1、首先阅读了hrnet的网络结构分析,了解到了网络构造如下:
参考博文姿态估计之2D人体姿态估计 - (HRNet)Deep High-Resolution Representation Learning for Human Pose Estimation(多家综合)-CSDN博客
最重要的就是这个图了:
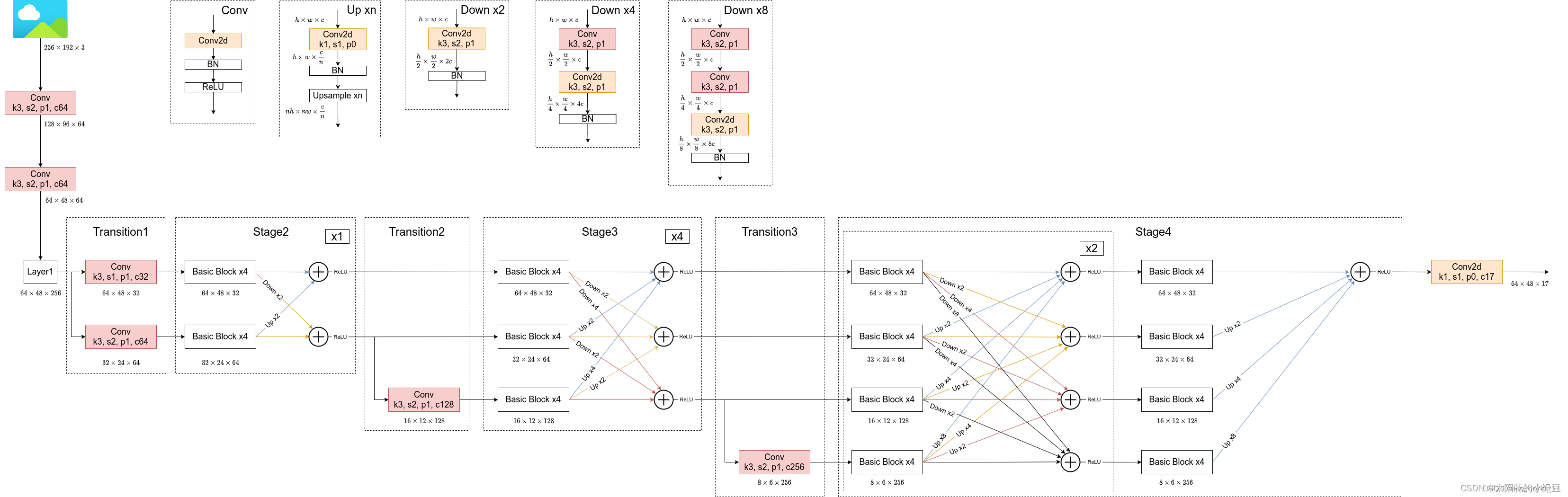
在这里主要是注释自己对这个图的认识和理解:
在RGB图片(256*192*3)输入主干网络之前先经过了两次conv卷积网络(包含3*3的卷积层和归一层,激活函数relu),然后就来到了layer1(主要是改变了通道数,通过重复堆叠Bottleneck来实现),然后进行两个层次的特征处理,一个是向下进行二倍采样,一个是直接过来,这就形成了所谓的不同维度的特征信息,然后进行融合,因为它们的通道数并不相同,所以就需要进行下采样(down),和上采样(up),具体这两个网络结构也已经放出来了。然后就是将前面得到的不同维度的特征信息融合·,输入到下一层里面。按照这个流程做下去,到最后,也就是stage4的时候,进行最后一次的多维度的特征信息融合,然后输入到最后一个卷积里面,这个卷积主要是输出17个关键点的预测信息,所以可以看到那里是C17(17个通道)也相当于17个卷积核(1*1的)。
然后图片里面的
k3, s2, p1, 和 c64 通常是卷积层的超参数,它们分别代表:
k3:这通常指的是卷积核(kernel)的大小。k3 表示卷积核的大小为 3x3,即宽度和高度都是3。
s2:这是步长(stride)的参数。s2 表示卷积操作的步长为2。步长决定了卷积核在输入特征图上滑动时,每次移动的像素数量。
p1:这是填充(padding)的参数。p1 表示在输入特征图的边界周围填充1个像素。填充通常用于控制输出特征图的大小,以及确保在特征图的边缘信息不会被丢失。
c64:这指的是输出通道数(number of output channels)。c64 表示该卷积层有64个输出通道,即卷积操作会产生64个不同的特征图。
其中输出通道数C64是和卷积核相对应的,有多少个卷积核就有多少个输出通道。
我去学习,看了一哈paddledetection里面的,发现有使用paddle实现HRNet网络,于是我就打算进行复现,训练出自己想要的模型效果,
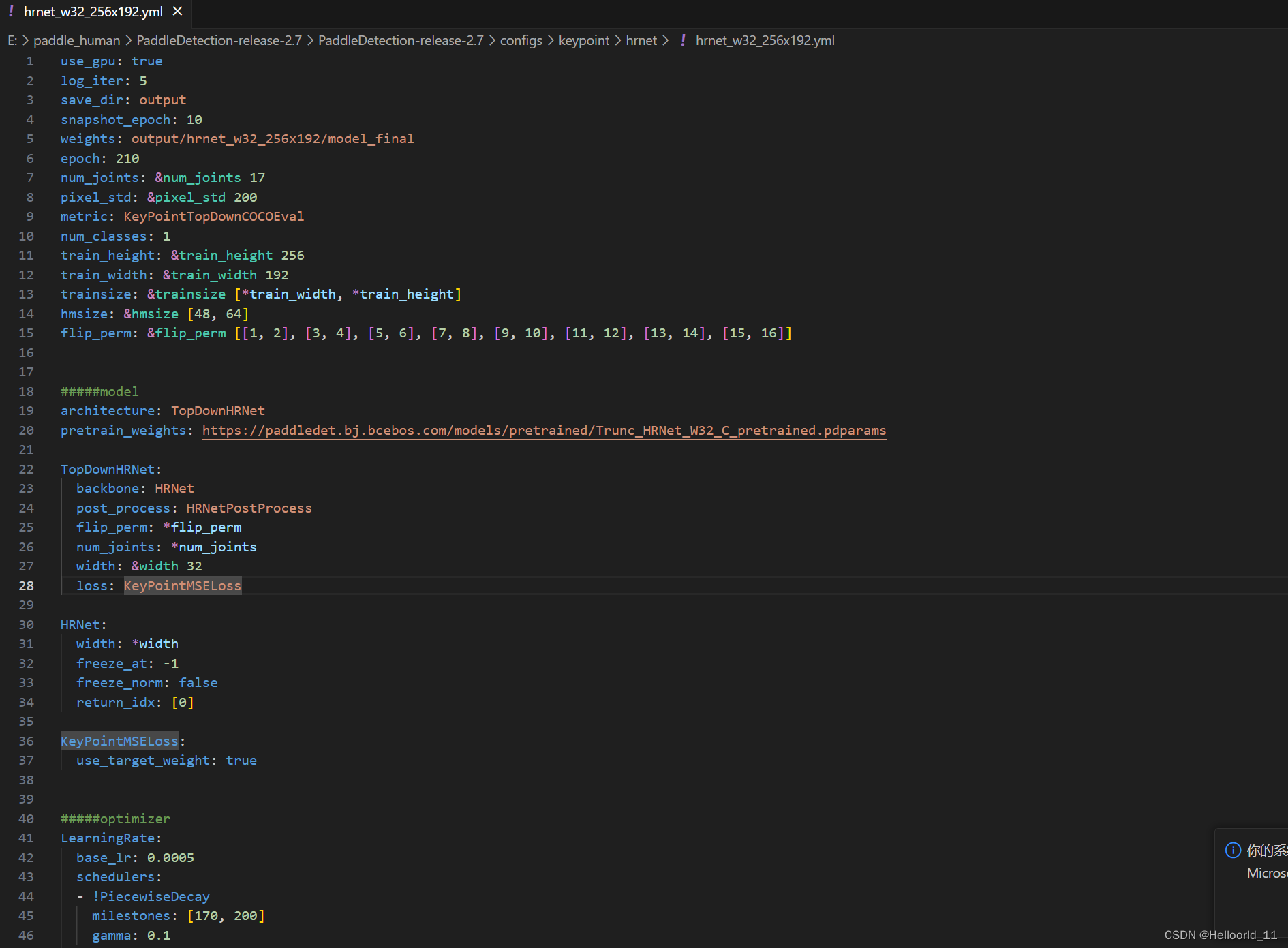
值得一提的是这个hrnetpostprocess的代码的实现,运用了中心点+尺度因子+热力图的关系,来改变固定预测关键点是整数值。
class HRNetPostProcess(object):def __init__(self, use_dark=True):self.use_dark = use_darkdef get_max_preds(self, heatmaps):'''get predictions from score maps
该类主要用于从热图(heatmaps)中获取预测的关键点坐标和对应的最大置信度Args:heatmaps: numpy.ndarray([batch_size, num_joints, height, width])heatmaps是一个四维数组 batch_size是批处理大小,num_joints是关键点的数量,height和width是热图的高度和宽度Returns:preds: numpy.ndarray([batch_size, num_joints, 2]), keypoints coordsmaxvals: numpy.ndarray([batch_size, num_joints, 2]), the maximum confidence of the keypoints输出:两个numpy数组,preds和maxvals。preds的形状为[batch_size, num_joints, 2],表示每个关键点的坐标;maxvals的形状也为[batch_size, num_joints, 1],表示每个关键点的最大置信度。'''