项目地址:https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
文章目录
- 摘要
- 一、前言
- 二、Nerual Network Diffusion (神经网络扩散)
- 2.1扩散模型(预备知识)
- 2.2 总览
- 2.3 参数自动编码器
- 2.4 参数生成
- 三、实验
- 3.1 设置
- 3.2 结果
- 3.3 消融实验与分析
- 四、P-diff只是记忆吗?
- 4.1 问题和实验设计
- 4.2 相似性指标
- 4.3 预测的相似性
- 4.4 潜在表示的比较
- 4.5 p-diff过程的运动轨迹
- 4.6 从记忆到生成新的参数
- 五、相关工作
- 1.引入库
- 2.读入数据
- 总结
摘要
扩散模型在图像和视频生成方面取得了显著的成功。这项工作证明了,扩散模型也可以生成高性能的神经网络参数:利用一个自动编码器和一个标准的潜在扩散模型。自动编码器提取训练后的网络参数子集的潜在表示。然后训练一个扩散模型,从随机噪声中合成这些潜在的参数表示。然后,它生成新的表示,通过自动编码器的解码器,其输出准备用作网络参数的新子集。
在不同的架构和数据集上,我们的扩散过程始终以最小的额外成本生成与训练网络相比的性能相当或改进的模型。值得注意的是,我们根据经验发现,生成的模型与训练后的网络表现不同。
一、前言
扩散模型的起源可以追溯到非平衡热力学。在(Sohl-Dickstein等人)中,首先利用扩散过程逐步去除输入中的噪声,并生成清晰的图像。后来的工作,如DDPM和DDIM,采用了以正向过程和反向过程为特征的训练范式,细化了扩散模型。
当时,由扩散模型生成的图像的质量还没有达到预期的水平。Guided-Diffusion进行了消融,找到了更好的架构,这代表了将扩散模型超越基于GAN的方法的开创性努力。随后,GLIDE、Imagen、DALL·E2和SD实现了艺术家所采用的逼真图像。
扩散模型在其他领域的潜力:本文展示了扩散模型在生成高性能模型参数方面的惊人能力,这是一项与传统的视觉生成有根本不同的任务。 参数生成的重点是创建能够在给定任务上表现良好的神经网络参数。从先验和概率建模方面进行了探索,即 随机神经网络 和 贝叶斯神经网络。然而,在参数生成中使用扩散模型还没有得到很好的探索。
仔细研究神经网络训练和扩散模型,基于扩散的图像生成 与 随机梯度下降(SGD)学习过程在以下几个方面有共同之处 (如图1,顶部为扩散过程;底部为ResNet-18在CIFAR-100训练过程中批归一化(BN)的参数分布。上半部分为BN权重,下半部分为 BN偏差。)
