1、MyBatis返回多个结果集
MyBatis可以通过存储过程或者自定义查询语句来返回多个结果集。
- 存储过程
存储过程(Stored Procedure)是一组预编译的 SQL 语句集合,可以在数据库中被多次调用。存储过程通常用于执行特定的任务或操作,并且可以接受参数、返回结果,甚至可以包含流程控制和逻辑处理。
如果你使用存储过程,可以在存储过程中执行多个查询语句并返回多个结果集,然后通过MyBatis的映射配置将这些结果集映射到不同的对象中。
示例:
当使用存储过程来返回多个结果集时,可以按照以下步骤进行操作:
- 在数据库中创建一个存储过程,该存储过程包含多个查询语句,并能够返回多个结果集。例如,下面是一个简单的 MySQL 存储过程示例:
DELIMITER //CREATE PROCEDURE get_multiple_result_sets()
BEGINSELECT * FROM table1;SELECT * FROM table2;
END //
- 在 MyBatis 的映射文件中配置调用存储过程的语句,并指定结果集的映射关系。例如,可以使用
<select>标签来执行存储过程并映射结果集:
<select id="callMultipleResultSets" statementType="CALLABLE">{ call get_multiple_result_sets() }
</select>
- 在 Java 代码中调用 MyBatis 的
selectList方法来执行存储过程并获取多个结果集。示例代码如下:
try (SqlSession sqlSession = sqlSessionFactory.openSession()) {List<Object> results = sqlSession.selectList("namespace.callMultipleResultSets");// 处理返回的多个结果集for (Object result : results) {// 处理每个结果集}
}
通过以上步骤,你可以使用存储过程来返回多个结果集,并通过 MyBatis 实现结果集的映射和处理。在实际应用中,根据具体情况进行适当的调整和扩展。
- 自定义查询语句
另外,如果你使用自定义查询语句,也可以在SQL语句中使用MySQL的分号来执行多个查询,然后在MyBatis中获取这些结果集并进行处理。在MyBatis的映射文件中,可以使用<select>标签的resultSets属性来指定返回多个结果集,并使用<resultMap>标签来定义每个结果集的映射规则。
示例:
展示如何在 MyBatis 中执行包含多个查询的自定义 SQL 语句,并进行结果集的处理:
首先,在 MyBatis 的映射文件(如 mapper.xml)中定义包含多个查询的 SQL 语句,并指定返回多个结果集:
<select id="callMultipleQueries" resultSets="result1, result2">SELECT * FROM table1;SELECT * FROM table2;
</select><resultMap id="result1" type="YourResultType1"><!-- 定义 result1 的映射规则 -->
</resultMap><resultMap id="result2" type="YourResultType2"><!-- 定义 result2 的映射规则 -->
</resultMap>
接下来,在 MyBatis 的 Mapper 接口中定义对应的方法,并使用 @Select 注解指定对应的 SQL 语句:
public interface YourMapper {@Select("SELECT * FROM table1; SELECT * FROM table2;")@Results({@Result(property = "field1", column = "column1", javaType = YourResultType1.class, resultMap = "result1"),@Result(property = "field2", column = "column2", javaType = YourResultType2.class, resultMap = "result2")})List<YourResultType1> callMultipleQueries();
}
通过以上配置,你可以在 MyBatis 中执行包含多个查询的自定义 SQL 语句,并将结果集映射到对应的 Java 对象中进行处理。这种方式可以有效地利用 MyBatis 的功能来处理复杂的查询逻辑,并将查询结果映射到 Java 对象中方便后续操作。
2、创建线程的几种方式,哪种方式好
在 Java 中,创建线程的几种方式包括继承 Thread 类、实现 Runnable 接口、使用 Callable 和 Future、使用线程池等。每种方式都有其适用的场景和优劣点,下面简要介绍这几种方式:
- 继承 Thread 类:
- 创建一个类继承自 Thread 类,并重写 run() 方法来定义线程执行的任务。
- 优点:简单直观,适合简单的线程任务。
- 缺点:Java 不支持多重继承,因此如果已经继承了其他类,则无法再通过继承 Thread 类来创建线程。
以下是使用继承 Thread 类创建线程的 Java 代码示例:
public class MyThread extends Thread {public void run() {System.out.println("MyThread is running");}public static void main(String[] args) {MyThread thread = new MyThread();thread.start();}
}
在上述示例中,我们定义了一个类 MyThread 继承自 Thread 类,并重写了 run() 方法来定义线程执行的任务。在 main 方法中创建 MyThread 的实例并调用 start() 方法启动线程。
这种方式简单直观,适合于简单的线程任务。但需要注意的是,由于 Java 不支持多重继承,如果已经继承了其他类,则无法再通过继承 Thread 类来创建线程。
