目录
引用
常引用
指针与引用的关系
小拓展
引用的价值
做形参
传值、传引用的效率比较
做返回值
函数传值返回
函数传引用返回(错误示范)
野引用(错误示范)
引用的正常应用
值和引用作为返回值类型的性能比较
引用和指针的区别
语法上
底层(汇编)上
引用
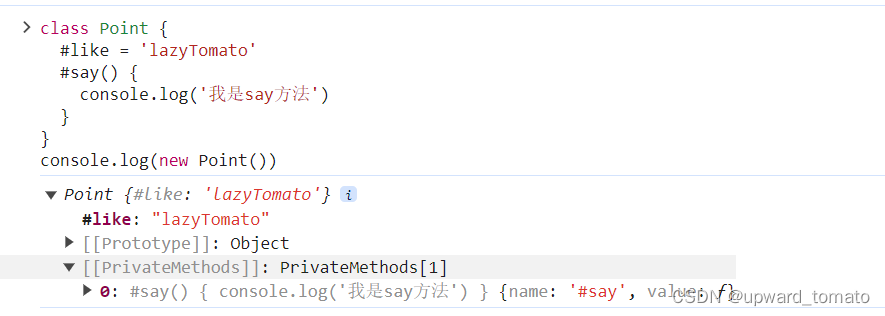
基本概念:引用是给已存在变量取了一个别名
李逵,在家称为“铁牛”,江湖上人称“黑旋风”
特点:和原变量共用同一块内存空间(地址相同,且牵一发而动全身),同一变量可以有多个别名
格式:类型& 引用变量名(对象名) = 引用实体
注意事项:
1、C++中的&依然可以表示取地址运算符和按位与运算符
2、引用类型必须和引用实体是同种类型的
3、当引用实体和它的别名属于不同的域时,别名和引用实体的名字可以相同但是不建议这样做
#include <iostream>
using namespace std;int main()
{int a = 10;int& b = a;cout << &a << endl;cout << &b << endl << endl;a++;b++;cout << a << endl;cout << b << endl << endl;return 0;
}
4、 引用必须在开始就初始化(说明自己是谁的别名)
int a = 0;//wrong
int& b;
b = a; //right
int &b = a;5、引用定义后,不能改变指向(别名与绑定后无法修改,对别名的任何操作就是对实体的操作)
int a = 0;
int& b = a;
int c = 1;
b = c; // 这里不是让b指向c,而是将1赋值给了引用实体a
常引用
定义:使用 const 修饰的引用
特点:被const修饰的引用不能被修改
void printValue(const int& value) {// 这里无法通过value来修改原始值,如果输入value += 10;编译器就会报错cout << "Value: " << value << endl;
}int main() {int num = 10;// 使用常量引⽤来传递numprintValue(num);return 0;
}
指针与引用的关系
基本概念:指针和引用是类似的,指针找到并修改你,别名直接修改你(二者存在依赖关系)
虽然C++的引用可以对使用指针后比较复杂的场景进行一些替换,让代码更简单易懂,但是因
为引用在定义后不能改变指向(删除双向链表的一个结点时, 需要用改变前去指针和后继指针,
用不能做到这一点),而指针可以,所以在C++中引用并不能替代指针:
struct Node
{struct Node* next;struct Node* prev;int val;
};
之前我们在写单链表时,用二级指针pphead接收头指针的地址,而当我们有了引用的概念后,
可以以一种更好理解的方式实现下列单链表的(伪)代码:
#include <stdio.h>
struct Node
{struct Node* next;struct Node* prev;int val;
};//二级指针版本
void PushBack(struct Node** pphead,int x)
{*pphead = newnode;
}//引用版本
void PushBack(struct Node*& phead, int x)//为指针取别名,plist指针的别名是phead
{phead = newnode;
}int main()
{struct Node* plist = NULL;PushBack(plist,0);return 0;
}我们将原来的二级指针pphead换为struct Node*& phead,phead是plist的别名,对phead的操
作就是对plist的操作,这使得代码看起来更加简单。单链表使用二级指针的原因就是为了能够向
头指针中存入新节点的值(不用的话对于值得修改不能被带出尾插函数),这里直接通过引用就实
现了这一目的所以不需要再去考虑传值调用的问题
关于单链表的内容可以查看:单链表的实现(全注释promax版)
小拓展
#include <stdio.h> typedef struct Node
{struct Node* next;struct Node* prev;int val;
}LNode,*PNode;//引用版本
void PushBack(PNode& phead, int x)//为指针取别名,plist指针的别名是phead
{phead = newnode;
}int main()
{PNode plist = NULL;PushBack(plist,0);return 0;
}-
LNode: 是struct Node的别名(当你使用LNode时,就相当于使用了struct Node) -
PNode: 是结构体类型的指针struct Node*的别名
C++百分之八十的场景都在使用引用,剩下的才会用指针
引用的价值
做形参
原来我们在交换两个变量的时候,向Swap函数中传递的是地址,形参是实参的拷贝。实参必
须传递的是地址,否则交换后的结果无法传递回去,有了别名后就不需要传递地址了,形参可以直
接写成实参的别名即可,对于别名的修改就相当于原来的实参的修改:
#include <iostream>
using namespace std;//原版本,传递地址
void Swap(int* left, int* right)
{int tmp;tmp = *left;*left = *right;*right = tmp;
}int main()
{int i = 10;int j = 20;Swap(&i, &j);cout << i << endl;cout << j << endl;return 0;
}//现版本,引用
void Swap(int& left, int& right)