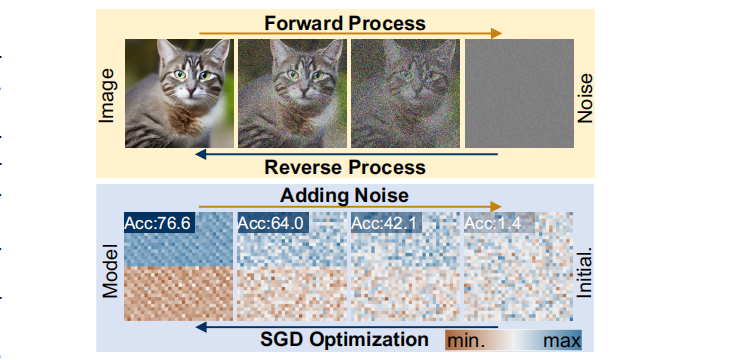
i)神经网络训练和扩散模型的反向过程都可以看作是从随机噪声/初始化到特定分布的过渡。
ii)高质量的图像和高性能的参数也可以通过多重噪声的添加而退化为简单的分布,如高斯分布。
基于上述观察,我们引入了一种新的参数生成方法,即神经网络扩散 p-diff(p代表参数),该方法采用了一个标准的潜在扩散模型来合成一组新的参数。这是由于扩散模型有能力将给定的随机分布转换为特定的随机分布。首先,对于由SGD优化器训练的模型参数的一个子集,我们训练自动编码器来提取这些参数的潜在表示。然后,我们利用一个标准的潜在扩散模型来综合来自随机噪声的潜在表示。最后,将合成的潜在表示通过经过训练的自动编码器的解码器,得到新的高性能模型参数。
我们的方法有以下特点:
i)它在几秒内跨多个数据集和架构实现相似甚至增强的性能,即由SGD优化器训练的模型。
ii)我们生成的模型,与训练好的模型有很大的差异,这说明我们的方法可以合成新的参数,而不是记忆训练样本。
二、Nerual Network Diffusion (神经网络扩散)
2.1扩散模型(预备知识)
扩散模型通常由由 timesteps 索引的多步链中的正向和反向过程组成
前向过程
给定一个样本 x0∼q (x),正向过程在T步中,逐步增加的高斯噪声,得到x1、x2、···、xT:
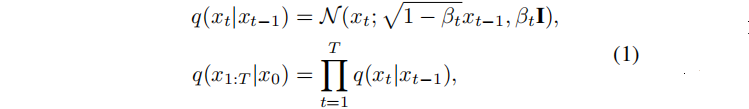
其中q和N表示前向过程,以及由 βt 参数化的高斯噪声,I 为单位矩阵。
反向过程
反向过程的目的是训练一个去噪网络递归地去除 xt 中的噪声。当t从T减少到0时,它在多步链上向后移动。数学表述为:
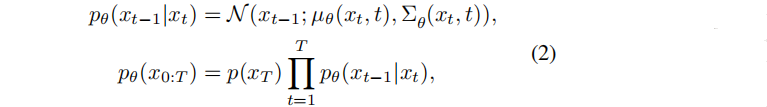
其中p表示反向过程,µθ(xt, t) 和 Σθ(xt, t) 是由去噪网络参数θ估计的高斯均值和方差。去噪网络采用标准负对数似然法 进行优化(DKL(·||·) 为KL散度):
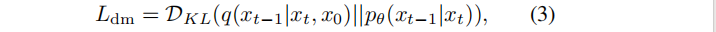
训练扩散模型的目标是找到在每个时间步长t中,最大化 forward transitions的似然的 reverse transitions。在实践中,训练等价地由最小化变分上界构成。推理过程的目的,是通过优化去噪参数θ∗ 和反向的多步链,从随机噪声中生成新的样本。
训练和推理程序
2.2 总览
神经网络扩散 p-diff ,目的是从随机噪声中生成高性能的参数。如图2所示,方法由两个过程组成,即参数自动编码器和生成器。
