目录
- 一. Sora能力
- 二. Sora训练流程
- 1. Visusal encoder
- 2. Diffusion Transformer
- 3. Transformer Decoder
一. Sora能力
- 长视频:最大可支持60s高清视频生成
- 保持人物与场景高度统一
- 视频融合能力强
- 同一场景多角度/多镜头
- 涌现:随着运动镜头的变化,人与场景在三维空间中一致移动
- 支持任意分辨率,宽高比的视频输出
但是,Sora并没能完全达到理解物理世界的能力
二. Sora训练流程
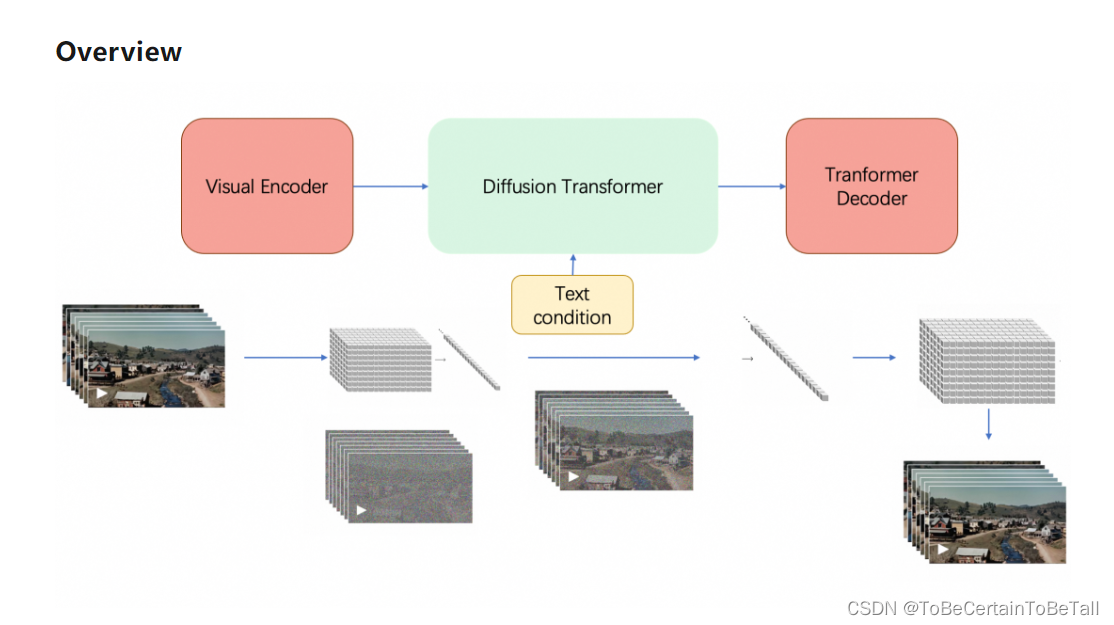
1. Visusal encoder
将原始的视频数据(NxHxW的若干帧图像)切分成一小块一小块的patch通过VAE编码器,压缩成低维空间表示,提取特征flatten操作拉平为一维数据patch被送入diffusion model
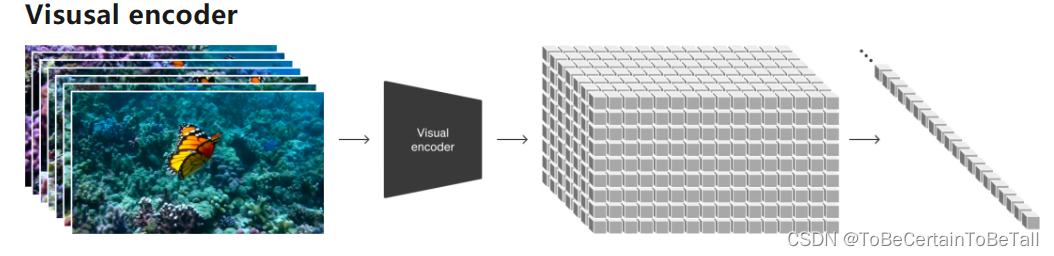
视频数据经过一个Visusal encoder的编辑器,将所有的数据做成一个灰色的block
这个block可以存储在spatial temperal patch中,其中patch含有视频空间和时间的表征
2. Diffusion Transformer
基于文本语义到图像语义的再映射
相当于输入一个promote提示词后,即文本语义基于文本语义做出一个相对于图片的映射最后根据映射生成的图片再去组成一个一维的视频数据
3. Transformer Decoder
Diffusion Transformer生成的低维空间通过VAE解码器恢复成像素级的视频数据
Reference:
【一文看Sora技术推演 作者:周文猛 魔搭社区】
【📖学习手册】
【sora技术原理详解回放】