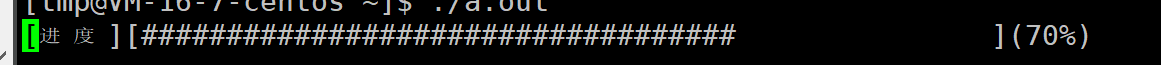目录
- 编译过程
- 编译器查看
- 详解
- 函数库
- 自动化构建工具
- 进度条程序
1. 编译过程
预处理: a. 去注释 b.宏替换 c.头文件展开 d.条件编译
编译: 汇编
汇编: 可重定向二进制目标文件
链接: 链接多个.o, .obj合并形成一个可执行exe
gcc编译c程序, g++编译c++程序
2. 编译器查看
输入gcc -v , g++ -v ,查看编译器的版本,如果不存在g++,可以用命令安装
sudo yum install -y gcc-c++
3. 详解
如果要编译成可执行文件,首先编写一个.c文件,然后输入:
gcc [选项] 要编译的文件 [选项] [目标文件]
例如: gcc code.c -o myexe , -o后面带要生成的程序名

3.1 预处理
预处理功能主要包括宏定义、文件包含展开,条件编译,去注释等
预处理指令是以#号开头的代码行
实例: gcc -E hello.c -o hello.i
E的作用是让预处理后停止编译,选项-o是生成目标文件,不然会打印在屏幕上,.i为预处理后的文件
准备要一份这样的源代码:
1 #include <stdio.h>2 #define M 1003 4 int main()5 {6 printf("hello %d\n ", M);7 8 //条件编译9 #ifdef DEBUG 10 printf("debug\n");11 #else12 printf("release\n");13 #endif 14 return 0;15 }
执行预处理结果:
打开源代码和生成的.i文件对比
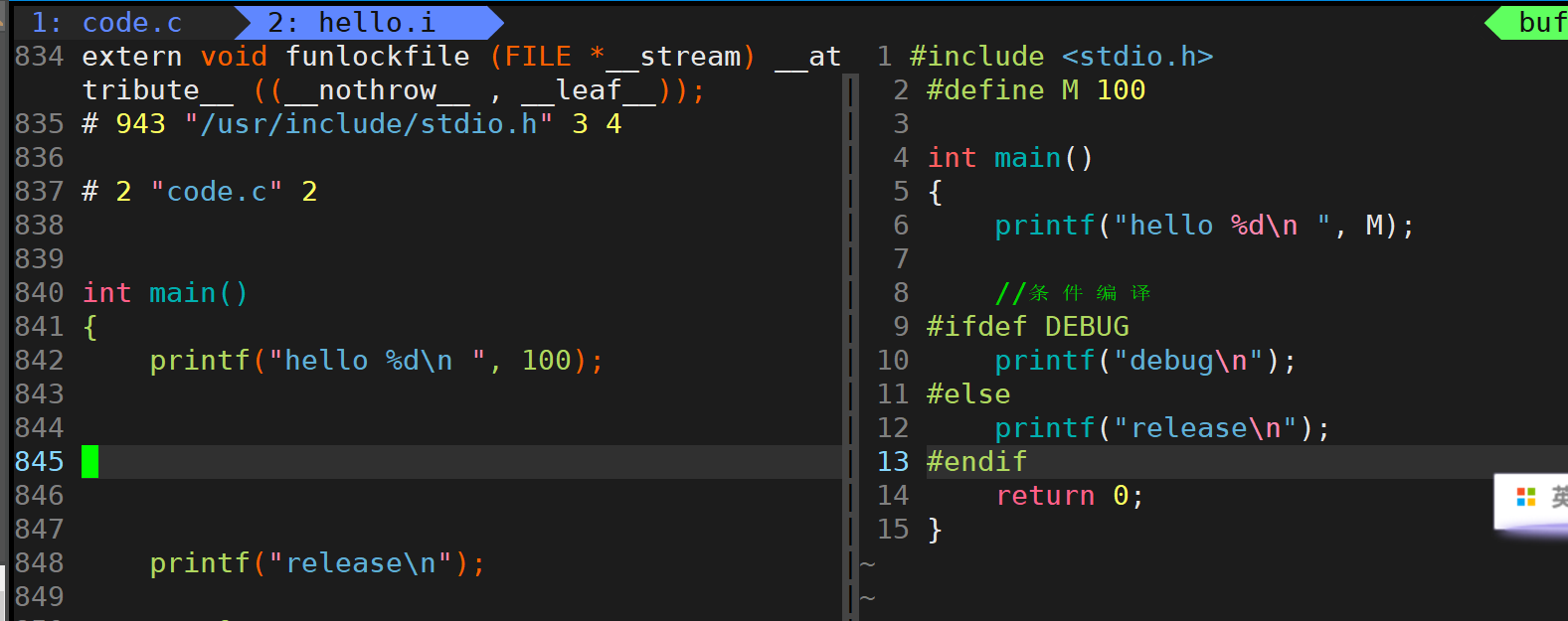
上面的840行才到main函数,前面的一大段部分是include头文件展开的结果,里面都是头文件函数的声明。define定义的宏M直接用100替换了输出的地方。条件编译这四个注释的字也去了,因为gcc默认编译为release模式,所以条件编译只保留条件成立的结果
3.2 编译
这个阶段首先检查代码的规范性,语法错误以及实际要做的工作,确保无误后翻译成汇编语言
实例:
gcc -S [.i文件] -o [文件名.s]
源文件翻译完成停止编译,将上面的.i 文件编译成.s文件查看

