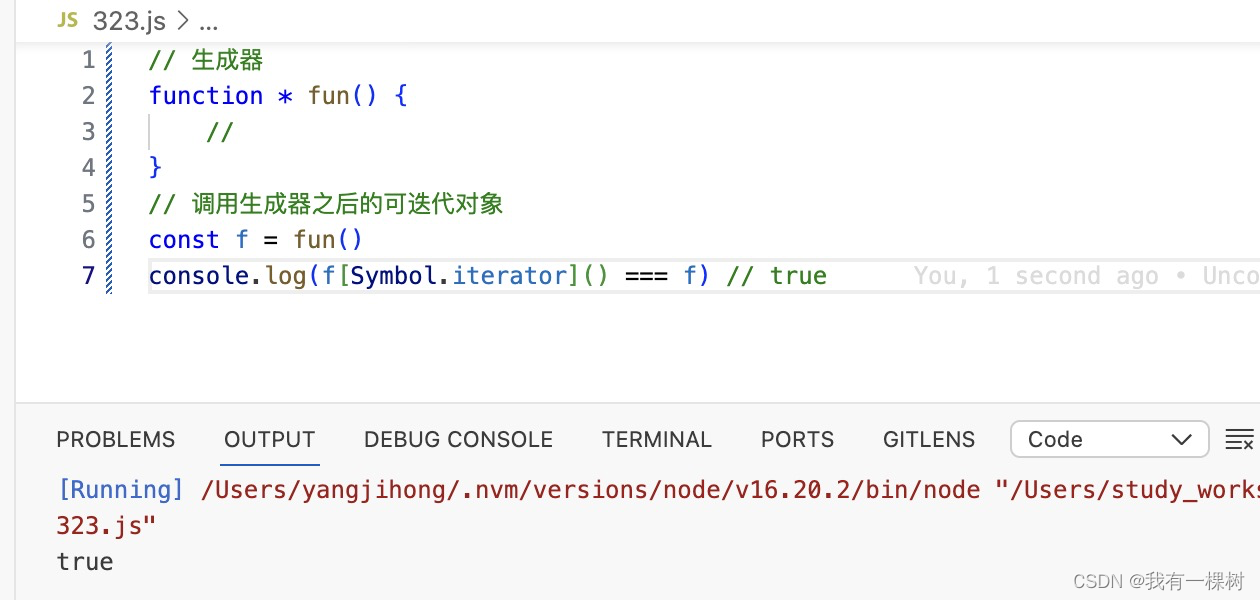
05-JVM虚拟机
4.JVM调优实践
4.1 JVM调优疑问三连
4.1.1 为什么JVM调优?
调优的最终目的都是为了应用程序使用最小的硬件消耗来承载更大的吞吐量。JVM调优主要是针对垃圾收集器的收集性能进行优化令运行在虚拟机上的应用,能够使用更少的内存(Footprint),及更低的延迟(Latency),获取更大的吞吐量(Throughput)。
下面展示了一些JVM调优的量化目标参考实例
调优目标:
-
堆内存使用率 <= 70%;
-
老年代内存使用率<= 70%; avg pause <= 1秒;
-
Full GC 次数0 或 avg pause interval = 24小时 ;
注意:不同应用场景的JVM调优量化目标是不一样的,这里的目标只一个参照模板。
4.1.2 什么时候JVM调优?
遇到以下情况,就需要考虑进行JVM调优:
-
系统吞吐量下降与响应延迟(P99);
-
Heap内存(老年代)持续上涨至出现OOM;
-
Full GC 次数频繁;
-
GC 停顿过长(超过1秒);
-
应用出现OutOfMemory 等内存异常;
-
应用中有使用本地缓存且占用大量内存空间;
4.1.3 调优调什么?
内存分配 + 垃圾回收!