{int tmp = left;left = right;right = tmp;
}int main()
{int i = 10;int j = 20;Swap(i, j);cout << i << endl;cout << j << endl;return 0;
}从语法上来讲,left和right是i和j的拷贝,int& left和int& right是i和j的别名
🤡从底层上来讲,这里先不讲,我不会🤡
传值、传引用的效率比较
#include <stdio.h>
#include <time.h>
#include <iostream>
using namespace std;struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}int main()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;return 0;
}
结论:引用做形参时是输出型参数,且当对象较大时,减少拷贝提高效率
这些效果指针也可以实现,但是没引用方便
输出型参数:传递给函数的参数数据,函数可以使用且能修改这些数据
输入型参数:传递给函数的参数数据,函数可以使用但不能修改这些数据
做返回值
函数传值返回

main函数开辟了一块栈帧,接着又调用了func函数,再开辟一块帧栈,然后func返回a的
值并结束,然后main函数又想接收func函数的返回值a,但是返回值a已经在func函数结束后被销
毁了,a空间中所存放的值已经不再被保证有效,所以此时ret得到是随机值(也有可能是原来的
值,这相当于你鸡蛋碎在大街上了,你记着位置回去找,还能在地上找到蛋黄。如果等久一点,再
回去找,那就不一定能找到啥了),但是在大多数情况下,编译器在栈帧销毁时会将返回值存储在
寄存器中(对象比较小时)或者其他适当位置(除了函数返回值之外,编译器还可以选择使用寄存
器来保存一些重要的局部变量或者临时变量,以减少对内存的读写作),最后寄存器中存放的原来返回值的值会交给ret
在函数结束后硬要把局部变量搞成一个随机值是一件没有意义的事情。只能说函数结束后局部变量的值【不再保证有效】
销毁是需要花点力气的,函数销毁后,原来函数的那一片空间变成空闲区域,随时会再次被使用。大部分情况下,你还能输出,是因为没人用到了那片空闲区域!然而机器也懒得去销毁,重置内存也得费电。
函数传引用返回(错误示范)

func函数的返回值是一个int&类型的引用,即返回值是局部变量a的引用(别名),而当函数
返回该引用时,a的值已经不再保证有效了(随机值或者原值)
结论:函数传值返回的是返回变量的拷贝,函数传引用返回的是返回变量的引用(别名)
野引用(错误示范)

func函数返回的是a的引用(别名),那么ret就是a的引用的引用,而a的那片空间在func函
数销毁时已经不再保证有效了,所以ret就是一个野引用(在程序运行过程中无法保证该内存空间
仍然有效或包含原始值(因为它可能已被其他数据覆盖),因此称之为野引用)
结论:返回变量(局部变量)出了函数作用域就被销毁时,不能用引用返回(薛定谔的🐱)
引用的正常应用
全局变量、静态变量、堆上分配对象等内容可以用引用返回:
- 全局变量:全局变量在程序运行期间始终存在,因此可以安全地通过引用返回
- 静态变量:静态变量也类似于全局常驻内存,在程序整个执行周期中都存在
- 堆上分配对象:如果一个对象是通过
new运算符在堆上动态分配内存创建的,则其生命周期由new和delete控制,并不受限于函数作用域
①int a = 10;
int& func()
{②static int a = 0;return a;
}int main()
{int& ret = func();cout << ret << endl;return 0;
}堆上分配对象的例子我不会🤡
这是C语言(参杂了一点C++)实现顺序表的简化代码:
#include <iostream>
#include <assert.h>
#include <stdio.h>using namespace std;struct SeqList
{int* a;int size;int capacity;
};//初始化
void SLInit(SeqList& sl)//利用引用了
{sl.a = (int*)malloc(sizeof(int) * 4);//... sl.size = 0;sl.capacity = 4;
}void SLPushBack(SeqList& sl, int x)
{//...(扩容)sl.a[sl.size++] = x;
}//修改
void SLModity(SeqList& sl, int pos, int x)
{assert(pos >= 0);assert(pos <= sl.size);sl.a[pos] = x;
}//获取pos位置的值
int SLGet(SeqList& sl, int pos)
{assert(pos >= 0);assert(pos <= sl.size);return sl.a[pos];
}int main()
{SeqList s;//C++将stryct SeqList变为了类,所以可以直接用SeqListSLInit(s);SLPushBack(s, 1);SLPushBack(s, 2);SLPushBack(s, 3);SLPushBack(s, 4);for (int i = 0; i < s.size; i++){cout << SLGet(s,i) << " ";}cout << endl;for (int i = 0; i < s.size; i++){int val = SLGet(s,i);if (val % 2 == 0){SLModity(s, i, val * 2);}}cout << endl;for (int i = 0; i < s.size; i++){cout << SLGet(s, i) << " ";}cout << endl;return 0;
