python
python处理数据 struct
kitti数据类型-SemanticKITTI
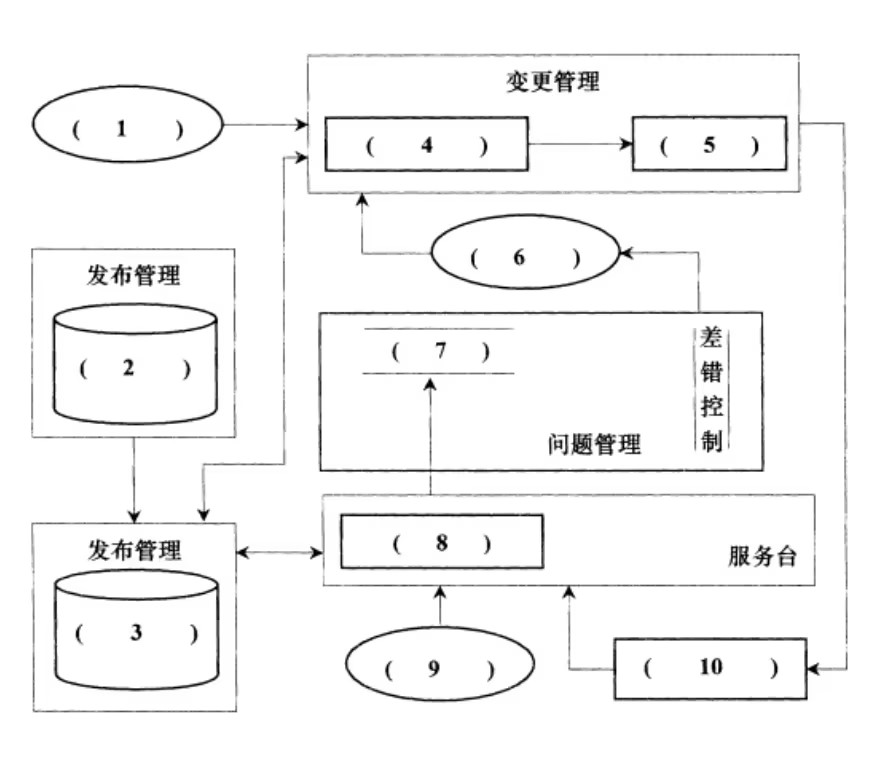
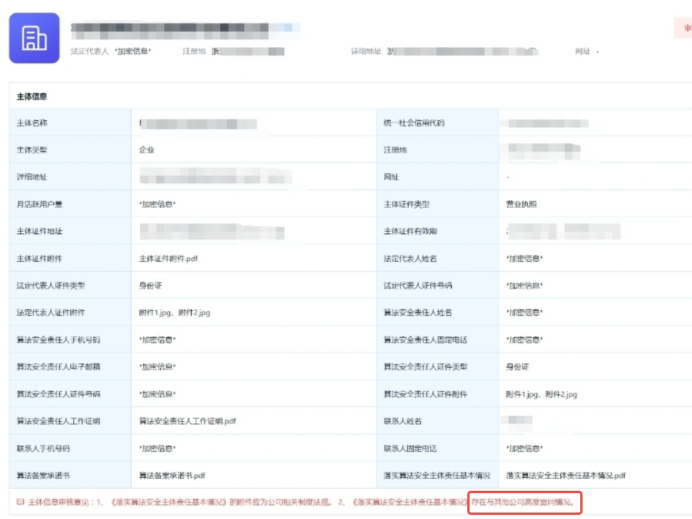
ITTI数据采集平台包括2个灰度摄像机,2个彩色摄像机,一个Velodyne 3D激光雷达,4个光学镜头,以及1个GPS导航系统 数据被保存为.bin文件,并且,每一个点包含3个坐标和反射率信息,即(x,y,z,r),并且数据类型为浮点数类型 KITTI数据集,calib解析 P0 P1 P2 P3 Trvelodyne 存放激光雷达点云数据 labels 分割标注 (其中高16位存放实例分割标注,低16位存放语义分割标注)实例分割(Instance Segmentation) 实例分割不仅要将每个像素归类到某个类别,还要区分同类中的不同个体。语义分割(Semantic Segmentation)The label is a 32-bit unsigned integer (aka uint32_t ) for each pointwhere the lower 16 bits correspond to the label.The upper 16 bits encode the instance id28 个类的逐点注释 不区分骑车人和车辆,而是将车辆和人标记为骑自行车的人或骑摩托车的人循环闭合位姿(the loop closed poses)将点云序列细分为 100 m x 100 m 的图块(tiles)地面(ground)类中,道路(road)、人行道(sidewalk)、建筑物(building)、植被(vegetation)和地形(terrain)
python 大小端
import struct指示打包数据的字节顺序,大小和对齐方式 < 小端I unsigned int 整数 4 打包:arr = [struct.pack('<I', label) for label in labels]with open(filename, "bw") as f:for a in arr:f.write(a)解包 f.seek(0, 2)移动到文件尾位置。 fileObject.seek(offset[, whence])contents = bytes()with open(filename, "rb") as f:f.seek(0, 2) # move the cursor to the end of the filenum_points = int(f.tell() / 4)f.seek(0, 0)contents = f.read()arr = [struct.unpack('<I', contents[4 * i:4 * i + 4])[0] for i in range(num_points)]import sysprint("系统字节序是:", sys.byteorder)多字节数据的字节存放顺序。 ### 大大小小对应是小端,大小大小交叉是大端order是用于指定数组的存储顺序的参数。它通常用于指定多维数组在内存中的布局方式,有两种取值:'C'和'F'。
1)'C'(C order,也称为行优先)
在内存中按行存储数组元素,即按行顺序存储数组的元素,每一行的元素连续存储。这是NumPy默认的存储顺序。
2)'F'(Fortran order,也称为列优先)在内存中按列存储数组元素,即按列顺序存储数组的元素,每一列的元素连续存储 C++编译器可能会在结构体成员之间添加填充字节(padding),以优化内存访问。这会影响到结构体的整体大小和每个成员的偏移量于字符数组(如char name[20];),在Python中解码前可能需要去除末尾的null字符(\x00)。
参考
https://mmdetection3d.readthedocs.io/zh-cn/latest/advanced_guides/datasets/semantickitti.html https://blog.csdn.net/BIT_HXZ/article/details/124027659https://github.com/jbehley/point_labeler/blob/master/scripts/repair_labels.py如何将自定义点云转换成semanticKitti格式 https://blog.csdn.net/weixin_42628609/article/details/134339866