继续上一节的内容,解析代码。
目录
- 编码器
- 注册中心
- 负载均衡策略
- 动态代理屏蔽网络传输细节
- 通过spring注解注册/消费服务
编码器
参考LengthFieldBasedFrameDecoder解码器的协议,在协议里规定传输哪些类型的数据, 以及每一种类型的数据应该占多少字节。这样我们在接收到二级制数据之后,就可以正确的解析出我们需要的数据。
下面是本次使用的传输协议:
* 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16* +-----+-----+-----+-----+--------+----+----+----+------+-----------+-------+----- --+-----+-----+-------+* | magic code |version | full length | messageType| codec|compress| RequestId |* +-----------------------+--------+---------------------+-----------+-----------+-----------+------------+* | |* | body |* | |* | ... ... |* +-------------------------------------------------------------------------------------------------------+* 4B magic code(魔法数) 1B version(版本) 4B full length(消息长度) 1B messageType(消息类型)* 1B compress(压缩类型) 1B codec(序列化类型) 4B requestId(请求的Id)* body(object类型数据)
首先是RpcMessageEncoder.java,这个RpcMessageEncoder类的主要作用是将RpcMessage编码为字节,以便可以通过网络发送。它首先将RpcMessage的各个字段(如魔法数、版本号、消息类型等)写入到一个ByteBuf中,然后如果消息类型不是心跳请求类型和心跳响应类型,它还会将消息数据序列化和压缩,然后将序列化和压缩后的字节数组写入到ByteBuf中。最后,它会在ByteBuf的适当位置写入消息的全长度。
@Slf4j
public class RpcMessageEncoder extends MessageToByteEncoder<RpcMessage> {private static final AtomicInteger ATOMIC_INTEGER = new AtomicInteger(0);// 定义一个原子整数,用于生成请求ID@Overrideprotected void encode(ChannelHandlerContext ctx, RpcMessage rpcMessage, ByteBuf out) {// 当需要将RpcMessage编码为字节时被调用try {out.writeBytes(RpcConstants.MAGIC_NUMBER);// 写入魔法数(常量)out.writeByte(RpcConstants.VERSION);// 写入版本号(常量)out.writerIndex(out.writerIndex() + 4);// 留出一个位置来写入消息的全长度byte messageType = rpcMessage.getMessageType();// 获取消息类型out.writeByte(messageType);// 写入消息类型out.writeByte(rpcMessage.getCodec());// 写入编解码类型 hessian、kyro或protostuffout.writeByte(CompressTypeEnum.GZIP.getCode());// 写入压缩类型out.writeInt(ATOMIC_INTEGER.getAndIncrement());// 写入请求ID,并将原子整数加1byte[] bodyBytes = null;// 定义一个字节数组来存储消息体int fullLength = RpcConstants.HEAD_LENGTH;// 定义一个整数来存储消息的全长度,初始值为头部长度16// 消息类型不是心跳消息,则全长=头部长度+正文长度if (messageType != RpcConstants.HEARTBEAT_REQUEST_TYPE&& messageType != RpcConstants.HEARTBEAT_RESPONSE_TYPE) {// 如果消息类型不是心跳请求类型和心跳响应类型// 序列化对象String codecName = SerializationTypeEnum.getName(rpcMessage.getCodec());// 获取编解码类型的名字log.info("codec name: [{}] ", codecName);Serializer serializer = ExtensionLoader.getExtensionLoader(Serializer.class).getExtension(codecName);// 通过ExtensionLoader加载扩展类——序列化器bodyBytes = serializer.serialize(rpcMessage.getData());// 将消息数据序列化为字节数组// 压缩字节数组String compressName = CompressTypeEnum.getName(rpcMessage.getCompress());// 获取压缩类型的名字Compress compress = ExtensionLoader.getExtensionLoader(Compress.class).getExtension(compressName);// 通过ExtensionLoader加载扩展类——压缩器bodyBytes = compress.compress(bodyBytes);// 将字节数组压缩fullLength += bodyBytes.length;// 将字节数组的长度加到消息的全长度上}if (bodyBytes != null) {out.writeBytes(bodyBytes);// 如果字节数组不为空,就将字节数组写入到输出中}int writeIndex = out.writerIndex();// 获取写入的索引//回退到消息长度字段的位置,以便写入消息的全长度。out.writerIndex(writeIndex - fullLength + RpcConstants.MAGIC_NUMBER.length + 1);// 设置写入的索引到合适位置out.writeInt(fullLength);// 写入消息的全长度out.writerIndex(writeIndex);// 恢复写入的索引} catch (Exception e) {log.error("Encode request error!", e);}}}
然后是RpcMessageDecoder.java,这个RpcMessageDecoder类的主要作用是将字节解码为RpcMessage。它首先从ByteBuf中读取各个字段(如魔法数、版本号、全长度等),然后根据消息类型,可能会从ByteBuf中读取消息体,然后将消息体解压缩和反序列化,最后将反序列化后的对象设置到RpcMessage的数据中。
@Slf4j