}
这是完全使用C++语法写出的顺序表代码:
#include <iostream>
#include <assert.h>
#include <stdio.h>using namespace std;struct SeqList
{//成员变量int* a;int size;int capacity;//成员函数//C++的结构体(类)除了可以定义变量还可以定义函数void Init()//可以不写前缀{a = (int*)malloc(sizeof(int) * 4);//... size = 0;capacity = 4;}void PushBack(int x){//...(扩容)a[size++] = x;}int& Get(int pos)//加上一个引用就可以代替原来的SLModify和SLGet两个函数的作用{assert(pos >= 0);assert(pos <= size);return a[pos];//由于数组中pos位置的空间是由malloc开辟的,如果不主动释放它就一直都在,所以即使函数销毁,该空间也不会销毁,该空间中的值也会被保留 }
};int main()
{SeqList s;//C++将stryct SeqList变为了类,所以可以直接用SeqLists.Init();s.PushBack(1);s.PushBack(2);s.PushBack(3);s.PushBack(4);for (int i = 0; i < s.size; i++){cout << s.Get(i) << " ";}cout << endl;//将满足条件的数组pos位置的值进行修改for (int i = 0; i < s.size; i++){if (s.Get(i) % 2 == 0){s.Get(i) *= 2;}}cout << endl;for (int i = 0; i < s.size; i++){cout << SLGet(s, i) << " ";}cout << endl;return 0;
}
- C语言:数据与函数分离,想要访问数据就要将数据作为参数传递给函数
- C++:数据和函数不分离,都处于一个类中(实际上也传了编译器做的但是现在没学到)可以直接用(不需要再传一个结构体类型的指针将存储在结构体中的数据传递)
在这段代码中我们不仅仅需要关注的是将原本放在外部的尾插、初始化等函数放在了结构体
中,还需要注意在这里我们用Get一个函数就可以实现原来SLGet和SLModify两个函数的作用(读
写pos位置的数据)这是因为:C++规定临时变量具有常性(特指存储在寄存器中的变量,虽然
pos位置的值除非主动释放否则不会销毁,但是可以将该值拷贝一份放入寄存器中作为函数的返回
值),临时变量默认被const修饰无法修改,如果在试图修改pos位置的值时就会出现不可修改的
左值的报错,但是即使C++没有做出这一规定,我们仍然不能做到对数组pos位置的值进行修改,
因为临时变量只是原来该位置数组的一个拷贝,对拷贝内容的修改无法影响到原来位置的数值,这
两种情况都只能对pos位置的值进行读取而不能进行修改,而当我们加上了一个引用,就可以实现
对pos位置的值的修改,此时Get函数返回的就不是一个临时变量(函数返回引用不会产生临时变
量),而是a[pos]的别名,至于谁的别名作者不知道就不做解释,只需要此时我们既可以读取到
pos位置的值也可以对该值进行修改
完成对数组pos位置的值的修改还有一个前提就是数组pos位置存放值的空间在函数结束后仍然可以保证值得有效,否则就会出现传引用返回(错误示范)中出现得值不保证有效的问题,对于这一点由于数组空间是由mallo开辟的,除非主动销毁否则不会释放,即使函数结束数组pos位置存放值得空间仍然存在,值仍然保证有效,所以可以放心引用该实体对象
值和引用作为返回值类型的性能比较
#include <iostream>
#include <time.h>
using namespace std;struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }int main()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
结论:引用做返回值,可以修改和读取返回对象,减少拷贝(临时变量)提高效率
引用和指针的区别
一个东西在语法上表达得意思和底层实现它得方式是不一样得(鱼香肉丝里没有🐟)
语法上
①、引用是别名,不开空间,指针是地址,需要开空间存地址
int main()
{int a = 10;int& ra = a;//引用语法上不开空间ra = 20;int* pa = &a;//指针语法上开空间*pa = 20;return 0;
}②、引用必须初始化,指针可以初始胡也可以不初始化(所以指针更容易出现野的情况)
③、引用不可以改变指向,指针可以改变指向
④、引用相对安全,没有空引用,但是有空指针,容易出现野指针,但是不容易出现野引用
⑤、在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数
⑥、引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
⑦、有多级指针,但是没有多级引用
⑧、访问实体方式不同,指针需要显式解引用,引用编译器自己处理
⑨、引用比指针使用起来相对更安全
底层(汇编)上
对于①中的引用,在底层(汇编)上的情况是这样的:

“003F2026 lea eax,[a]”:取a的地址放在eax寄存器,故引用在底层层面需要开空间
结论:
- 引用底层是用指针实现的
- 语法含义和底层实现是背离的(鱼香肉丝没有🐟)
汇编层面上,没有引用,都是指针,引用编译后也转换成指针了
~over~