- 合理使用堆内存
- GC高效回收占用的内存的垃圾对象
- GC高效释放掉内存空间
4.1.4 调优原则
- 优先原则:优先架构调优和代码调优,JVM优化是不得已的手段
- 大多数的Java应用不需要进行JVM优化
- 观测性原则:发现问题解决问题,没有问题不找问题
4.1.5 JVM实践调优主要步骤
第一步:监控分析GC日志
第二步:判断JVM问题:
- 如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化
- 如果GC时间超过1秒,或者频繁GC,则必须优化。
第三步:确定调优目标
第四步:调整参数
- 调优一般是从满足程序的内存使用需求开始,之后是时间延迟需求,最后才是吞吐量要求,要基于这个步骤来不断优化,每一个步骤都是进行下一步的基础,不可逆行之。
第五步:对比调优前后差距
第六步:重复:1、2、3、4、5步骤
- 找到最佳JVM参数设置
第七步:应用JVM参数到应用服务器:
- 找到最合适的参数,将这些参数灰度发布一部分机器,观察一段时间。
- 如果,观察结果可以验证方案的价值,则进行全量发布!
4.2 GC日志详解
4.2.1 参数配置
JVM调优典型参数设置:
-
-Xms堆内存最小值
-
-Xmx堆内存最大值
-
-Xmn新生代内存的最大值
-
-Xss每个线程的栈内存
# 计算最大线程数的公式:理论上限
Number of threads = (MaxProcess内存 - JVM内存 - ReservedOsMemory) / (ThreadStackSize)
系统最大可创建的线程数量=(机器本身可用内存 - (JVM分配的堆内存+JVM元数据区)) / Xss的值
建议:在开发测试环境可以用Xms和Xmx设置最小值最大值,但是在线上生产环境,Xms和Xmx设置的值相同防止抖动;
JVM调优设置合适大小堆内存空间,既不能太大,也不能太小。那么应该设置为多少呢?
JAVA_OPT="-Xms4096m -Xmx4096m -Xmn1024m"
JAVA_OPT="-Xms512m -Xmx512m -Xmn256m"
默认的配置是否存在性能瓶颈!
如果想要确定JVM性能问题瓶颈,需要分析GC日志
-
-XX:+PrintGCDetails 开启GC日志创建更详细的GC日志,默认关闭
-
-XX:+PrintGCTimeStamps,-XX:+PrintGCDateStamps
- 开启GC时间提示,开启时间便于我们更精确地判断几次GC操作之间的两个时间参数的区别
- 时间戳是相对于0(依据JVM启动的时间)的值,而日期戳(date stamp)是实际的日期字符串
- 由于日期戳需要进行格式化,所以它的效率可能会受轻微的影响,不过这种操作并不频繁,它造成的影响也很难被我们感知。
-
-XX:+PrintHeapAtGC 打印堆的GC日志
-
-Xloggc:./logs/gc.log 指定GC日志路径
# 配置GC日志输出
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-default.log "
4.2.2 GC日志解读
Young GC 日志含义
2021-05-18T14:31:11.340+0800: 2.340: [GC (Allocation Failure) [PSYoungGen: 896512K->41519K(1045504K)]
896512K-41543K(3435008K), 0.0931965 secs] [Times: user=0.14 sys=0.02, real=0.10 secs]
这段日志描述了一次GC(垃圾收集)事件的详细信息。让我们逐行解读每一部分的含义:1. 第一部分:- 时间戳和时区:2021-05-18T14:31:11.340+0800,表示事件发生的时间为2021年5月18日下午2点31分11.34秒,时区为东八区(中国标准时间)。- 相对时间:2.340,表示该事件相对于JVM启动的时间间隔为2.34秒。- GC类型:该行以"[GC"开始,表示这是一次Young Generation的GC。2. 第二部分:- 垃圾收集器名称:PSYoungGen,表示使用的是Parallel Scavenge(并行年轻代)垃圾收集器。- 新生代内存情况:896512K->41519K(1045504K),表示在垃圾收集之前和之后,新生代的内存使用情况。在GC前,新生代使用了896512K内存,GC后剩余41519K内存(其中总共可用1045504K内存)。- 堆内存情况:896512K-41543K(3435008K),表示在垃圾收集之前和之后,整个堆内存的使用情况。在GC前,堆内存使用了896512K,GC后剩余41543K(其中总共可用3435008K内存)。- GC持续时间:0.0931965秒,表示这次GC的持续时间为0.0931965秒。3. 第三部分:- 时间统计信息:[Times: user=0.14 sys=0.02, real=0.10 secs],表示与GC相关的时间统计信息。- user=0.14,表示GC线程消耗的CPU时间为0.14秒。- sys=0.02,表示GC过程中操作系统调用和系统等待事件所消耗的时间为0.02秒。- real=0.10,表示应用程序暂停的时间为0.10秒。该日志提供了关于GC事件发生的时间、GC类型、内存使用情况以及与GC相关的时间统计信息。这些信息对于分析和调优应用程序的内存管理性能非常有用。
