELECT a.active_date AS reference_date,COUNT(DISTINCT CASE WHEN b.actday = date_add(a.active_date, 1) THEN b.uid END) AS day1_retained_users,COUNT(DISTINCT CASE WHEN b.actday = date_add(a.active_date, 3) THEN b.uid END) AS day3_retained_users,COUNT(DISTINCT CASE WHEN b.actday = date_add(a.active_date, 7) THEN b.uid END) AS day7_retained_usersFROM active_users aLEFT JOIN user_table b ON a.uid = b.uidGROUP BY a.active_date
)
SELECT reference_date,day1_retained_users,day3_retained_users,day7_retained_users
FROM retention_data;通过使用 LEFT JOIN,确保了即使活跃用户在后续日期没有相应的记录,也会被保留在结果中,从而更准确地计算每天活跃用户的次日留存率、3日留存率和7日留存率。
修改以后的 结果是正确的。