目录
一、简要介绍
二、研究背景
三、用于小目标检测的transformer
3.1 Object Representation
3.2 Fast Attention for High-Resolution or Multi-Scale Feature Maps
3.3 Fully Transformer-Based Detectors
3.4 Architecture and Block Modifications
3.6 Improved Feature Representation
3.7 Spatio-Temporal Information
四、结果和基准
4.1数据集
4.2视觉应用程序中的基准测试
4.2.1通用应用程序
4.2.2在航空图像中的小目标检测
4.2.3医学图像中的小目标检测
4.2.4在水下图像中的小目标检测
4.2.5 主动毫米波图像中的小目标检测
4.2.6视频中的小目标检测
五、讨论
六、结论
一、简要介绍

Transformer在计算机视觉领域迅速普及,特别是在目标识别和检测领域。在检查最先进的目标检测方法的结果时,我们注意到,在几乎每个视频或图像数据集中,transformer始终优于完善的基于cnn的检测器。虽然基于transformer的方法仍然处于小目标检测(SOD)技术的前沿,但本文旨在探索如此广泛的网络所提供的性能效益,并确定其SOD优势的潜在原因。小目标由于其低可见性,已被确定为检测框架中最具挑战性的目标类型之一。论文的目的是研究可以提高transformer在SOD中的性能的潜在策略。本调查对跨越2020年至2023年的60多个针对SOD任务开发的transformer的研究进行了分类。这些研究包括各种检测应用,包括在通用图像、航空图像、医学图像、主动毫米图像、水下图像和视频中的小目标检测。论文还编制并提供了12个适合SOD的大规模数据集,这些数据集在以前的研究中被忽视了,并使用流行的指标如平均平均精度(mAP)、每秒帧(FPS)、参数数量等来比较回顾研究的性能。
二、研究背景
小型目标检测(SOD)已被认为是最先进的(SOTA)目标检测方法的一个重大挑战。术语“小目标”指的是占据输入图像的一小部分的目标。例如,在广泛使用的MS COCO数据集中,它定义了在典型的480×640图像中,边界框为32×32像素或更小的目标(图1)。其他数据集也有自己的定义,例如,占图像10%的目标。小目标经常被错误的局部边界框遗漏或发现,有时还会有不正确的标签。SOD中定位不足的主要原因是输入图像或视频帧中提供的信息有限,再加上它们在深度网络中通过多层时随后经历的空间退化。由于小目标经常出现在行人检测、医学图像分析、人脸识别、交通标志检测、交通灯检测、船舶检测、基于合成孔径雷达(SAR)的目标检测等各种应用领域中,因此值得研究现代深度学习SOD技术的性能。在本文中,作者比较了基于transformer的检测器与基于卷积神经网络(CNNs)的检测器在其小目标检测方面的性能。在性能明显优于cnn的情况下,论文然后试图揭示transformer的强大性能背后的原因。一个直接的解释可能是,transformer建模了输入图像中成对位置之间的相互作用。这是一种有效的编码上下文的方式。而且,在人类和计算模型中,上下文都是检测和识别小目标的主要信息来源。然而,这可能不是解释transformer成功的唯一因素。具体来说,论文的目标是从几个维度来分析这一成功,包括目标表示、对高分辨率或多尺度特征图的快速关注、完全基于transformer的检测、架构和块修改、辅助技术、改进的特征表示和时空信息。此外,论文还指出了有可能提高SOD transformer性能的方法。

在之前的工作中,论文调查了许多基于深度学习的策略,以提高到2022年在光学图像和视频中的小目标检测的性能。论文发现,除了适应transformer等较新的深度学习结构之外,流行的方法还包括数据增强、超分辨率、多尺度特征学习、上下文学习、基于注意力的学习、区域建议、损失函数正则化、利用辅助任务和时空特征聚合。此外,论文观察到,transformer是在大多数数据集中定位小目标的主要方法之一。然而,考虑到之前的工作主要评估了160多篇关注于基于cnn的网络的论文,因此没有对以transformer为中心的方法进行深入的探索。认识到该领域的增长和探索速度,现在有了一个及时的窗口来深入研究针对小目标检测的当前transformer模型。 在本文中,作者的目标是全面了解影响transformer在应用于小目标检测时令人印象深刻的性能的因素,以及它们与用于通用目标检测的策略的区别。为了奠定基础,论文首先突出了著名的基于transformer的SOD目标检测器,并将它们的进展与现有的基于cnn的方法并列起来。 自2017年以来,该领域已经发表了大量的综述文章。在之前的调查中介绍了这些评论的广泛讨论和清单。最近的另一篇综述文章也主要关注基于cnn的技术。当前综述的叙述与之前的叙述不同。本文中的重点特别缩小到transformer——一个之前没有探索过的方面——将它们定位为图像和视频SOD的主导网络架构。