FullGC 日志含义
2021-05-19T14:46:07.367+0800: 1.562: [Full GC (Metadata GC Threshold)[PSYoungGen: 18640K-
>0K(1835008K)] [ParOldGen: 16K->18327K(1538048K)] 18656K->18327K(3373056K), [Metaspace: 20401K-
>20398K(1069056K)], 0.0624559 secs] [Times: user=0.19 sys=0.00, real=0.06 secs]
这段日志描述了一次Full GC(全局垃圾收集)事件的详细信息。让我们逐行解读每一部分的含义:1. 第一部分:- 时间戳和时区:2021-05-19T14:46:07.367+0800,表示事件发生的时间为2021年5月19日下午2点46分7.367秒,时区为东八区(中国标准时间)。- 相对时间:1.562,表示该事件相对于JVM启动的时间间隔为1.562秒。- GC类型:该行以"Full GC"开始,表示这是一次Full GC。2. 第二部分:- 垃圾收集器名称:PSYoungGen,表示使用的是Parallel Scavenge(并行年轻代)垃圾收集器。- 新生代内存情况:18640K->0K(1835008K),表示在垃圾收集之前和之后,新生代的内存使用情况。在GC前,新生代使用了18640K内存,GC后剩余0K内存(其中总共可用1835008K内存)。- 老年代垃圾收集器名称:ParOldGen,表示使用的是并行老年代垃圾收集器。- 老年代内存情况:16K->18327K(1538048K),表示在垃圾收集之前和之后,老年代的内存使用情况。在GC前,老年代使用了16K内存,GC后剩余18327K内存(其中总共可用1538048K内存)。- 堆内存情况:18656K->18327K(3373056K),表示在垃圾收集之前和之后,整个堆内存的使用情况。在GC前,堆内存使用了18656K,GC后剩余18327K(其中总共可用3373056K内存)。3. 第三部分:- 元空间垃圾收集器:Metaspace,表示对元空间进行了垃圾收集。- 元空间内存情况:20401K->20398K(1069056K),表示在垃圾收集之前和之后,元空间的内存使用情况。在GC前,元空间使用了20401K内存,GC后剩余20398K内存(其中总共可用1069056K内存)。- GC持续时间:0.0624559秒,表示这次GC的持续时间为0.0624559秒。- 时间统计信息:[Times: user=0.19 sys=0.00, real=0.06 secs],表示与GC相关的时间统计信息。- user=0.19,表示GC线程消耗的CPU时间为0.19秒。- sys=0.00,表示GC过程中操作系统调用和系统等待事件所消耗的时间为0.00秒。- real=0.06,表示应用程序暂停的时间为0.06秒。该日志提供了关于Full GC事件发生的时间、GC类型、内存使用情况以及与GC相关的时间统计信息。这些信息对于分析和调优应用程序的内存管理性能非常有用。
日志这么看是不是很累?接下来,我们学一个GC日志可视化工具
4.2.3 GC日志可视化分析
分析GC日志,就必须让GC日志输出到一个文件中,然后使用GC日志分析工具(https://gceasy.io/)进行分析。默认配置
1) JVM内存占用情况:
| Generation【区域】 | Allocated【最大值】 | Peak【占用峰值】 |
|---|---|---|
| Young Generation【新生代】 | 624 mb | 624 mb |
| Old Generation【老新生代】 | 350 mb | 274.3 mb |
| Meta Space【元空间】 | 05 gb | 59.95 mb |
| Young + Old +Metaspace【整体】 | 2.9 gb | 937.13 mb |
2)关键性能指标:

1、吞吐量:百分比越高表明GC开销越低。这个指标反映了JVM的吞吐量。
Percentage of time spent in processing real transactions vs time spent in GC activity. Higher percentage is a good indication that GC overhead is low. One should aim for high throughput.
