:::info
💡 近日,OpenAI发布了视频生成模型Sora,最大的Sora模型能够生成一分钟的高保真视频。同时 OpenAI称,可扩展的视频生成模型,是构建物理世界通用模拟器的一条可能的路径。
**📃 **Sora能够生成横屏19201080视频,竖屏10801920视频,以及之间的所有内容。这使得Sora可 以兼容不同的视频播放设备,根据特定的纵横比来生成视频内容,这也会大大影响视频创作领域, 包括电影制作,电视内容,自媒体等。
:::
源地址为: Video generation models as world simulators
⛳️ ** 提示词:**一位时髦的女士穿行在东京的街头,街道充满了温暖的霓虹灯光和动感的城市标志。她穿着一 件黑色皮夹克,一条长红裙和黑色靴子,手拿一个黑色手提包。她戴着太阳镜和红色口红。她走路既自 信又随意。街道潮湿且能反射,创造出彩色灯光的镜面效果。许多行人来来往往。
演示效果如下:
title_0
当然,openai还展示了非常多的prompt,可以在Twitter或者上方链接中观看。
sora技术流程
根据魔搭社区所推测的sora技术架构图如下:
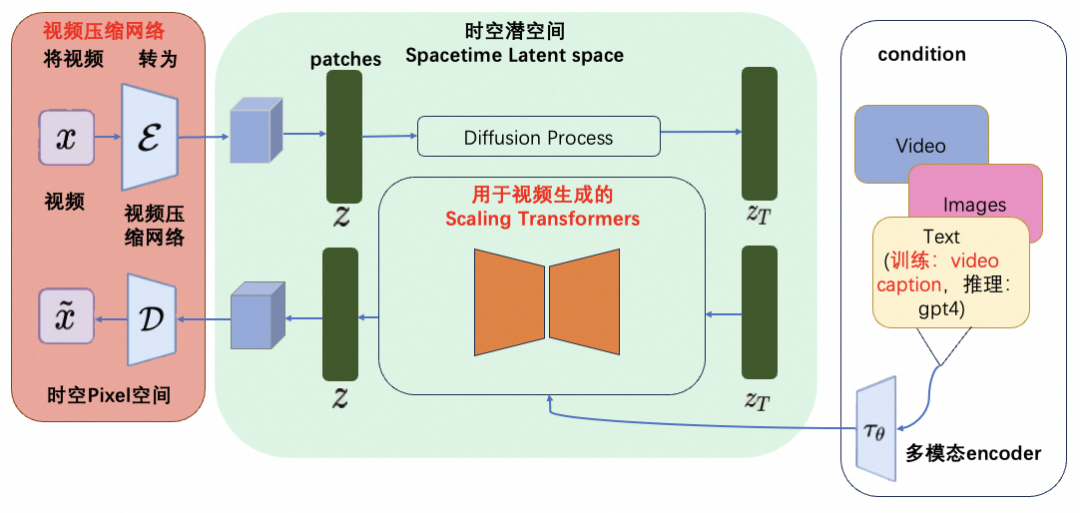
OpenAI训练了一个降低视觉数据维度的网络。这个网络接受原始视频作为输入,并输出在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间上进行训练,并随后生成视频。同时还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间(源自Sora技术报告)。这部分内容为图中的红色部分。可见下图:
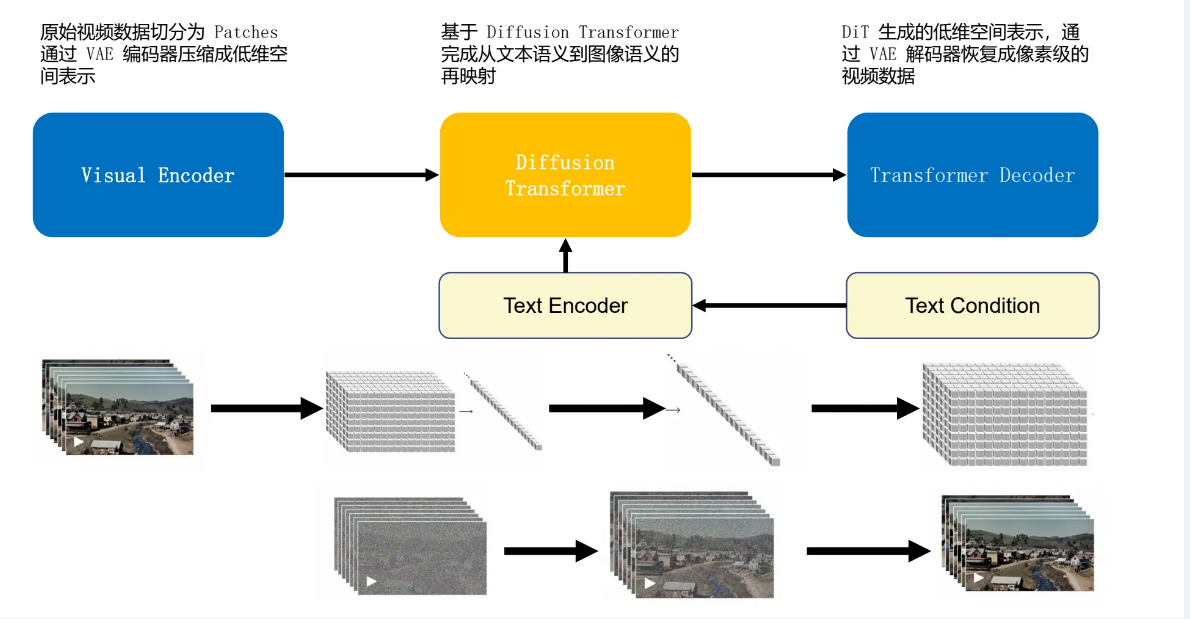
而其中的核心工作为将视觉数据转化为patches,patches是从大语言模型中获得的灵感,大语言模型范式的成功部分得益于使用优雅统一各种文本模态(代码、数学和各种自然语言)的token。大语言模型拥有文本token,而Sora拥有视觉分块(patches)。OpenAI在之前的Clip等工作中,充分实践了分块是视觉数据模型的一种有效表示(参考论文:An image is worth 16x16 words: Transformers for image recognition at scale.)这一技术路线。而视频压缩网络的工作就是将高维度的视频数据转换为patches,首先将视频压缩到一个低纬的latent space,然后分解为spacetime patches。

这个方法同样适用于图像(将图像作为单一帧视频处理),基于Patches的表示使得Sora能够训练具有不同分辨率,持续时间和纵横比的视频和图像,而在推理过程中,只需要在适当大小的grid中随机初始化patches即可控制视频生成的大小。
**技术难点:**视频压缩网络类比于latent diffusion model中的VAE,但是压缩率是多少,如何保证视频特征被更好地保留,还需要进一步的研究。
sora的前世今生
sora是一个diffusion模型,而扩散概念的提出是在2015年,并在2020年得到完善,提出了扩散模型DDPM,其是一种用于生成高质量图像的模型,其训练流程相对复杂但非常有效。以下是DDPM的训练流程和具体步骤:
- 定义可扩展步骤: DDPM使用马尔可夫链来定义可扩展的生成步骤。这意味着在每一步中,模型会逐渐生成图像的细节,使图像质量逐步提高。
- 改进Diffusion Models: DDPM对传统的diffusion模型进行了改进。传统的diffusion模型是通过对噪声进行预测来生成图像,而DDPM则更注重对噪声的预测,而不是直接生成图像,这有助于提高生成图像的质量和稳定性。
- 预测噪声而不是图片: 在DDPM中,模型的主要任务是预测噪声而不是直接生成图像。通过对噪声的预测,模型可以逐步生成图像的细节,从而得到高质量的图像输出。
- 使用Patch库: DDPM使用patch库将图像分割成小块,这有助于模型更好地处理图像的局部信息,并提高生成图像的质量。
- 向量操作: 模型使用ENOS库进行向量操作,以便更有效地处理图像数据,提高训练效率和生成图像的质量。
DDPM模型
整个过程的训练流程,即为:
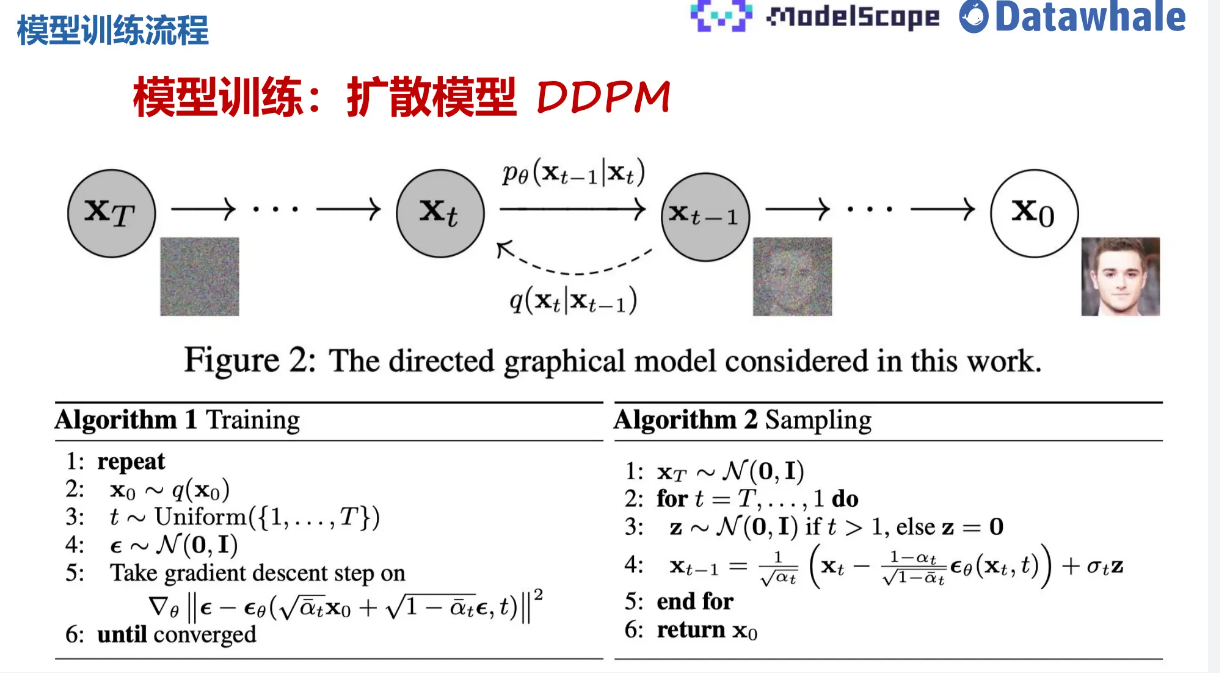
其中,figure 2所提到的work主要分为两个step(加噪&去噪):
- 首先是Diffuison(前向扩散) : 简单来说就是对原始图片 x 0 x_{0} x0进行加噪操作为: q ( x t ∣ x t − 1 ) = N ( x t ; 1 − β x t − 1 , β t I ) q\left(x_{t} \mid x_{t-1}\right)=N\left(x_{t} ; \sqrt{1-\beta} x_{t-1}, \beta_{t} I\right) q(xt∣xt−1)=N(xt;1−βxt−1,βtI) 文章中主要就是逐渐将高斯噪声加到img中,最后得到纯噪声: q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)=\mathcal{N}\left(\mathbf{x}_{t} ; \sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0},\left(1-\bar{\alpha}_{t}\right) \mathbf{I}\right) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
- p θ p_{\theta} pθ反向去噪扩散: p θ ( x t − 1 ∣ x t ) = N ( X t − 1 ; μ θ ( x t , t ) , ∑ θ ( x t , t ) ) p_{\theta}\left(x_{t-1} \mid x_{t}\right)=N\left(X_{t-1} ; \mu_{\theta}\left(x_{t}, t\right), \sum_{\theta}\left(x_{t}, t\right)\right) pθ(xt−1∣xt)=N(Xt−1;μθ(xt,t),∑θ(xt,t)),即神经网络从纯噪声 Xt (T=1000 In raw paper) 开始对图像进行去噪,公式为:
