ChemLLM论文介绍,垂直领域模型搭建训练指南(ChemLLM: A Chemical Large Language Model)
返回论文目录
1.论文简介
论文是上海人工智能实验室的工作,想训练一个化学垂直领域的对话大模型,然而现有的化学数据往往是结构性的,所以这里论文提出了一套垂直领域数据制作和训练方法,为社区制作专有领域模型提供参考。ChemLLM在化学的三个主要任务上都超过了GPT-3.5,并且超过了GPT-3.5,在其中两个任务上都超过了GPT-4。值得注意的是,ChemLLM对相关的数学和物理任务也显示出了特殊的适应性,尽管它主要接受了以化学为中心的语料库的训练。
2.介绍
此前,存在3个挑战:
- 原化学的表达是SMILES,不适合自然语言处理。
- 大部分的化学信息和知识都存储在结构化的数据库中
- 化学数据和任务非常多样化,这使得为化学LLM设计一个统一的训练管道变得困难
作者通过开发一个合成化学指令调优数据集ChemData来解决这些挑战,该数据集利用一种基于模板的指令构建方法,可以将结构化的化学数据转换为适合于训练llm的自然对话形式。并进一步训练了一个化学专业模型ChemLLM,ChemLLM是基于大规模化学语料训练的,包括来自丰富模板合成的各种化学指令数据,如化学名称转换、分子性质预测、分子生成、分子标题、反应条件预测、反应产物预测等。论文还提出了一个两阶段的指令调整管道来适应ChemLLM:通用语料库和化学领域知识训练。这种训练管道保留了ChemLLM在一般情况下的能力,并使消融实验能够比较第二阶段的化学语料库训练对模型的影响。
作者进行了3方面的评估:
- 化学专业领域能力
- 通用领域语言模型能力
- 多语言能力的评估
3.ChemData
本节介绍ChemData,这是一个为化学语言模型(llm)精心定制的创新的指令调优数据集。化学数据已经被精心设计为包含三个基本类别:分子、反应和特定领域的任务。总的来说,这些类别封装了化学研究的基本组成部分,为推进该领域提供了一个全面的资源。在即将到来的小节中,我们将深入研究不同的数据来源,概述每个类别中的具体任务,并描述为组装这个数据集所进行的细致过程。通过这一详细的描述,我们的目的是清楚地概述化学数据的来源,相应的任务,以及教学构建的方式,以及它将彻底改变化学llm的培训的潜力。
3.1原始数据的收集
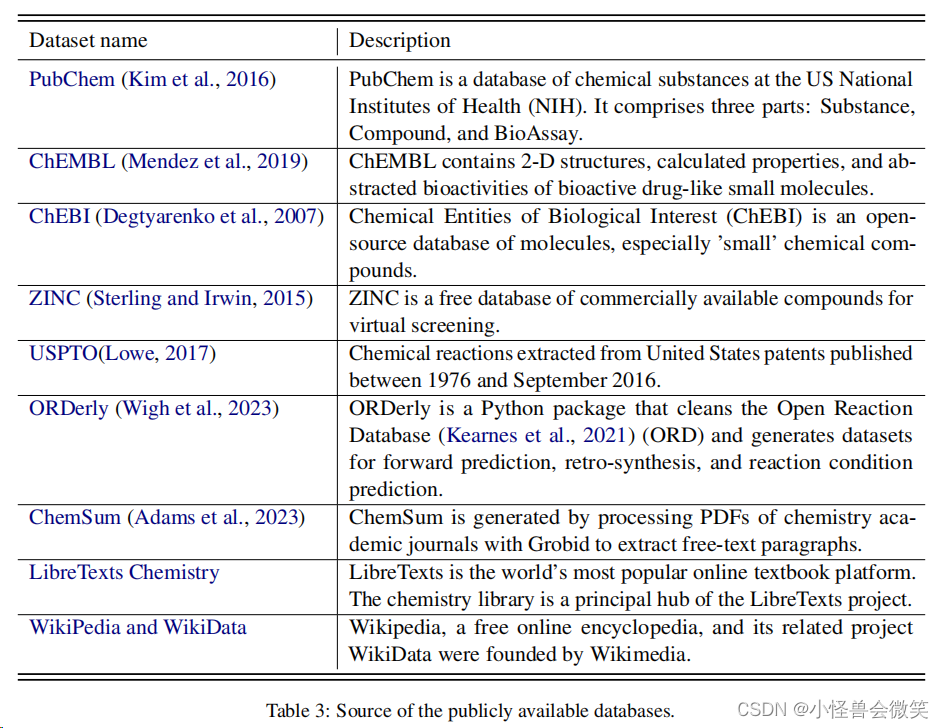
收集了来自大量互联网来源的化学数据。如下图所示,该数据包含了广泛的化学领域知识,与三个主要的任务类别相一致:分子、反应和结构域任务。
3.2指令构建
由于化学语言模型(llm)对分子的独特表示和数据库的性质,其高度结构化的训练提出了重大挑战。为了克服这些障碍,需要一种创新的策略,将这种结构化的、特定于领域的数据转换为一种更有利于LLM训练的格式。我们引入了一种新的管道,将这种形式化的化学数据转换为可访问的自然语言格式,以确保重要的化学信息的保存。我们的方法利用了一个“种子模板”。它实现了一个“戏剧和剧本和剧作家”的策略来创建单回合和多回合的对话场景,显著提高了训练数据集的多样性。虽然这个管道在设计时考虑到了化学数据,但它的基本原理是通用的。它们可以应用于其他科学领域,标志着LLM研究跨越广泛的科学学科的一个新阶段的开始。
将结构化的化学数据转换为适合于训练llm的指令调优数据涉及到解决两个关键挑战:
- 模板的多样性
- 在问答对中包含化学逻辑和推理
对于挑战1 ,通过下面种子模板的方式解决。种子模板的生成和使用方式如下图所示,其中借助GPT4生成大量问答模板(这里都是单轮对话场景数据模板),在模板中把结构化数据进行随机填充,以此得到大量多样性良好的自然语言数据。