2、GC 延迟:
-
Avg Pause GC Time:10.6ms 平均GC暂停时间
-
Max Pause GC Time:190ms最大GC暂停时间
3) GC 可视化交互聚合结果
存在问题:一开始就发生了3次Full GC很明显不正常;

4)GC统计

5)GC原因:

| 原因 | 次数 | 平均时间 | 最大时间 | 总耗时 |
|---|---|---|---|---|
| Allocation Failure | 77 | 21.4 ms | 70.0 ms | 1 sec 650ms |
| Ergonomics | 2 | 270 ms | 310 ms | 540 ms |
| Metadata GC Threshold | 6 | 48.3 ms | 110 ms | 290 ms |
-
Allocation Failure :新生代空间不足
-
Metadata GC Threshold: 元空间超阈值
-
Ergonomics:译文是"人体工程学",有自适应的意思,GC中的Ergonomics含义是负责自动调解GC暂停时间和吞吐量之间平衡从而产生的GC。目的:使得虚拟机性能更好的一种机制。
-
TPS&RT&内存占用:


4.3 堆内存与元空间优化
- 堆内存给多少合适?
- 年轻代给多少合适?
- 老年代给多少合适?
- 元空间给多少合适?依据观察的结果,元空间给128,尽量是8的整数倍
- 堆栈给多少合适?
4.3.1 监控分析
JVM内存占用情况:
- Meta Space空间分配不合理

Young和Full GC趋势:
4.3.2 判断
GC主要原因 {width=“6.515439632545932in”
{width=“6.515439632545932in”
height=“2.2316666666666665in”}
4.3.3 确定目标
则其他堆空间的分配,基于以下规则来进行。
老年代的空间大小为 274MB【那些不容易消亡的老对象】
-
java heap:参数-Xms和-Xmx,建议扩大至3-4倍FullGC后的老年代空间占用。274 *(3-4) = (822-1096)MB ,设置heap大小为 1096MB,最好是8的整数倍;
-
元空间:参数-XX:MetaspaceSize=N,设置元空间大小为128MB;
-
新生代:参数-Xmn,建议扩大至1-1.5倍FullGC之后的老年代空间占用。274M*(1-1.5)=(274 -411)M,设置新生代大小为 411MB,最好是8的整数倍,因此改为408M;
# 调整参数,基于当前系统运行情况这是最佳配置
JAVA_OPT="${JAVA_OPT} -Xms1096m -Xmx1096m -Xmn408m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m"
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-best-heap-metaspace.log"
4.3.4 对比差异
对比内存占用
 {width=“6.540995188101487in”
{width=“6.540995188101487in”
height=“2.4721872265966756in”}
 {width=“6.522553587051618in”
{width=“6.522553587051618in”
height=“2.3625in”}
对比TPS和RT

4.4 线程堆栈优化
对于不同版本的Java虚拟机和不同的操作系统,栈容量最小值可能会有所限制,这主要取决于操作系统内存分页大小。譬如上述方法中的参数-Xss128k可以正常用于32位Windows系统下的JDK 6,但是如果用于64位Windows系统下的JDK 11,则会提示栈容量最小不能低于180K,而在Linux下这个值则可能是228K,如果低于这个最小限制,HotSpot虚拟器启动时会给出如下提示:
The Java thread stack size specified is too small. Specify at least 228k
那么问题来了,Xss应该设置多少呢?
JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256。根据应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成, 如果栈不是很深, 应该是256k够用了,大的应用建议使用512k。
注意:这个选项对性能影响较大,需严格测试确定最终大小。
# 计算最大线程数的公式:
Number of threads = (MaxProcess内存 - JVM内存 - ReservedOsMemory) / (ThreadStackSize)
系统最大可创建的线程数量 = (机器本身可用内存 - (JVM分配的堆内存+JVM元数据区)) / Xss的值
优化后的参数配置:
JAVA_OPT="${JAVA_OPT} -Xms1096m -Xmx1096m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -
XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-best-stack.log"
前提:高延迟场景!
Xss512k内存占用:
 {width=“6.389686132983377in”
{width=“6.389686132983377in”
height=“1.5764577865266842in”}
Xss2m内存占用:
 {width=“6.370265748031496in”
{width=“6.370265748031496in”
height=“1.5716666666666668in”}
4.5 垃圾回收器优化:吞吐量优先ps+po
压力提升至1000-3000
默认使用ps+po 垃圾回收器组合: 并行垃圾回收器组合
JAVA_OPT="${JAVA_OPT} -Xms256m -Xmx256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"JAVA_OPT="${JAVA_OPT} -XX:+UseParallelGC -XX:+UseParallelOldGC "JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-ps-po.log"
 {width=“6.415895669291339in”
{width=“6.415895669291339in”
height=“1237489063867017in”}
 {width=“6.363924978127734in”
{width=“6.363924978127734in”
height=“1.4281244531933508in”}
4.6 垃圾回收器优化:响应时间优先parnew+cms
压力提升至1000-3000
使用cms垃圾回收器,垃圾回收器组合: parNew+CMS, cms垃圾回收器在垃圾标记,垃圾清除的时候,和业务线程交叉执行,尽量减少stw时间,因此这垃圾回收器叫做响应时间优先;
JAVA_OPT="${JAVA_OPT} -Xms256m -Xmx256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"JAVA_OPT="${JAVA_OPT} -XX:+UseParNewGC -XX:+UseConcMarkSweepGC "JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-parnew-cms.log"
 {width=“6.368468941382327in”
{width=“6.368468941382327in”
height=“0170833333333333in”}
 {width=“6.4474923447069115in”
{width=“6.4474923447069115in”
height=“4.6706244531933505in”}
 {width=“6.32165135608049in”
{width=“6.32165135608049in”
height=“1.39375in”}
4.7 垃圾回收器优化:G1全功能但不全能
配置G1只需要简单三步即可:
-
第一步,开启G1垃圾收集器
-
第二步,设置堆的最大内存
-
第三步,设置最大的停顿时间
JAVA_OPT="${JAVA_OPT} -Xms256m -Xmx256m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Xss512k"
JAVA_OPT="${JAVA_OPT} -XX:+UseG1GC -XX:MaxGCPauseMillis=100"JAVA_OPT="${JAVA_OPT} -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:${BASE_DIR}/logs/gc-g-one.log"
对于G1垃圾收集器参数设置建议:
- 设置为100-300之间比较合理,不要设置的太短
- 堆内存小于2GB,不建议使用G1
 {width=“6.415402449693788in”
{width=“6.415402449693788in”
height=“2.247916666666667in”}
 {width=“6.46816491688539in”
{width=“6.46816491688539in”
height=“1.8759372265966754in”}

 {width=“6.464599737532809in”
{width=“6.464599737532809in”
height=“1.43375in”}
5. JVM调优实战场景
实战01-内存溢出的定位与分析
内存溢出在实际的生产环境中经常会遇到,比如,不断的将数据写入到一个集合中,出现了死循环,读取超大的文件等等,都可能会造成内存溢出。
如果出现了内存溢出,首先我们需要定位到发生内存溢出的环节,并且进行分析,是正常还是非正常情况,如果是正常的需求,就应该考虑加大内存的设置,如果是非正常需求,那么就要对代码进行修改,修复这个bug。
首先,我们得先学会如何定位问题,然后再进行分析。如何定位问题呢,我们需要借助于jmap与MAT工具进行定位分析。接下来,我们模拟内存溢出的场景。
1.1 模拟内存溢出
编写代码,向List集合中添加100万个字符串,每个字符串由1000个UUID组成。如果程序能够正常执行,最后打印ok。
package com.hero.jvm.memory;import java.util.ArrayList;
import java.util.List;
import java.util.UUID;public class TestJvmOutOfMemory {public static void main(String[] args) {List<Object> list = new ArrayList<>();for (int i = 0; i < 10000000; i++) {StringBuilder str = new StringBuilder();for (int j = 0; j < 1000; j++) {str.append(UUID.randomUUID().toString());}list.add(str.toString());}System.out.println("ok");}
}
为了演示效果,我们将设置执行的参数,这里使用的是Idea编辑器。
 {width=“6.3841119860017495in”
{width=“6.3841119860017495in”
height=“2.0275in”}
#参数如下:
-Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
1.2 运行测试
测试结果如下:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to java_pid31092.hprof ...
