混淆矩阵(confusion matrix)——
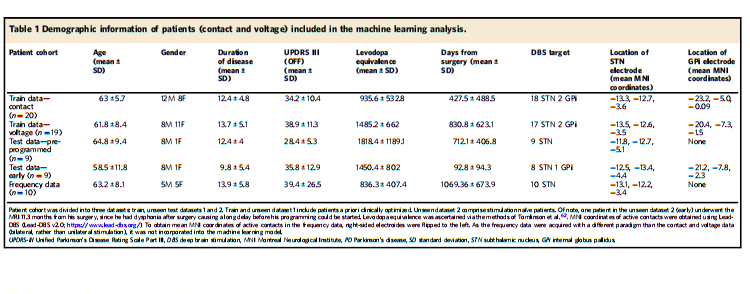
混淆矩阵(Confusion Matrix)是人工智能领域,特别是在机器学习和深度学习中,用于衡量分类模型性能的重要工具。它通过统计分类模型的真实分类与预测分类之间的结果,以矩阵的形式展示模型的性能。以下将详细阐述混淆矩阵的定义、相关概念、解决的问题、使用场景、工具以及步骤。
一、混淆矩阵的定义
混淆矩阵是一个N×N的矩阵(N为类别的数量),用于展示分类模型的预测结果与真实结果之间的对应关系。矩阵的每一行代表实际类别,每一列代表预测类别。矩阵中的元素表示实际类别与预测类别之间的样本数量。
二、相关概念
- 真正例(True Positive, TP):实际为正例且被模型正确预测为正例的样本数。
- 假正例(False Positive, FP):实际为负例但被模型错误预测为正例的样本数。
- 真负例(True Negative, TN):实际为负例且被模型正确预测为负例的样本数。
- 假负例(False Negative, FN):实际为正例但被模型错误预测为负例的样本数。

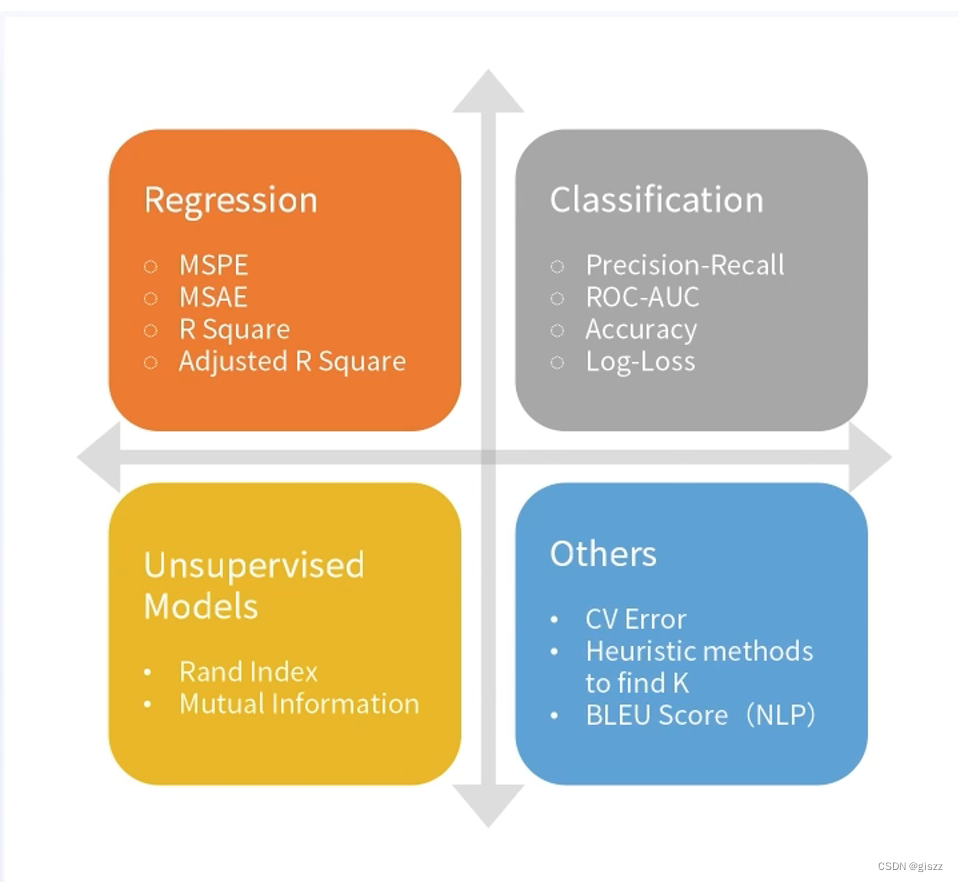
基于这些基本指标,可以进一步计算出以下重要的评估指标:
- 准确率(Accuracy):所有预测正确的样本占总样本的比例。
- 精确率(Precision):预测为正例的样本中真正为正例的比例。
- 召回率(Recall),又称真正例率(True Positive Rate):实际为正例的样本中被正确预测为正例的比例。
- F1 分数(F1 Score):精确率和召回率的调和平均数,用于综合评价模型的性能。
三、解决的问题
混淆矩阵主要解决了分类模型性能评估的问题。通过混淆矩阵,我们可以直观地了解模型在各类别上的表现,包括正确预测和错误预测的情况。此外,混淆矩阵还提供了计算其他评估指标的基础数据,如准确率、精确率、召回率等,这些指标有助于更全面地评估模型的性能。
四、使用场景
混淆矩阵广泛应用于各种分类任务中,如图像识别、文本分类、语音识别等。在这些场景中,混淆矩阵能够帮助研究者或开发者了解模型在各类别上的表现,从而发现模型的优点和不足。此外,在模型调优过程中,通过对比不同模型的混淆矩阵,可以更方便地选择性能更优的模型。
五、工具
在Python环境中,可以使用多种库来计算和绘制混淆矩阵,其中最常见的包括:
- Scikit-learn:这是一个功能强大的机器学习库,提供了计算混淆矩阵的函数
confusion_matrix以及绘制混淆矩阵的工具。 - Matplotlib:这是一个用于绘制图表的库,可以与Scikit-learn结合使用,绘制出美观的混淆矩阵图。
- Seaborn:这是一个基于Matplotlib的更高级的绘图库,也支持混淆矩阵的绘制。
- TensorFlow 和 PyTorch:这两个深度学习框架也提供了相关的API来计算和可视化混淆矩阵。
六、步骤
使用Python和Scikit-learn库计算和绘制混淆矩阵的一般步骤如下:
- 导入必要的库:首先导入所需的库,如NumPy、Scikit-learn、Matplotlib等。
- 准备数据:准备分类模型的真实标签和预测标签。这些标签通常是列表或NumPy数组的形式。
- 计算混淆矩阵:使用Scikit-learn的
confusion_matrix函数计算混淆矩阵。传入真实标签和预测标签作为参数。 - 绘制混淆矩阵图(可选):可以使用Matplotlib或Seaborn等工具绘制混淆矩阵图,以便更直观地展示结果。在绘制时,可以根据需要调整颜色、标签等设置。
- 分析混淆矩阵:通过观察混淆矩阵中的元素分布,分析模型在各类别上的表现。特别关注那些错误预测的样本,分析可能的原因,并为后续的模型优化提供依据。
- 计算其他评估指标(可选):基于混淆矩阵,可以进一步计算准确率、精确率、召回率等其他评估指标,以便更全面地评估模型的性能。
综上所述,混淆矩阵是人工智能领域中评估分类模型性能的重要工具。通过混淆矩阵及其相关指标,我们可以全面了解模型在各类别上的表现,并为模型的优化提供有力支持。