assert isinstance(heatmaps,np.ndarray), 'heatmaps should be numpy.ndarray'assert heatmaps.ndim == 4, 'batch_images should be 4-ndim'#检查heatmaps是否是4维的batch_size = heatmaps.shape[0]num_joints = heatmaps.shape[1]width = heatmaps.shape[3]heatmaps_reshaped = heatmaps.reshape((batch_size, num_joints, -1))#代码重新整形heatmaps,使其从[batch_size, num_joints, height, width]变为[batch_size, num_joints, height*width]idx = np.argmax(heatmaps_reshaped, 2)#使用np.argmax获取每个位置的最大值的索引,这对应于每个关键点在热图中的位置。maxvals = np.amax(heatmaps_reshaped, 2)#使用np.amax获取每个位置的最大值,这对应于每个关键点的置信度。# 将maxvals和idx重新整形为[batch_size, num_joints, 1]maxvals = maxvals.reshape((batch_size, num_joints, 1))idx = idx.reshape((batch_size, num_joints, 1))preds = np.tile(idx, (1, 1, 2)).astype(np.float32)#使用np.tile复制idx的每一行和每一列,生成一个新的三维数组preds[:, :, 0] = (preds[:, :, 0]) % width #对这个新数组的第三列(即每个关键点的x坐标)进行模运算,以确保其值在[0, width)范围内preds[:, :, 1] = np.floor((preds[:, :, 1]) / width)#对新数组的第二列(即每个关键点的y坐标)进行整除运算,然后取整,以获取每个关键点的y坐标。pred_mask = np.tile(np.greater(maxvals, 0.0), (1, 1, 2))#创建一个掩码pred_mask,其中最大置信度大于0的位置为1,否则为0。pred_mask = pred_mask.astype(np.float32)#使用pred_mask将preds中置信度不为0的位置设置为0。preds *= pred_mask#preds *= pred_mask这一行,实际上是将那些置信度不大于0的关键点坐标设置为0。这可能是为了确保只返回那些有足够置信度的预测结果。return preds, maxvalsdef gaussian_blur(self, heatmap, kernel):#对热力图进行高斯模糊border = (kernel - 1) // 2#根据核大小计算边界大小,用于扩展热图以处理边界效应batch_size = heatmap.shape[0]num_joints = heatmap.shape[1]height = heatmap.shape[2]width = heatmap.shape[3]for i in range(batch_size):#遍历批处理中的每个热图:对于每个热图,遍历每个关键点。for j in range(num_joints):origin_max = np.max(heatmap[i, j])dr = np.zeros((height + 2 * border, width + 2 * border))dr[border:-border, border:-border] = heatmap[i, j].copy()#将原始热图扩展,以便在应用高斯模糊时不会丢失边界信息dr = cv2.GaussianBlur(dr, (kernel, kernel), 0)#使用OpenCV的GaussianBlur函数对扩展的热图进行高斯模糊heatmap[i, j] = dr[border:-border, border:-border].copy()#还原热图:将模糊后的热图裁剪回原始大小。