Heap dump file created [8453096 bytes in 0.031 secs]
Exception in thread "main" java.lang.OutOfMemoryError: Java heap spaceat java.util.Arrays.copyOf(Arrays.java:3332)at java.lang.AbstractStringBuilder.ensureCapacityInternal(AbstractStringBuilder.java:124)at java.lang.AbstractStringBuilder.append(AbstractStringBuilder.java:448)at java.lang.StringBuilder.append(StringBuilder.java:136)at com.hero.TestJvmOutOfMemory.main(TestJvmOutOfMemory.java:13)
可以看到,当发生内存溢出时,会dump文件到java_pid31092.hprof。
 {width=“7799989063867017in”
{width=“7799989063867017in”
height=“2.0249989063867018in”}
1.3 导入到MAT工具中进行分析
 {width=“6.397988845144357in”
{width=“6.397988845144357in”
height=“4.013437226596675in”}
可以看到,有81.72%的内存由Object[]数组占有,所以比较可疑。
分析:这个可疑是正确的,因为已经有超过80%的内存都被它占有,这是非常有可能出现内存溢出的。查看详情:
 {width=“6.243832020997376in”
{width=“6.243832020997376in”
height=“2.5975in”}
可以看到集合中存储了大量的uuid字符串。
实战02-检测死锁
有些时候我们需要查看下jvm中的线程执行情况,比如,发现服务器的CPU的负载突然增高了、出现了死锁、死循环等,我们该如何分析呢?
由于程序是正常运行的,没有任何的输出,从日志方面也看不出什么问题,所以就需要看下JVM的内部线程的执行情况,然后再进行分析查找出原因。
 {width=“6.535541338582677in”
{width=“6.535541338582677in”
height=“4049989063867017in”}
这个时候,就需要借助于jstack命令了,jstack的作用是将正在运行的jvm的线程情况进行快照,并且打印出来:
2.1 线程的状态
并发编程中详细讲解
2.2 实战:死锁问题
如果在生产环境发生了死锁,我们将看到的是部署的程序没有任何反应了,这个时候我们可以借助jstack进行分析,下面我们实战下查找死锁的原因。
2.2.1 构造死锁
编写代码,启动2个线程,Thread1拿到了obj1锁,准备去拿obj2锁时,obj2已经被Thread2锁定,所以发生了死锁。
public class TestDeadLock {private static Object obj1 = new Object();private static Object obj2 = new Object();public static void main(String[] args) {new Thread(new Thread1()).start(); // 启动线程01new Thread(new Thread2()).start(); // 启动线程02}// 线程01private static class Thread1 implements Runnable {@Overridepublic void run() {synchronized (obj1) {System.out.println("Thread1 拿到了 obj1 的锁!");try {// 停顿2秒的意义在于,让Thread2线程拿到obj2的锁Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}synchronized (obj2) {System.out.println("Thread1 拿到了 obj2 的锁!");}}}}// 线程02private static class Thread2 implements Runnable {@Overridepublic void run() {synchronized (obj2) {System.out.println("Thread2 拿到了 obj2 的锁!");try {// 停顿2秒的意义在于,让Thread1线程拿到obj1的锁Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}synchronized (obj1) {System.out.println("Thread2 拿到了 obj1 的锁!");}}}}