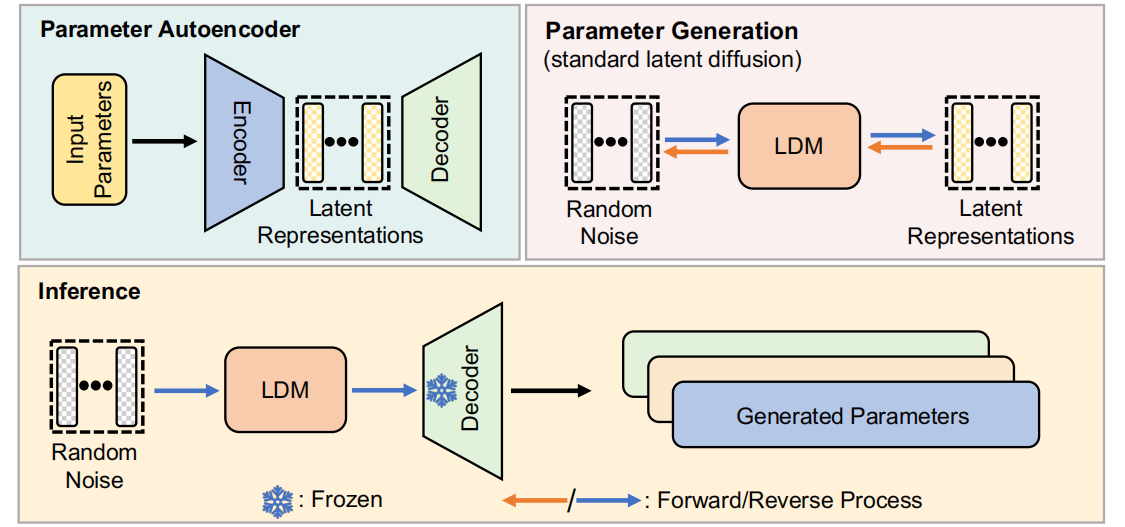
1.给定一组训练好的高性能模型,选择参数中的一个子集,并压平为一维向量。
2.引入一个编码器,从这些向量中提取潜在表示,并伴随着一个解码器,负责从潜在表示中重建参数。
3.训练一个标准的潜在扩散模型,从随机噪声中合成潜在表示。
经过训练后,利用p-diff通过以下链生成新的参数:随机噪声→反向处理→训练的解码器→生成的参数。
2.3 参数自动编码器
2.3.1数据准备
收集自动编码器的训练数据,我们从头开始训练一个模型,并在最后一个epoch密集地保存权重(只通过SGD优化器更新参数子集,并修复模型的剩余参数)。利用保存的参数子集S=[s1…,sk,…,sK]来训练自动编码器,其中K是训练样本的数量。对于一些在大规模数据集上训练的大型架构,考虑到从头训练的成本,对预训练模型的参数子集进行微调,并将微调后的参数密集保存为训练样本。
2.3.2训练
将参数S压缩成一维向量 V = [v1,…,vk,…,vK],其中 V∈RK×D ,D是子集参数的大小。然后,训练一个自动编码器来重构这些参数V。为了增强其鲁棒性和泛化性,在输入参数和潜在表示中同时引入了随机噪声增强。Encoder和Decoder过程:
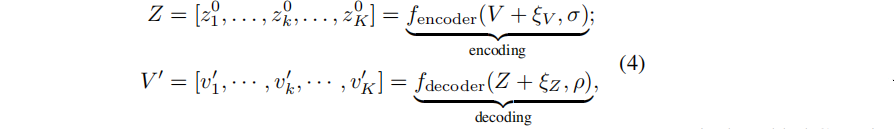
其中,fencoder(·, σ) 和 fdecoder(·, ρ) 分别表示由σ和ρ参数化的编码器和解码器。
Z为潜在表示,ξ为随机噪声,Z表示,V’ 为重构参数。默认使用一个一个4层编码器和解码器的自动编码器。将V’ 和V之间的均方误差(MSE)损失最小化如下:
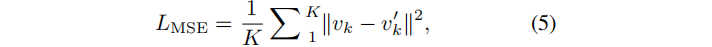
2.4 参数生成
最直接的策略是,通过扩散模型直接生成新的参数。该操作的内存成本太重,特别是当V的维数超大时。在此基础上,我们将扩散过程默认应用于潜在表示Z,具体使用DDPM来优化:
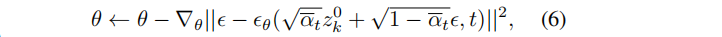
其中t在1和T之间均匀采样,超参数 α ˉ \bar{α} αˉt 表示每一步的噪声强度,ϵ是添加的高斯噪声,ϵθ表示由θ参数化的去噪网络。训练完成后,直接利用随机噪声,逆扩散和解码,生成一组新的高性能参数。这些生成的参数与剩余的模型参数连接起来,形成新的模型进行评估。神经网络参数和图像像素在几个关键方面表现出显著的差异,包括数据类型、维度、范围和物理解释。与图像不同的是,神经网络参数大多没有空间相关性,因此我们在参数自编码器和参数生成过程中,用一维卷积代替二维卷积。
三、实验
3.1 设置
3.1.1数据集和框架
