自然语言处理二-attention 注意力机制
- 自然语言处理二-attention 注意力
- 记忆能力
- 回顾下RNN(也包括LSTM GRU)解决memory问题
- 改进后基于attention注意力的model
- match操作
- softmax操作
- softmax值与hidder layer的值做weight sum 计算和
- 将计算出来的和作为memory,成为decoder输入的一部分
- 依次计算decoder其他输入
自然语言处理二-attention 注意力
自然语言处理离不开attention的概念,当然attention的机制不仅仅用在自然语言处理。
那么attention到底是什么呢?Attention可以理解成一种记忆能力,而人工智能需要具备推理、人工智慧等能力,那记忆能力就必不可少。
记忆能力
记忆能力分为三种sensory memory、working memory、Long-term memory
Sensory memory记忆的时间很短,一般通过外界输入,比如眼睛和耳朵可以看到的东西
Working memory 真正感知世界的信息,选择人应该attention的东西,比如眼睛一瞬间可以看到很多东西,但我们会根据当下的需要,attention其中的一部分。
Long-term memory 真正要 处理 感知到的这些信息,还需要长期记忆,从长期记忆中提取到本次处理需要的信息,然后处理了后再encode到长期记忆中。比如说我们看到本次讲课的内容,需要回忆很久之前课程讲解的内容,消化后我们会再更新到长期记忆中。
整个过程就如下:
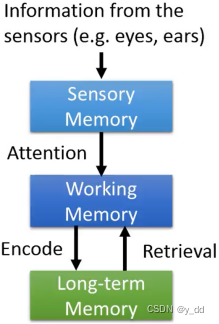
生物学上的注意力,也是遵从这个过程的。
Attention based的model如果对应于上述memory的处理过程,其实可以分为两部分:
1.第一部分是sensory memory和working memory之间,这部分用于处理模型的输入,用于关注模型中的部分输入。
2.第二部分是working memory和long-term之间,这部分也不陌生在老的模型,RNN和LSTM等模型中就具备这种记忆能力,但是这些模型有些缺点,越大的memory就意味着更多的参数,比如RNN中需要memory是K*K大小(K是memory size),参数过多很容易overfit(过拟合)。但是attention based的model就解决了这种问题,参加memory的size不会增加参数数量,这部分会在后面解释。
回顾下RNN(也包括LSTM GRU)解决memory问题
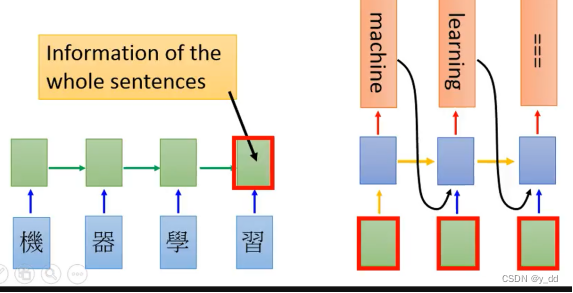
下面用RNN代表RNN LSTM GRU等,我们以前用RNN实现机器翻译是用的seq2seq的model,模型的实现架构如上图,这个里面是如何实现记忆能力的呢?