}
2.2.2 在Linux上运行
 {width=“6.411951006124235in”
{width=“6.411951006124235in”
height=“1.38in”}
2.2.3 使用jstack进行分析
jstack 18487 | grep 'BLOCKED' -A 15 --color
 {width=“6.396827427821522in”
{width=“6.396827427821522in”
height=“2.845833333333333in”}
可以清晰的看到:
Thread2获取了 <0x00000000d8b5a678> 的锁,等待获取<0x00000000d8b5a668>这个锁
Thread1获取了 <0x00000000d8b5a668> 的锁,等待获取<0x00000000d8b5a678>这个锁由此可见,发生了死锁。
2.2.4 使用Arthas进行分析
thread -b
 {width=“6.491110017497813in”
{width=“6.491110017497813in”
height=“1.2266655730533684in”}
可以准确知道: 死锁在代码的中的第几行
扩展01-高并发场景下JVM调优实践
背景:不久之前,我解决了这样一个JVM性能问题。我司APP某核心接口高峰期响应慢。通过Grafana发现,接口响应慢、同时该服务的GC也有异常,两者之间存在相关性。本案例是来自于当时的实践。
今日总结:
-
JVM相关工具
- jps JVM Process status tool:JVM进程状态工具,查看进程基本信息
- jstat: JVM statistics monitoring tool : JVM统计监控工具,查看堆,GC详细信息
- jinfo:Java Configuration Info :查看配置参数信息,支持部分参数运行时修改
- jmap:Java Memory Map:分析堆内存工具,dump堆内存快照
- jhat:Java Heap Analysis Tool :堆内存dump文件解析工具
- jstack:Java Stack Trace :Java堆栈跟踪工具
- VisualVM:性能分析可视化工具
-
第三方JVM优化工具
- GCEasy:免费GC日志可视化分析Web工具
- MAT:Memory Analyzer Tool 可视化内存分析工具
- Arthas:线上Java程序诊断工具,功能非常强大
- GCViewer:开源的GC日志分析工具
-
JVM参数:标准化参数,非标准化参数,不稳定参数
-
JVM调优基本知识
- 为什么JVM调优?调优的最终目的都是为了应用程序使用最小的硬件消耗来承载更大的吞吐量
- 什么时候JVM调优?
- 系统吞吐量下降,或P90、P99响应增加
- 堆内存持续上涨,到出现OOM
- 频繁FullGC、GC停顿过长
- 堆内存占用过高
- 调优调什么?内存合理分配与使用、垃圾收集器的选配
- 调优原则
- 优先原则:产品、架构、代码、数据库优先,JVM是最后的手段
- 观测性原则:发现问题解决问题,没问题不创造问题。
- 调优步骤:监控JVM分析问题 --》 确定目标 --》制定方案 --》 验证方案 --》 结果验收 --》 结束
-
GC日志解析及可视化分析工具
- GCEasy
- JVM监控环境搭建之Grafana+Prometheus+Micrometer
-
JVM调优实践
- 内存优化:堆内存+元空间调优
- 线程堆栈优化
- GC优化:吞吐量优先PS+PO
- GC优化:响应时间优先ParNew+CMS
- GC优化:大内存,吞吐量+响应时间全功能G1
-
JVM调优实战场景
- 内存溢出的定位与分析MAT
- 检测死锁:jstack、Arthas
-
重点:JVM调优实践、JVM分析工具的使用
-
难点:理解GC垃圾收集器的特点
-
易错点:先完成再完美,先保证完成课程中的所有案例,具体工具等细节可以待有时间再行研究