一、简介
Doris(原百度Palo)是一款基于大规模并行处理技术的分布式SQL数据库。基于MPP的交互式SQL数据库,可以用于OLAP。MPP是将任务并行的分散到多个服务器和节点上,在每个节点上结算完后,将各个部分的结果汇总在一起得到最终的结果。
1.1Doris的定位
- MPP架构的关系型分析数据库;
- PB级别大数据集,秒级/毫秒级响应查询;
- 主要用于多维分析和报表查询;
1.2 产品
-
StarRocks
-
StarRocks | StarRocksStarRocks 是一款高性能分析型数据仓库,使用向量化、MPP 架构、CBO、智能物化视图、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时 StarRocks 具备水平扩展,高可用、高可靠、易运维等特性。广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。
 https://docs.mirrorship.cn/zh/docs/introduction/StarRocks_intro/
https://docs.mirrorship.cn/zh/docs/introduction/StarRocks_intro/ - SelectDB :
-
SelectDB Cloud 介绍 | SelectDB
https://docs.selectdb.com/docs/cloud/overview - SelectDB Enterprise 介绍 | SelectDBhttps://docs.selectdb.com/docs/enterprise/selectdb-enterprise-overview
产品定位
-
性能卓越:TPC-H/TPC-DS性能领先,性价比高,高并发查询,100台集群可达10W QPS,流式导入单点50MB/s,小批量导入毫秒延迟
-
简单易用:高度兼容Mysql协议;支持在线表结构变更、高度集中,不依赖于外部存储系统,通过了权威第三方产品能力测评验证;
-