评估数据集,包括MNIST,CIFAR-10/100,ImageNet-1K,STL-10,Flowers,Pets和F-101。网络主要在ResNet-18/50、ViT-Tiny/Base和ConvNeXt-T/B上进行实验。
3.1.2训练细节
自动编码器和潜在扩散模型都包括一个基于4层的一维CNN的Encoder和Decoder。默认所有框架接收200个训练数据。ResNet-18/50,从零开始训练。在最后一个阶段,我们继续训练最后两个BN层,并修复其他参数。在最后一个epoch保存了200个checkpoints。对于ViT-Tiny/Base和ConvNeXt-T/B,使用timm库中发布的模型的最后两个标准化参数进行了微调。ξV和ξZ为振幅分别为0.001和0.1的高斯噪声。自动编码器和潜扩散训练可以在单个Nvidia A100 40G GPU上在1到3小时内完成。
3.1.3推理细节
通过在潜在扩散模型和训练解码器中加入随机噪声,合成了100个新参数。然后将这些合成参数与上述固定参数连接起来,形成我们生成的模型。从这些生成的模型中,我们选择了在训练集上表现最好的模型。随后,我们在验证集上评估其准确性,并报告结果。这是考虑与使用SGD优化训练的模型进行公平比较的问题。
3.2 结果
表1显示了与8个数据集和6个架构上的两个基线的结果比较。基于这些结果,我们有以下几个观察结果: i)在大多数情况下,我们的方法获得了比两个基线相似或更好的结果。这表明,我们的方法可以有效地学习高性能参数的分布,并从随机噪声中生成优越的模型。ii)我们的方法在各种数据集上始终表现良好,这表明我们的方法具有良好的通用性。

3.3 消融实验与分析
消融实验默认在CIFAR-100上训练ResNet-18,并报告最好的、平均的和中等的准确性。
3.3.1训练模型的数量
表2.(a)改变了训练数据的大小,即原始模型的数量。我们发现,不同数量的原始模型之间的最佳结果的性能差距很小。为了全面探讨不同数量的训练数据对性能稳定性的影响,采用平均值(avg.)和中位数(med.)准确性,作为我们生成的模型的稳定性的指标。值得注意的是, 由少量训练实例生成的模型的稳定性,比在较大的设置中观察到的要差得多 。这可以用扩散模型的学习原理来解释:如果只使用少量的输入样本进行训练,扩散过程可能很难很好地模拟目标分布。
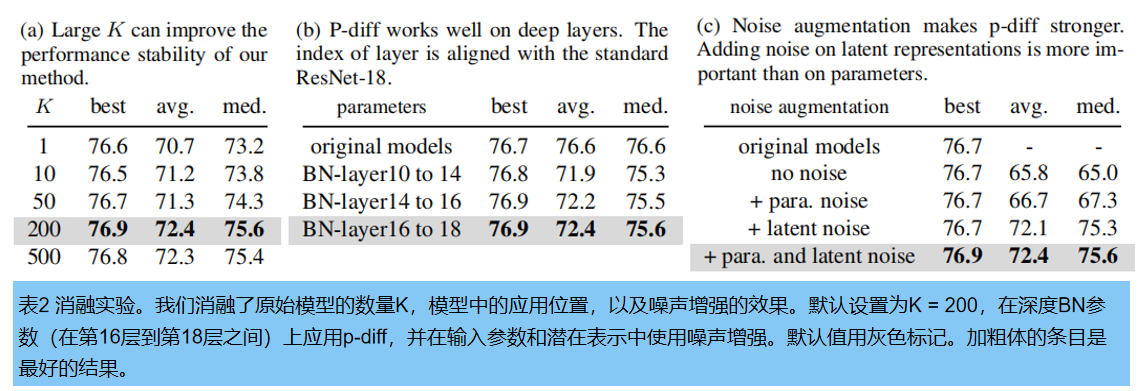
3.3.2在哪里应用 p-diff