- 实现 Runnable 接口:
- 创建一个类实现 Runnable 接口,并实现 run() 方法。
- 优点:避免了 Java 单继承的限制,更灵活。
- 缺点:需要创建 Thread 对象并将实现了 Runnable 接口的对象作为参数传递给 Thread 对象。
以下是使用实现 Runnable 接口创建线程的 Java 代码示例:
public class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println("MyRunnable is running");}public static void main(String[] args) {MyRunnable myRunnable = new MyRunnable();Thread thread = new Thread(myRunnable);thread.start();}
}
在上述示例中,我们定义了一个类 MyRunnable 实现了 Runnable 接口,并实现了 run() 方法来定义线程执行的任务。在 main 方法中创建 MyRunnable 的实例,然后创建 Thread 对象并将 MyRunnable 的实例作为参数传递给 Thread 对象,最后调用 start() 方法启动线程。
通过实现 Runnable 接口,避免了 Java 单继承的限制,更加灵活,可以更好地组织代码结构。
- 使用 Callable 和 Future:
- 创建一个实现 Callable 接口的类,可以返回线程执行的结果,并通过 FutureTask 进行管理。
- 优点:可以获取线程执行的结果,支持异常处理。
- 缺点:相对于实现 Runnable 接口更复杂一些。
以下是使用 Callable 和 Future 创建线程的 Java 代码示例:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;public class MyCallable implements Callable<String> {@Overridepublic String call() throws Exception {return "Callable thread is running";}public static void main(String[] args) throws InterruptedException, ExecutionException {Callable<String> callable = new MyCallable();FutureTask<String> futureTask = new FutureTask<>(callable);Thread thread = new Thread(futureTask);thread.start();System.out.println(futureTask.get());}
}
在上述示例中,我们定义了一个类 MyCallable 实现了 Callable 接口,并实现了 call() 方法来定义线程执行的任务。在 main 方法中创建 MyCallable 的实例,然后创建 FutureTask 对象并将 MyCallable 的实例作为参数传递给 FutureTask 对象,最后创建 Thread 对象并将 FutureTask 对象作为参数传递给 Thread 对象,启动线程。通过 FutureTask 的 get() 方法可以获取线程执行的结果。
使用 Callable 和 Future 可以获取线程执行的结果,支持异常处理,相对于实现 Runnable 接口更加灵活。
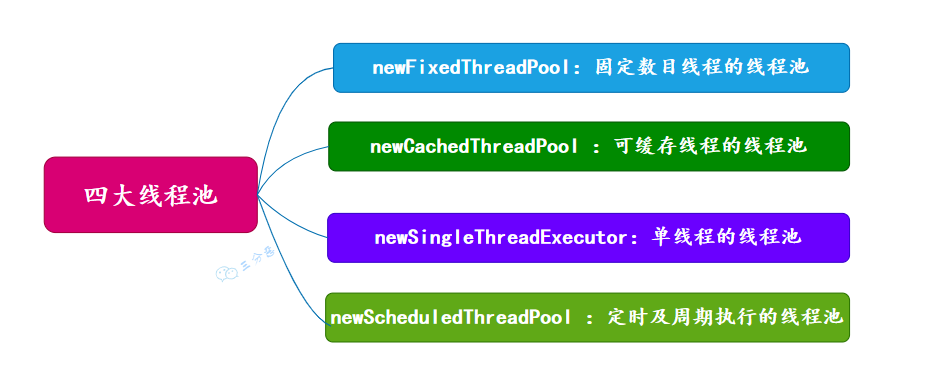
- 使用线程池:
- 使用 Executors 工厂类创建线程池,可以重用线程、控制并发数等。
- 优点:提高了线程的管理效率,避免频繁创建和销毁线程的开销。
- 缺点:可能会引入线程安全和资源管理的问题。
以下是使用线程池创建线程的 Java 代码示例:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ThreadPoolExample {public static void main(String[] args) {ExecutorService executor = Executors.newFixedThreadPool(5); // 创建一个固定大小的线程池,包含5个线程for (int i = 0; i < 10; i++) {Runnable worker = new MyTask("Task " + i);executor.execute(worker); // 提交任务给线程池执行}executor.shutdown(); // 关闭线程池while (!executor.isTerminated()) {}System.out.println("All tasks are finished");}
}class MyTask implements Runnable {private String taskName;public MyTask(String taskName) {this.taskName = taskName;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " Start. Task = " + taskName);processTask();System.out.println(Thread.currentThread().getName() + " End.");}private void processTask() {// 模拟任务执行try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}}
}
在上述示例中,我们使用 Executors 工厂类创建了一个固定大小为5的线程池。然后创建了10个任务(MyTask),并通过 execute 方法提交给线程池执行。最后调用 shutdown 方法关闭线程池。
使用线程池能够提高线程的管理效率,避免频繁创建和销毁线程的开销。但需要注意线程安全和资源管理的问题,例如共享资源的访问需谨慎处理。
哪种方式好?
