前言
不同于常见的 LRU 或 LFU,Window TinyLFU 是一种非常高效的缓存设计方案。先来看下 LRU 和 LFU 算法的缺点:
LFU 缺点:
- 需要为每个记录项维护频率信息,这将消耗大量的内存空间
- 可能存在旧数据长期不被淘汰(一开始频繁访问该数据,后来不访问了,也不被淘汰占用缓存)
LRU 缺点:
- 不能反馈访问频率,对热点数据的命中率不如 LFU
W-TinyLFU 综合了两者的长处:高命令率、低内存占用。
参考链接:
- Caffeine 详解 —— Caffeine 的 Window TinyLfu
- 论文《TinyLFU: A Highly Ecient Cache Admission Policy》阅读笔记
W-TinyLFU 的基础 TinyLFU
TinyLFU 是一种空间利用率很高的数据结构,可以在较大访问量的场景下近似的替代 LFU 的频率统计信息。
它的原理与 BloomFilter 类似,把多个 bit 位看作一个整体,用来统计一个 key 的使用频率,TinyLFU 中的 key 通过多次不同的 hash 计算映射到多个 bit 组。在读取时,取映射的所有值中的最小的值作为 key 的使用频率。
在 Caffeine 中,维护了一个 4-bit CountMinSketch 来记录 key 的使用频率,这意味着 key 最大使用频率为 15。
为了可以移除旧事件,TinyLFU 还采用一种衰减机制,借助 reset 操作:每次 get 数据时都会给计数器加上 1,当计数器到达一个尺寸 W 时,把所有记录的 Sketch 数值都除以 2。
W-TinyLFU 的窗口设计
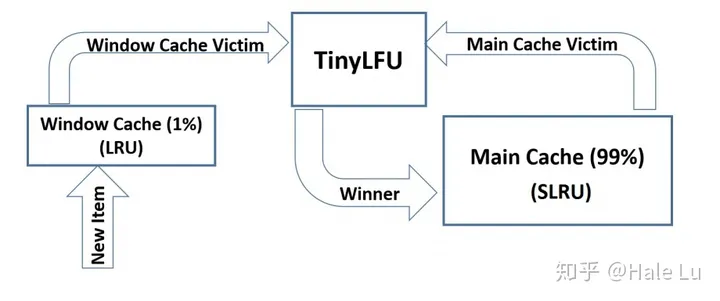
然而在对同一对象的「稀疏突发」的场景下,TinyLFU 会出现问题。在这种情况下,突发的 key 无法建立足够的频率以保存在缓存中,从而导致不断的 cache miss。Caffeine 通过设计 W-TinyLFU 的策略(包含两个缓存区域)解决了这个问题。
主缓存(main cache)使用 SLRU 逐出策略和 TinyLFU 准入策略(TinyLFU 的准入和淘汰策略是:新增一个元素时,判断使用该元素替换一个旧元素,是否可以提升缓存命中率),而窗口缓存(window cache)采用 LRU 逐出策略而没有任何准入策略。
主缓存根据 SLRU 策略静态划分为 A1 和 A2 两个区域,80% 的空间分配给热门项目(A2),并从 20% 非热门项目中挑选 victim。所有请求的 key 都会被允许进入窗口缓存,而窗口缓存的 victim 则有机会进入主缓存(主缓存没满直接进入;满了的话,比较窗口缓存的 victim 和非热门项目的 victim 的出现频率,留下较高的内个)。
窗口缓存的大小初始为总缓存大小的 1%,主缓存的大小为 99%。
W-TinyLFU 方案如下所示:
具体实现
LRU
以下是代码实现,只有重要部分:
这就是传统的 LRU,需要注意的是当满了再 add 时,没有直接将链表末尾元素删除,再将新元素添加到链表头部,而是采用了交换的方式,减少了内存的申请次数。
type windowLRU struct {data map[uint64]*list.Element // key 到相应元素的映射cap int // lru 容量list *list.List
}type storeItem struct {stage intkey uint64value interface{}
}// 向窗口 LRU 添加数据
func (lru *windowLRU) add(newitem storeItem) (eitem storeItem, evicted bool) {// 没满直接插入if lru.list.Len() < lru.cap {lru.data[newitem.key] = lru.list.PushFront(&newitem)return storeItem{}, false}// 满了的话需要淘汰链表最后一个evictItem := lru.list.Back()item := evictItem.Value.(*storeItem)// 在哈希表中删除淘汰的元素delete(lru.data, item.key)// 通过交换,链表最后一个元素内容变为要插入的 newitemeitem, *item = *item, newitemlru.data[item.key] = evictItemlru.list.MoveToFront(evictItem)return eitem, true
}func (lru *windowLRU) get(v *list.Element) {lru.list.MoveToFront(v)
}
SLRU
以下是代码实现,只有重要部分:
这是一个分段 LRU 实现,添加元素时先添加到非热门区域,当被 get 时再提升到热门区域。
type segmentedLRU struct {data map[uint64]*list.ElementstageColdCap, stageHotCap intstageCold, stageHot *list.List
}const (STAGE_COLD = iotaSTAGE_HOTSTAGE_WINDOW
)func (slru *segmentedLRU) add(newitem storeItem) {// 默认插入到非热门区域newitem.stage = STAGE_COLD// 主缓存还没满,直接插入if slru.stageCold.Len() < slru.stageColdCap || slru.Len() < slru.stageColdCap+slru.stageHotCap {slru.data[newitem.key] = slru.stageCold.PushFront(&newitem)return}// 满了的话需要淘汰非热门链表的最后一个e := slru.stageCold.Back()item := e.Value.(*storeItem)// 在哈希表中删除淘汰的元素delete(slru.data, item.key)// 直接覆盖链表中的元素*item = newitemslru.data[item.key] = eslru.stageCold.MoveToFront(e)
}func (slru *segmentedLRU) get(v *list.Element) {item := v.Value.(*storeItem)// 已经在热门区域了,提到链表头部即可if item.stage == STAGE_HOT {slru.stageHot.MoveToFront(v)return}// 不在热门区域,但热门区域还有空间if slru.stageHot.Len() < slru.stageHotCap {slru.stageCold.Remove(v)item.stage = STAGE_HOTslru.data[item.key] = slru.stageHot.PushFront(item)return}// 此时,既不在热门区域,热门区域也没空间了// 需要将热门链表最后一个下放到非热门区域back := slru.stageHot.Back()bitem := back.Value.(*storeItem)*bitem, *item = *item, *bitembitem.stage = STAGE_HOTitem.stage = STAGE_COLDslru.data[item.key] = vslru.data[bitem.key] = backslru.stageCold.MoveToFront(v)slru.stageHot.MoveToFront(back)