这需要针对这种创新体系结构量身定制的独特分类法,有意识地避开基于cnn的方法。鉴于这个主题的新颖性和复杂性,论文的评论主要优先考虑2022年后提出的作品。此外,论文还阐明了在更广泛的应用范围中用于定位和检测小目标的新数据集。 本调查中的研究主要提出了针对小目标定位和分类的方法,或间接解决了SOD的挑战。推动我们进行分析的是这些论文中为小目标指定的检测结果。然而,早期的研究注意了SOD结果,但在其开发方法中表现出不佳或忽略了SOD特定参数,没有考虑纳入本综述。在本调查中,我们假设读者已经熟悉了通用的目标检测技术、它们的架构和相关的性能度量。 本文的结构如下:在第3节中,论文提出了一个基于transformer的SOD技术的分类,并对每个类别进行了全面的深入研究。第4节展示了用于SOD的不同数据集,并跨一系列应用程序对它们进行了评估。在第5节中,论文分析并将这些结果与之前来自CNN网络的结果进行了对比。本文在第6节中总结了一些结论。
三、用于小目标检测的transformer
在本节中,论文将讨论基于transformer的SOD网络。小目标检测器的分类法如图4所示。论文表明,现有的基于新型transformer的检测器可以通过以下一个或几个角度进行分析:目标表示、对高分辨率或多尺度特征图的快速注意力、完全基于transformer的检测、架构和块修改、辅助技术、改进的特征表示和时空信息。在下面的小节中,将分别详细讨论这些类别。

3.1 Object Representation
在目标检测技术中已经采用了各种目标表示技术。感兴趣的目标可以用矩形框、中心点和点集、概率目标和关键点来表示。在需要注释格式和小目标表示方面,每种目标表示技术都有自己的优缺点。在保持现有表示技术的所有优势的同时,寻找最优表示技术的追求,从RelationNet++开始。这种方法连接了各种异构的视觉表示,并通过一个称为桥接视觉表示(BVR)的模块结合了它们的优势。BVR可以有效地运行,但并不破坏主要表示所采用的整体推理过程,它利用了关键采样和共享位置嵌入的新技术。更重要的是,BVR依赖于一个注意模块,该模块将一种表示形式指定为“主表示”(或查询),而其他表示则被指定为“辅助”表示(或键)。BVR块如图5所示,它通过将中心点和角点(键)无缝集成到基于锚定(查询)的目标检测方法中,增强了锚定盒的特征表示。

3.2 Fast Attention for High-Resolution or Multi-Scale Feature Maps
以往的研究表明,保持高分辨率的特征图是保持SOD中高性能的必要步骤。与cnn相比,transformer本质上表现出明显更高的复杂度,这是因为它们的复杂度相对于令牌的数量(例如,像素数量)呈二次增加。这种复杂性来自于跨所有令牌的成对相关性计算的要求。因此,训练时间和推理时间都超过了预期,使得检测器不适用于高分辨率图像和视频中的小目标检测。在他们关于可变形的DETR的工作中,Zhu等人解决了第一次在DETR中观察到的这个问题。他们建议只关注一个参考文献周围的一小部分关键采样点,这大大降低了复杂性。采用这种策略,通过使用多尺度变形注意模块有效地保持了空间分辨率。值得注意的是,该方法消除了特征金字塔网络的必要性,从而大大提高了对小目标的检测和识别。变形注意中多头注意模块的第i个输出为:
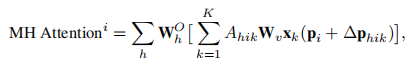
其中,i = 1,···,T和pi是查询的参考点,∆phik是K个采样(K<<T=HW)的采样偏移量(2D)。图6说明了其多头注意模块内的计算过程。可变形的DETR受益于它的编码器和解码器模块,编码器内的复杂度顺序为O(HW C2),其中H和W为输入特征图的高度和宽度,C为通道数。与DETR编码器相比,复杂度为O(H2W2C),随着H和W的增加,复杂性呈二次增长。可变形注意在其他各种检测器中发挥了突出的作用,例如在T-TRD中。随后,DETR,具有动态编码器和动态解码器,利用从低分辨率到高分辨率表示的特征金字塔,从而实现高效的粗到细的目标检测和更快的收敛。动态编码器可以看作是完全自我注意的顺序分解近似,基于尺度、空间重要性和表征动态调整注意机制。可变形DETR和动态DETR都利用可变形卷积进行特征提取。在一种独特的方法中,O2DETR 证明了自注意模块提供的全局推理实际上对航空图像并不是必需的,在航空图像中,目标通常密集地聚集在同一图像区域。因此,用局部卷积代替注意模块,并集成多尺度特征映射,被证明可以在面向目标检测的环境中提高检测性能。RCDA作者提出了行-列解耦注意(RCDA)的概念,将关键特征的二维注意分解为两种更简单的形式:一维行注意和列注意。在CF-DETR 的情况下,提出了一种FPN的替代方法,即在第5级(E5)用编码器特征替换C5特征,从而改进了目标表示。该创新被命名为transformer增强型FPN(TEF)模块。在另一项研究中,Xu等人通过将跳跃连接操作与Swintransformer集成,开发了一个加权的双向特征金字塔网络(BiFPN)。这种方法有效地保存了与小目标相关的信息。

3.3 Fully Transformer-Based Detectors
