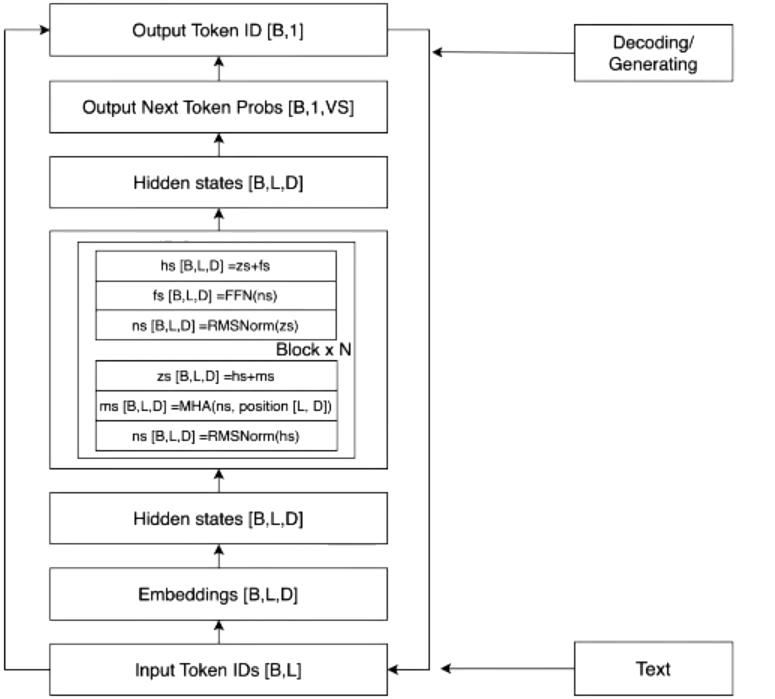
1. 简介
融合激光雷达和相机的信息已经变成了3D目标检测的一个标准,当前的方法依赖于激光雷达传感器的点云作为查询,以利用图像空间的特征。然而,人们发现,这种基本假设使得当前的融合框架无法在发生 LiDAR 故障时做出任何预测,无论是轻微还是严重。这从根本上限制了实际场景下的部署能力。相比之下,在BEVFusion框架中,其相机流不依赖于 LiDAR 数据的输入,从而解决了以前方法的缺点。
有两个版本的BEVFusion,分别是北大与阿里合作的Bevfusion: A Simple and Robust LiDAR-Camera和麻省理工发表的Bevfusion: Multi-task multi-sensor fusion with unified bird's-eye view representation,下面分别进行介绍。
2. PKU BEVFusion
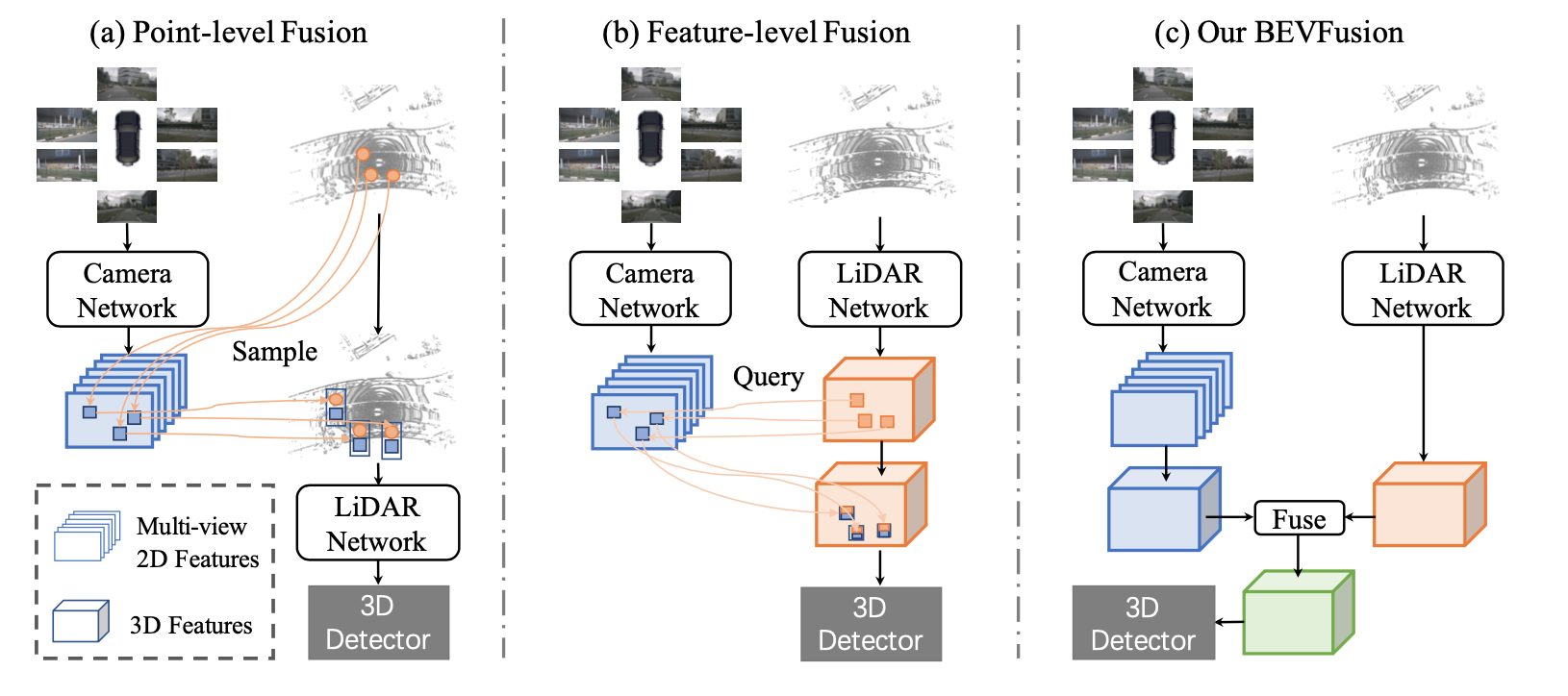
作者认为,LiDAR和相机融合的理想框架应该是,无论彼此是否存在,单个模态的每个模型都不应该失败,但同时拥有两种模态将进一步提高感知准确性。为此,作者提出了一个令人惊讶的简单而有效的框架,它解决了当前方法的LiDAR相机融合的依赖性,称为BEVFusion。具体来说,如图1 (c)所示,作者的框架有两个独立的流,它们将来自相机和LiDAR传感器的原始输入编码为同一BEV空间内的特征。然后作者设计了一个简单的模块,在这两个流之后融合这些BEV的特征,以便最终的特征可以传递到下游任务架构中。由于作者的框架是一种通用方法,作者可以将当前用于相机和LiDAR的单模态BEV模型合并到作者的框架中。作者采用Lift-Splat-Shoot作为相机流,它将多视图图像特征投影到3D车身坐标特征以生成相机BEV特征。同样,对于LiDAR流,作者选择了三个流行的模型,两个基于超体素(voxel)的模型和一个基于柱子(pillar)的模型将LiDAR特征编码到BEV空间中。

3. MIT BEVFusion

 3.1. 统一表示
3.1. 统一表示
