Paper Card
论文标题:RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation
论文作者:Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Zackory Erickson, David Held, Chuang Gan
作者单位:CMU, Tsinghua IIIS, MIT CSAIL, UMass Amherst, MIT-IBM AI Lab
论文原文:https://arxiv.org/abs/2311.01455
论文出处:–
论文被引:5(02/24/2024)
项目主页:https://robogen-ai.github.io/
论文代码:https://github.com/Genesis-Embodied-AI/RoboGen, 412 star
研究问题:通过自动化数据生成和技能学习管线,赋予机器人各种技能,使其能够在各种非工厂环境中操作,并为人类执行广泛的任务。
面临挑战:
- 由于真实世界数据收集昂贵和费力,这些技能中的许多都是在仿真中通过适当的领域随机化进行训练的,然后部署到真实世界中。
- 虽然仿真环境中的探索和实践具有成本效益,但构建这些环境需要大量的劳动努力,需要大量的繁琐的步骤,包括设计任务、选择相关和语义上有意义的资产、生成合理的场景布局和配置,以及制作训练监督,如奖励或损失函数。
主要贡献:
- 提出了生成仿真(Generative Simulation),结合了仿真机器人技能学习的进步以及基础模型和生成模型的最新进展。
- RoboGen生成的任务和技能的多样性超过了以前由人类创建的机器人技能学习数据集,除了几个提示设计和上下文示例之外,只需要最少的人类参与。
方法概述:
- RoboGen 是一个自动化管道,它利用最新基础模型的嵌入常识和生成能力进行自动任务、场景和训练监督生成,实现大规模机器人技能学习的多样化。整个管道由几个阶段组成:任务提议、场景生成、训练监督生成和技能学习。
主要结论:
- 与之前的所有基准相比,RoboGen 实现了最低的 Self-BLEU 和嵌入相似性,这表明生成的任务的多样性高于这两个指标下先前手动建立的基准。
- 在 RoboGen 中使用物体和大小验证提高了物体选择的有效性。
- 自动生成的训练监督在推导有意义和有用的技能方面是有效的。
- 允许选择学习算法有利于实现更高性能来完成任务。
总结:
- 对学习技能的大规模验证(即生成的技能是否真的通过文本描述解决相应的任务)仍然是当前管道中的挑战。
- 目前基于仿真环境生成场景,受到 sim-to-real 差距的限制。
- 强假设性质,策略学习算法仍然不够健壮,并且通常需要多次运行才能为某些生成任务产生成功的技能演示。
- 可以使用Self-BLEU 和嵌入相似性从文本角度评估生成数据的多样性。
ABSTRACT
我们介绍了 RoboGen,一种生成式机器人Agent,通过生成仿真(generative simulation)在规模上自动学习各种机器人技能(robotic skills)。RoboGen利用了基础模型和生成模型的最新进展。我们主张使用生成方案,而不是直接使用或调整这些模型来产生策略或低层次的行动,该方案使用这些模型自动生成多样化的任务、场景和训练监督,从而在最少的人工监督下扩大机器人技能学习。我们的方法为机器人Agent提供了一个自我引导的建议-生成-学习(propose-generate-learn)循环:Agent 首先提出要开发的有趣任务和技能,然后通过用适当的空间配置填充相关物体和资产来生成相应的仿真环境。然后,agent将所提出的高级任务分解为子任务,选择最优学习方法(强化学习、运动规划或轨迹优化),生成所需的训练监督,然后学习策略以获得所提出的技能。我们的工作试图提取嵌入大规模模型中的广泛而通用的知识,并将其迁移到机器人领域。我们完全生成的管道可以重复查询,产生与不同任务和环境相关的源源不断的技能演示。
1 INTRODUCTION