public class RpcMessageDecoder extends LengthFieldBasedFrameDecoder {public RpcMessageDecoder() {// 调用父类的构造函数,设置各个参数// lengthFieldOffset: 魔法数是4B,版本是1B,然后才是消息长度。所以值是5// lengthFieldLength: 消息长度是4B。所以值是4// lengthAdjustment: 消息长度加上之前读取的所有数据,9个字节,所以剩下的长度是(fullLength-9)。所以值是-9// initialBytesToStrip: 我们将手动检查魔术代码和版本,所以不要剥离任何字节。因此值为0this(RpcConstants.MAX_FRAME_LENGTH, 5, 4, -9, 0);}/*** @param maxFrameLength 最大帧长度。它决定了可以接收的数据的最大长度。* 如果超过,数据将被丢弃。* @param lengthFieldOffset 这是长度字段的偏移量。也就是说,数据帧的开始到消息长度的开始的字节数。* @param lengthFieldLength 消息长度的调整值。* @param lengthAdjustment 消息长度补偿值。lengthAdjustment +数据长度取值 = 数据长度字段之后剩下包的字节数* @param initialBytesToStrip 需要剥离ByteBuf的长度(一般为0)* 如果需要接收所有标头+正文数据,则此值为0* 如果只想接收正文数据,则需要跳过标头所消耗的字节数。*/public RpcMessageDecoder(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,int lengthAdjustment, int initialBytesToStrip) {// 调用父类的构造函数,设置各个参数super(maxFrameLength, lengthFieldOffset, lengthFieldLength, lengthAdjustment, initialBytesToStrip);}// 当需要将字节解码为RpcMessage时被调用@Overrideprotected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {Object decoded = super.decode(ctx, in);// 调用父类的decode方法,获取解码后的对象if (decoded instanceof ByteBuf) {// 如果解码后的对象是ByteBuf类型ByteBuf frame = (ByteBuf) decoded;// 将解码后的对象转换为ByteBuf类型if (frame.readableBytes() >= RpcConstants.TOTAL_LENGTH) {// 如果ByteBuf中可读的字节数大于或等于16 16是所有消息头的长度和try {return decodeFrame(frame);// 解码帧} catch (Exception e) {log.error("Decode frame error!", e);throw e;} finally {frame.release();// 释放帧}}}return decoded;}private Object decodeFrame(ByteBuf in) {// 解码帧// note: must read ByteBuf in ordercheckMagicNumber(in);// 检查魔法数checkVersion(in);// 检查版本号int fullLength = in.readInt();// 读取消息长度// build RpcMessage objectbyte messageType = in.readByte();// 读取消息类型byte codecType = in.readByte();// 读取编解码类型byte compressType = in.readByte();// 读取压缩类型int requestId = in.readInt();// 读取请求IDRpcMessage rpcMessage = RpcMessage.builder()//构建RpcMessage.codec(codecType).requestId(requestId).messageType(messageType).build();if (messageType == RpcConstants.HEARTBEAT_REQUEST_TYPE) {// 如果消息类型是心跳请求类型rpcMessage.setData(RpcConstants.PING);return rpcMessage;}if (messageType == RpcConstants.HEARTBEAT_RESPONSE_TYPE) {// 如果消息类型是心跳响应类型rpcMessage.setData(RpcConstants.PONG);return rpcMessage;}int bodyLength = fullLength - RpcConstants.HEAD_LENGTH;// 计算消息体data的长度if (bodyLength > 0) {// 如果消息体的长度大于0byte[] bs = new byte[bodyLength];// 创建一个新的字节数组来存储消息体in.readBytes(bs);// 从ByteBuf中读取字节到字节数组中// 解压字节数组String compressName = CompressTypeEnum.getName(compressType);// 获取压缩类型的名字Compress compress = ExtensionLoader.getExtensionLoader(Compress.class).getExtension(compressName);// 通过ExtensionLoader加载扩展类——压缩器bs = compress.decompress(bs);// 将字节数组解压缩// 反序列化String codecName = SerializationTypeEnum.getName(rpcMessage.getCodec());// 获取编解码类型的名字log.info("codec name: [{}] ", codecName);Serializer serializer = ExtensionLoader.getExtensionLoader(Serializer.class).getExtension(codecName);// 通过ExtensionLoader加载扩展类——序列化器if (messageType == RpcConstants.REQUEST_TYPE) {// 如果消息类型是请求类型RpcRequest tmpValue = serializer.deserialize(bs, RpcRequest.class);// 将字节数组反序列化为RpcRequestrpcMessage.setData(tmpValue);// 设置RpcMessage的数据为RpcRequest} else {RpcResponse tmpValue = serializer.deserialize(bs, RpcResponse.class);// 将字节数组反序列化为RpcResponserpcMessage.setData(tmpValue);// 设置RpcMessage的数据为RpcResponse}}return rpcMessage;}private void checkVersion(ByteBuf in) {// 检查版本号// read the