不同的视图中可以存在不同的特征。例如,相机特征在透视视图中,而激光雷达/雷达特征通常在3D/鸟瞰视图中。即使是相机功能,每个功能都有不同的视角(即前、后、左、右)。这个视图差异使得特征融合变得困难,因为不同特征张量中的相同元素可能对应完全不同的空间位置(在这种情况下,naïve elementwise特征融合将不起作用)。因此,找到一个共享的表示是至关重要的,这样(1)所有传感器特征都可以很容易地转换为它而不丢失信息,(2)它适合于不同类型的任务。
相机。在RGB-D数据的激励下,一种选择是将LiDAR点云投影到相机平面上,并渲染2.5D稀疏深度。然而,这种转换在几何上是有损的。深度图上的两个邻居在3D空间中可以彼此远离。这使得相机视图对于专注于物体/场景几何的任务(如3D物体检测)的效果较差。
激光雷达。大多数最先进的传感器融合方法用相应的摄像机特征(例如语义标签、CNN特征或虚拟点)装饰LiDAR点。然而,这种摄像头到激光雷达的投影在语义上是有损耗的。相机和激光雷达功能的密度有很大的不同,导致只有不到5%的相机功能与激光雷达点匹配(对于32通道激光雷达扫描仪)。放弃相机特征的语义密度严重损害了模型在面向语义任务(如BEV地图分割)上的性能。类似的缺点也适用于潜在空间中的最新融合方法(例如,对象查询)。
鸟瞰图。采用鸟瞰图(BEV)作为融合的统一表示。这个视图对几乎所有的感知任务都是友好的,因为输出空间也是在BEV中。更重要的是,向BEV的转换同时保持几何结构(来自激光雷达特征)和语义密度(来自相机特征)。一方面,LiDAR- bev投影将稀疏的LiDAR特征沿高度维度平坦化,从而不会在图1a中产生几何失真。另一方面,相机到BEV投影将每个相机特征像素投射回3D空间中的射线(下一节将详细介绍),这可能导致图1c中密集的BEV特征映射,其中保留了来自相机的完整语义信息。
3.2. 高效的摄像头到BEV的转换
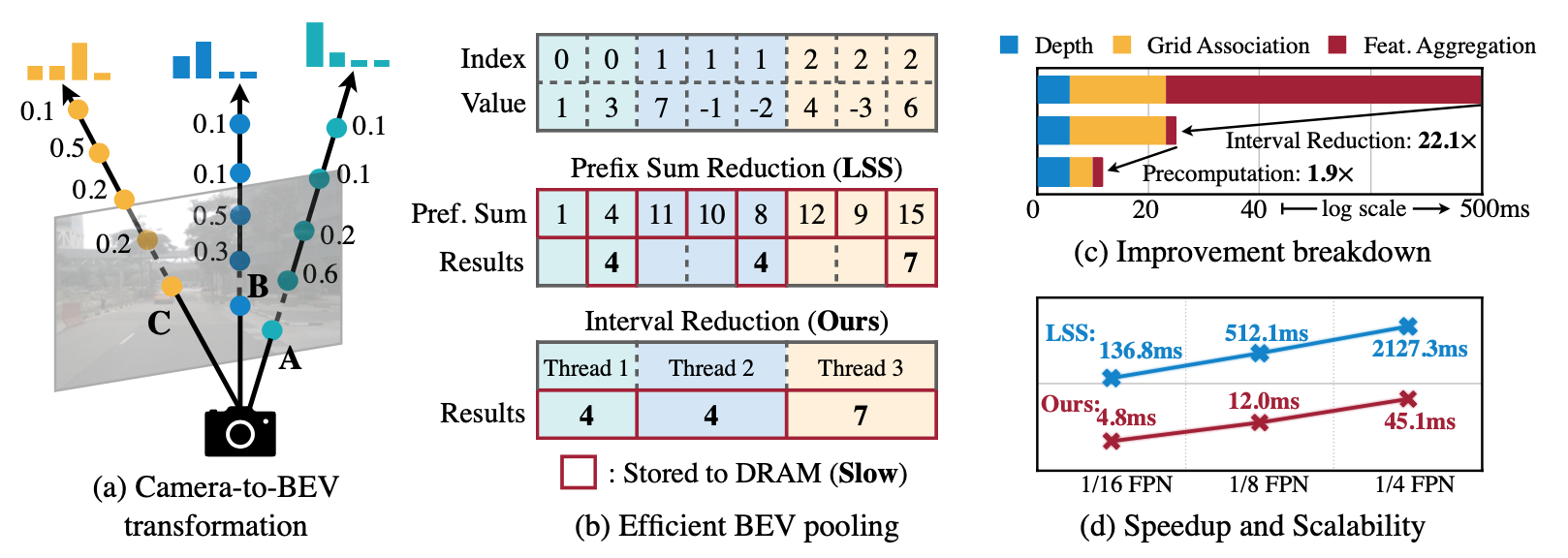
摄像头到BEV的转换不是简单的,因为与每个摄像头特征像素相关的深度本质上是模糊的。根据LSS和BEVDet,他们明确地预测了每个像素的离散深度分布。然后,他们将每个特征像素沿摄像机射线分散到D个离散点,并根据相应的深度概率重新缩放相关特征(图3a)。这将生成一个大小为N HW D的相机特征点云,其中N是相机的数量,(H, W)是相机特征映射的大小。该三维特征点云沿x、y轴进行量化,步长为r(例如0.4m)。他们使用BEV池化操作来聚集每个r × r BEV网格中的所有特征,并沿z轴将特征平坦化。