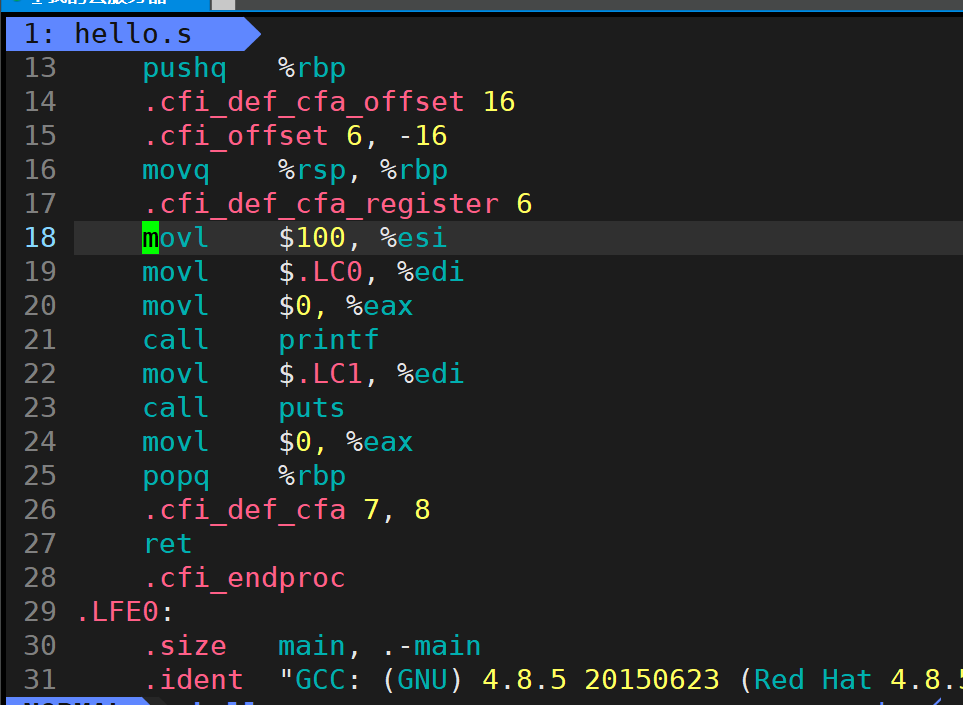
3.3 汇编
生成机器识别的二进制代码,实例:
gcc -c hello.s -o hello.o
将上面的汇编文件转换为二进制目标文件查看

由于是二进制文件,编辑器不能识别,所以显示为乱码
3.4 链接
生成可执行文件或库文件
实例:
gcc hello.o -o hello
4. 函数库
我们的程序中并没有printf函数的实现,而且预处理后也只有函数的声明,那是在哪里实现的printf函数
输入 file [程序名]

这里说动态链接分享的库,答案是这些函数的实现都在名为libc.so.6的库文件中,gcc会在路径/usr/bin目录下寻找,就能链接到库函数
/usr/include目录下有函数头文件,提供c语言函数的声明
ldd [程序]可以看到依赖的库,提供函数的实现

库分为动态库和静态库
静态库是编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,运行时也不需要库文件了
动态库是一个包含可由多个程序同时使用的代码和数据的库,动态链接提供了一种方法地址,程序执行时去找对应的函数实现
win:.dll 是动态库 .lib是静态库
linux: .so是动态库 .a是静态库
静态库需要拷贝函数实现所以文件更大,动态库生成的程序更小
gcc/g++默认动态链接的,输入命令使用静态链接
gcc [文件] -o [程序名] -static