我们默认是合成最后两个标准化层的参数。为了研究p-diff在其他归一化层深度上的有效性,我们还探讨了合成其他浅层参数的性能。为了保持相同数量的BN参数,我们对三组BN层实现了我们的方法,它们是在不同深度的层之间。如表2(b), 方法在所有BN层设置的深度上都比原始模型获得了更好的性能(最佳精度)。另一个发现是, 合成深层比生成浅层可以获得更好的精度。这是因为生成浅层参数比生成深层参数更容易在正向传播过程中积累误差。
3.3.3噪声增强
噪声增强是为了增强训练自动编码器的鲁棒性和泛化性。我们分别降低了在输入参数和潜在表示中应用这种增强的有效性。消融结果见表2(c)
i)噪声增强在生成稳定和高性能的模型中起着至关重要的作用。
ii)在潜在表示中应用噪声增强的性能增益,大于在输入参数中。
iii)我们的默认设置,在参数和表示中联合使用噪声增强,获得了最佳的性能
3.3.4对整个模型参数的泛化
以上评估了在综合模型参数的一个子集方面的有效性,即批处理归一化参数。为评估综合整个模型参数,将其扩展到两个小的架构,即MLP-3(三个线性层+ReLU激活)和ConvNet-3(三个卷积层+一个线性层)。与前面提到的训练数据收集策略不同,我们分别用200个不同的随机种子从头开始单独训练这些架构。我们以CIFAR-10为例,展示了两种框架的细节(卷积层:核大小×核大小,通道数量;线性层:输入维度,输出维度):
• ConvNet-3: conv1. 3×3, 32, conv2. 3×3, 32, conv3. 3×3,
32, linear layer. 2048, 10.
• MLP-3: linear layer1. 3072, 50, linear layer2. 50, 25,
linear layer3. 25, 10.
我们在表3展示了本方法和两个基线(即原始和集成)之间的结果比较,证明了方法在综合整个模型参数方面的有效性和泛化,即在基线上实现相似甚至改进的性能。然而,受到GPU内存的限制,无法综合大型体系结构的整个参数,如ResNet、ViT和ConvNeXt系列。

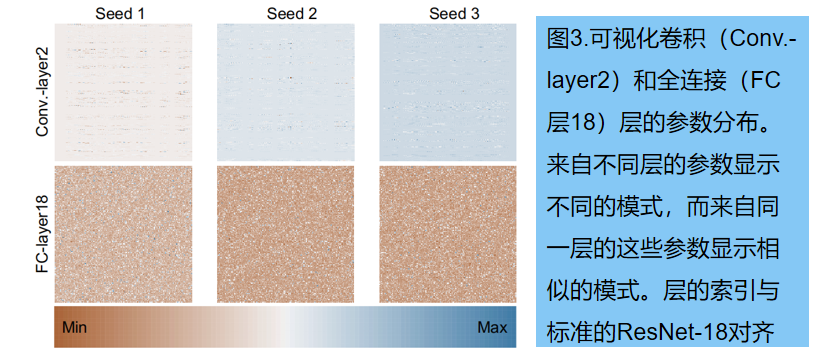
3.3.5原始模型的参数模式
实验结果和消融研究证明了我们的方法在生成神经网络参数方面的有效性。为了探究这背后的内在原因,我们使用3个随机种子从头开始训练ResNet-18模型,并可视化图3中的参数。我们通过最小-最大归一化,来可视化不同层的参数分布的热图。基于卷积层(Conv.-layer2)和全连接层(fc层18层)参数的可视化,这些层之间确实存在特定的参数模式 (specific parameter
patterns)。基于对这些模式的学习,我们的方法可以生成高性能的神经网络参数。
四、P-diff只是记忆吗?