根据具体的需求和场景选择合适的方式。一般来说,推荐使用实现 Runnable 接口的方式或者使用线程池,因为它们比较灵活且易于管理。
下面是一个简单的示例,演示如何通过实现 Runnable 接口的方式创建线程:
public class MyRunnable implements Runnable {@Overridepublic void run() {System.out.println("MyThread is running");}public static void main(String[] args) {Thread thread = new Thread(new MyRunnable());thread.start();}
}
通过上述示例,可以看到如何通过实现 Runnable 接口并创建 Thread 对象来启动一个线程。
3、什么是消息队列
消息队列是一种异步的服务间通信方式,适用于无服务器和微服务架构。消息在被处理和删除之前一直存储在队列上。
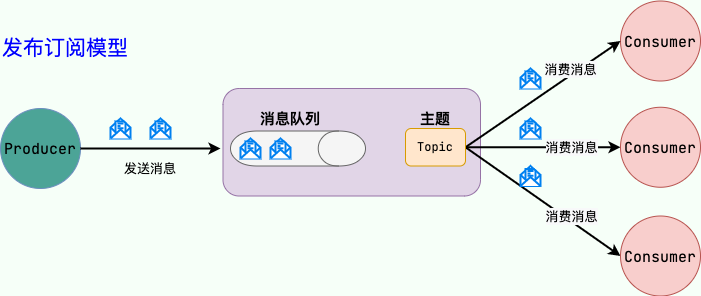
消息队列是一种在软件系统中用于存储、转发和处理消息的技术。它通常被用于异步通信,将消息从一个应用程序传递到另一个应用程序,或者在同一个应用程序的不同组件之间进行通信。
消息队列通常包含以下核心组件和特性:
- 消息生产者(Producer):负责向消息队列发送消息的组件。
- 消息队列(Message Queue):用于存储消息的数据结构,消息按照先进先出的顺序排队等待被消费。
- 消息消费者(Consumer):从消息队列中取出消息并进行处理的组件。
- 消息(Message):要在系统中传递的信息单元,可以是文本、对象、指令等。
- 队列管理器(Queue Manager):负责消息的存储、管理和传递,确保消息的可靠性和顺序性。
消息队列的优点包括:
- 解耦合:消息队列实现了生产者和消费者之间的解耦合,提高了系统的灵活性和可维护性。
- 异步通信:生产者和消费者可以独立运行,不需要等待彼此的响应,提高了系统的响应速度和吞吐量。
- 削峰填谷:能够平衡生产者和消费者之间的速率差异,缓解系统压力,避免系统崩溃。
消息队列在分布式系统、微服务架构、大数据处理等场景中被广泛应用,如 Apache Kafka、RabbitMQ、ActiveMQ 等都是常见的消息队列实现。
4、HashMap如何解决Hash冲突
在 HashMap 中,Hash 冲突是指不同的键经过哈希函数计算后得到相同的哈希值,导致它们应该被存储在 HashMap 的同一个桶中。HashMap 采用了链地址法(Separate Chaining)来解决哈希冲突。
具体来说,当发生哈希冲突时,HashMap 会将具有相同哈希值的键值对存储在同一个桶内,形成一个链表结构。每个桶实际上是一个链表的头部,当插入新的键值对时,HashMap 会首先计算键的哈希值,然后根据哈希值找到对应的桶,最后将新的键值对添加到链表的末尾。
在 Java 8 中,当链表长度超过一定阈值(默认为8)时,链表会转换为红黑树,以提高查询效率。这样即使发生哈希冲突,仍然可以保持较好的性能。
总结一下,HashMap 解决哈希冲突的主要方式是使用链地址法,即将具有相同哈希值的键值对存储在同一个桶内,并通过链表或红黑树来处理多个键值对的存储和查找。
5、MySQL事务隔离机制有几种
MySQL 提供了四种事务隔离级别,分别是:
-
读未提交(Read Uncommitted):最低级别的事务隔离,允许一个事务可以看到另一个事务修改但尚未提交的数据。可能会导致脏读、不可重复读和幻影读问题。