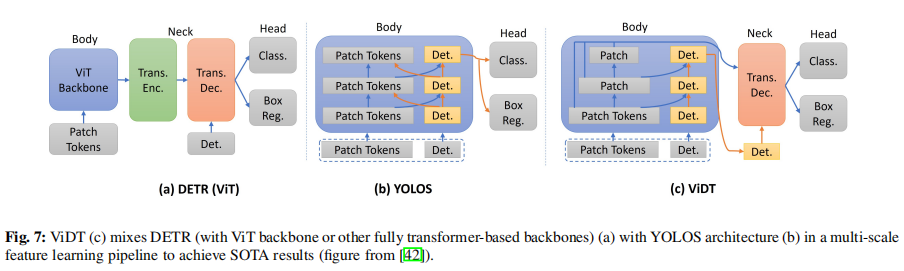
Transformer的出现及其在计算机视觉中许多复杂任务中的出色性能,逐渐促使研究人员从基于cnn或混合系统转向完全基于transformer的视觉系统。这项工作始于图像识别任务,该任务称为ViT。ViDT扩展了YOLOS模型(第一个完全基于transformer的检测器),以开发出第一个适用于SOD的高效检测器。在ViDT中,DETR中用于特征提取的ResNet被各种ViT变体所取代,如Swintransformer、ViTDet 和DeiT ,以及重新配置的注意模块(RAM)。RAM能够处理[PATCH]×[PATCH]、[DET]×[PATCH]和[PATCH]×[DET]的注意。这些交叉和自我注意模块是必要的,因为与YOLOS类似,ViDT在输入中附加了[DET]和[PATCH]标记。ViDT只利用一个transformer解码器作为其颈部,以利用在其身体步骤的每个阶段产生的多尺度特征。图7说明了ViDT的总体结构,并突出了其与DETR和YOLOS的区别。
认识到解码器模块是基于transformer的目标检测低效的主要来源,无解码器全transformer(DFFT)利用两个编码器:尺度聚合编码器(SAE)和任务对齐编码器(TAE),以保持较高的准确性。SAE将多尺度特征(四个尺度)聚合成一个单一特征图,而TAE则对单一特征图进行对齐,用于目标类型、位置分类和回归。采用面向检测的transformer(DOT)骨干技术进行了具有强语义的多尺度特征提取。 在基于稀疏roi的可变形DETR(SRDD)中,作者提出了一种带有评分系统的轻量级transformer,以最终去除编码器中的冗余令牌。这是通过在端到端学习方案中使用基于roi的检测来实现的。
3.4 Architecture and Block Modifications
DETR是第一种端到端目标检测方法,它在训练过程中延长了收敛时间,在小目标上表现较差。一些研究工作已经解决了这些问题,以提高SOD的性能。一个值得注意的贡献来自Sun等人,他从FCOS(一个完全卷积单级检测器)和faster RCNN中获得灵感,提出了两种仅编码器的DETR变体,称为TSP-FCOS和TSP-RCNN。这是通过消除解码器中的交叉注意模块来实现的。他们的研究结果表明,解码器中的交叉注意和匈牙利损失的不稳定性是DETR后期收敛的主要原因。这一发现导致他们放弃了解码器,并在这些新的变体中引入了一种新的二部匹配技术,即TSP-FCOS和TSP-RCNN。 Peng等人通过联合使用cnn和transformer的方法,提出了一种称为“构形”的混合网络结构。该结构将cnn提供的局部特征表示与不同分辨率的transformer提供的全局特征表示相结合(见图8)。这是通过特征耦合单元(FCUs)实现的,实验结果证明了其与ResNet50、ResNet101、DeiT等模型相比的有效性。

认识到局部感知和随机相关性的重要性,Xu等人在Swintransformer的Swintransformer块中添加了一个局部感知块(LPB)。这种新的主干,称为局部感知振荡变换(LPSW),显著地改进了空中图像中小目标的检测。DIAG-TR 在编码器中引入了一个全局-局部特征交织(GLFI)模块,以自适应和分层地将局部特征嵌入到全局表示中。这种技术平衡了小目标的尺度差异。此外,可学习的锚盒坐标被添加到transformer解码器中的内容查询中,提供了一个归纳偏差。在最近的一项研究中,Chen等人提出了混合网络transformer,它通过将卷积嵌入到transformer块中扩展了局部信息的范围。这一改进增强了对MS COCO数据集的检测结果。在另一项研究中,作者提出了一种名为NeXtfrorm的新主干,它结合了CNN和transformer,以增强小目标的局部细节和特征,同时也提供了一个全局的接受域。 在各种方法中,O2DETR 用深度可分离卷积代替了transformer中的注意机制。这一变化不仅降低了与多尺度特征相关的内存使用和计算成本,而且还潜在地提高了航空照片的检测精度。 Wang等人质疑之前工作中使用的目标查询,提出了锚点DETR,它使用锚点进行目标查询。这些锚点增强了目标查询位置的可解释性。对每个锚点使用多个模式,改进了对一个区域内的多个目标的检测。相比之下,Conditional DETR 强调从解码器内容中衍生出的条件空间查询,从而导致空间注意预测。随后的一个版本,条件DETR v2 ,通过将目标查询重新构造为方框查询的形式,增强了体系结构。此修改涉及嵌入一个参考点和针对参考点转换框。在随后的工作中,DABDETR通过使用动态可调的锚定盒,进一步改进了查询设计的思想。这些锚点框既作为参考查询点,又作为锚点尺寸(参见图9)。