heatmap[i, j] *= origin_max / np.max(heatmap[i, j])#确保模糊后的热图的最大值与原始热图的最大值相同。return heatmapdef dark_parse(self, hm, coord):#两个参数:hm(一个二维numpy数组,表示一个关键点的热图)和coord(一个包含x和y坐标的列表或元组)heatmap_height = hm.shape[0]heatmap_width = hm.shape[1]px = int(coord[0])py = int(coord[1])if 1 < px < heatmap_width - 2 and 1 < py < heatmap_height - 2:#确保提供的坐标位于热图的有效范围内dx = 0.5 * (hm[py][px + 1] - hm[py][px - 1])#计算梯度和Hessian矩阵:基于热图在给定坐标周围的像素值,计算梯度(dx, dy)和Hessian矩阵(dxx, dxy, dyy)。dy = 0.5 * (hm[py + 1][px] - hm[py - 1][px])dxx = 0.25 * (hm[py][px + 2] - 2 * hm[py][px] + hm[py][px - 2])dxy = 0.25 * (hm[py + 1][px + 1] - hm[py - 1][px + 1] - hm[py + 1][px - 1] \+ hm[py - 1][px - 1])dyy = 0.25 * (hm[py + 2 * 1][px] - 2 * hm[py][px] + hm[py - 2 * 1][px])derivative = np.matrix([[dx], [dy]])hessian = np.matrix([[dxx, dxy], [dxy, dyy]])if dxx * dyy - dxy ** 2 != 0:#如果Hessian矩阵的行列式不为零(确保Hessian矩阵非奇异),则使用计算出的偏移量更新原始坐标。hessianinv = hessian.Ioffset = -hessianinv * derivativeoffset = np.squeeze(np.array(offset.T), axis=0)coord += offsetreturn coorddef dark_postprocess(self, hm, coords, kernelsize):#hm(热图),coords(关键点的初步坐标),和kernelsize(高斯模糊核的大小)'''DARK postpocessing, Zhang et al. Distribution-Aware CoordinateRepresentation for Human Pose Estimation (CVPR 2020).'''hm = self.gaussian_blur(hm, kernelsize)#进行高斯模糊hm = np.maximum(hm, 1e-10)#为了确保数值稳定性,热图中的值被限制为最小为 1e-10hm = np.log(hm)#对热图应用对数变换for n in range(coords.shape[0]):for p in range(coords.shape[1]):coords[n, p] = self.dark_parse(hm[n][p], coords[n][p])#对于每一个初步坐标,使用 dark_parse 函数来修正坐标return coordsdef get_final_preds(self, heatmaps, center, scale, kernelsize=3):"""the highest heatvalue location with a quarter offset in thedirection from the highest response to the second highest response.Args:heatmaps (numpy.ndarray): The predicted heatmapscenter (numpy.ndarray): The boxes centerscale (numpy.ndarray): The scale