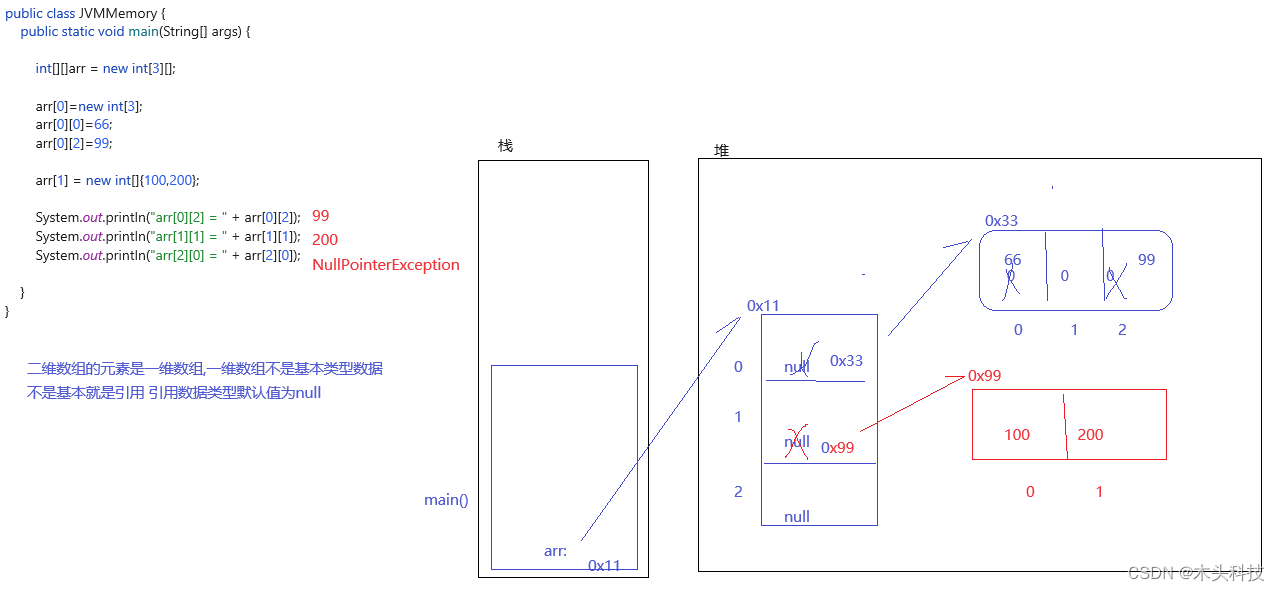
鸢尾花数据集
'''
from sklearn.datasets import load_iris
from sklearn.datasets import load_iris
from sklearn.datasets import fetch_20newsgroups
#iris = load_iris()
#加载花的类别3(山鸢尾,虹膜鸢尾,变色鸢尾),特征4(花瓣长宽,花萼长宽),样本数量150,每个类别数50
#print(iris)#sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)subset可选train,test,all
#news = fetch_20newsgroups()# 获取鸢尾花数据集
iris = load_iris()
print("鸢尾花数据集的返回值:\n", iris)
# 返回值类型是bunch--是一个字典类型
print("鸢尾花数据集特征值是:",iris["data"])
# 既可以使用[]输出也可以使用.输出
# print("数据集特征值是:",iris.data)
print("鸢尾花数据集目标值是:",iris.target)#由0,1,2组成的数组
print("鸢尾花数据集特征值名字是:",iris.feature_names)
print("鸢尾花数据集目标值名字是:",iris.target_names)
print("鸢尾花数据集的描述是:",iris.DESCR)'''import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris# 设置显示中文字体
plt.rcParams["font.sans-serif"] = ["SimHei"]
# 获取数据集
iris = load_iris()# 图像可视化
# 把数据转换成dataframe的格式
iris_d = pd.DataFrame(iris['data'], columns = ['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
# # 输出二维数组表格
# print(iris_d)
# 种类
iris_d['Species'] = iris.targetdef plot_iris(iris, col1, col2):# hue表示目标值,fit_reg = False表示不线性拟合,即不要线段sns.lmplot(x = col1, y = col2, data = iris, hue = "Species", fit_reg = False)# x,y轴标签plt.xlabel(col1)plt.ylabel(col2)# 表格标题plt.title('鸢尾花种类分布图')plt.show()
plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')鸢尾花种类分布图

测试
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#x 数据集的特征值; y 数据集的标签值
# 1.获取鸢尾花数据集
iris = load_iris()
# 2.对鸢尾花数据集进行分割
# 训练集的特征值x_train 测试集的特征值x_test 训练集的目标值y_train 测试集的目标值y_test。test_size=0.2,训练集是0.2,则测试集是0.8
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
# print("训练集特征值:\n",x_train)
# print("训练集目标值:\n",y_train)
# print("测试集特征值:\n",x_test)
# print("测试集目标值:\n",y_test)
# 可以通过.shape看形状,测试集30,训练集120
print("x_train:\n", x_train.shape) #x_train:(120, 4)打印训练使0.8×150=120个样本
print("x_test:\n", x_test.shape) #x_test:(30, 4)打印结果测试使0.2×150=30个样本
# 2.2随机数种子不同的情况下结果不同
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, test_size=0.2, random_state=6)
print("如果随机数种子不一致:\n", x_train == x_train1)
print("-----------------------------------------")
print("-----------------------------------------")
print("-----------------------------------------")
print("-----------------------------------------")
print("如果随机数种子一致:\n", x_train1 == x_train2)#第二次的true明显更多。
# 输出结果:
# 如果随机数种子不一致:
# [[ True False False False]
# [False False False False]
# [False False False False]
# [False False False False]...
# 如果随机数种子一致:
# [[ True True True True]
# [ True True True True]
# [ True True True True]
# [ True True True True]...未完