在另一项工作 中,作者观察到,虽然DETR中小目标的平均平均精度(mAP)不能与最先进的(SOTA)技术竞争,但它在小IoU阈值下的性能惊人地优于其竞争对手。这表明,虽然DETR提供了较强的感知能力,但它需要进行微调,以获得更好的定位精度。作为一种解决方案,提出了粗到精细的检测transformer(CF-DETR),通过解码器层中的自适应尺度融合(ASF)和局部交叉注意(LCA)模块来进行这种细化。在之前的一个研究中,作者认为,基于transformer的检测器的次优性能可以归因于使用单一的交叉注意模块进行分类和回归、内容查询的初始化不足以及在自注意模块中缺乏利用先验知识等因素。为了解决这些问题,他们提出了检测分裂transformer(DESTR)。该模型将交叉注意力分为两个分支,一个用于分类,另一个用于回归。此外,DESTR使用了一个迷你检测器来确保在解码器中适当的内容查询初始化,并增强了自注意模块。另一项研究引入了FEA-Swin,它利用了Swintransformer框架中的高级前景增强关注,将上下文信息集成到原始的主干中。这是由于Swintransformer不能充分处理密集的目标检测,由于缺少相邻目标之间的连接。因此,前景增强突出了需要进一步进行相关性分析的目标。TOLO 是最近的工作之一,旨在通过一个简单的颈部模块将感应偏差(使用CNN)引入transformer架构。该模块结合了来自不同层的特性,以合并高分辨率和高语义的属性。设计了多个光transformer磁头,用于检测不同尺度下的目标。由Liang等人提出的CBNet,不是修改每个架构中的模块,而是将通过复合连接连接的多个相同的主干进行分组。 在多源聚合transformer(MATR)中,该transformer的交叉注意模块用于利用来自不同视图的同一目标的其他支持映像。一项研究中也采用了类似的方法,其中多视图视觉transformer(MVViT)框架结合了来自多个视图的信息,包括目标视图,以提高当目标在单一视图中不可见时的检测性能。 其他工作更喜欢坚持YOLO架构。例如,SPH-Yolov5 在Yolov5网络的较浅层中增加了一个新的分支,以融合特征,以改进小目标定位。它还首次在Yolov5管道中加入了Swintransformer预测头。 另一项研究中,作者认为,匈牙利损失的直接一对一的边界盒匹配方法可能并不总是有利的。他们证明了使用单组分配策略和使用NMS(非最大抑制)模块可以导致更好的检测结果。与这个观点相同,Group DETR 通过一对一的标签分配实现了K组目标查询,从而对每个地面真实目标进行K个正目标查询,以提高性能。 DKTNet提出了一种双键transformer网络,其中使用了两个键——一个是Q流,另一个是V流。这增强了Q和V之间的一致性,从而改善了学习能力。此外,通过计算通道注意而不是空间注意,并使用一维卷积来加速该过程。
实验结果表明,辅助技术或任务与主任务相结合,可以提高性能。在transformer的背景下,已经采用了几种技术,包括: (i)辅助解码/编码损失:这是指为边界框回归和目标分类而设计的前馈网络连接到单独的解码层的方法。因此,将不同尺度上的个体损失组合起来来训练模型,从而获得更好的检测结果。该技术或其变体已用于ViDT ,MDef-DETR,CBNet,SRDD 。(ii)迭代框细化:在这种方法中,每个解码层内的边界框都是根据前一层的预测进行细化的。这种反馈机制逐步提高了检测精度。该技术已用于ViDT 。(iii)自上而下的监督:这种方法利用人类可理解的语义来帮助检测小的或类不可知的目标的复杂任务,例如,MDef-DETR 中的对齐图像文本对,或TGOD 中的文本引导目标检测器。(iv)预训练:这包括在大规模数据集上进行训练,然后对检测任务进行特定的微调。该技术已被用于CBNet V2-TTA 、FPDETR、T-TRD、SPH-Yolov5、MATR ,并广泛应用于DETR v2组。(v)数据增强:该技术通过应用旋转、翻转、放大、裁剪、翻译、添加噪声等各种增强技术,丰富了检测数据集。数据增强是一种常用的解决各种不平衡问题的方法,例如,在深度学习数据集中目标大小的不平衡。数据增强可以被看作是一种间接的方法,以最小化训练集和测试集之间的差距。一些方法在检测任务中使用了增强功能,包括TTRD [43]、SPH-Yolov5 、MATR 、NLFFTNet 、DeoT、HTDet和Sw-YoloX 。(vi)一对多标签分配:DETR中的一对一匹配会导致编码器内较差的鉴别特征。因此,在其他方法中,一对多的作业,如Faster-RCNN、RetinaNet和FCOS已经被用作CO-DETR的辅助头部。(vii)去噪训练:该技术旨在提高DETR中解码器的收敛速度,由于二部匹配而经常面临不稳定的收敛问题。在去噪训练中,解码器将有噪声的地面真实标签和盒子输入解码器。然后训练该模型来重建原始的GT值(在一个辅助损失的引导下)。像DINO 和DN-DETR 这样的实现已经证明了该技术在提高解码器的稳定性方面的有效性。
3.6 Improved Feature Representation