这项工作的动机是机器人研究中一个长期且具有挑战性的目标:赋予机器人各种技能,使其能够在各种非工厂环境中操作,并为人类执行广泛的任务。近年来,在教授机器人各种复杂技能方面取得了令人印象深刻的进展:从可变形物体和流体操纵(deformable object and fluid manipulation),到动态和灵巧的技能(dynamic and dexterous skills),如投掷物体(object tossing)、手部重新定向(in-hand re-orientation),足球比赛(soccer playing),甚至机器人跑酷(robot parkour)。然而,这些技能仍然是分隔开的,视野相对较短,需要人工设计的任务描述和训练监督。值得注意的是,由于真实世界数据收集昂贵和费力,这些技能中的许多都是在仿真中通过适当的领域随机化进行训练的,然后部署到真实世界中。
事实上,仿真环境已经成为多样化机器人技能学习背后的关键驱动力。与现实世界中的探索和数据收集相比,仿真中的技能学习提供了几个优势:
- 1)仿真环境提供了低层次状态的访问和无限的探索机会;
- 2)仿真支持大规模并行计算,无需对机器人硬件和人力进行大量投资,就可以实现更快的数据收集;
- 3)仿真中的探索允许机器人开发闭环策略和错误恢复能力,而现实世界的演示通常只提供专家轨迹。
然而,仿真中的机器人学习也有其的局限性:虽然仿真环境中的探索和实践具有成本效益,但构建这些环境需要大量的劳动努力,需要大量的繁琐的步骤,包括设计任务、选择相关和语义上有意义的资产、生成合理的场景布局和配置,以及制作训练监督,如奖励或损失函数。创建这些组件并构建我们日常生活中遇到的无数任务中的每一个个性化仿真设置是一项压倒性的挑战,它也限制了机器人技能学习的可扩展性。
鉴于此,我们提出了一种称为生成仿真(Generative Simulation)的范式,它结合了仿真机器人技能学习的进步以及基础模型和生成模型的最新进展。利用最先进的基础模型的生成能力,生成仿真旨在为仿真中不同机器人技能学习所需的所有阶段生成信息:从高级任务和技能建议到与任务相关的场景描述、资产选择和生成、策略学习选择和训练监督。由于在最新基础模型中编码的综合知识,以这种方式生成的场景和任务数据有可能与现实世界场景的分布非常相似。此外,这些模型可以进一步提供分解的低层次子任务,这可以通过特定领域的策略学习方法无缝处理,从而为各种技能和场景生成闭环演示。
我们提出的范式的一个明显优势在于从当代基础模型中提取什么样的知识模式的战略设计。这些模型已经在各种模态中展示了令人印象深刻的能力,产生了能够使用一系列工具并解决虚拟领域中各种任务的自主Agent。然而,由于缺乏与 dynamics,actuations 和 physical interactions 有关的训练数据,这些模型还没有完全理解机器人有效执行物理动作和与周围环境交互的必要条件——从识别稳定运动所需的精确关节力矩,涉及诸如擀面团之类的灵巧操作任务所需的高频手指运动命令。与最近使用这些基础模型(如 LLM)直接生成策略或低层次操作的努力形成对比,我们提倡一种方案,该方案可以提取完全属于这些模型的能力和模态范围内的信息——object semantics,object affordances,识别有价值的学习任务的常识知识等。我们使用这些知识来构建环境 playgrounds,然后求助于基于物理的仿真的额外帮助,让机器人发展对物理交互的理解并获得不同的技能。
我们在最近的一篇白皮书中首次描述了这种范式,该白皮书概述了为通才手机器人学习生成不同数据的一条有前途的途径。在本文中,我们介绍了RoboGen,这是对这一范式的全面实现。RoboGen是一种生成型机器人Agent,它自行提出要学习的技能,在仿真中生成场景组件和配置,用自然语言描述标记任务,并为后续的技能学习设计适当的训练监督。我们的实验表明,RoboGen可以提供源源不断的多样化技能演示,涵盖刚性和关节式物体操纵、可变形物体操纵以及腿部运动技能等任务(见图1)。RoboGen生成的任务和技能的多样性超过了以前由人类创建的机器人技能学习数据集,除了几个提示设计和上下文示例之外,只需要最少的人类参与。我们的工作试图提取嵌入大模型中的广泛而通用的知识,并将其迁移到机器人领域。当被无休止地询问时,我们的系统有可能为机器人学习释放无限量的多样化演示数据,为可推广的机器人系统的全自动化大规模机器人技能训练迈出了一步。

2 RELATED WORK
Robotic skill learning in simulations