-
读已提交(Read Committed):确保一个事务只能看到已经提交的数据,避免了脏读问题。但依然可能出现不可重复读和幻影读问题。
-
可重复读(Repeatable Read):确保在同一个事务中多次读取相同数据时,结果始终一致。避免了脏读、不可重复读问题,但仍可能出现幻影读问题。
-
串行化(Serializable):提供最高的事务隔禅级别,在执行期间对被操作的数据集加锁,避免了脏读、不可重复读和幻影读问题。但是会降低并发性能,因为事务之间需要相互等待锁释放。
在 MySQL 中,默认的事务隔离级别是可重复读(Repeatable Read)。开发人员可以根据具体的业务需求选择合适的事务隔离级别。需要注意的是,较高的事务隔离级别往往会带来更高的系统开销和性能损耗,因此需要权衡利弊进行选择。
6、MySQL的聚合函数有哪些
MySQL 提供了多种聚合函数用于对数据进行计算和统计。常用的 MySQL 聚合函数包括:
-
COUNT():用于计算结果集中行的数量。
-
SUM():用于计算指定列的总和。
-
AVG():用于计算指定列的平均值。
-
MAX():用于返回指定列的最大值。
-
MIN():用于返回指定列的最小值。
-
GROUP_CONCAT():将查询结果集中的每行数据按照指定的顺序连接起来,常用于将多行数据合并成单行并以逗号分隔的形式展示。
以下是一个简单的 SQL 示例,演示如何使用 COUNT()、SUM()、AVG()、MAX()、MIN() 等聚合函数:
-- 创建一个示例表
CREATE TABLE students (id INT,name VARCHAR(50),score INT
);-- 插入示例数据
INSERT INTO students (id, name, score) VALUES (1, 'Alice', 85);
INSERT INTO students (id, name, score) VALUES (2, 'Bob', 92);
INSERT INTO students (id, name, score) VALUES (3, 'Charlie', 78);
INSERT INTO students (id, name, score) VALUES (4, 'David', 90);
INSERT INTO students (id, name, score) VALUES (5, 'Emily', 87);-- 使用聚合函数进行统计
SELECT COUNT(*) AS total_students,SUM(score) AS total_score,AVG(score) AS average_score,MAX(score) AS max_score,MIN(score) AS min_score
FROM students;
在这个示例中,我们首先创建了一个名为 students 的表,并向其中插入了一些学生的成绩数据。然后,通过 SELECT 语句结合 COUNT()、SUM()、AVG()、MAX()、MIN() 等聚合函数,对学生的成绩数据进行统计计算,得到总人数、总分数、平均分、最高分和最低分等信息。
以下是一个SQL 示例,演示如何使用 GROUP_CONCAT() 函数将查询结果集中的每行数据按照指定的顺序连接起来:
假设有一个名为 products 的表,包含了产品信息,字段包括 category 和 product_name,我们想要按照类别将产品名称连接成一个字符串并以逗号分隔展示:
-- 创建示例表 products
CREATE TABLE products (id INT,category VARCHAR(50),product_name VARCHAR(50)
);-- 插入示例数据
INSERT INTO products (id, category, product_name) VALUES (1, 'Electronics', 'Laptop');
INSERT INTO products (id, category, product_name) VALUES (2, 'Electronics', 'Smartphone');
INSERT INTO products (id, category, product_name) VALUES (3, 'Clothing', 'T-shirt');
INSERT INTO products (id, category, product_name) VALUES (4, 'Clothing', 'Jeans');
INSERT INTO products (id, category, product_name) VALUES (5, 'Clothing', 'Shoes');-- 使用 GROUP_CONCAT() 函数进行连接
SELECT category,GROUP_CONCAT(product_name ORDER BY product_name SEPARATOR ', ') AS products_in_category
FROM products
GROUP BY category;
在这个表达式中:
GROUP_CONCAT()是一个 MySQL 聚合函数,用于将组内的值连接成一个字符串。product_name是要连接的字段名,表示我们希望将哪个字段的值连接起来。ORDER BY product_name指定了在连接时按照product_name的值进行排序,确保连接后的字符串中产品名称是按照字母顺序排列的。SEPARATOR ', '表示用逗号加空格作为分隔符,在每个值连接起来形成的字符串中,不同产品名称之间用逗号加空格分隔开。
因此,整个表达式 GROUP_CONCAT(product_name ORDER BY product_name SEPARATOR ', ') 的含义是将每个组内的 product_name 字段值按照产品名称的字母顺序连接成一个字符串,并使用逗号加空格作为分隔符。
在这个示例中,我们首先创建了一个名为 products 的表,并向其中插入了一些产品信息数据。然后,通过 SELECT 语句结合 GROUP_CONCAT() 函数,按照类别将产品名称连接成一个字符串,并按照产品名称的顺序排序,最后以逗号加空格的形式显示出来。最后使用 GROUP BY 子句按照类别进行分组,得到每个类别下产品名称的合并结果。
总结
这些聚合函数可以结合 SQL 查询语句使用,在 SELECT 语句中对数据进行统计和计算,帮助用户快速获取需要的数据摘要信息。
7、说说你对集合的了解
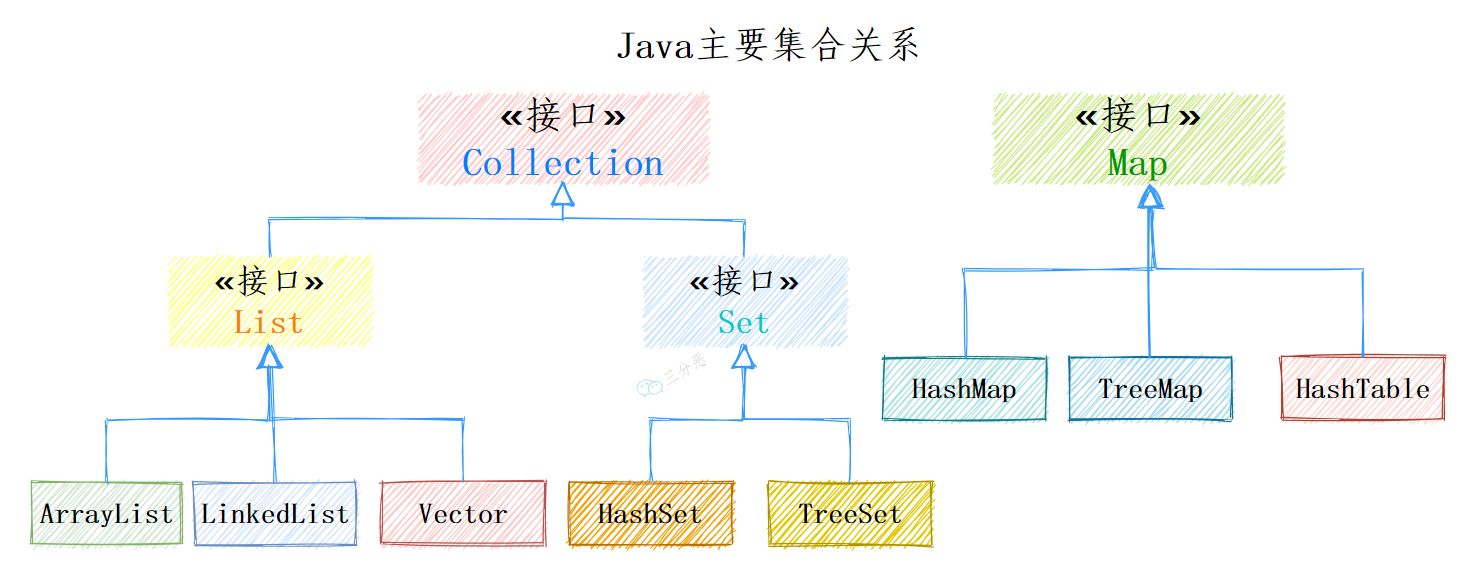 Java集合框架是Java编程语言中用于存储、操作和管理一组对象的类库。Java集合框架提供了一系列接口(interfaces)和类(classes),用于表示不同类型的集合,如列表(List)、集(Set)、映射(Map)等。以下是我对Java集合框架的一些了解:
Java集合框架是Java编程语言中用于存储、操作和管理一组对象的类库。Java集合框架提供了一系列接口(interfaces)和类(classes),用于表示不同类型的集合,如列表(List)、集(Set)、映射(Map)等。以下是我对Java集合框架的一些了解:
-
常见接口和类:
- List接口:继承自Collection接口,表示有序、可重复的集合。常见的实现类有ArrayList、LinkedList。
- Set接口:继承自Collection接口,表示无序、不重复的集合。常见的实现类有HashSet、LinkedHashSet、TreeSet。
- Map接口:表示键值对的集合,键是唯一的。常见的实现类有HashMap、LinkedHashMap、TreeMap。
-
集合框架的特点:
- 泛型支持:集合框架使用泛型来确保类型安全,在编译时就能捕获到类型不匹配的错误。
- 迭代器:集合框架提供了Iterator接口和增强for循环,方便遍历集合中的元素。
- 高效性能:集合框架提供了各种数据结构的实现类,针对不同的需求有不同的选择,从而可以实现高效的操作。
-
常见操作:
- 添加和删除元素:通过add()和remove()方法向集合中添加或删除元素。
- 查找元素:通过contains()方法判断集合中是否包含某个元素。
- 遍历集合:可以使用Iterator接口、增强for循环或stream API来遍历集合中的元素。
- 集合间的操作:可以进行集合的交集、并集、差集等操作。
总的来说,Java集合框架提供了丰富的数据结构和操作方法,能够满足不同场景下的需求。熟练掌握Java集合框架可以让开发人员更高效地处理和管理数据集合。
8、Cookie和session的区别
Cookie和Session是Web开发中常用的两种机制,用于在客户端和服务器之间存储信息。它们之间的主要区别如下:
-
存储位置:
- Cookie:Cookie是存储在客户端(通常是浏览器)上的小型文本文件,可以通过在HTTP响应头中设置Set-Cookie字段将Cookie发送给客户端,客户端会在后续的请求中通过Cookie请求头将Cookie发送回服务器。
- Session:Session数据则是存储在服务器端的,通常是在服务器内存或数据库中保存的,客户端只会在请求时携带一个用于标识Session的标识符(通常是一个Session ID)。
-
安全性:
- Cookie:由于Cookie是存储在客户端的,所以可能会受到一些安全风险,比如被窃取、篡改等。为了增加安全性,可以对Cookie进行加密或设置HttpOnly属性来防止被恶意脚本访问。
- Session:Session数据存储在服务器端,相对来说更加安全,客户端无法直接访问其中的数据。
-
容量限制:
- Cookie:单个Cookie的大小通常受到限制,不同浏览器对Cookie的大小限制不同,一般为几KB到几MB不等。
- Session:Session数据一般存在于服务器内存或数据库中,理论上可以存储更大量级的数据。
-
生存周期:
- Cookie:可以设置Cookie的过期时间,可以是会话级的(浏览器关闭时失效)或永久性的(指定过期时间)。
- Session:Session通常在用户关闭浏览器或一定时间内没有活动时会被销毁。
总的来说,Cookie适合存储少量且不敏感的数据,而Session适合存储敏感数据或大量数据。在实际应用中,通常会结合使用Cookie和Session来实现用户认证、状态管理等功能。
9、String 和 StringBuffer、StringBuilder 的区别是什么?