主要研究原始模型和生成模型之间的差异。我们首先提出了一个相似度度量方法。然后进行了几次比较和可视化来说明我们的方法的特点
4.1 问题和实验设计
设计以下问题:
1)p-diff是否只是记住了从训练集中的原始模型中提取的样本?
2)在添加噪声或微调原始模型和由我们的方法生成的模型之间有什么区别?
论文中,希望p-diff能够产生一些性能不同于原始模型的新参数。为了验证这一点,我们设计了一些实验,通过比较原始模型的预测和可视化结果,来研究原始模型、噪声添加模型、微调模型、p-diff模型和p-diff模型之间的差异。
4.2 相似性指标
默认设置(使用ResNet-18对CIFAR-100进行实验)只生成最后两批归一化层的参数。我们通过计算两个模型错误预测的联合交集(IoU)来衡量两个模型之间的相似性。IoU可以表述如下:
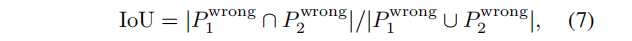
其中Pwrong 表示验证集上错误预测的指标。IoU越高,表明两种模型的预测相似性越大。为减轻实验中性能对比的影响,我们默认选择性能优于76.5%的模型。
4.3 预测的相似性
对于每个模型,我们通过与其他模型的IoU平均来获得其相似性。
我们引入了四个比较: 1)原始模型之间的相似性;2)p-diff模型之间的相似性;3)原始模型和p-diff模型之间的相似性;4)原始模型和p-diff模型之间的最大相似度(最近邻)。我们计算了上述四种比较中所有模型的iou,并在图4(a).中报告了它们的平均值我们可以发现, 生成的模型之间的差异远远大于原始模型之间的差异。另一个发现是,即使原始模型和生成模型之间的最大相似性也低于原始模型之间的相似性。它显示了我们的p-diff可以生成新的参数
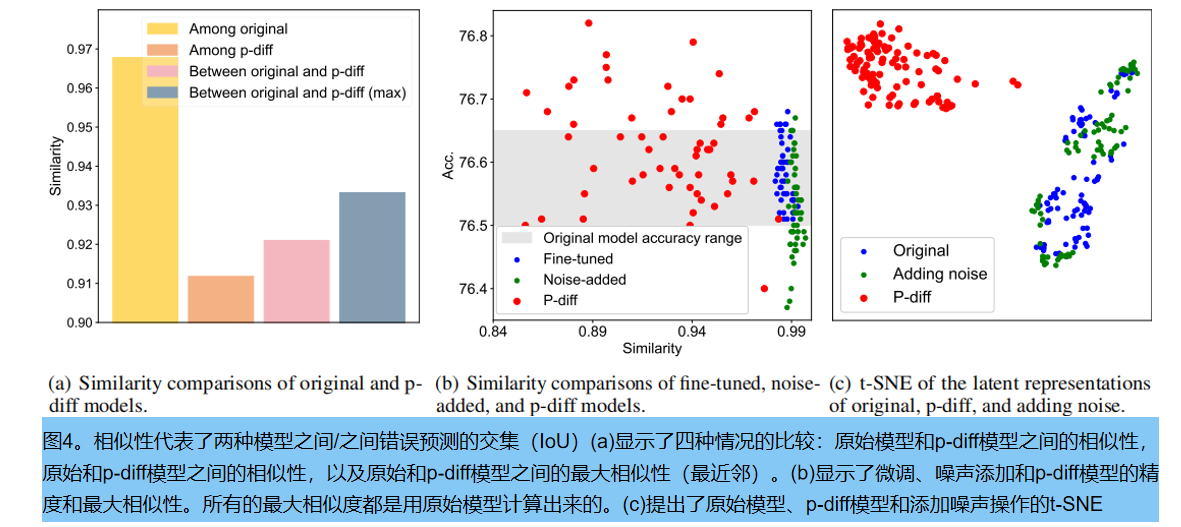
噪声消融
随机选择一个生成的模型,并从原始模型中搜索其最近邻(即最大相似度)。然后,对最近邻的随机噪声进行微调和添加,得到相应的模型。然后,我们分别用微调模型和噪声添加模型计算原始模型的相似度。最后,我们重复此操作50次,并报告其平均iou进行分析。在这个实验中,我们还限制了所有模型的性能,即在这里只使用好的模型来减少可视化的偏差。我们根据经验设置了随机噪声的振幅,其范围为0.01到0.1,以防止性能的实质性下降。