过去已经开发了各种基于物理的仿真平台,以加速机器人研究。其中包括刚体仿真器,可变形物体仿真器,以及支持多种材料的环境及其与机器人的耦合。这种仿真平台在机器人界被广泛用于学习各种技能,包括table-top manipulation,deformable object manipulation,object cutting,fluid manipulation,以及高度动态和复杂的技能,如 in-hand re-orientation,object tossing,acrobatic flight,locomotion for legged robots and soft robots。
Scaling up simulation environments
除了构建物理引擎和仿真器外,大量先前的工作旨在构建大规模仿真基准,为可扩展的技能学习和标准化基准提供平台。值得注意的是,这些先前的仿真基准或技能学习环境中的大多数都是用人工标记手动构建的。另一系列工作试图使用程序生成来扩大任务和环境的规模,并使用任务和运动规划(TAMP)生成演示。这些方法主要建立在手动定义的规则和规划域之上,将生成的环境和技能的多样性限制在相对简单的拾取和放置以及物体堆叠任务上。与这些工作相反,我们提取了嵌入LLM等基础模型中的常识性知识,并将其用于生成有意义的任务、相关场景和技能训练监督,从而获得更多样、更合理的技能。
Foundation and generative models for robotics
随着图像、语言和其他模态领域基础和生成模型的快速发展,一项活跃的工作是研究如何通过 code generation,data augmentation,visual imagination for skill execution,sub-task planning,concept generalization of learned skills,outputting low-level control actions,goal specification 等方法将这些大规模模型用于机器人研究。与我们更相关是使用 LLM 进行奖励生成的方法,子任务和轨迹生成。与它们相比,我们提出的系统旨在实现全自动管道,该管道自我提出新任务、生成环境并产生不同的技能。
Generative Simulation
我们首先在最近的白皮书(Xian et al., 2023a)中提出了生成仿真的想法。我们使用图像生成模型和 LLM 为 Franka 臂生成资产,任务描述和分解,实现了 (Katara et al., 2023) 中生成仿真概念的证明。在本文中,我们扩展了这一研究方向,以支持更广泛的机器人类型和更多样化的具有照片级真实感视觉的任务集,由更高级的渲染和物理引擎提供支持。
3 ROBOGEN
RoboGen 是一个自动化管道,它利用最新基础模型的嵌入常识和生成能力进行自动任务、场景和训练监督生成,实现大规模机器人技能学习的多样化。我们在图 2 中说明了整个管道,由几个阶段组成:任务提议、场景生成、训练监督生成和技能学习。
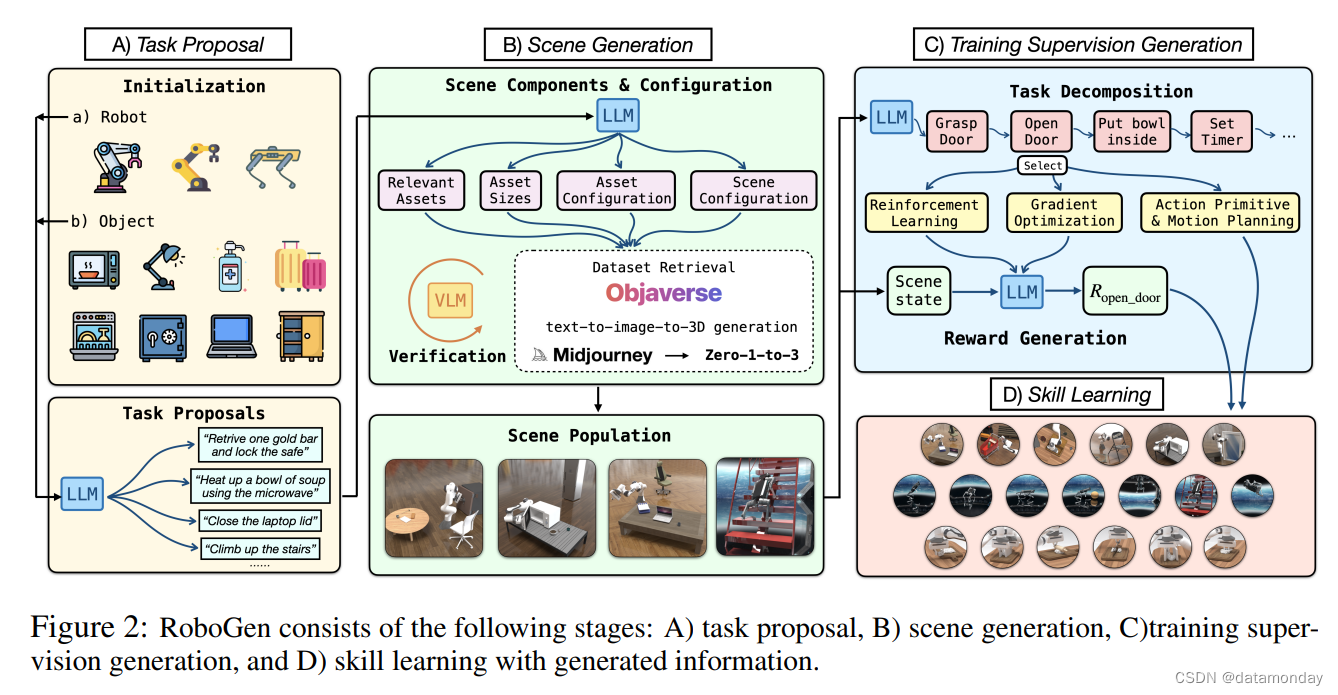
3.1 TASK PROPOSAL
RoboGen 从为机器人学习生成有意义、多样化和高级任务开始。我们没有直接查询LLM进行任务建议,而是使用特定的机器人类型和从池中随机采样的物体来初始化系统。然后将提供的机器人和采样的物体信息用作LLM的输入来执行任务建议。这样的采样过程确保了生成任务的多样性:例如,四足机器人等腿机器人能够获得各种运动技能,而机械臂机械手在与不同采样物体配对时有可能执行各种操作任务。该初始化步骤用作种子阶段,提供了一个基础,即 LLM 可以根据该阶段进行条件和推断以生成各种任务,同时考虑机器人和物体affordances。除了基于物体的初始化之外,另一种选择是使用基于实例的初始化,我们使用提供的机器人初始化查询,以及从列出的 11 个预定义任务中采样的几个示例任务。