静态链接的文件体积大很多
如果没有静态库,可以安装
sudo yum install -y glibc-static
sudo yum install -y libstdc+±static
gcc选项
-E 只激活预处理,不生成文件,需要重定向到输出文件
-S 编译到汇编语言不进行汇编和链接
-c 编译到目标代码
-o 文件输出到文件
-static 此选项仅对生成的文件采用静态链接
-g 生成调试信息,GNU调试器可利用该信息
-shared 尽量使用动态库,生成文件较小,需要有动态库
-O0
-O1
-O2
-O3 编译器优化的四个级别,0表示没有优化,1为缺省值,3最高
-w 不生成任何警告信息
-Wall 生成所有警告信息
可以记忆为编译选项Esc ,生成iso文件
5. 自动化构建
make和makefile
一个工程中的源文件不计其数,放在若干个目录中,makefile定义了一系列规则,哪些
文件需要先编译,哪些文件后编译,什么时候重新编译
带来的好处就是自动化编译,一旦写好,以后只需要调用,极大提高了开发效率。
make是一个命令工具,解释makefile指令的工具,一般来说大多数ide都有这个命令,如:Delphi的make,vc的nmake,linux下GNU的make
make是命令,makefile是文件,两个搭配使用
自动化构建的makefile需要明确两个东西,依赖关系和依赖方法,依赖关系自顶向下匹配,所以把首先把依赖关系根部的写最前面
准备三个文件,一个头文件和实现,一个main函数
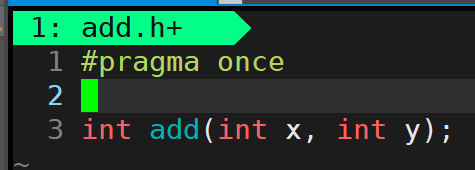
头文件,add.h
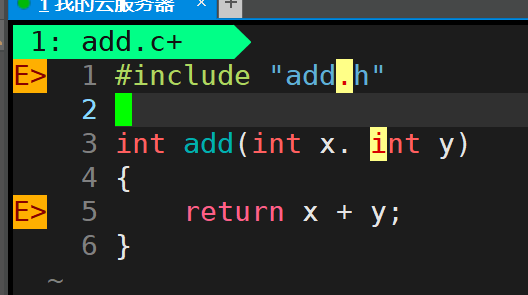
实现 add.c
main文件 main.c
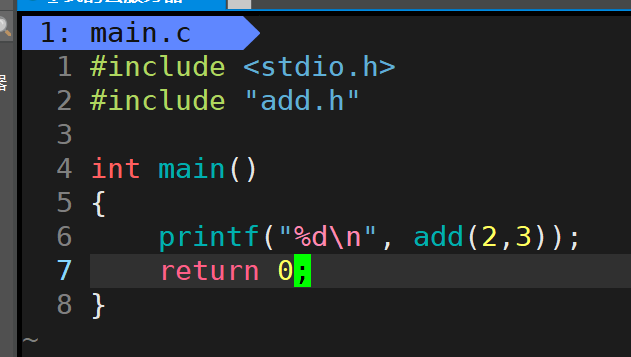
先用gcc编译一下程序有没有错误