在不同任务中,作者的处理细节不同。
在分子任务中,首先,从数据库中提取结构化数据,如“IUPAC name,common name,SMILES”。然后,我们将这些数据字段组织成针对特定任务的问答格式。例如,“IUPAC name”可能是问题,“SMILES”作为答案。这对初始对构成了我们的种子模板的基础。为了加强这一点,我们让ChatGPT来解释最初的问题和答案,生成了40个不同的模板,反映了现实世界和学术文本的多样性。
在反应任务中,在化学反应数据输入领域,关键领域表现出高度的均匀性,包括反应物、产物、产率和反应条件。其中,反应条件数据的特点是其格式不同和存在缺失值。为了解决这个问题,我们设计了一个专门的反应条件模板,以适应缺失的值,便于将这些数据转换为标准化的自然语言描述。随后,我们使用种子模板方法,我们为各种预测目标制作了不同的模板,从而能够构建目标指令。
在领域任务中,在领域任务指令的构建中,我们的方法主要结合了“扮演剧作家”的指导技术,将广泛的领域文献文本和研究主题转化为建设性的、多回合的对话数据,旨在促进实质性的讨论。然后,我们聚合了来自ChemXiv、列表文本化学和维基百科化学门户的特定领域的教科书数据,以为特定领域的多回合对话合成主题。
为了解决第二个挑战,通过构建多回合对话来增强指令调优数据的上下文丰富性和逻辑一致性。
我们坚持综合多回合对话数据的三个指导原则:内容的专业性和准确性,讨论对中心主题的针对性,以及随着领域主题的展开而扩大内容和深化对话的范围。我们的目标是模拟专家之间典型的动态交流和深入讨论,从而细化模型在专门领域问题上进行推理、对话和分析的能力。
4.两阶段指令微调管道
为了提高语言模型在专业领域的熟练程度,采用了一种新颖的两阶段指令调优管道,如下图所示。从一个InternLM2-base-7B开始,在第一阶段使用一些开源的通用数据集进行训练,第二阶段,使用通用+化学领域数据进行训练。

其他训练的重点:
1.LORA,这个工作微调时使用了Lora微调,从以往的经验来看,全量微调>Lora微调。所以,是否是因为训练数据比较大的缘故,lora微调能够更稳定,所以采用了这个。参数如下: a rank of 8, a scale factor of 16.0, and a dropout rate of 0.1。
2.AdamW优化器,初始学习速率为5.0×10−5,β1为0.99,β2为0.999,ϵ为1.0×10−8。
3.16个A100,两个机器,每个上8个gpu,在slurm集群上训练。
4.NEFTune,使用NEFTune加入数据噪声,防止过拟合。
3.损失函数,采用自监督的自回归交叉熵函数,即常规的生成模型损失函数,最大化预测词在真实下一个词上的概率。

5.ChemLLM表现
1.化学方面
使用论文中提出的ChemBench,包括下面三个任务。

2.通用方面
使用多学科MMLU和数学GSM8K。
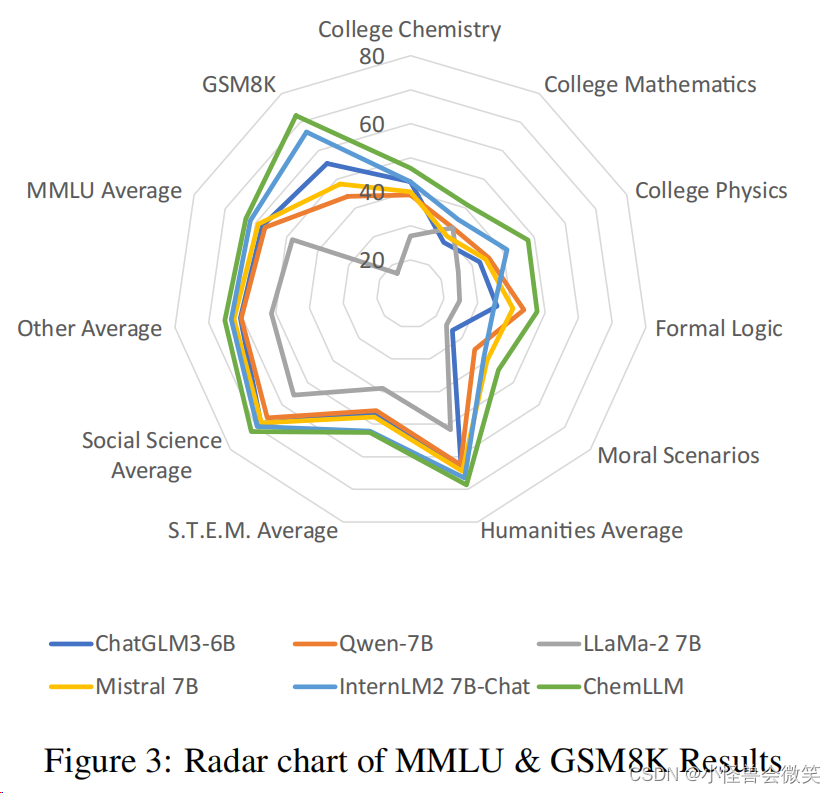
3.中文方面
使用论文中提出的Chinese ChemQA 和Chinese M&H ChemTest数据集。


![[element]element-ui框架下载](https://img-blog.csdnimg.cn/direct/bf91a3c5aa674e9d8933744b64c657f8.png)