}// 获取将淘汰的元素
func (slru *segmentedLRU) victim() *storeItem {if slru.Len() < slru.stageColdCap+slru.stageHotCap {return nil}v := slru.stageCold.Back()return v.Value.(*storeItem)
}
Count-Min Sketch
以下是代码实现,只有重要部分:
const (cmWidth = 4
)type cmSketch struct {rows [cmWidth]cmRowseed [cmWidth]uint64mask uint64
}func newCmSketch(numCounters int64) *cmSketch {// next2Power 获取最接近 numCounters 的 2 的幂numCounters = next2Power(numCounters)sketch := &cmSketch{mask: uint64(numCounters - 1)}source := rand.New(rand.NewSource(time.Now().UnixNano()))for i := 0; i < cmWidth; i++ {sketch.seed[i] = source.Uint64()sketch.rows[i] = newCmRow(numCounters)}return sketch
}func (s *cmSketch) Increment(hashed uint64) {for i := range s.rows {s.rows[i].increment((hashed ^ s.seed[i]) & s.mask)}
}// 获取出现次数近似值
func (s *cmSketch) Estimate(hashed uint64) int64 {min := byte(255)for i := range s.rows {val := s.rows[i].get((hashed ^ s.seed[i]) & s.mask)if val < min {min = val}}return int64(min)
}func (s *cmSketch) Reset() {for _, r := range s.rows {r.reset()}
}func (s *cmSketch) Clear() {for _, r := range s.rows {r.clear()}
}type cmRow []byte// 为每个计数分配 4 位
func newCmRow(numCounters int64) cmRow {return make(cmRow, numCounters/2)
}// 获取指定位置计数
func (r cmRow) get(n uint64) byte {// n/2 定位到相应字节// (n & 1) * 4 奇数为 4 偶数为 0return r[n/2] >> ((n & 1) * 4) & 0x0f
}// 增加指定位置计数
func (r cmRow) increment(n uint64) {i := n / 2s := (n & 1) * 4v := (r[i] >> s) & 0x0fif v < 15 {r[i] += 1 << s}
}// 减少为原来一半
func (r cmRow) reset() {for i := range r {r[i] = (r[i] >> 1) & 0x77}
}// 全部清空
func (r cmRow) clear() {for i := range r {r[i] = 0}
}
Cache
以下是代码实现,只有重要部分:
type Cache struct {lru *windowLRUslru *segmentedLRUc *cmSketcht int32 // 计数器threshold int32 // 用来记录临界值,当计数器等于临界值时调用 resetdata map[uint64]*list.Element
}func NewCache(size int) *Cache {const lruPct = 1lruSz := (lruPct * size) / 100slruSz := int(float64(size) * ((100 - lruPct) / 100.0))slruO := int(0.2 * float64(slruSz))data := make(map[uint64]*list.Element, size)return &Cache{lru: newWindowLRU(lruSz, data),slru: newSLRU(data, slruO, slruSz-slruO),c: newCmSketch(int64(size)),data: data,}
}func (c *Cache) set(key, value interface{}) bool {keyHash := c.keyToHash(key)i := storeItem{stage: STAGE_COLD,key: keyHash,value: value,}// 先向窗口 LRU 中插入eitem, evicted := c.lru.add(i)// 没有数据被淘汰,插入完成if !evicted {return true}// 有数据被淘汰,看主缓存中是否有数据被淘汰victim := c.slru.victim()// 没有的话,直接插入主缓存if victim == nil {c.slru.add(eitem)return true}// 此时说明主缓存满了,也有数据被淘汰// 比较窗口 lru 和 slru 淘汰的数据的频率,保留频率多的vcount := c.c.Estimate(victim.key)ocount := c.c.Estimate(eitem.key)if ocount < vcount {return true}c.slru.add(eitem)return true
}func (c *Cache) get(key interface{}) (interface{}, bool) {c.t++// 计数器到达临界时后,调用 Reset()if c.t == c.threshold {c.c.Reset()c.t = 0}keyHash := c.keyToHash(key)val, _ := c.data[keyHash]item := val.Value.(*storeItem)c.c.Increment(item.key)v := item.value// 调用相应部分的 get,提到链表的头部if item.stage == STAGE_WINDOW {c.lru.get(val)} else {c.slru.get(val)}return v, true
}