我们使用 GPT-4 作为 LLM 在当前管道中查询,但是一旦可用更好的模型,这个后端就可以升级。在下文中,我们使用基于物体的初始化来解释机械臂(例如 Franka)和与物体操作相关的任务(例如 Franka)上下文中 RoboGen 的细节。在这种情况下,用于初始化的物体是从预定义的列表中采样的,其中包括从 PartNetMobility (Xiang et al., 2020) 和 RLBench (James et al., 2020) 等家庭场景中的常见铰接和非铰接物体。在广泛的互联网规模数据集上进行训练后,GPT-4 等 LLM 对这些物体的 affordances,如何与之交互的知识以及它们可以与之关联的有意义的任务的丰富理解。为了生成涉及机器人对采样铰接物体的交互和操作的任务,我们构建了一个查询,其中包含关节物体所属的广泛类别、源自 URDF 文件的关节树以及提供物体链接注释的语义文件,例如,哪个链接对应于采样微波中的门。此信息由 PartNetMobility 数据集提供。铰接物体的类别告知可以使用此类物体执行哪些通用类型的任务,关节树和语义文件通知 GPT-4 物体可以铰接的确切程度以及每个关节和链接的语义。查询要求 GPT-4 返回可以使用采样物体执行的许多任务,其中每个任务由任务名称、任务的简短描述组成,如果除了提供的关节物体之外,任务还需要有任何其他物体,以及机器人需要与之交互的关节/链接来完成任务。此外,我们在 GPT-4 的查询中包含示例输入输出对来执行上下文学习以提高其响应的质量。
作为具体的例子,给定一个采样的铰接物体是一个 microwave,其中关节 0 是一个连接其门的转动关节,关节 1 是另一个控制计时器旋钮的旋转关节,GPT-4 将返回一个名为 heat up a bowl of soup 的任务,任务描述 The robot arm places a bowl of soup inside the microwave, closes the door and sets the microwave timer for an appropriate heating duration,生成任务所需的附加物体,如 A bowl of soup 和与任务相关的关节和链接,包括关节 0 (打开微波门)、关节 1 (设置计时器)、链接 0 (门) 和链接 1 (计时器旋钮)。有关详细的提示和示例响应,请参阅附录 B。请注意,对于我们对非铰接物体进行采样或使用基于实例的初始化的情况,采样物体和示例仅作为任务建议的提示提供,并且生成的任务不会与它们相关联。对于铰接物体,由于PartNetMobility是唯一高质量的铰接物体数据集,并且已经涵盖了不同的铰接资产范围,我们将生成依赖于采样资产的任务。对于运动和软体操作任务,我们仅使用基于实例的初始化,并采用 GPT-4 填充额外的所需物体。通过反复查询不同的采样物体和示例,我们可以生成一系列不同的操作和运动任务,涉及在需要时的相关物体 affordances。
3.2 SCENE GENERATION
给定一个提议的任务,我们继续生成相应的仿真场景来学习技能来完成任务。如图 2 所示,场景组件和配置是根据任务描述生成的,然后检索或生成物体资产以随后填充仿真场景。具体来说,场景组件和配置由以下元素组成:对要填充到场景中的相关资产的查询、它们的物理参数,例如大小、配置,例如初始关节角度和资产的整体空间配置。
Obtaining queries for relevant assets
除了任务提议上一步生成的任务所需的必要物体资产外,为了增加生成场景的复杂性和多样性,同时类似于真实场景的物体分布,我们查询 GPT-4 为与任务语义相关的物体返回一些额外的查询。有关 GPT-4 为任务返回的附加物体的示例,请参见图 1,例如,对于任务“打开储物柜、将玩具放在里面,关闭它”,生成的场景还包括客厅垫、桌面灯、书籍和办公室椅子。
Retrieving or generating assets