创建一个makefile文件,用来自动化构建
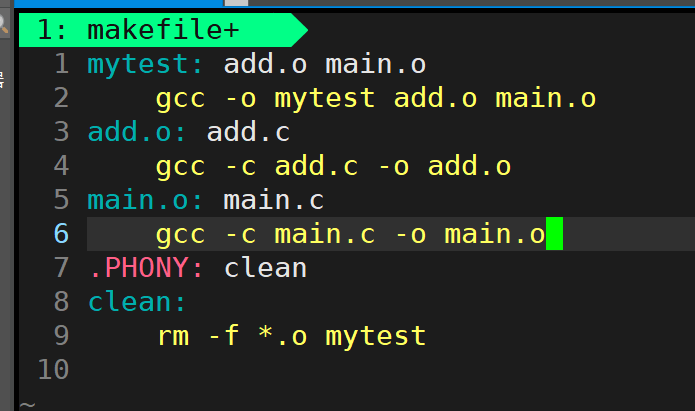
mytest是要生成的程序名,依赖于add.o和main.o两个文件,这两个文件各自又依赖于源文件,gcc生成这两个源文件,最后加clean的依赖关系和依赖方法,删除所有临时文件和程序
输入make就会自动生成程序
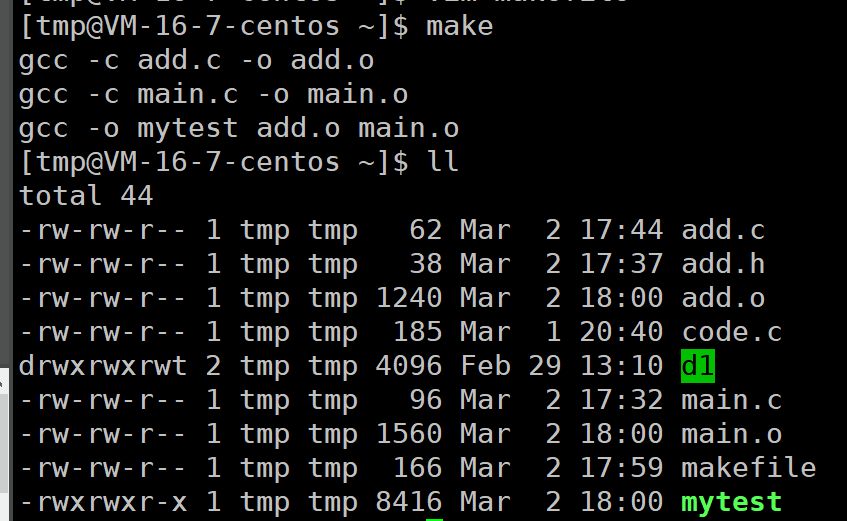
输入make clean就会清楚项目
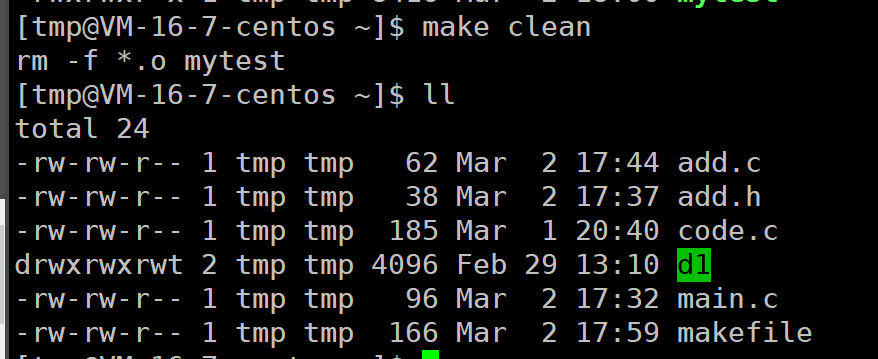
当多次make会显示程序已经是最新的了
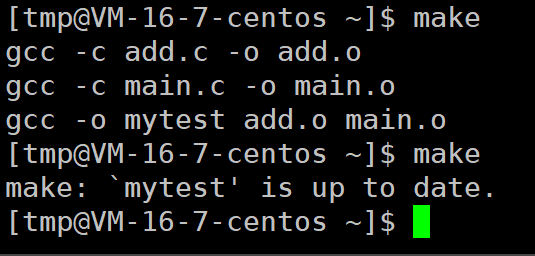
这是因为程序如果已经是最新的,就没必要继续生成。makefile如何得知程序是最新的?。前面说过文件有acm时间,a是访问时间,因为是频繁操作所以达到一定量会刷新,c是内容修改时间,m是文件属性修改时间,一般内容修改,文件大小也会变化。一般情况下,生成的程序的修改时间应该是最晚的,make时会对比依赖的两个源文件是否有内容变化,如果这两个文件的修改时间晚于程序的时间,就说明内容有变化,这时可以make生成
我们修改一下main文件的参数重新make
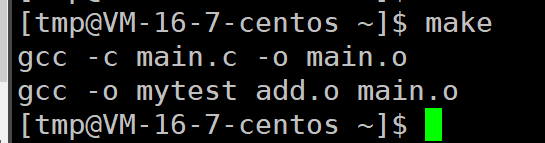
修改后就可以构建了
.PHONY的依赖关系总是被执行的,这个如何理解
当我们构建时,如果程序是最新的将无法生成,但我们执行clean却不受时间限制,每次都可以执行,这就是总是可以执行
在写项目时,makefile先确保没问题再写项目
6. 进度条程序
\r和\n两个是不同的功能,在最初的计算机中,\n用来换行,而光标还在上一行的位置,\r回车用来重新回到本行开头,所以到下一行开头就是\r\n
#include <stdio.h> int main()
{ printf("hello \r"); return 0;
}
输入上面程序执行
发现什么都没有打印,这是因为\r让光标回到了最开头所以没有文本。在计算机里,输出并不是立即输出,有一个输出缓冲区的概念,有自己的刷新规则。碰到\n会把\n之前的内容刷新到目标设备。也可以用一些强制刷新缓冲区的函数,如:fflush(stdout)函数
制作进度条,每次打印增加的部分和百分比,都在同一行不断刷新,不换行。这个可以用\r打印
#include <stdio.h>
#include <unistd.h> int main()
{ int cnt = 1; char str[100]= {0}; while(cnt <=50) { str[cnt - 1] = '#'; printf("[进度][%-50s](%d%%) \r", str,cnt*2); fflush(stdout); usleep(30000); cnt++; } printf("\n"); return 0;
}
由于屏幕不够,每行打印50个扩大2倍作为百分百,usleep可以查询,是一个延时的函数,单位是微秒,上面是0.3秒一打印