尽管当前的目标检测器在常规大小或大型目标的广泛应用中出色,但某些用例需要专门的特性表示来改进SOD。例如,当涉及到检测航空图像中的定向目标时,任何目标旋转都可以大大改变特征表示,因为在场景中增加的背景噪声或杂波(区域建议)。为了解决这个问题,Dai等人提出了AO2-DETR,这是一种设计为对任意目标旋转具有鲁棒性的方法。这是通过三个关键组件来实现的: (i)定向候选的生成,(ii)定向候选的改进模块,它提取旋转不变特征,以及(iii)旋转感知集匹配损失。这些模块有助于抵消目标的任何旋转的影响。在一种相关的方法中,DETR++使用了多个双向特征金字塔层(BiFPN),它们以自底而上的方式应用于来自C3、C4和C5的特征图。然后,只选择一个代表所有尺度特征的尺度,输入DETR框架进行检测。对于一些特定的应用程序,如工厂安全监测,其中感兴趣的目标通常与人类工人相关,利用这些上下文信息可以极大地改善特征表示。PointDet++ 利用了这一点,结合了人体姿态估计技术,集成了局部和全局特征来提高SOD性能。影响特征质量的另一个关键因素是主干网络及其提取语义和高分辨率特征的能力。GhostNet提供了一个精简和更高效的网络,为transformer提供高质量、多尺度的功能。他们在这个网络中的Ghost模块部分生成输出特征图,其余部分使用简单的线性操作来恢复。这是缓解骨干网络复杂性的关键步骤。在医学图像分析的背景下,MStransformer使用自监督学习方法对输入图像执行随机掩模,这有助于重建更丰富的特征,较不敏感的噪声。与分层transformer相结合,这种方法优于具有各种骨干的DETR框架。小目标偏好DETR(SOFDETR),特别支持通过在输入到DETR-transformer之前合并来自第3层和第4层的卷积特征来检测小目标。NLFFTNet通过引入非局部特征融合transformer卷积网络,捕获不同特征层之间的长距离语义关系,解决了当前融合技术中只考虑局部交互的局限性。DeoT 将一个仅限编码器的transformer与一个新的特征金字塔融合模块合并。通过在通道细化模块(CRM)和空间细化模块(SRM)中使用通道和空间注意力,增强了这种融合,从而能够提取出更丰富的特征。HTDet 的作者提出了一种细粒度的FPN来累积融合低级和高级特征,以更好地进行目标检测。同时,在MDCT 中,作者提出了一个多核扩展卷积(MDC)模块,以同时利用小目标的本体和相邻空间特征来提高小目标相关特征提取的性能。该模块利用深度可分离卷积来降低计算成本。最后,RTD-Net的一个特征融合模块配对了一个轻量级的主干,通过拓宽接受域来增强小目标的视觉特征。RTD-Net中的混合注意模块,通过合并小目标周围的上下文信息,使系统能够检测部分被遮挡的目标。
3.7 Spatio-Temporal Information
在本节中,我们的重点完全是基于视频的目标检测器,旨在识别小目标。虽然许多这些研究已经在ImageNet VID数据集上进行了测试,但该数据集最初并不是用于小目标检测的。尽管如此,也有一些工作报告了他们对ImageNet VID数据集的小目标的结果。跟踪和检测视频中的小目标的主题也已经利用transformer体系结构进行了探索。虽然基于图像的SOD技术可以应用于视频,但它们通常不利用有价值的时间信息,这对于识别杂乱或遮挡帧中的小目标特别有用。transformer在一般目标检测/跟踪中的应用始于跟踪transformer和TransT。这些模型使用了帧到帧(设置前一帧作为参考)设置预测和模板到帧(设置一个模板帧作为参考)检测。Liu等人是第一批使用transformer专门用于基于视频的小目标检测和跟踪的人之一。他们的核心概念是更新模板框架,以捕捉由小目标的存在引起的任何小的变化,并在模板框架和搜索框架之间提供一个全局的注意驱动的关系。 通过引入端到端目标检测器TransVOD,基于transformer的目标检测获得了正式的识别。该模型将空间和时间transformer应用于一系列视频帧,从而识别和连接到这些帧中的目标。TransVOD已经产生了几个变体,每个变体都有独特的特性,包括实时检测功能。PTSE采用渐进策略,关注时间信息和目标帧间的空间转换。它采用了多尺度的特征提取来实现这一目标。与其他模型不同,PT-SEFrorter直接从相邻帧而不是整个数据集回归目标查询,提供了一种更本地化的方法。Sparse VOD 提出了一种端到端可训练的视频目标检测器,它结合了时间信息来提出区域建议。相比之下,DAFA 强调了视频中全局特征的重要性,而不是局部时间特征。DEFA指出了FIFO记忆结构的低效,并提出了一种采用目标级记忆代替帧级记忆的多样性感知记忆作为注意模块。VSTAM 在逐个元素的基础上提高了特征质量,然后在将这些增强的特征用于目标候选区域检测之前执行稀疏聚合。该模型还结合了外部记忆,以利用长期的上下文信息。在FAQ工作中,提出了一种在解码器模块中使用查询特征聚合的新型视频目标检测器。这与专注于编码器中的特性聚合的方法或对不同帧执行后处理的方法不同。研究表明,该技术的检测性能优于SOTA方法。
四、结果和基准
在本节中,论文将定量和定性地评估以前的小目标检测工作,确定一个特定应用的最有效的技术。在此比较之前,论文引入了一系列专门用于小目标检测的新数据集,包括用于不同应用程序的视频和图像。
4.1数据集