虽然简单,但BEV池化的效率和速度惊人地低,在RTX 3090 GPU上需要超过500毫秒(而他们模型的其余部分只需要大约100毫秒)。这是因为摄像特征点云非常大:对于典型的工作负载,每帧可能生成大约200万个点,比激光雷达特征点云的密度大两个数量级。为了克服这一效率瓶颈,他们提出了通过预计算和间隔缩短来优化BEV池。
预先计算。BEV池化的第一步是将摄像机特征点云中的每个点与BEV网格关联。与LiDAR点云不同,相机特征点云的坐标是固定的(只要相机的intrinsic和extrinsics保持不变,这通常是在适当校准后的情况下)。在此基础上,他们预先计算每个点的3D坐标和BEV网格索引。他们还根据网格索引对所有点进行排序,并记录每个点的排名。在推理过程中,他们只需要根据预先计算的秩对所有特征点进行重新排序。这种缓存机制可以将网格关联的延迟从17ms减少到4ms。
间隔的减少。网格关联后,同一BEV网格内的所有点在张量表示中都是连续的。BEV池化的下一步是通过一些对称函数(例如,均值、最大值和和)聚合每个BEV网格中的特征。如图3b所示,现有实现首先计算所有点的前缀和,然后减去索引变化边界处的值。然而,前缀和操作需要GPU上的树约简,并产生许多未使用的部分和(因为他们只需要边界上的那些值),这两者都是低效的。为了加速特征聚合,他们实现了一个专门的GPU内核,它直接在BEV网格上并行:他们为每个网格分配一个GPU线程,计算它的间隔和并将结果写回来。该内核消除了输出之间的依赖关系(因此不需要多级树约化),并避免将部分和写入DRAM,将特征聚合的延迟从500ms减少到2ms(图3c)。
其他。通过优化的BEV池化,相机到BEV的转换速度提高了40倍:延迟从超过500ms减少到12ms(仅占他们模型端到端运行时间的10%),并且在不同的特征分辨率上都能很好地伸缩(图3d)。这是在共享BEV表示中统一多模态感官特征的关键使能器。我们同时进行的两项工作也确定了仅在相机的3D检测中的效率瓶颈。他们通过假设均匀的深度分布或截断每个BEV网格中的点来近似视图转换器。相比之下,他们的技术是精确的,没有任何近似,同时仍然更快。