在Java中,String、StringBuffer和StringBuilder都用来表示字符串,它们之间的主要区别如下:
-
不可变性:
- String:String是不可变的,即一旦创建就不能被修改。对String对象进行任何改变(如拼接、替换等)都会创建一个新的String对象。
- StringBuffer和StringBuilder:StringBuffer和StringBuilder是可变的,可以对它们进行修改而不创建新对象。StringBuffer是线程安全的(即支持多线程),而StringBuilder是非线程安全的。
-
线程安全性:
- String:String是不可变的,因此是线程安全的。
- StringBuffer:由于StringBuffer是线程安全的,它的操作是同步的(synchronized),适合在多线程环境下使用。
- StringBuilder:StringBuilder是非线程安全的,性能比StringBuffer更好,但在多线程环境下使用时需要自行保证同步。
-
性能:
- String:由于不可变性,每次对String对象的修改都会导致新的对象的创建,可能会影响性能。
- StringBuffer和StringBuilder:由于可变性,对于频繁的字符串操作,使用StringBuffer和StringBuilder会比String更高效,其中StringBuilder的性能更好,但不是线程安全的。
-
适用场景:
- String:适用于不经常变化的字符串,如配置信息、常量等。
- StringBuffer:适用于多线程环境,或需要频繁进行字符串操作的情况。
- StringBuilder:适用于单线程环境下需要频繁进行字符串操作的情况,且不需要考虑线程安全性。
总的来说,如果需要频繁进行字符串操作且不需要考虑线程安全性,建议使用StringBuilder;如果在多线程环境下需要进行字符串操作,则使用StringBuffer;而String适合存储不可变的字符串。
10、String类的常用方法
String类是Java中用来表示字符串的类,提供了丰富的方法来操作字符串。下面是String类的一些常用方法:
-
length():返回字符串的长度。
-
charAt(int index):返回指定索引位置的字符。
-
concat(String str):将指定字符串连接到此字符串的结尾。等价于使用"+"进行字符串拼接。
-
equals(Object anObject):比较字符串内容是否相同。
-
equalsIgnoreCase(String anotherString):忽略大小写比较字符串内容是否相同。
-
indexOf(String str):返回字符串中第一次出现指定子字符串的索引。
-
substring(int beginIndex):返回一个新的字符串,从beginIndex开始直到字符串末尾。
-
substring(int beginIndex, int endIndex):返回一个新的字符串,包含指定索引区间内的字符(不包括endIndex位置的字符)。
-
toUpperCase():将字符串转换为大写形式。
-
toLowerCase():将字符串转换为小写形式。
-
trim():去除字符串首尾的空白字符。
-
startsWith(String prefix):判断字符串是否以指定前缀开头。
-
endsWith(String suffix):判断字符串是否以指定后缀结尾。
-
replace(char oldChar, char newChar):将字符串中的所有oldChar字符替换为newChar字符。
-
split(String regex):根据给定正则表达式将字符串拆分为字符串数组。
这些只是String类中的一部分常用方法,String类还提供了很多其他方法用于对字符串进行各种操作。
11、SQL题目 查询学生课程成绩表中成绩为空或低于平均分的记录要查询学生课程成绩表中成绩为空或低于平均分的记录,可以使用以下SQL语句:
SELECT s.name AS student_name, c.name AS course_name, sc.score
FROM 学生表 s, 课程表 c, 学生课程成绩表 sc
WHERE s.id = sc.sid
AND c.id = sc.cid
AND (sc.score IS NULL OR sc.score < (SELECT AVG(score) FROM 学生课程成绩表))
这条SQL语句将会查询学生表、课程表和学生课程成绩表联合起来,找出成绩为空或低于平均分的学生课程成绩记录。
让我来解析一下这个查询语句的顺序和逻辑:
-
表关联:
- 首先,通过
学生表 s, 课程表 c, 学生课程成绩表 sc将三张表连接起来,以便后续筛选和获取需要的字段。
- 首先,通过
-
条件筛选:
WHERE s.id = sc.sid AND c.id = sc.cid:这两个条件用来确保学生表、课程表和学生成绩表之间的关联正确,即学生表的id和学生成绩表的sid相匹配,课程表的id和学生成绩表的cid相匹配。
-
成绩判断:
AND (sc.score IS NULL OR sc.score < (SELECT AVG(score) FROM 学生课程成绩表)):这部分条件用来筛选出成绩为空或低于平均分的记录。首先判断成绩是否为空,如果为空则符合条件;如果不为空,则判断成绩是否低于整个学生课程成绩表的平均分,如果低于平均分则也符合条件。
-
字段选择:
SELECT s.name AS student_name, c.name AS course_name, sc.score:最后根据条件筛选出的记录,选择需要显示的字段,包括学生姓名、课程名称和成绩。
这样的顺序和逻辑可以确保查询结果准确地找出成绩为空或低于平均分的学生课程成绩记录,并保证查询的效率。
12、遍历HashMap的几种方式
遍历HashMap有多种方式,下面列举了几种常用的遍历方式:
- 使用entrySet()遍历:
Map<K, V> map = new HashMap<>();
// 填充mapfor (Map.Entry<K, V> entry : map.entrySet()) {K key = entry.getKey();V value = entry.getValue();// 处理key和value
}
- 只遍历键或值:
Map<K, V> map = new HashMap<>();
// 填充map// 遍历键
for (K key : map.keySet()) {// 处理key
}// 遍历值
for (V value : map.values()) {// 处理value
}
- 使用Iterator遍历:
Map<K, V> map = new HashMap<>();
// 填充mapIterator<Map.Entry<K, V>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {Map.Entry<K, V> entry = iterator.next();K key = entry.getKey();V value = entry.getValue();// 处理key和value