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − σ t ϵ θ ( x t , t ) ) \mu_{\theta}\left(\mathbf{x}_{t}, t\right)=\frac{1}{\sqrt{\alpha_{t}}}\left(\mathbf{x}_{t}-\frac{\beta_{t}}{\sqrt{1-\sigma_{t}}} \epsilon_{\theta}\left(\mathbf{x}_{t}, t\right)\right) μθ(xt,t)=αt1(xt−1−σtβtϵθ(xt,t))
training
training实作上就是使用真实高斯噪声 μ t ( x t , x 0 ) \mu_{t}\left(x_{t}, x_{0}\right) μt(xt,x0) 和预测高斯噪声 μ θ ( x t , t ) \mu_{\theta}\left(x_{t}, t\right) μθ(xt,t) 做 M S E MSE MSE优化

- 随机抽样 x 0 ∼ q ( x 0 ) x_{0} \sim q\left(x_{0}\right) x0∼q(x0)
- 采样 t ∼ Uniform ( 1 , … , T ) t \sim \operatorname{Uniform}(1, \ldots, T) t∼Uniform(1,…,T)
- 随机采样噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim N(0, I) ϵ∼N(0,I)
- train神经网络(U-net) based on Loss
- 目标函数 L t = ∥ ϵ − ϵ θ ( x t , t ) ∥ 2 = ∥ ϵ − ϵ θ ( α ˉ t x 0 + ( 1 − α ˉ t ) ϵ , t ) ∥ 2 L_{t}=\left\|\epsilon-\epsilon_{\theta}\left(\mathbf{x}_{t}, t\right)\right\|^{2}=\left\|\epsilon-\epsilon_{\theta}\left(\sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}+\sqrt{\left(1-\bar{\alpha}_{t}\right)} \epsilon, t\right)\right\|^{2} Lt=∥ϵ−ϵθ(xt,t)∥2= ϵ−ϵθ(αˉtx0+(1−αˉt)ϵ,t) 2
需要理解的是生成模型使用U-net结构,在DDPM中需要生成器预测噪声的分布,但是此处我们可以把噪声看成数据的增广,因此我们需要一个具有强大能力的生成网络,而使用Unet相当于把模型结构规定,结构如下图:
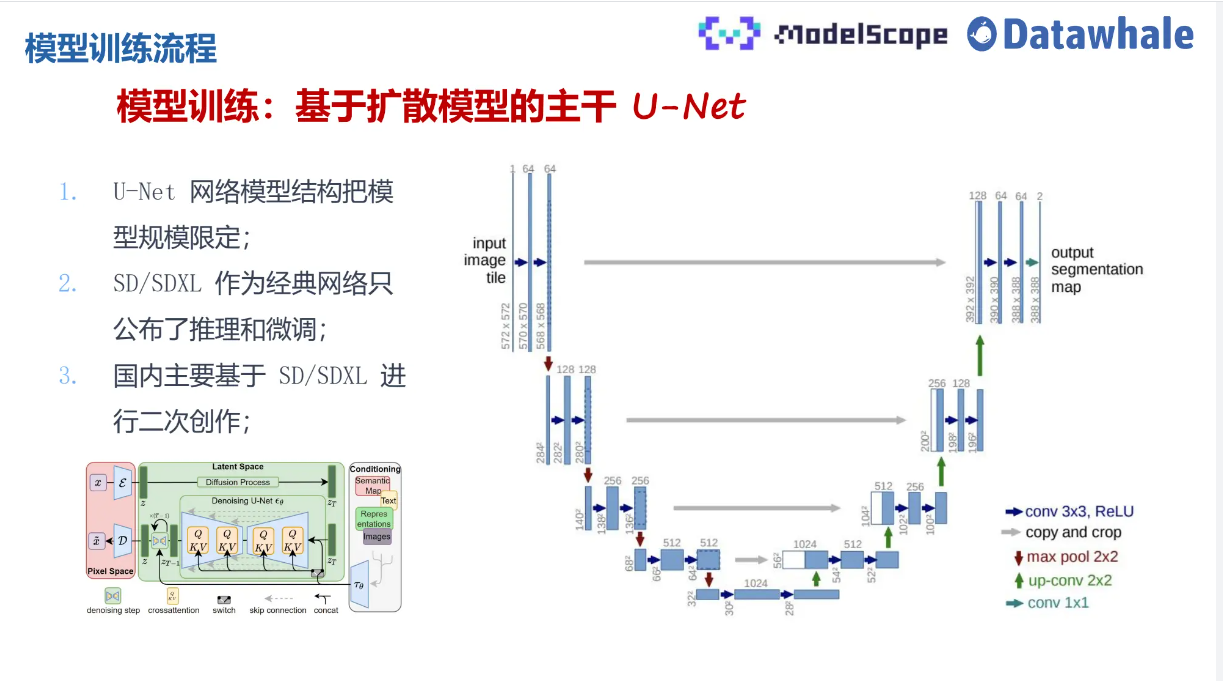
以上即为DDPM的一个训练过程,这里列举前向扩散过程的code解析,即将噪声逐步添加到img中,正向过程的方差在本文中采用线性计划,将方差设为常数,定义beta schedule,之后为上述步骤描述,详细代码为:
timesteps = 200# define beta schedule