生成的相关物体查询(即它们的语言描述)将用于搜索现有数据库 Objverse(Deitke et al., 2023),或者用作文本到图像的输入(Midjourney, 2022),然后图像到 3d 的网格生成模型以生成资产的 3d 纹理网格。具体来说,我们使用 Objverse,这是一个包含超过 800k 个物体资产(3d 网格、纹理图片等)的大规模数据集作为检索的主要数据库。对于 Objverse 中的每个物体,我们通过结合默认注释和来自 (Luo et al., 2023) 的更清理的注释版本来获得它的语言描述列表。鉴于我们想要检索的资产的语言描述,我们使用 Sentence-Bert (Reimers & Gurevych, 2019) 来获取描述的嵌入,并从 Objverse 中检索 k 个物体,其语言嵌入与目标资产的语言嵌入最相似。由于物体注释中的噪声,即使语言嵌入空间中的相似度得分很高,实际资产和预期目标之间也可能存在显着差异。为了解决这个问题,我们进一步利用视觉语言模型 (VLM) 来验证检索到的资产并过滤掉不希望的资产。具体来说,我们将检索到的物体的图像输入到 VLM 模型中,并要求 VLM 对其进行描述。该描述连同对所需资产的描述和任务的描述一起被馈送到 GPT-4 中,以验证检索到的资产是否适合用于提议的任务。由于 Objverse 的多样化资产范围对于现有的预训练模型来说本质上具有挑战性,为了提高我们系统的鲁棒性,我们使用 Bard (Google, 2022) 和 BLIP-2 (Li et al., 2023b) 来交叉验证检索到的资产的有效性,并且仅当它们的描述都被认为适合 GPT-4 的任务时采用资产。我们在管道中使用 k = 10,如果所有资产都被拒绝,我们求助于文本到图像,然后是图像到网格生成模型来从语言描述中生成所需的资产。我们使用 Midjourney (Midjourney, 2022) 作为我们的文本到图像生成模型,使用 Zero-1 到 3 (Liu et al., 2023b) 作为我们的图像到图像生成模型。对于软体操作任务,为了获得操作下软体更一致的可控目标形状,我们要求GPT-4提出所需的目标形状,只使用这种文本到图像到网格的管道,而不是数据库检索。
Asset size
Objverse (DeiTke et al., 2022) 或 PartNetMobility (Xiang et al., 2020) 的资产通常不是物理上合理的大小。为了解决这个问题,我们查询 GPT-4 以生成资产的大小,以便:1)大小应该匹配现实世界的物体大小; 2)物体之间的相对大小允许合理的解决方案来解决任务,例如,对于“把书放入抽屉”的任务,抽屉的大小应该大于这本书。
Initial asset configuration
对于某些任务,关节物体应该用机器人的有效状态初始化以学习技能。例如,对于“关闭窗户”的任务,窗户应该在开放状态下初始化;类似地,对于打开门的任务,门应该最初关闭。同样,我们查询 GPT-4 来设置这些铰接物体的初始配置,以关节角度指定。为了允许 GPT-4 推理任务和铰接物体,查询脚本包含关节物体的任务描述、关节树和语义描述。
Scene configuration
指定场景中每个资产的位置和相关姿势的场景配置对于产生合理的环境并允许有效的技能学习至关重要。例如,对于“retrieving a document from the safe”的任务,文档需要在安全范围内初始化;对于“removing the knife from the chopping board”的任务,刀需要最初放在砧板上。RoboGen 查询 GPT-4 以生成与任务描述这样的特殊空间关系作为输入,并且还指示 GPT-4 以无碰撞的方式放置物体。
使用生成的场景组件和配置,我们相应地填充场景。有关 RoboGen 生成的示例场景和任务的集合,请参见图 1。
3.3 TRAINING SUPERVISION GENERATION
为了获得解决提出任务的技能,需要对技能学习进行监督。为了促进学习过程,RoboGen 首先查询 GPT-4 以计划和分解生成的任务,这些任务可以是长视距的,较短的子任务。我们的主要假设是,当任务分解为足够短的子任务时,每个子任务都可以通过现有算法可靠地解决,例如强化学习、运动规划 或轨迹预测。
在分解后,RoboGen 然后查询 GPT-4 以选择一个合适的算法来解决每个子任务。将三种不同类型的学习算法集成到RoboGen中:强化学习、进化策略、基于梯度的轨迹优化和运动规划的动作基元。这些任务中的每一个都适用于不同的任务,例如,
- 基于梯度的轨迹优化更适合学习涉及软体的细粒度操作任务,例如将粗略塑造到目标形状;
- 动作基元与运动规划相结合对于解决任务更可靠,例如通过无碰撞路径接近目标物体;