RNN中最后一个hidden layer的输出,作为解码器每一个单元的输入的一部分,也就是图中红框的部分,这就实现了解码的时候可以具有记忆功能了。但是最后一层的输出真的能代表整个输入的信息么?答案肯定是不能,所以我们有了新的模型,attention based的model
改进后基于attention注意力的model
这个model改进了上面RNN model的缺陷,增加了attention的处理。
要实现attention需要经过下面这些步骤
match操作
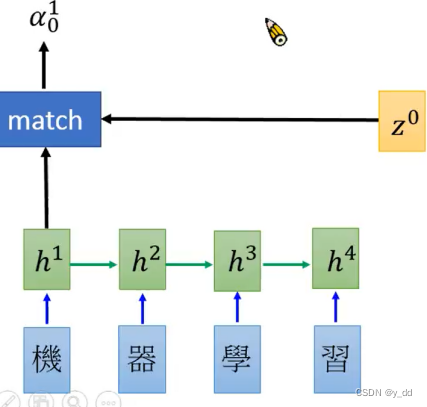
图中字符标识意义:
z0:vector(向量),相当于RNN中init的memory。
match:function(操作)
a 01 : 输入h1与z0经过match操作后的结果
这个match操作有很多不同的做法,不同的论文中不同:
1.cosine z 和h
2.一个小的nn的网络,input是z和h,输出是一个标量
3.hTWz,h的转置乘上一个矩阵W,乘上矩阵h
第2 3中是有参数的,该怎么学习获得呢?这部分下面会讲到。
用match操作对Encoder的hidden layer都计算一下,得到如下:
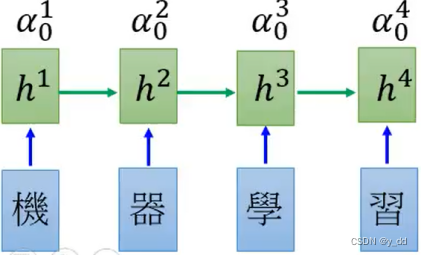
softmax操作
对上面得到的每一个a做softmax,目的是希望这些值的和是1。
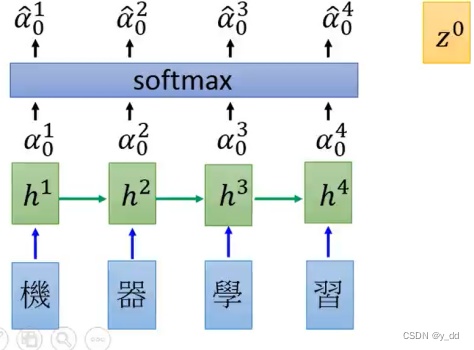
值得注意的是,这些操作跟seq的长度是没有关系的。
softmax值与hidder layer的值做weight sum 计算和
也就是下图中c0
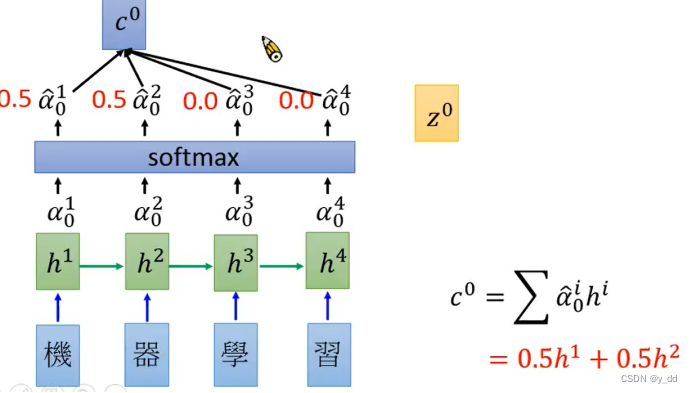
上图以softmax计算出来为0.5 0.5 0.0 0.0为例,出来的结果就是右图的c0
这个结果就表示说,我们这次的输入更关注前面两个的输入。
将计算出来的和作为memory,成为decoder输入的一部分
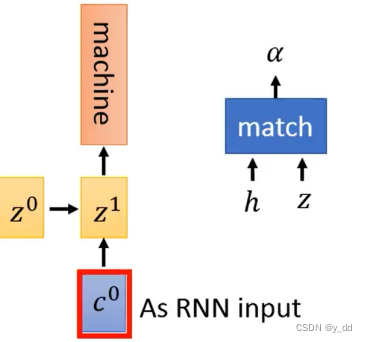
获取到c0 与z0之后经过 attintion的model生成了Z1
这时候可以解答上面如果需要learn的参数问题了,因为我们知道输出应该是machine,通过反向传播调整这个值,可以依次调整c0 ,最终调整到match操作中的参数。
依次计算decoder其他输入
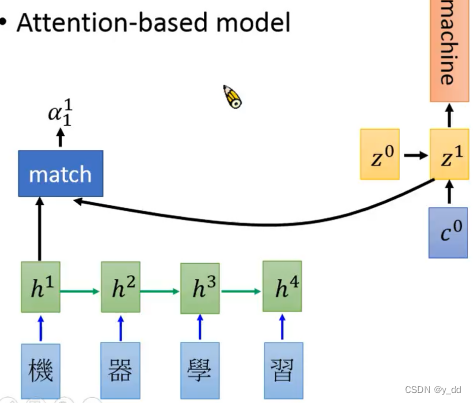
获得Z1后,继续与z0做相同的操作,与hidden layer做match,softmax等生成c1
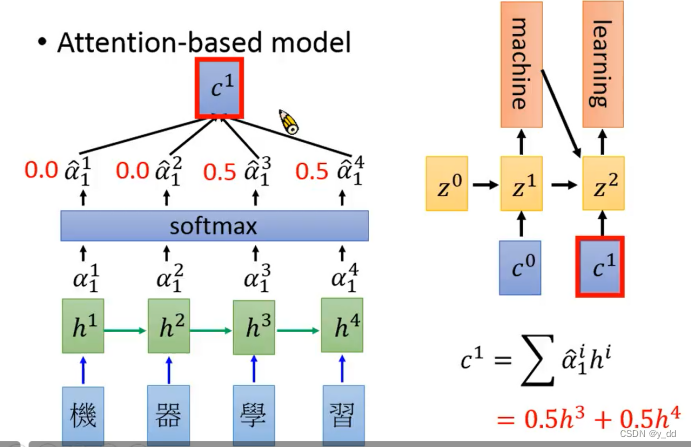
然后依次计算,一直遇到结束符。
模型就这样具备了记忆能力,当然也有其缺陷,所以后来也产生了自注意,这部分在后面的文章中会继续介绍。