betas = linear_beta_schedule(timesteps=timesteps)# define alphas
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)# calculations for diffusion q(x_t | x_{t-1}) and others
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)def extract(a, t, x_shape):batch_size = t.shape[0]out = a.gather(-1, t.cpu())return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)# forward diffusion (using the nice property)
def q_sample(x_start, t, noise=None):if noise is None:noise = torch.randn_like(x_start)sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape)return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
sampling
- 利用 diffusion model生成新图像,从高斯分布 x T ∼ N ( 0 , I ) x_{T} \sim N(0, I) xT∼N(0,I) 采样纯噪声
- 利用神经网络进行去噪(条件概率 p θ ( x t − 1 , x t ) p_{\theta}\left(x_{t-1}, x_{t}\right) pθ(xt−1,xt))
- 插入重参数化过的均值,逐步推导出去噪程度略低的图像 x t − 1 x_{t-1} xt−1


下面的代码实现里这一过程(Simple Version | different from raw code):
@torch.no_grad()
def p_sample(model, x, t, t_index):betas_t = extract(betas, t, x.shape)sqrt_one_minus_alphas_cumprod_t = extract(sqrt_one_minus_alphas_cumprod, t, x.shape)sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)# Equation 11 in the paper# Use our model (noise predictor) to predict the meanmodel_mean = sqrt_recip_alphas_t * (x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t)if t_index == 0:return model_meanelse:posterior_variance_t = extract(posterior_variance, t, x.shape)noise = torch.randn_like(x)# Algorithm 2 line 4:return model_mean + torch.sqrt(posterior_variance_t) * noise # Algorithm 2 (including returning all images)