- 强化学习和进化策略更适合接触丰富且涉及与其他场景组件的连续交互的任务,例如腿部运动,或者当所需的动作不能简单地由离散的末端执行器姿势参数化时,例如转动烤箱的旋钮。
我们提供示例并让 GPT-4 在线选择哪种学习算法以生成的子任务为条件使用。我们考虑动作基元,包括抓取、接近和释放目标物体。由于在抓取不同大小的物体时,平行下巴夹持器可能受到限制,我们考虑配备吸盘的机械臂来简化物体抓取。抓取和接近基元的实现如下:我们首先在目标物体或链路上随机采样一个点,计算一个与采样点法线一致的夹持器姿态,然后使用运动规划找到无碰撞路径到达目标夹持器姿态。在达到姿势后,我们保持沿法线方向移动,直到与目标物体接触。
对于使用 RL 或轨迹优化学习的子任务,我们提示 GPT-4 用几个上下文示例编写相应的奖励函数。对于物体操作和运动任务,奖励函数基于低层次仿真状态,GPT-4 可以通过提供的 API 调用列表查询。此外,我们要求 GPT-4 建议学习算法的动作空间,例如末端执行器的增量平移,或末端执行器的目标位置移动到。Delta-translation 更适合涉及局部运动的任务,例如,在抓取后打开门;对于涉及将物体迁移到不同位置的任务,直接将目标指定为动作空间使学习更容易。对于软体操作任务,奖励具有固定的形式,指定为软体当前形状与目标形状之间的地球距离。
3.4 SKILL LEARNING
一旦我们获得了所提出任务所需的所有信息,包括场景组件和配置、任务分解和分解子任务的训练监督,我们能够在仿真中构建场景来学习完成任务所需的技能。
如前所述,我们使用技术的组合进行技能学习,包括强化学习、进化策略、基于梯度的轨迹优化和运动规划的动作基元,因为每个都适用于不同类型的任务。对于物体操作任务,我们使用 SAC (Haarnoja et al., 2018) 作为 RL 算法来学习技能。观察空间是任务中物体和机器人的低层次状态。RL策略的动作空间包括机器人末端执行器的增量平移或目标位置(由GPT-4确定),以及它们的增量旋转。我们使用在开放运动规划库 (OMPL) (Sucan et al., 2012) 中实现的 BIT∗ (Gammell et al., 2015) 作为动作基元的底层运动规划算法。对于涉及多个子任务的长视距任务,我们采用一种简单的顺序学习每个子任务方案:对于每个子任务,我们运行 RL N = 8 次,并使用奖励最高的最终状态作为下一个子任务的初始状态。对于运动任务,交叉熵方法用于技能学习,我们发现它比 RL 更稳定和高效。ground-truth 仿真器被用作 CEM 中的发电机模型,待优化的动作是机器人的关节角度值。对于软体操作任务,我们使用 Adam 运行基于梯度的轨迹优化来学习技能,其中梯度由我们使用的完全可微仿真器提供。有关技能学习的更多细节可以在附录 A 中找到。
4 EXPERIMENTS
RoboGen 是一个自动管道,可以无限查询,并为不同的任务生成连续的技能演示流。在我们的实验中,我们旨在回答以下问题:
- Task Diversity: How diverse are the tasks proposed by RoboGen robotic skill learning?
- Scene Validity: Does RoboGen generate valid simulation environments that match the proposed task descriptions?
- Training Supervision Validity: Does RoboGen generate correct task decomposition and training supervisions for the task that will induce intended robot skills?
- Skill Learning: Does integrating different learning algorithms in RoboGen improve the success rate of learning a skill?
- System: Combining all the automated stages, can the whole system produce diverse and meaningful robotic skills?