3.3. 全卷积融合
将所有的感官特征转换为共享的BEV表示,他们可以很容易地用一个元素操作符(如拼接)将它们融合在一起。尽管在同一空间中,由于视图转换器的深度不准确,LiDAR BEV特征和相机BEV特征仍然会在一定程度上出现空间错位。为此,他们应用了一个基于卷积的BEV编码器(带有一些剩余块)来补偿这种局部失调。他们的方法可能从更精确的深度估计中受益(例如,用地面真实深度监视视图转换器),他们将其留给未来的工作。
3.4. 多任务头
他们将多个特定于任务的头应用到融合BEV特征图中。他们的方法适用于大多数3D感知任务。他们展示了两个例子:三维物体检测和BEV地图分割。
检测。他们使用特定于类的中心热图头来预测所有对象的中心位置,并使用一些回归头来估计对象的大小、旋转和速度。我们建议读者参考之前的3D检测论文[1,67,68]了解更多细节。
分割。不同的地图类别可能会重叠(例如,人行横道是可驾驶空间的子集)。因此,他们将这个问题表述为多个二进制语义分割,每个类一个。他们遵循CVT,用标准focal loss来训练分割头。

参考文献
https://download.csdn.net/blog/column/11257654/134724055
Bevfusion: A Simple and Robust LiDAR-Camera
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework - 知乎
BEVFusion:A Simple and Robust LiDAR-Camera Fusion Framework 论文笔记_bevfusion: a simple and robust lidar-camera fusion-CSDN博客
Bevfusion: Multi-task multi-sensor fusion with unified bird's-eye view representation
技术精讲 | BEVFusion: 基于统一BEV表征的多任务多传感器融合-CSDN博客
BEVFusion论文解读-CSDN博客