@torch.no_grad()
def p_sample_loop(model, shape):device = next(model.parameters()).deviceb = shape[0]# start from pure noise (for each example in the batch)img = torch.randn(shape, device=device)imgs = []for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)imgs.append(img.cpu().numpy())return imgs@torch.no_grad()
def sample(model, image_size, batch_size=16, channels=3):return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
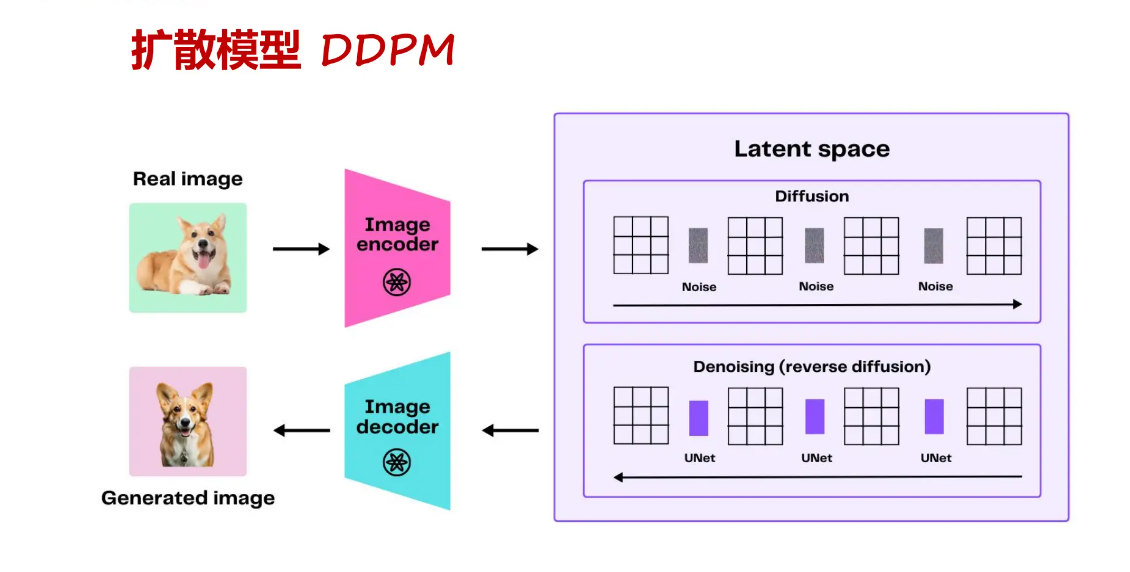
那我们可以用一张比较形象的图进行总结,为:
sora模块拆解
根据上述DDPM模型中的介绍,可以将sora拆解为三个部分,为Visusal encoder、Diffusion Transformer与Transformer Decoder下面就对其分别阐述。
Visusal encoder

Sora 之所以显得如此强大,在于以前的文本转视频方法需要训练时使用的所有图片和视频都要有相同的大小,这就需要大量的预处理工作来裁剪视频至适当的大小。而由于 Sora 是基于“Patch”而非视频的全帧进行训练的,它可以处理任何大小的视频或图片,无需进行裁剪。这就让 OpenAI 能够在大量的图像和视频数据上训练 Sora。因此,可以有更多的数据用于训练,得到的输出质量也会更高。例如,将视频预处理至新的长宽比通常会导致视频的原始构图丢失。一个在宽屏中心呈现人物的视频,裁剪后可能只能部分展示该人物。因为 Sora 能接收任何视频作为训练输入,所以其输出不会受到训练输入构图不良的影响。
输入的视频可以看成是NxHxW的若干帧图像, 通过Encoder被切分成spatial tempral patch,这些patch最终会被flatten成一维向量,送入diffusion model。其中,这里的patch的定义可以类比Vision Transformer中的patch,列举一个简单例子,可以定义一个patch类,最后展示为分割后的结果,代码为:
class Patches(L.Layer):def __init__(self, patch_size=PATCH_SIZE, **kwargs):super().__init__(**kwargs)self.patch_size = patch_sizeself.resize = L.Reshape((-1, patch_size * patch_size * 3))def call(self, images):patches = tf.image.extract_patches(images=images,sizes=[1, self.patch_size, self.patch_size, 1],strides=[1, self.patch_size, self.patch_size, 1],rates=[1, 1, 1, 1],padding="VALID",)patches = self.resize(patches)return patchesdef show_patched_image(self, images, patches):idx = np.random.choice(patches.shape[0])print(f"Index selected: {idx}.")plt.figure(figsize=(4, 4))plt.imshow(keras.utils.array_to_img(images[idx]))plt.suptitle('Original Image')plt.axis("off")plt.show()n = int(np.sqrt(patches.shape[1]))plt.figure(figsize=(4, 4))plt.suptitle('Patches')for i, patch in enumerate(patches[idx]):ax = plt.subplot(n, n, i + 1)patch_img = tf.reshape(patch, (self.patch_size, self.patch_size, 3))plt.imshow(keras.utils.img_to_array(patch_img))plt.axis("off")plt.show()return idxdef reconstruct_from_patch(self, patch):num_patches = patch.shape[0]n = int(np.sqrt(num_patches))patch = tf.reshape(patch, (num_patches, self.patch_size, self.patch_size, 3))rows = tf.split(patch, n, axis=0)rows = [tf.concat(tf.unstack(x), axis=1) for x in rows]reconstructed = tf.concat(rows, axis=0)return reconstructedimage_batch = next(iter(train_ds))augmentation_model = get_train_augmentation_model()
augmented_images = augmentation_model(image_batch)patch_layer = Patches()
patches = patch_layer(images=augmented_images)
random_index = patch_layer.show_patched_image(images=augmented_images, patches=patches)