扩展性强:架构优雅,单集群可水平扩展200台以上
-
高可用性:多副本,元数据高可用
1.3 Doris的整体架构
Doris主要整合了Google Mesa(数据模型)、Apache Impala(MPP Query Engine)和ORCFile(存储格式,编码和压缩)的技术。
- Mesa可以满足我们许多存储需求,但是Mesa本身不提供SQL查询引擎
- Impala是一个非常好的MPP SQL查询引擎,但是缺少完美的分布式存储引擎
- 自研列式存储:存储层对存储数据的管理通过stotage_root_path路径进行配置,路径可以是多个。存储目录下一层按照分桶进行组织,分桶目录存放具体的tablet。
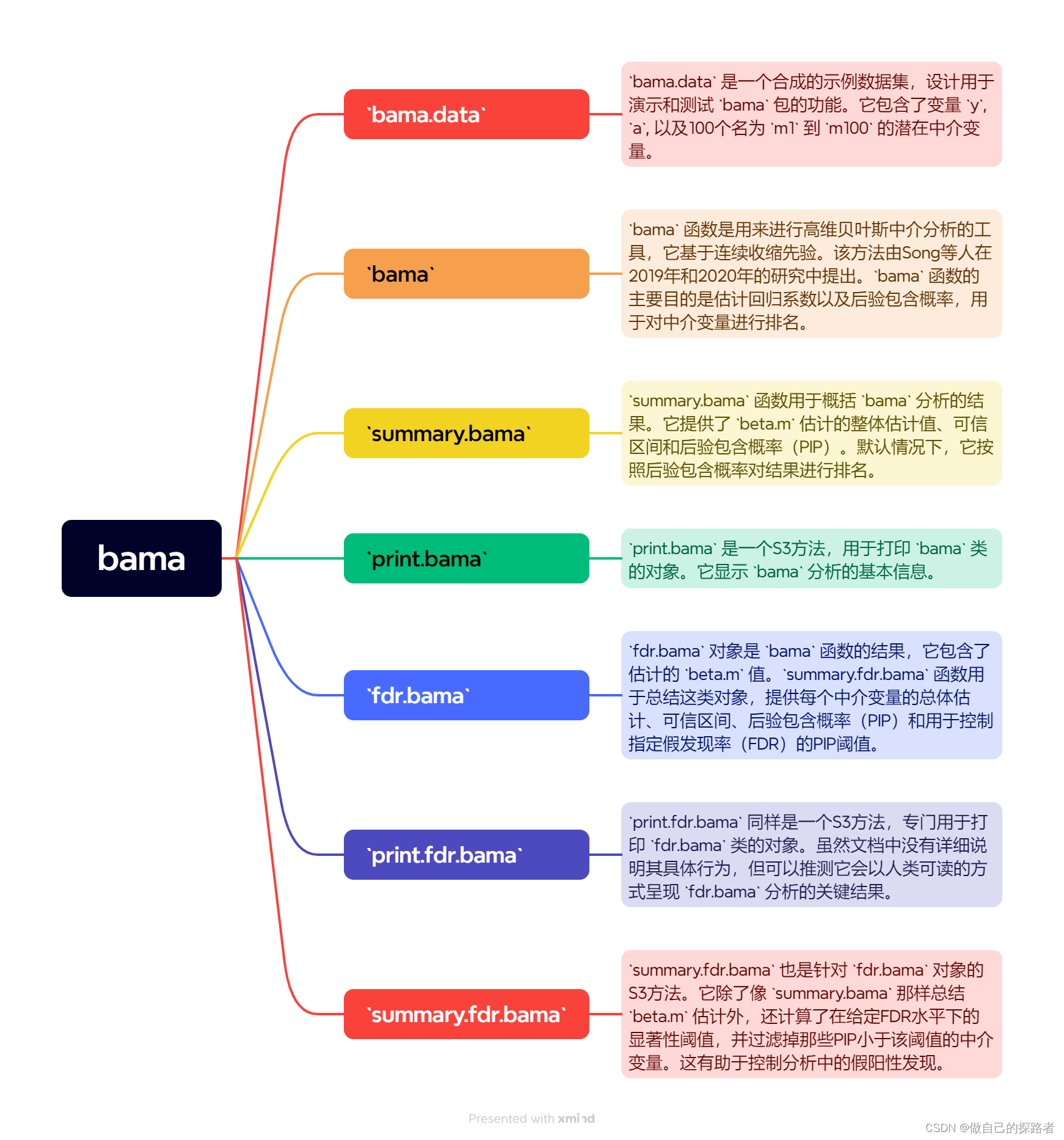
Doris的架构只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运营。
- 数据存储:FE存储、维护集群的元数据;BE存储物理数据;
- 查询处理:FE节点接收、解析查询请求,规划查询计划,调度查询计划,返回查询结果;BE节点依据FE生成物理计划,分布式执行查询。
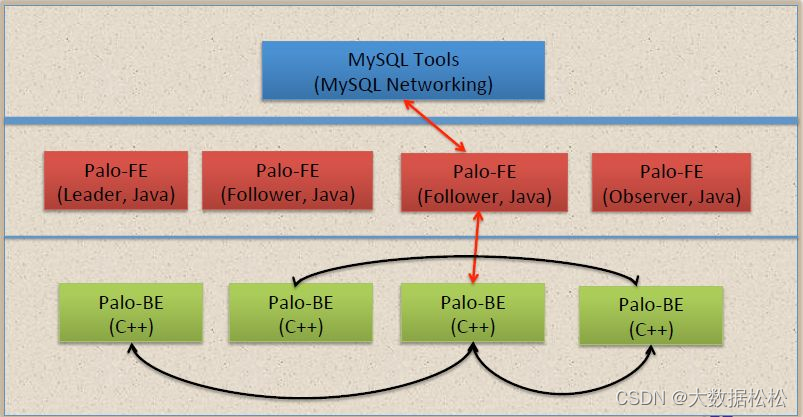
Doris的数据分布
1.4 Doris技术特点
-
数据可靠性:
-
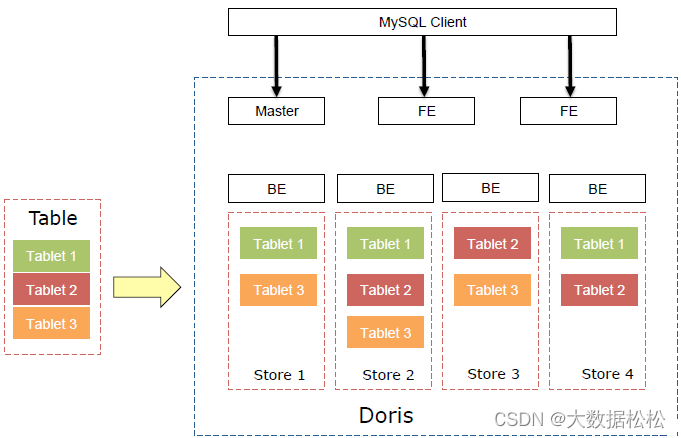
元数据使用Memory+CheckPoint+Journal,使用BTBJE协议实现高可用和高可靠性
-
Doris内部自行管理数据的多副本和自动修复。保证数据的高可用、高可靠。再服务器宕机的情况下,服务依然可用,数据也不会丢失。
-
-
容易运营:
-
没有外部依赖:Doris部署无外部依赖,只需要部署BE和FE即可搭建起一个集群;支持Online Schema Change;支持在线更改表模式(加减列,创建rollUp),不会影响当前服务,不会堵塞读、写操作;执行是异步的
-
数据同步操作和异步操作:
-
