微信公众号“DotNet开发跳槽”、“dotNET跨平台”、“DotNet”发布了几篇将网页生成图片或pdf文件的文章(参考文献2-5),其中介绍了使用puppeteer-sharp、Select.HtmlToPdf、iTextSharp等多种方式实现html转图片或pdf,正好最近有类似的需要(网上的文档没有找到离线版,手动一页页保存成pdf又太费劲),看完上述文章后,个人感觉PuppeteerSharp使用最简单、没什么限制,同时PuppeteerSharp官网的示例和文档也较全,本文学习PuppeteerSharp生成PDF文件的基本用法。
VS2022新建Winform程序,在Nuget包管理器中搜索并安装PuppeteerSharp包:
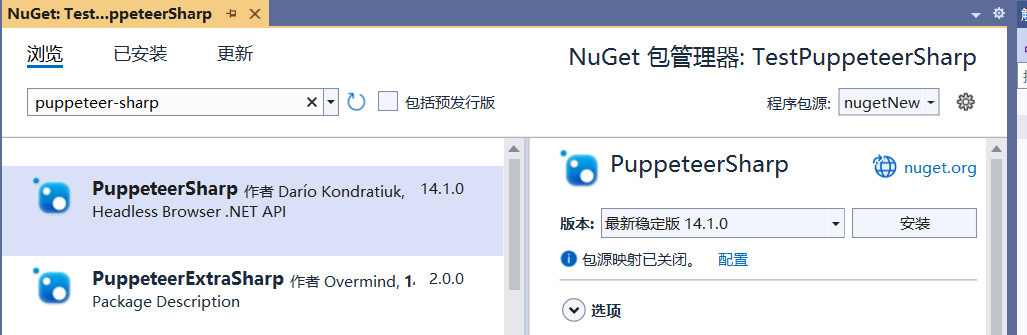
采用参考文献8中的示例代码进行测试,主要代码及说明如下所示,可以看出最简单的情况下不到10行代码即可导出pdf文件。
// 设置并下载浏览器相关组件,第一次下载可能耗时较长,后续再运行则速度很快
var options = new LaunchOptions { Headless = true };
using var browserFetcher = new BrowserFetcher();
await browserFetcher.DownloadAsync();//加载指定网址的页面
await using var browser = await Puppeteer.LaunchAsync(options);
await using var page = await browser.NewPageAsync();
await page.GoToAsync(txtUrl.Text);//将网页输出位指定名称的pdf文件
await page.PdfAsync(Path.Combine(Directory.GetCurrentDirectory(), $"{txtName.Text}.pdf"));
如果想直接采用网页中的内容设置输出文件名,PuppeteerSharp提供了QuerySelector、GetProperty等函数查找并获取页面元素内容,下列示例查找并获取页面标题元素的内容:
var titleHtml = await page.QuerySelectorAsync("title");
var innerTextHandle = await titleHtml.GetPropertyAsync("innerText");
var innerText = await innerTextHandle.JsonValueAsync();
调用PdfAsync输出pdf文件时,支持创建PdfOptions示例设置输出选项,主要属性如下图所示,如Format设置页面尺寸、Landscape设置纸张方向、PageRanges设置输出的页码范围、MarginOptions设置页边距等。

单个网页生成pdf文件的路线算是通了,后续会再学习基于C#爬取网页链接的文章及代码,目标是能做到自动把网页中链接的页面都能自动生成PDF文件。
参考文献:
[1]https://github.com/hardkoded/puppeteer-sharp
[2]https://www.cnblogs.com/wuyongfu/p/17243490.html
[3]https://blog.csdn.net/sD7O95O/article/details/111771428
[4]https://www.cnblogs.com/hohoa/p/11087198.html
[5]https://blog.csdn.net/sD7O95O/article/details/115300554
[6]https://www.puppeteersharp.com/
[7]https://www.puppeteersharp.com/api/index.html
[8]https://github.com/hardkoded/puppeteer-sharp/blob/master/demos/PuppeteerSharpPdfDemo/Program.cs