在本小节中,除了广泛使用的MS COCO数据集外,还汇编并呈现了12个新的SOD数据集。这些新的数据集主要是为特定的应用程序而定制的,除了通用环境和海洋环境。图10显示了这些数据集的时间顺序以及截至2023年6月15日的引文计数。

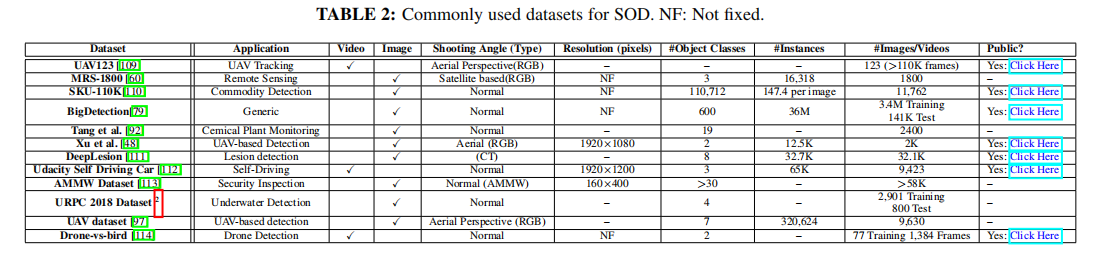
UAV123:该数据集包含123个用无人机获取的123个视频,是全球最大的帧数超过110K帧的目标跟踪数据集之一。 MRS-1800:该数据集由来自其他三个遥感数据集的图像组合组成: DIOR 、NWPU VHR-10 和HRRSD。MRD-1800是为了检测和实例分割的双重目的,有1800张手动注释的图像,其中包括3种类型的目标:飞机、船只和储罐。 SKU-110K :该数据集可作为商品检测的严格测试平台,以从世界各地的各种超市捕获的图像为特色。该数据集包括一系列的尺度、相机角度、照明条件等。 BigDetection:这是一个大规模的数据集,通过集成现有的数据集,细致地消除重复的盒子,同时标记被忽略的目标。它具有各种大小的目标数量的平衡,使它成为推进现场目标检测的关键资源。使用此数据集进行预训练和随后对MS COCO进行微调,可以显著提高性能结果。 Tang等人:该数据集源自化工厂现场活动的视频片段,涵盖了各种类型的工作,如热作业、空中作业、密闭空间作业等。它包括人、头盔、灭火器、手套、工作服等相关物品等分类标签。 Xu等人:这个公开的数据集专注于无人机捕获的图像,并包含2K张图像,旨在检测行人和车辆。这些图像是使用大疆无人机收集的,并具有不同的条件,如不同的光照水平和密集停放的车辆。 DeepLesion:包括4427名患者的CT扫描,该数据集是同类数据中最大的。它包括多种病变类型,如肺结节、骨异常、肾脏病变和肿大淋巴结。这些图像中感兴趣的目标通常很小,并伴随着噪声,这使得它们的识别具有挑战性。 Udacity Self Driving Car:仅为教育用途设计,该数据集具有在山景城和附近城市的驾驶场景,以2Hz的图像采集率捕获。该数据集中的类别标签包括汽车、卡车和行人。 AMMW数据集:它是为安全应用程序而创建的,这个活动的毫米波图像数据集包含了30多个不同类型的目标。这包括两种打火机(由塑料和金属制成),一种模拟枪支,一把刀,一把刀片,一个子弹壳、手机、汤、钥匙、磁铁、液体瓶、吸收材料、火柴等等。 URPC 2018数据集:该水下图像数据集包括四种类型的目标:全息鱼、棘鱼、扇贝和海星。 UAV数据集:该图像数据集包括无人机在不同天气、光照条件和各种复杂背景下捕获的9K多个图像。这个数据集中的目标是轿车、人、马达、自行车、卡车、公共汽车和三轮车。 Drone-vs-bird:这个视频数据集旨在解决无人机在敏感地区飞行的安全问题。它提供了带标记的视频序列,以区分在各种照明、照明、天气和背景条件下的鸟类和无人机 表2提供了这些数据集的摘要,包括它们的应用程序、类型、分辨率、类/实例/图像/帧的数量,以及到它们的网页的链接。
4.2视觉应用程序中的基准测试
在本小节中,将介绍各种基于视觉的应用程序,其中对小目标的检测性能至关重要。对于每个应用程序,我们选择一个最流行的数据集,并报告其性能指标,以及实验设置的细节。
4.2.1通用应用程序
对于通用应用程序,论文在具有挑战性的MS COCO基准测试上评估所有小型目标检测器的性能。该数据集的选择是基于它在目标检测领域的广泛接受度和性能结果的可访问性。MS COCO数据集由横跨80个类别的大约160K张图像组成。虽然建议作者使用COCO 2017训练和验证集来训练他们的算法,但它们并不局限于这些子集。

在表3中,检查和评估了所有报告其在MS COCO上的结果(从他们的论文汇编)的检测技术的性能。该表提供了关于主干架构、GFLOPS/FPS(表示计算花费和执行速度)、参数数量(表示模型的规模)、mAP(平均平均精度:目标检测性能的度量)和epoch(表示推理时间和收敛特性)的信息。此外,还提供了指向每个方法网页的链接以供进一步参考。这些方法被分为三组:基于cnn的方法,混合的方法和transformer专用的方法。每个度量的最佳性能方法显示在表的最后一行中。应该指出的是,这种比较只适用于那些报告了每个特定度量值的方法。在出现平局的情况下,平均平均精度最高的方法被认为是最好的。默认的mAP值为“COCO2017val”集,而“COCO test-dev”集的mAP值用星号标记。请注意,所报告的mAP仅适用于具有<322目标的区域。 通过检查表3,很明显,大多数技术都受益于使用CNN和transformer架构的混合,本质上是采用混合策略。值得注意的是,仅依赖于基于transformer的架构的组DETR v2,获得的mAP为48.4%的mAP。然而,实现这样的性能需要采用额外的技术,如在两个大规模数据集上进行预训练和多尺度学习。在收敛性方面,DINO仅在12个时代后就达到了稳定的结果,同时也获得了值得称赞的32.3%的mAP。相反,原始的DETR模型具有最快的推理时间和最低的GFLOPS。FP-DETR拥有最轻的网络,只有36M的参数。 根据这些发现,论文得出结论,预训练和多尺度学习是最有效的策略。这可能是由于下游任务的不平衡和小目标中缺乏信息特征。 图11以及图12中更详细的对应内容,说明了各种transformer和基于cnn的方法的检测结果。它们使用从COCO数据集中选择的图像进行相互比较,并由论文使用它们在GitHub页面上提供的公共模型来实现。分析表明,faster RCNN和SSD在准确检测小目标方面存在不足。具体来说,SSD要么错过了大多数目标,要么生成了大量带有假标签的边界框和位置不佳的边界框。虽然faster RCNN表现得更好,但它仍然会产生低可信度的边界框,并偶尔分配不正确的标签。 =