同步:是所有的操作都完成,才返回给用户结果;即写完数据库之后,再响应用户,用户体验不好;
-
异步:不用等所有的操作做完,就响应用户请求;即先响应用户请求,然后再慢慢的写数据库,用户体验好。缓存机制(也就是消息队列),就是异步操作的一个典型应用。
-
副本自动均衡
-
内置监控
-
-
-
-
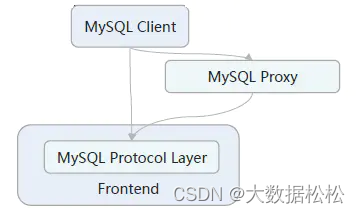
MySql兼容:兼容Mysql的网络协议;兼容Mysql的语法
-
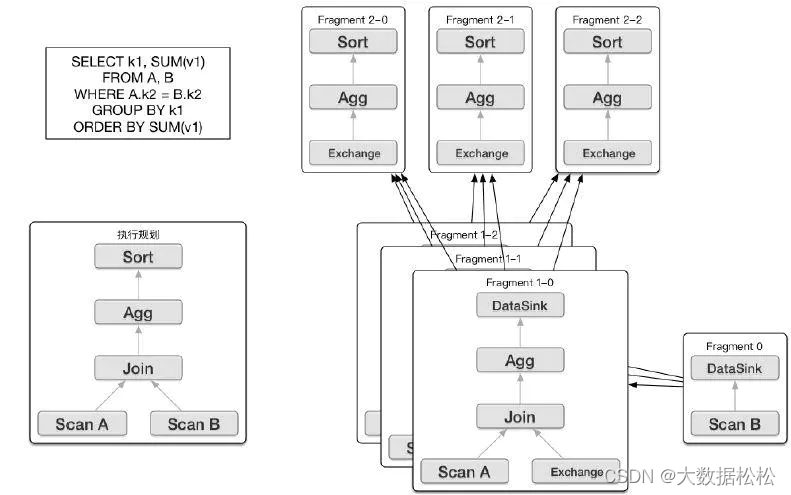
支持MPP:即支持Massively Parallel Processing,大规模并行处理,即海量数据并发查询。
SELECT k1,SUM(v1) FROM A,B WHERE A.k2=B.k2 GROUP BY k1 ORDER BY SUM(v1)该语句包含了合并、聚合计算、排序等多种操作;在执行计划的时候,MPP将其拆解成多份,分布到每台机器上执行,最后再将结果汇总。假设有10台机器,在大数据量下,这种查询执行方式可以使得查询性能达到10倍的提升。
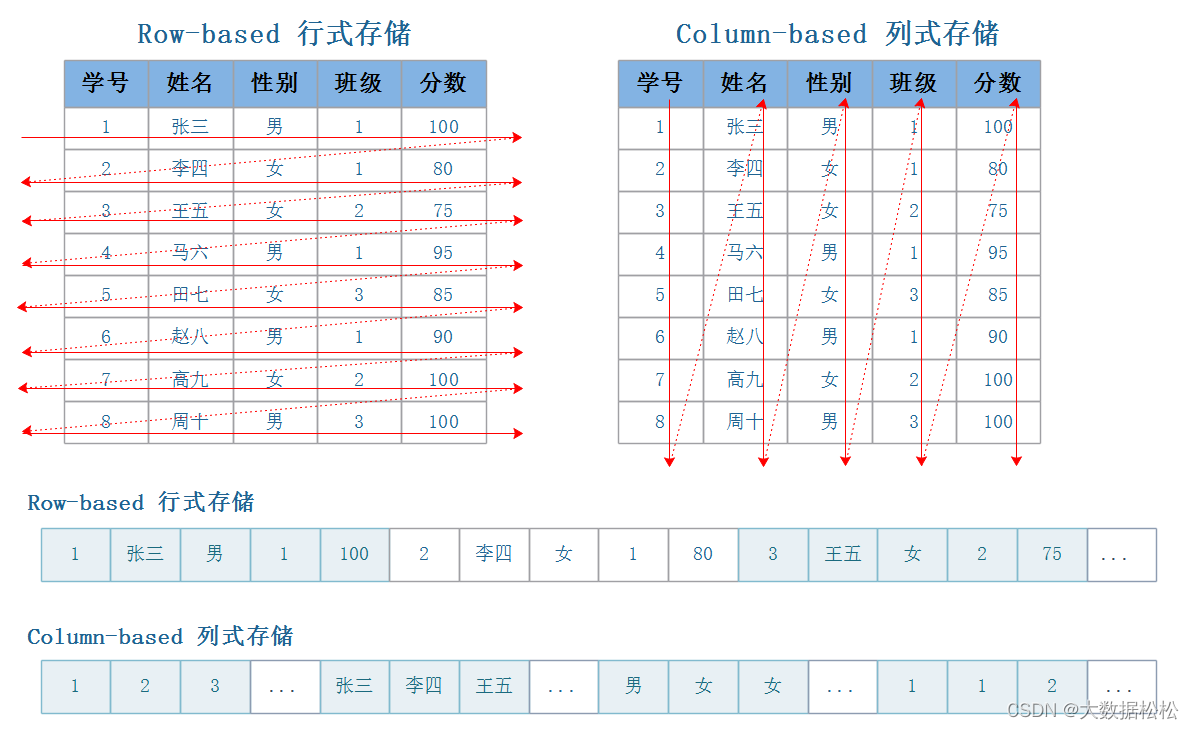
- 列式存储引擎:
- 列式存储在数据写入和修改上具有优势
- 列式存储在数据读取和解析、分析数据上具有优势
- 支持向量化查询引擎:Doris查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅度减少虚函数的调用、提升Cache命中率,高效利用SIMD指令的效果。在宽表聚合场景下新跟那个是非向量化引擎的5-10倍。
- 动态调整执行计划:Doris采用了Adaptive Query Execution技术,可以根据Runtime Statistics来动态调整执行计划,比如通过Runtime Filter技术能够在运行时生成Filter推到Probe侧,并且能够将Filter自动穿透到Probe侧最底层的Scan节点,从而大幅度减少Probe的数据量,加速Join性能。Doris的Runtime Filter支持in/Min/Max/Bloom Filter。