根据图4(b)中的结果,发现微调模型和噪声添加模型的性能很难优于原始模型。此外,微调模型或噪声添加模型与原始模型之间的相似性非常高,这表明这两种操作无法获得新的但高性能的模型
4.4 潜在表示的比较
除了预测,我们使用t-SNE评估原始和生成模型的潜在表征分布。为了识别我们的方法和在原始模型的潜在表示中添加噪声的操作之间的差异,如图4©。添加的噪声振幅为0.1的随机高斯噪声。我们可以发现,p-diff可以产生新的潜在表示,而添加噪声只是围绕原始模型的潜在表示进行插值。
4.5 p-diff过程的运动轨迹
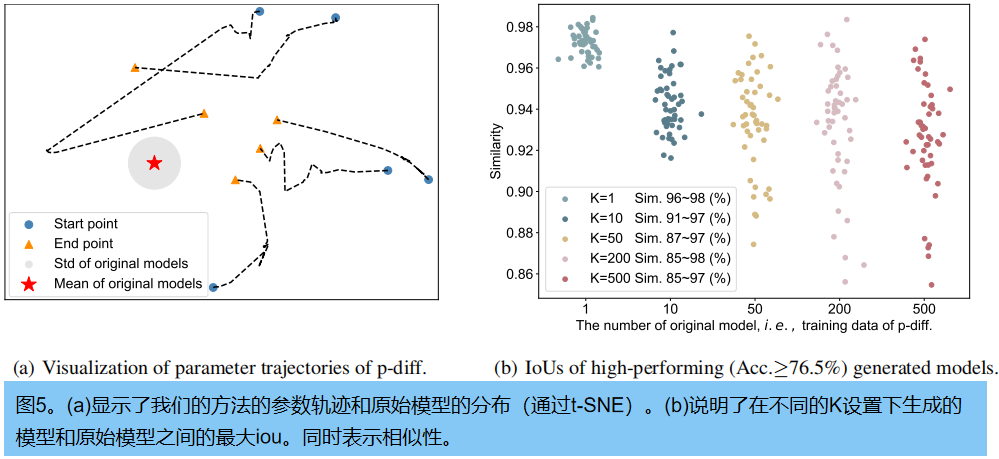
我们在推理阶段绘制不同时间步长的生成参数,形成轨迹,以探索其生成过程。5个轨迹(由5个随机噪声初始化)如图5(a).所示我们还绘制了原始模型的平均参数及其标准差(std)。随着时间步长的增加,生成的参数总体上接近于原始模型。虽然我们对可视化保持了一个较窄的性能范围约束,但轨迹的端点(橙色三角形)与平均参数(五角星)之间仍然有一定的距离。另一个发现是,这五种轨迹是不同的。
4.6 从记忆到生成新的参数
为了研究原始模型的数量(K)对生成模型的多样性的影响,我们在图5(b).中可视化了具有不同K的原始模型和生成模型之间的最大相似性具体来说,我们不断地生成参数,直到50个模型在所有情况下都优于76.5%。当K=为1时,生成的模型几乎记忆了原始模型,相似度范围较窄,值较高。随着K的增加,这些生成的模型的相似性范围变大,这表明我们的方法可以生成与原始模型不同的参数。
五、相关工作
1.引入库
2.读入数据
d \sqrt{d} d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。




![使用 yarn 的时候,遇到 Error [ERR_REQUIRE_ESM]: require() of ES Module 怎么解决?](https://img-blog.csdnimg.cn/direct/ee57608020294fd2968810185d2c706f.png#pic_center)