而该方案来自于Vision Transformer论文,也是由此,让图像进入了transformer时代。下面为Vit的架构图:
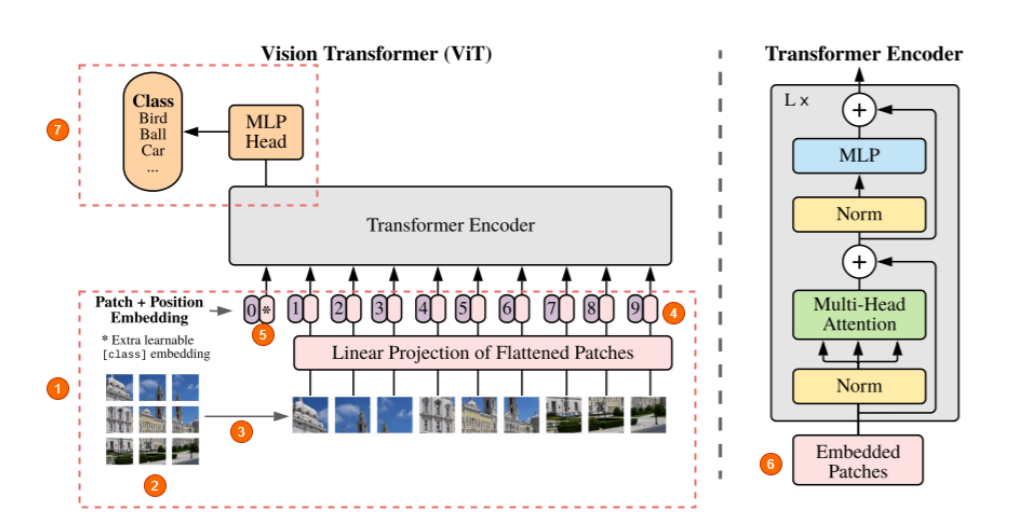
- 只使用transformer的编码器部分,但区别在于如何将图像输入网络
- 将图像分解成固定大小的patches。可以是16x16或32x32,或者更大,但更多的patches意味着随着patches本身变得更小,训练这些网络变得更简单。
- 将patches展开(压平,即将二维转化为一维向量)并发送到网络中进行进一步处理。
- 与神经网络不同,这里的模型对样本在序列中的位置一无所知,这里的每个样本都是来自输入图像的一个patches。因此,图像被连同positional embedding vector一起提供到encoder中。这里需要注意的一点是位置嵌入也是可学习的,所以实际上不需要将硬编码的向量 w.r.t 提供给它们的位置。
- 在开始时还有一个特殊的标记,就像 BERT 一样。
- 将一维(压平)的patches组成一个大矢量,并得到乘以一个embedding矩阵,这也是可学习的,创建embedding patches。将这些与位置向量相结合,输入到transformer中。
- 前馈神经网络MLP Header,并获取到分类输出。
以上为图像级别的Vit构造,Sora的Encoder根据openai的资料来看可能是一个Video transformer,但是作为视频来讲,不同的分辨率输入在训练时候带来的是大量的计算负载不均衡,一个最简单的做法就是直接padding到固定大小这种做大会引入大量不必要的计算量。 从技术报告给出的参考文献来看,openAI最有可能是使用了 Google 的 Patch n’ Pack (NaViT)即多个patches打包成一个单一序列以实现可变分辨率技术降低计算量,支持动态分辨率视频作为输入。
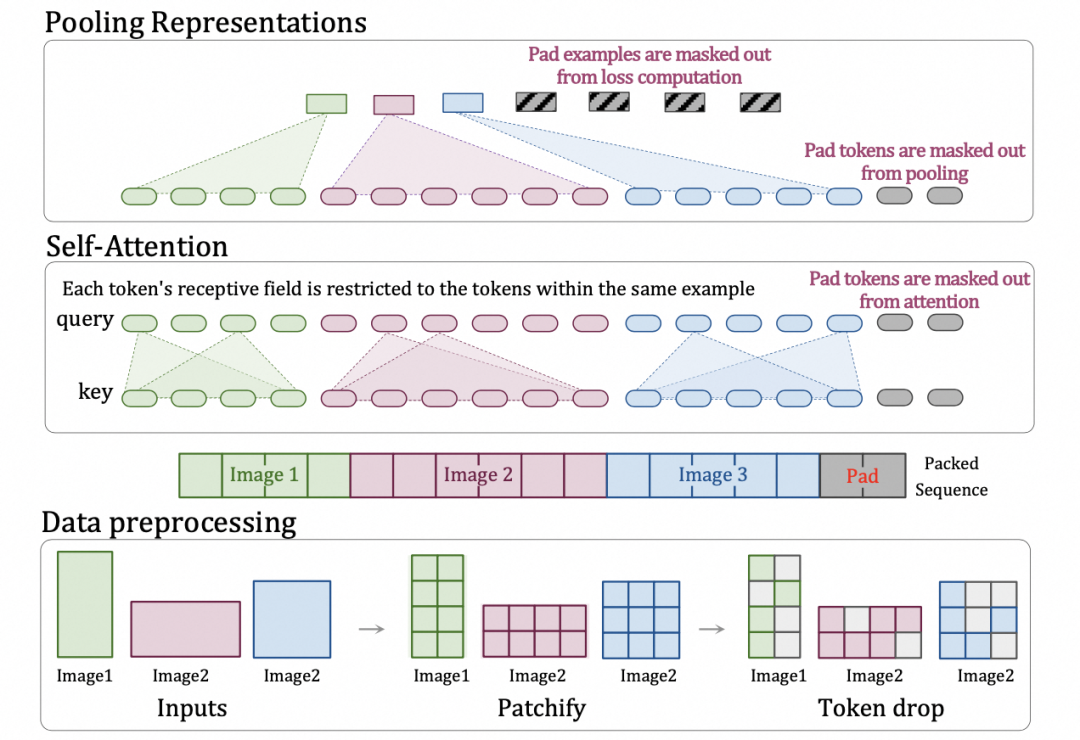
此外NaViT还有一个对视频处理特别关键的优势。它可以根据图像相似度,丢掉雷同的图像块,实现更快的训练。而在视频里,本来帧与帧之间就有大量雷同的图像信息。因此,这样一个技术也可以帮助Sora在训练视频时丢弃掉大量雷同的内容,从而大幅降低训练视频的成本。
那么如何视频数据进行采样呢?有两种方式:
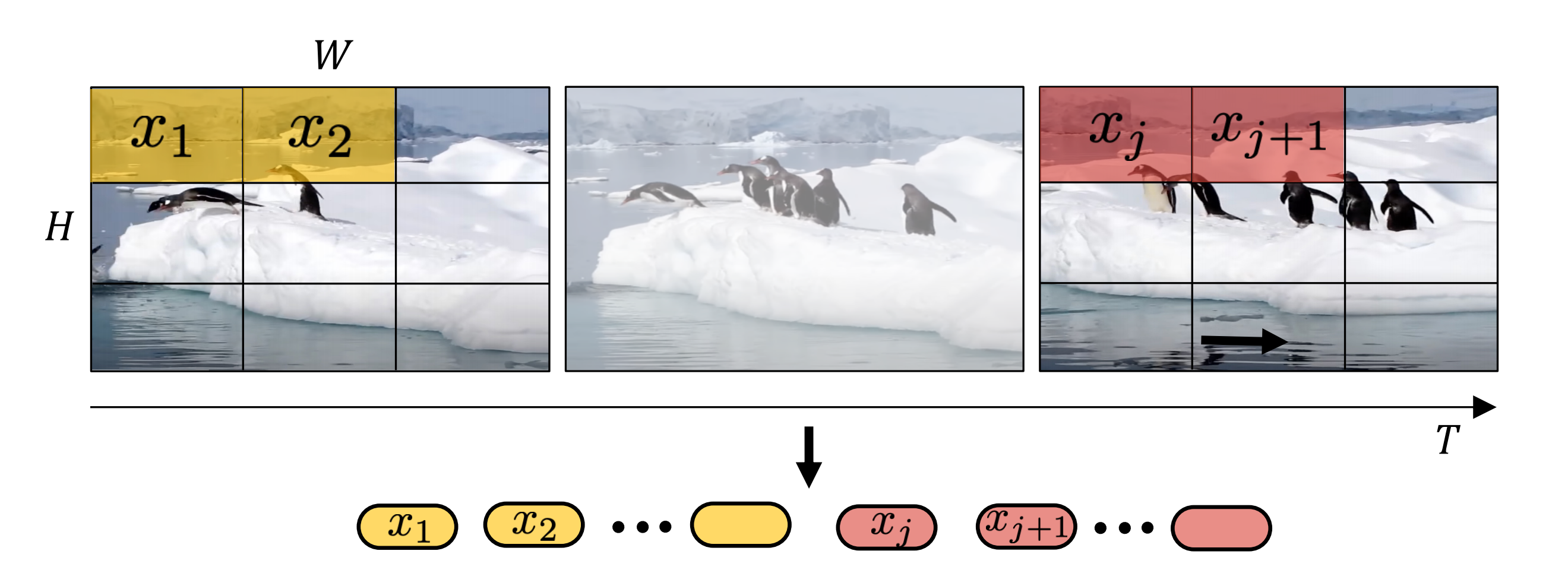
第一种,如下图所示,将输入视频划分为token的直接方法是从输入视频剪辑中均匀采样 n t n_t nt个帧,使用与ViT 相同的方法独立地嵌入每个2D帧(embed each 2D frame independently using the same method as ViT),并将所有这些token连接在一起。
具体地说,如果从每个帧中提取 n h ⋅ n w n_{h} \cdot n_{w} nh⋅nw个非重叠图像块(就像 ViT 一样),那么总共将有 n t ⋅ n h ⋅ n w n_{t} \cdot n_{h} \cdot n_{w} nt⋅nh⋅nw 个token通过transformer编码器进行传递,这个过程可以被看作是简单地构建一个大的2D图像,以便按照ViT的方式进行tokenised:
第二种则是把输入的视频划分成若干个tuplet(类似不重叠的带空间-时间维度的立方体),每个tuplet会变成一个token(因这个tublelt的维度就是: t ∗ h ∗ w t * h * w t∗h∗w 包含了时间、宽、高),经过spatial temperal attention进行空间和时间建模获得有效的视频表征token。
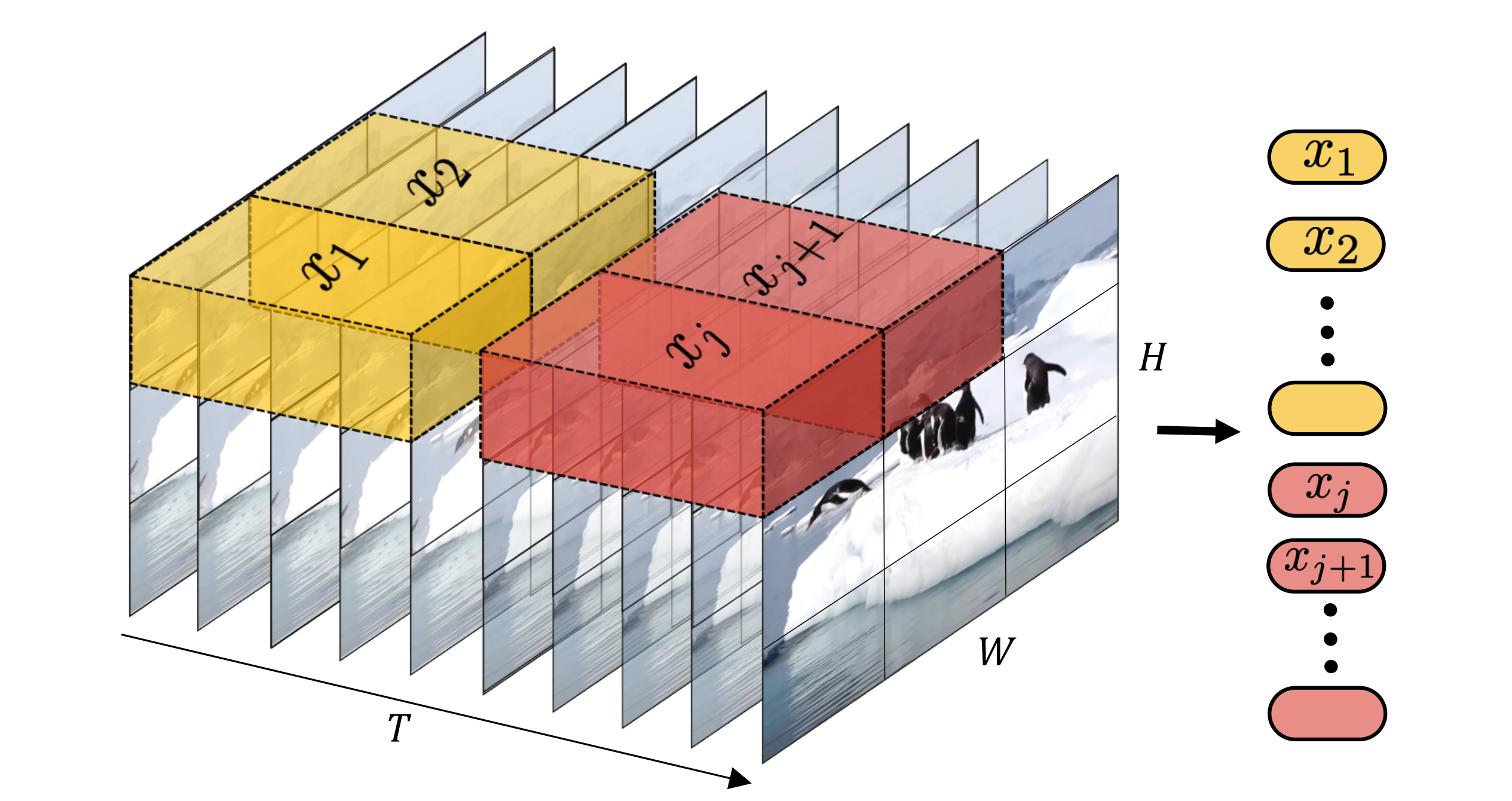
总结以上两种方法为,第一种是时空联合建模,通过spatial-tempral attention直接建模,这种方式在大数据量情况下效果最好,但是对于小的数据集,factorised方法将时间和空间解耦建模,相当于减少模型参数,会更容易训练和效果更好。基于openai大力出奇迹的惯性,我们推测他们采用了大量的数据,采用了时空联合建模的方式,进行了video encoder的训练。
Diffusion Transformer
Sora的主要作者是Peebles William,他在ICCV上发表了一篇DiT的工作,DiT = [VAE编码器 + ViT + DDPM + VAE解码器],但把DPPM中的卷积U-Net架构换成了transformer。这篇工作是通过结合diffusion model和transformer,从而达到可以scale up model来提升图像生成质量的效果,这篇文章是在technical report的reference中给出,直观来讲把图像的scaling技术运用到视频场景也非常直观,可以确定是Sora的技术之一。下图也是openai用以展示训练算力scale up后视频生成质量有所提升。
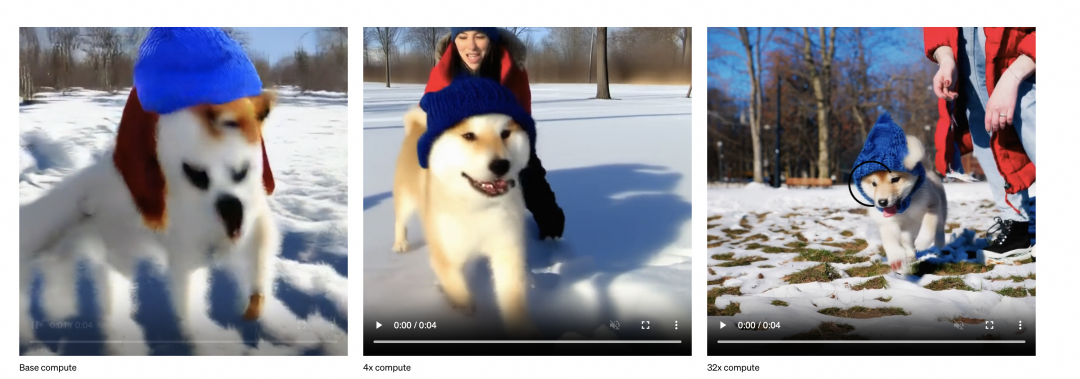
下图展示了Dit的主要原理,输入是一张256x256x3的图片,对图片做切patch后经过投影得到每个patch的token,得到32x32x4的latent(在推理时输入直接是32x32x4的噪声),结合当前的step t, 输入label y作为输入, 经过N个Dit Block通过mlp进行输出,得到输出的噪声以及对应的协方差矩阵,经过T个step采样,得到32x32x4的降噪后的latent。
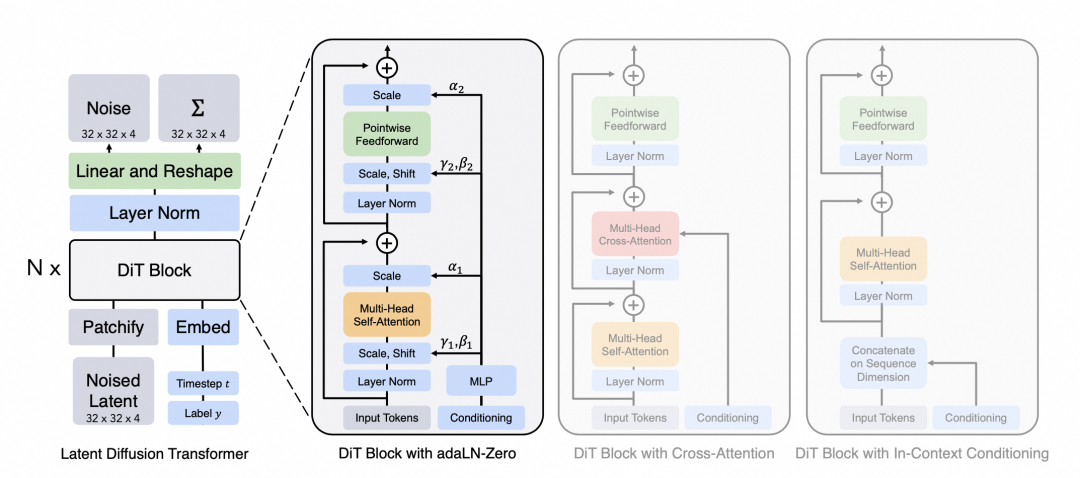
Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023
还存在的技术难点
- 训练数据很重要,具体怎么构建?Transformer Scale up到多大?
- 是从头训练到收敛的trick嘛?
- 如何实现Long Context(长达1分钟的视频)的支持,这里猜测是切断+性能优化?
- 如何保证视频中实体的高质量和一致性?
reference
- https://datawhaler.feishu.cn/wiki/LxSCw0EyRidru1kFkttc1jNQnnh
- 最强文生视频模型 SORA 技术路线解读
- Denoising Diffusion Probabilistic Models(DDPM)