相比之下,DETR有高估目标数量的倾向,导致单个目标的多个边界框。人们通常注意到,DETR容易产生假阳性。最后,在评价的方法中,CBNet V2以其优越的性能而突出。正如观察到的,它对它检测到的目标产生高置信分数,即使它偶尔会错误识别某些目标。
4.2.2在航空图像中的小目标检测
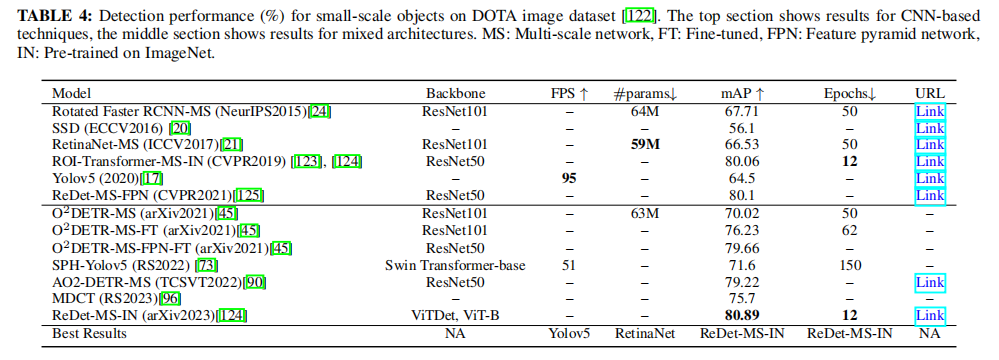
检测小目标的另一个有趣的用途是在遥感领域。这一领域特别吸引人,因为许多组织和研究机构的目标是通过航空图像定期监测地球表面,以收集国家和国际数据进行统计。虽然这些图像可以使用各种方式获得,但本调查只关注非sar图像。这是因为SAR图像已经得到了广泛的研究,值得它们自己的单独研究。尽管如此,本调查中讨论的学习技术也可以适用于SAR图像。 在航空图像中,由于目标与照相机的距离很远,它们通常看起来很小。鸟瞰图也增加了目标检测任务的复杂性,因为目标可以位于图像内的任何地方。为了评估为此类应用设计的基于transformer的检测器的性能,论文选择了DOTA图像数据集,它已成为目标检测领域广泛使用的基准。图13显示了来自DOTA数据集中的具有小目标的一些示例图像。该数据集包括一个预定义的训练集、验证集和测试集。与一般应用相比,这种特殊的应用受到的transformer专家的关注相对较少。然而,如表4所示(结果来自论文),ReDet通过其多尺度学习策略和在ImageNet数据集上的预训练进行区分,达到了最高的精度值(80.89%),只需要12个训练期。这反映了从COCO数据集分析中获得的见解,表明通过解决下游任务中的不平衡和包括来自小目标的信息特征,可以获得最佳性能。

4.2.3医学图像中的小目标检测
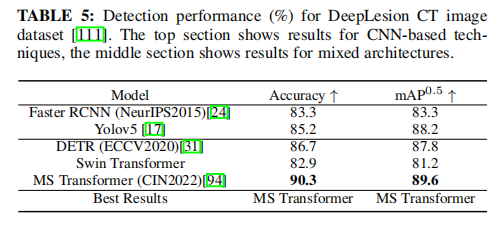
在医学成像领域,专家的任务往往是早期发现和识别异常。即使是几乎看不见或很小的异常细胞缺失,也会对患者造成严重的影响,包括癌症和危及生命的疾病。这些小目标可见于糖尿病患者视网膜异常、早期肿瘤、血管斑块等。尽管这一研究领域具有关键的性质和潜在的危及生命的影响,但只有少数研究解决了在这一关键应用中与检测小目标相关的挑战。对于那些对这个主题感兴趣的人,因为特定数据集的结果的可用性,论文选择了深度病变CT图像数据集作为基准。来自这个数据集的样本图像如图14所示。该数据集被分为三组:训练(70%)、验证(15%)和测试(15%)集。表5比较了三种基于transformer的研究与两级和一级检测器的准确性和mAP(结果汇编自他们的论文)。MStransformer成为这个数据集上最好的技术,尽管竞争有限。它的主要创新在于自我监督学习和在一个分层transformer模型中加入一个掩码机制。总的来说,该数据集的准确率为90.3%,mAP为89.6%,与其他医学成像任务相比似乎没有挑战性,特别是考虑到一些肿瘤检测任务几乎是看不见的。

4.2.4在水下图像中的小目标检测
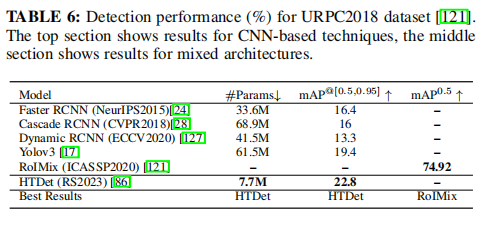
随着水下活动的增长,为了生态监测、设备维护和沉船捕鱼监测等目的,监测朦胧和低光环境的需求增加。诸如水的散射和光吸收等因素,使SOD的任务更具挑战性。图15显示了这种具有挑战性的环境的示例图像。基于transformer的检测方法不仅应该能够识别小目标,而且还需要对在深水中发现的低图像质量,以及由于每个通道的光衰减率不同而导致的颜色通道的变化具有鲁棒性。 表6显示了该数据集现有研究报告的性能指标(结果从他们的论文整理)。HTDet是为此特定应用程序而确定的唯一的基于transformer的技术。它的性能显著优于基于SOTA cnn的方法(mAP为3.4%)。然而,相对较低的mAP分数证实了在水下图像中的目标检测仍然是一项困难的任务。值得注意的是,URPC 2018的训练集包含2901张标记图像,测试集包含800张未标记图像。

4.2.5 主动毫米波图像中的小目标检测
小目标可以很容易地隐藏在普通的RGB摄像头中,例如,在机场的一个人的衣服里。因此,主动成像技术对于安全目的至关重要。在这些场景中,通常从不同的角度捕获多个图像,以提高检测哪怕是微小目标的可能性。有趣的是,就像在医学成像领域一样,transformer很少被用于这种特殊的应用。 在论文的研究中,重点关注了使用AMMW数据集的现有技术的检测性能,如表7所示(结果来自他们的论文)。作者确定,MATR是为该数据集结合transformer和cnn的唯一技术。尽管是唯一一种基于transformer的技术,但它可以显著提高相同主干(ResNet50)的SOD性能。图16直观地比较了MATR与其他基于SOTA cnn的技术。在这种成像方法中,在很大程度上结合不同角度的图像有助于识别即使是小的目标。对于训练和测试,分别使用了35426张和4019张图像。