factorReturns:preds: numpy.ndarray([batch_size, num_joints, 2]), keypoints coordsmaxvals: numpy.ndarray([batch_size, num_joints, 1]), the maximum confidence of the keypoints"""coords, maxvals = self.get_max_preds(heatmaps)#使用 get_max_preds 函数从热图中获取初步的关键点坐标和最大置信度heatmap_height = heatmaps.shape[2]#获取热图的高度和宽度heatmap_width = heatmaps.shape[3]#if self.use_dark:#如果启用了 use_dark,则使用 dark_postprocess 函数对坐标进行后处理。否则,对于每个初步坐标,如果它不在热图的边界内,则根据热图在该点的梯度进行简单的偏移coords = self.dark_postprocess(heatmaps, coords, kernelsize)else:for n in range(coords.shape[0]):#将修正后的坐标复制到 preds 变量中。for p in range(coords.shape[1]):hm = heatmaps[n][p]px = int(math.floor(coords[n][p][0] + 0.5))py = int(math.floor(coords[n][p][1] + 0.5))if 1 < px < heatmap_width - 1 and 1 < py < heatmap_height - 1:diff = np.array([hm[py][px + 1] - hm[py][px - 1],hm[py + 1][px] - hm[py - 1][px]])coords[n][p] += np.sign(diff) * .25preds = coords.copy()# Transform back 将关键点坐标从热图的空间转换回原始图像的空间for i in range(coords.shape[0]):preds[i] = transform_preds(coords[i], center[i], scale[i],[heatmap_width, heatmap_height])#根据每个图像的中心点(center)、尺度因子(scale)以及热图的尺寸(heatmap_width 和 heatmap_height)来调整坐标return preds, maxvalsdef __call__(self, output, center, scale):preds, maxvals = self.get_final_preds(output.numpy(), center, scale)#获得最终的预测结果"""将 preds 和 maxvals 沿着最后一个维度(axis=-1)进行连接。这意味着如果 preds 的形状是 (batch_size, num_joints, 2)(每个关键点的二维坐标),而 maxvals 的形状是 (batch_size, num_joints, 1)(每个关键点的最大置信度),那么连接后的结果将具有形状 (batch_size, num_joints, 3),其中最后一列是每个关键点的最大置信度。np.mean(maxvals, axis=1) 计算 maxvals 沿着第二个维度(axis=1)的均值。这通常用于获取每个图像(或批次中的每个样本)上所有关键点置信度的平均值。"""outputs = [[np.concatenate((preds, maxvals), axis=-1), np.mean(maxvals, axis=1)]]return outputs#连接后的 preds 和 maxvals 可以直接用于可视化,而 maxvals 的均值则可以用于评估模型的整体性能


![[项目设计] 从零实现的高并发内存池(二)](https://img-blog.csdnimg.cn/c446ebae288e480d84f5d14d494c88bb.gif)