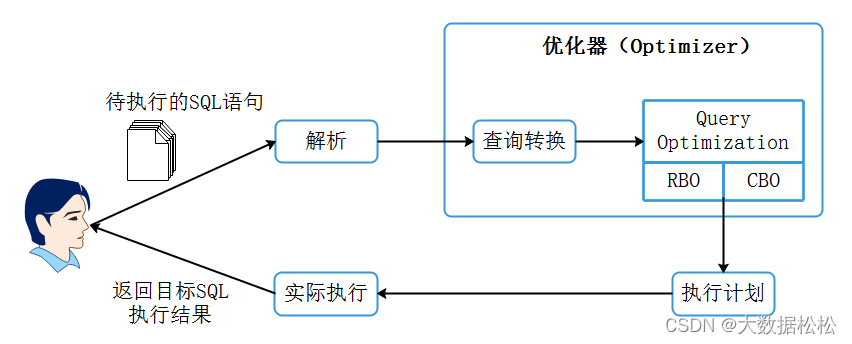
- 采用CBO和RBO查询优化器 :查询优化器主要解决的是多个连接操作的复杂查询优化,负责生成、制定SQL的执行计划,目前主要有2中查询优化器:基于规则的优化器(RBO)与基于代价的优化器(CBO),下面大约解释一下RBO与CBO优化器的原理:
- RBO:Rule-Based-Optimization。即基于规则的优化器,该优化器按照硬编码在数据库中的一系列规则来决定SQL的执行计划,只要求我们按照这套规则来写SQL语句,无论表中的数据分布和数据量如何都不会影响这套规则下的执行计划。
- CBO:Cost-Based-Optimization。即基于代价优化器,该优化器通过根据优化规则对关系表达式进行转换,按照表、索引、列等信息生成多个执行计划,然后CBO会通过根据统计信息(Statistics)和代价模型(Cost Model)计算各种可能”执行计划“的”代价”,即COST,从中选用Cost最低的执行方案。主要包括:SQL执行路径的IO、网络开销、CPU使用情况等。
二、Doris的数据模型
2.1 aggregate聚合模型
Aggregate模型可以通过预聚合,极大的降低聚合查询时所需要扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对count(*)查询很不友好。同时因为固定了value列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
维度列key:没设置aggregationtype
指标列value:设置了aggregationtype
当我们导入数据的时候,对于key列相同的行会聚合成一行,而value列会按照设置的aggregationtype进行聚合。aggregationtype目前的四种聚合方式:
- Sum:求和,多列的value值进行累加;