4.1 EXPERIMENTAL SETUP
我们提出的系统是通用的,并且与特定的仿真平台无关。然而,由于我们考虑了从刚体动力学到软体仿真的广泛任务类别,并考虑了基于梯度的轨迹优化等技能学习方法,这需要可微仿真平台,我们使用 Genesis 部署 RoboGen,这是一个用于机器人学习不同材料和完全可微的仿真平台。对于技能学习,我们使用 SAC 作为RL算法。策略和 Q 网络都是大小为 [256, 256, 256] 的多层感知器 ,学习率为 3e-4。对于每个子任务,我们使用 1M 环境步骤进行训练。我们使用 BIT∗ 作为运动规划算法,Adam Kingma & Ba 用于软体操作任务的基于梯度的轨迹优化。这些学习算法的更多实现细节可以在附录 A 中找到。
4.2 EVALUATION METRICS AND BASELINES
我们使用以下指标和基线来评估我们的系统:
Task Diversity
生成的任务的多样性可以通过多种方式衡量,例如任务的语义、生成的仿真环境的场景配置、检索到的物体资产的外观和几何以及执行任务所需的机器人动作。对于任务的语义,我们通过在生成的任务描述上计算 Self-BLEU 和嵌入相似度 (Zhu et al., 2018) 来执行定量评估,其中较低的分数表示更好的多样性。我们与已建立的基准进行比较,包括 RLBench,Maniskill2,Meta-World 和 Behavior-100 。对于物体资产和机器人动作,我们使用生成的仿真环境和可视化学习机器人技能定性地评估 RoboGen。
Scene Validity
为了验证检索到的物体与任务的要求相匹配,我们计算了仿真场景中检索到的物体的渲染图像与物体的文本描述之间的 BLIP-2 分数。我们与我们系统的两个消融进行了比较。
- A) 没有物体验证:我们不使用 VLM 来验证检索到的物体,并且仅基于文本匹配检索物体。
- B) 没有大小验证:我们不使用 GPT-4 输出的物体大小;相反,我们使用 Objaverse 或 PartNetMobility 中提供的资产的默认大小。
Training Supervision Validity
我们通过使用生成的分解和训练监督呈现学习技能的图像和视频来对这一点进行定性评估。
Skill Learning Performance
我们将其与消融进行比较,其中我们删除了使用基于运动规划的原始和基于梯度的轨迹优化的选项,并完全依赖于强化学习来学习技能。给定一个任务,我们使用 4 个不同的种子运行每种方法,并报告任务返回的均值和标准差(我们手动验证 GPT-4 生成的奖励函数对于评估的任务是正确的)。
System
我们通过在我们的网站上提供超过 100 个学习技能的视频来对整个系统进行定性评估。在本文中,我们展示了代表性技能的快照。

4.3 RESULTS
Task Diversity

定量评估结果如表 1 所示。我们比较了RoboGen的一个版本,其中总共生成了106个任务。如图所示,与之前的所有基准相比,RoboGen 实现了最低的 Self-BLEU 和嵌入相似性,这表明生成的任务的多样性高于这两个指标下先前手动建立的基准。这表明 RoboGen 可以生成一组任务,其多样性匹配或超过先前手工制作的技能学习基准和数据集。
Scene Validity
