【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
如果最终部署在客户现场的是一个嵌入式设备,那么上位机在做好了算法编辑和算法部署之后,很重要的一步就是处理上位机和下位机之间的通讯了。当然,我们可以通过一些开源库来解决通信问题,比如xmlrpc。但是,我们有时候可能需要自定义协议来处理。自定义协议还是有很多好处的,比如说你的嵌入式设备只能和你的上位机进行通信。
这样如果是自定义协议的话,那么有三个注意点就要小心一下。
1、CPU大小端
目前我们的笔记本电脑、台式机都是x86或者x64 cpu,这些cpu都是小端结构。而报文协议一般都是大端结构。所谓的小端、大端,主要代表了数据字节的存储次序。举个例子来说,如果有一个整数是0x12345678,那么0x78如果保存在低端地址,那么cpu就是小端;如果0x12保存在低端地址,那么cpu就是大端。写成函数就是这样的,
bool isCpuLittleEndian()
{unsigned int val = 0x12345678;unsigned char* p = (unsigned char*)&val;return (*p == 0x78) ? true : false;
}既然是这样,那我们在编写报文的时候,就需要把数据从小端转成大端结构。等到收到报文、解析报文的时候,再把数据从大端解析成小端。这个过程都是少不了的。
2、数据补齐
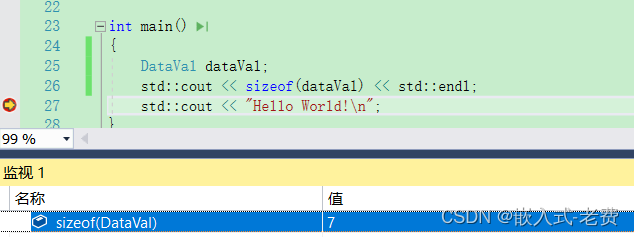
很多时候,编译器考虑到cpu访问数据的效率和便利,会有意、无意帮我们做数据对齐的动作。这些动作如果在平时,通常关系不大。但是通信的时候,我们的报文是要和别人的设备做数据交接的,这种情况下一个byte的偏移都是不应该的。所以,在上下文交互的时候,这种数据补齐必须是要避免发生的。举个例子来说,下面这个结构体,
typedef struct _DataVal
{short a;char b;int c;
}DataVal;如果不做特殊处理的话,这个数据结构体的大小就是8。但是实际大小应该是7。因为short长度是2,char长度是1,int长度是4,所以整体长度是7。这个时候,如果我们不想编译器帮助我们做数据补齐,应该怎么处理呢,
#pragma pack(1)
typedef struct _DataVal
{short a;char b;int c;
}DataVal;
#pragma unpack这个语法目前在visual studio和gdb上都是支持的,大家自己可以好好测试下。通过测试,我们可以清楚地看到,加了pack之后,DataVal的大小是7。
3、json数据的使用
早期协议开发的时候,特别是协议还没有稳定的时候,临时增添数据、减少数据,这都是很常见的事情。另外,即使协议比较稳定,添加新的客户需求,变更协议,这也不罕见。所以,建议大家可以在协议开发的时候,对于其中一部分内容,可以考虑用json保存和传递,还不用考虑字节序的问题。比如说,发送前,把json转成字节码。收到报文后,再恢复为json数据。虽然传输的效率效率有所降低,但是胜在稳定,易于拓展。朋友们可以在开发的过程中参考下。