- Max:保留最大值
- Min:保留最小值
- Replace:替代,下一批数据中的value会替代之前导入过的行中的value。在同一批次中的数据,对于replace这种聚合方式,替换顺序不做保证。
优点:我们会按照维度列区聚合数据,如果维度列数据相同我们会把这些数据合并(compaction)起来。也就是相当于在数据库里面存储的其实是一个合并之后的结果,这个结果对于统计分析来说是很有效果的。因为广告报表只关心这种统计之后的数据,现在我们把大量的数据聚合,比如一天的数据可能有一千条,我们聚合成一条,相当于整个IO节省了一千倍,效果非常明显。
缺点:有些业务场景分析的时候,是需要明细数据的,它不太关心统计的结果,而是更关心流程分析,更关心的是我要拿着历史的全量数据跟现在的数据做对比。
2.2 unique key模型
我们提供一个唯一Key模型,在整个历史数据导入的时候,我们保证key的唯一,不聚合。
Unique Key的模型主要面向留存分析或者订单分析的场景,他们需要一个Unique Key的约束去保证整个数据不丢不重。
Uniq模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用RollUp等预聚合带来的查询优势(因为本质是replace,没有sum这种聚合方式,rollup只是用来调准列顺序命中前缀索引)
2.3 duplicate key模型
数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也会保留。而在建表语句中制定的Duplicate key,只是用来指明底层数据按照那些列进行排序。
数据可能重复,对于有些日志分析它不太在意数据多几条或者少几条,可能只关心排序,这个时候可能重复key的模型会更加有效果。这种数据模型适用于既没有聚合需求,有没有主键唯一性约束的原始数据的存储。
Duplicate模型适用任意维度的ad-hoc查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有key列)