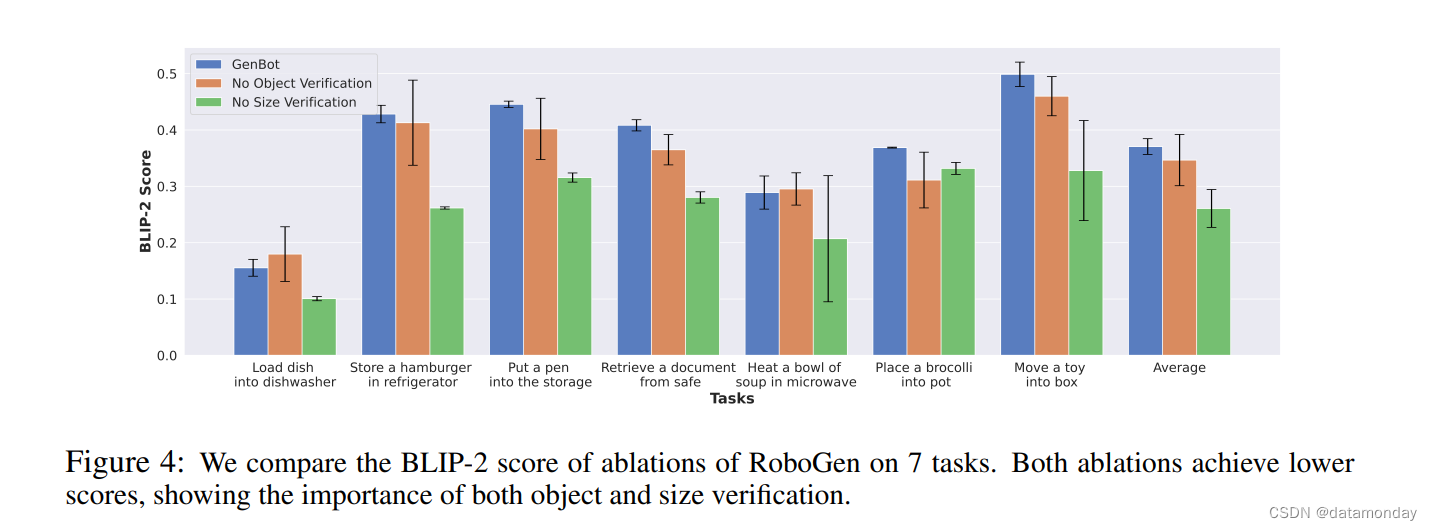
图 4 显示了 7 个示例生成任务中所有比较方法的 BLIP-2 分数。如图所示,删除大小验证会导致 BLIP-2 分数急剧下降。这是意料之中的,因为 Objaverse 和 PartNetMobility 的默认资产大小可能与合理的现实世界大小有很大不同。消融“无物体验证”也具有较低的 BLIP-2 分数,方差较大,表明我们的验证步骤提高了物体选择的有效性。结果表明,在 RoboGen 中使用物体和大小验证的重要性。
Training Supervision Validity
图 3 展示了在 4 个示例长视距任务上使用 RoboGen 生成的训练监督(即任务分解和奖励函数)学习的技能。如图所示,机器人成功地学习了完成相应任务的技能,这表明自动生成的训练监督在推导有意义和有用的技能方面是有效的。
Skill Learning

我们评估了 4 个涉及与铰接物体交互的任务。结果如表 2 所示。我们发现,允许选择学习算法有利于实现更高性能来完成任务。当仅使用 RL 时,技能学习在大多数任务中完全失败。
System
图 1 和图 3 可视化了 RoboGen 的一些生成任务和学习技能。如图 1 所示,RoboGen 可以生成不同的任务,用于从刚性/铰接的物体操作、运动和软体操作中进行技能学习。图 3 进一步表明,RoboGen 能够以合理的分解提供长期操纵技能。
有关拟议任务和学习技能的广泛定性结果,请参阅我们的项目网站。
5 CONCLUSION & LIMITATIONS
我们介绍了 RoboGen,这是一种生成式 Agent,它通过生成仿真自动提出和大规模学习不同的机器人技能。RoboGen利用基础模型的最新进展在仿真中自动生成不同的任务、场景和训练监督,为仿真中的可扩展机器人技能学习迈出了基础一步,同时一旦部署,需要最少的人工监督。我们的系统是一个完全生成的管道,可以无限查询,产生大量与不同任务和环境相关的技能演示。RoboGen 与后端基础模型无关,并且可以在可用时使用最新模型进行持续升级。
我们当前的系统仍然存在一些局限性:
- 1)对学习技能的大规模验证(即生成的技能是否真的通过文本描述解决相应的任务)仍然是当前管道中的挑战。这可以通过在未来使用更好的多模态基础模型来解决。最近的工作(Ma et al., 2023)还探索了使用环境反馈对生成的监督(奖励函数)进行迭代细化,我们希望在未来集成到我们的范式中。
- 2)当涉及到实际部署时,我们的范式本质上受到 sim-to-real 差距的限制。然而,随着物理精确仿真的最新进展和快速的进步,以及领域随机化和现实感觉信号渲染等技术,我们预计在不久的将来将进一步缩小仿真到真实的差距。
- 3)我们的系统假设在正确的奖励函数下,现有的策略学习算法足以学习所提出的技能。对于我们在本文中测试的策略学习算法(具有 SAC 的 RL 和 delta 末端执行器姿态的动作空间以及基于梯度的轨迹优化),我们观察到它们仍然不够健壮,并且通常需要多次运行才能为某些生成任务产生成功的技能演示。
我们将更强大的策略学习算法集成到 RoboGen 中,例如,那些具有更好的动作参数化算法(Zeng et al., 2021; Seita et al., 2023),作为未来的工作。