4.2.6视频中的小目标检测
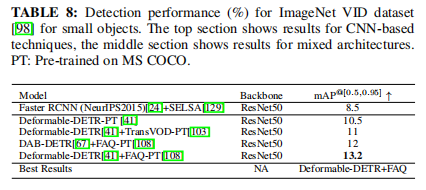
由于视频中的时间信息可以提高检测性能,视频中的目标检测领域最近得到了广泛的关注。为了对SOTA技术进行基准测试,ImageNet VID数据集已经被用于特别关注数据集中的小目标的结果。该数据集包括3862个训练视频和555个验证视频,包含30类目标。表8报告了几种最近开发的基于transformer的技术的映射。虽然transformer越来越多地用于视频目标检测,但它们在SOD中的性能仍然很少被探索。在已经在ImageNet VID数据集上报告了SOD性能的方法中,带有FAQ的可变形DETR获得了最高的性能。这突出了基于视频的SOD领域的一个重大研究差距。
五、讨论
在这篇综述文章中,探讨了基于transformer的方法如何解决SOD的挑战。论文的分类法将基于transformer的小目标检测器分为7个主要类别:目标表示、快速关注(用于高分辨率和多尺度特征图)、架构和块修改、时空信息、改进的特征表示、辅助技术和完全基于transformer的检测器。 当将此分类与基于CNN的技术的分类并置时,论文观察到其中一些类别重叠,而另一些类别是基于transformer的技术所特有的。某些策略被隐式地嵌入到transformer中,如注意学习和上下文学习,它们通过编码器和解码器中的自我注意模块和交叉注意模块来执行。另一方面,多尺度学习、辅助任务、体系结构修改和数据增强在这两种范式中都被普遍使用。然而,需要注意的是,当cnn通过3D-CNN、RNN或特征随时间聚合来处理时空分析时,transformer通过使用连续的时空transformer或更新解码器中连续帧的目标查询来实现这一点。 论文观察到,预训练和多尺度学习是最常用的策略,在不同的数据集上为不同的数据集提供了最先进的性能。数据融合是另一种广泛应用于SOD的方法。在基于视频的检测系统中,重点是如何收集时间数据并将其集成到特定于帧的检测模块中的有效方法。 虽然transformer在小目标的定位和分类方面取得了实质性的进步,但所付出的代价是很重要的。这些包括大量的参数(数十亿个左右),几天的训练(几百个迭代的epoch)和在非常大的数据集上进行预训练(如果没有强大的计算资源,这是不可行的)。所有这些方面都限制了能够为其下游任务训练和测试这些技术的用户池。现在,认识到对具有高效学习范式和架构的轻量级网络的需求比以往任何时候都更加重要。尽管现在参数的数量与人类大脑相当,但在小目标检测方面的性能仍然远远落后于人类的能力,这凸显了当前研究中的一个重大差距。 此外,基于图11和图12中的发现,论文确定了小目标检测中的两个主要挑战:缺失目标或假阴性,以及冗余的检测框。丢失目标的问题很可能是由于令牌中嵌入的信息有限所致。这可以通过使用高分辨率图像或增强特征金字塔来解决,尽管这带有增加延迟的缺点——这可能通过使用更高效、轻量级的网络来抵消。重复检测的问题传统上是通过后处理技术,如非最大抑制(NMS)来管理的。然而,在transformer的上下文中,这个问题应该通过最小化解码器中的目标查询相似性来解决,可能是通过使用辅助损失函数。 论文还研究了使用基于transformer的方法,专门在一系列基于视觉的任务中进行小目标检测(SOD)的研究。这些检测包括通用检测、航空图像检测、医学图像中的异常检测、用于安全目的的主动毫米波图像中的小隐藏目标检测、水下目标检测和视频中的小目标检测。除了通用和航空图像应用,transformer在其他应用中还不发达,与之前工作关于海上检测的观察一致。考虑到transformer在医学成像等生命领域可能产生的重大影响,这尤其令人惊讶。
六、结论
本综述论文回顾了60多篇研究论文,专注于开发小目标检测任务的transformer,包括纯基于transformer和集成cnn的混合技术。这些技术已经从七个不同的角度进行了研究:目标表示、用于高分辨率或多尺度特征图的快速注意机制、架构和块的修改、时空信息、改进的特征表示、辅助技术和完全基于transformer的检测。这些类别都包括几种最先进的(SOTA)技术,每一种都有自己的优点。论文还将这些基于transformer的方法与基于cnn的框架进行了比较,讨论了两者之间的异同。此外,对于一系列的视觉应用程序,论文引入了成熟的数据集,作为未来研究的基准。此外,本文还详细讨论了在SOD应用中使用的12个数据集,为未来的研究工作提供了便利。在未来的研究中,可以探索和解决与每个应用程序中的小目标检测相关的独特挑战。像医学成像和水下图像分析等领域将从使用transformer模型中获得显著的收益。此外,除了使用更大的模型来提高transformer的复杂性外,还可以探索替代策略来提高性能。