}
- Java 8中的forEach遍历:
Map<K, V> map = new HashMap<>();
// 填充mapmap.forEach((key, value) -> {// 处理key和value
});
13、讲出两种设计模式(单例、策略)
-
单例模式(Singleton Pattern):

- 单例模式是一种创建型设计模式,它保证一个类只有一个实例,并提供一个全局访问点来访问这个实例。
- 通常情况下,单例模式通过构造方法私有化、静态变量保存实例、提供静态方法返回唯一实例来实现。
- 单例模式适用于需要严格控制一个类只能有一个实例的场景,比如配置信息类、日志记录类等。
示例代码:
public class Singleton {private static Singleton instance;private Singleton() {// 私有构造方法,防止外部实例化}public static Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}
}
在这个示例中,我们通过将构造方法私有化并使用静态变量instance保存唯一实例,实现了单例模式。getInstance()方法用于获取该唯一实例。
-
策略模式(Strategy Pattern):

- 策略模式是一种行为型设计模式,它定义了一系列算法,并使得这些算法可以互相替换,让算法的变化独立于使用算法的客户。
- 在策略模式中,通常会定义一个接口或抽象类来表示策略,然后针对不同的需求提供具体的策略实现。
- 客户端可以在运行时动态切换不同的策略,从而实现灵活地改变系统的行为。
示例代码:
public interface PaymentStrategy {void pay(int amount);
}public class CreditCardPayment implements PaymentStrategy {@Overridepublic void pay(int amount) {System.out.println("Paid " + amount + " via Credit Card");}
}public class CashPayment implements PaymentStrategy {@Overridepublic void pay(int amount) {System.out.println("Paid " + amount + " via Cash");}
}public class PaymentContext {private PaymentStrategy paymentStrategy;public PaymentContext(PaymentStrategy paymentStrategy) {this.paymentStrategy = paymentStrategy;}public void pay(int amount) {paymentStrategy.pay(amount);}
}
在这个示例中,我们定义了一个PaymentStrategy接口表示支付策略,并分别实现了CreditCardPayment和CashPayment两种具体的支付策略。PaymentContext类包含了一个支付策略,可以根据不同的情况选择不同的策略进行支付。
14、写两种排序算法(冒泡排序,选择排序)
- 冒泡排序
冒泡排序(Bubble Sort):通过相邻元素的比较和交换来实现排序,每一轮将最大(或最小)的元素移动到数组末尾(或开头)。
public class BubbleSort {public static void main(String[] args) {int[] arr = {64, 34, 25, 12, 22, 11, 90};System.out.println("排序前数组:");printArray(arr);bubbleSort(arr);System.out.println("\n排序后数组:");printArray(arr);}// 冒泡排序函数public static void bubbleSort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {for (int j = 0; j < n - i - 1; j++) {if (arr[j] > arr[j + 1]) {// 交换arr[j]和arr[j+1]int temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}}// 打印数组函数public static void printArray(int[] arr) {for (int value : arr) {System.out.print(value + " ");}}
}
冒泡排序的核心思想是通过相邻元素的比较和交换,逐步将最大(或最小)的元素移动到数组的末尾(或开头)。
- 选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。它的工作原理如下:
- 首先,在未排序序列中找到最小(或最大)的元素,存放到排序序列的起始位置。
- 然后,再从剩余未排序元素中继续寻找最小(或最大)的元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
唯一的好处可能就是不占用额外的内存空间了吧。
以下是选择排序的Java代码示例:
public class SelectionSort {public static void main(String[] args) {int[] arr = {64, 34, 25, 12, 22, 11, 90};System.out.println("排序前数组:");printArray(arr);selectionSort(arr);System.out.println("\n排序后数组:");printArray(arr);}// 选择排序函数public static void selectionSort(int[] arr) {int n = arr.length;for (int i = 0; i < n - 1; i++) {int minIndex = i;for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}// 将找到的最小元素与当前位置交换int temp = arr[minIndex];arr[minIndex] = arr[i];arr[i] = temp;}}// 打印数组函数public static void printArray(int[] arr) {for (int value : arr) {System.out.print(value + " ");}}
}
选择排序的核心思想是每次遍历未排序部分,找到最小元素的索引,然后将其与未排序部分的第一个元素交换位置,这样经过 n-1 次遍历后,整个数组就会有序。选择排序的时间复杂度也是 O(n^2),因此效率较低,不适用于大规模数据的排序。