version and comparebyte version = in.readByte();if (version != RpcConstants.VERSION) {throw new RuntimeException("version isn't compatible" + version);}}private void checkMagicNumber(ByteBuf in) {// 检查魔法数// read the first 4 bit, which is the magic number, and compareint len = RpcConstants.MAGIC_NUMBER.length;byte[] tmp = new byte[len];in.readBytes(tmp);for (int i = 0; i < len; i++) {if (tmp[i] != RpcConstants.MAGIC_NUMBER[i]) {// 如果字节数组中的字节不等于预期的魔法数抛出非法参数异常throw new IllegalArgumentException("Unknown magic code: " + Arrays.toString(tmp));}}}}
注册中心
注册中心负责服务地址的注册与查找,相当于目录服务。 服务端启动的时候将服务名称及其对应的地址(ip+port)注册到注册中心,服务消
费端根据服务名称找到对应的服务地址。有了服务地址之后,服务消费端就可以通过网络请求服务端了。
简单来说注册中心就像是一个中转站,提供的作用就是根据调用的服务名称找到远程服务的地址(数据保存服务)。下面是注册中心的结构:
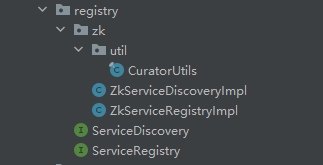
ServiceDiscovery.java 和ServiceRegistry.java 这两个接口分别定义了服务发现和服务注册行为。
@SPI
public interface ServiceDiscovery {/*** 根据 rpcServiceName 获取远程服务地址** @param rpcRequest rpc service pojo* @return service address*/InetSocketAddress lookupService(RpcRequest rpcRequest);
}@SPI
public interface ServiceRegistry {/*** 注册服务到注册中心** @param rpcServiceName rpc service name* @param inetSocketAddress service address*/void registerService(String rpcServiceName, InetSocketAddress inetSocketAddress);}
使用 zookeeper 作为注册中心的实现方式,并实现了这两个接口。下面是ZkServiceRegistry.java
@Slf4j
public class ZkServiceRegistryImpl implements ServiceRegistry {//服务注册@Overridepublic void registerService(String rpcServiceName, InetSocketAddress inetSocketAddress) {String servicePath = CuratorUtils.ZK_REGISTER_ROOT_PATH + "/" + rpcServiceName + inetSocketAddress.toString();CuratorFramework zkClient = CuratorUtils.getZkClient();CuratorUtils.createPersistentNode(zkClient, servicePath);}
}当我们的服务被注册进 zookeeper 的时候,我们将完整的服务名称 rpcServiceName (classname+group+version)作为根节点 ,子节点是对应的服务地址(ip+端口号)。
- class name : 服务接口名也就是类名比如: github.javaguide.HelloService 。
- version : 服务版本。主要是为后续不兼容升级提供可能
- group :服务所在的组。主要用于处理一个接口有多个类实现的情况。
一个根节点(rpcServiceName)可能会对应多个服务地址(相同服务被部署多份的情况)。如果我们要获得某个服务对应的地址的话,就直接根据完整的服务名称来获取到其下的所有子节点,然后通过具体的负载均衡策略取出一个就可以了。相关代码在如下ZkServiceDiscovery.java 中。
@Slf4j
public class ZkServiceDiscoveryImpl implements ServiceDiscovery {private final LoadBalance loadBalance;// 定义一个LoadBalance对象用于负载均衡public ZkServiceDiscoveryImpl() {// 通过ExtensionLoader获取LoadBalance的实例this.loadBalance = ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension(LoadBalanceEnum.LOADBALANCE.getName());}@Overridepublic InetSocketAddress lookupService(RpcRequest rpcRequest) {String rpcServiceName = rpcRequest.getRpcServiceName();// 获取rpc请求的服务名CuratorFramework zkClient = CuratorUtils.getZkClient();// 获取Zookeeper客户端List<String> serviceUrlList = CuratorUtils.getChildrenNodes(zkClient, rpcServiceName);// 获取服务名对应的所有服务地址if (CollectionUtil.isEmpty(serviceUrlList)) {// 如果服务地址列表为空throw new RpcException(RpcErrorMessageEnum.SERVICE_CAN_NOT_BE_FOUND, rpcServiceName);}// 通过负载均衡选择一个服务地址String targetServiceUrl = loadBalance.selectServiceAddress(serviceUrlList, rpcRequest);log.info("Successfully found the service address:[{}]", targetServiceUrl);String[] socketAddressArray = targetServiceUrl.split(":");// 将服务地址分割为主机和端口String host = socketAddressArray[0];// 获取主机int port = Integer.parseInt(socketAddressArray[1]);// 获取端口return new InetSocketAddress(host, port);// 返回一个新的InetSocketAddress}
}
ZkServiceDiscoveryImpl.java和ZkServiceRegistryImpl.java都使用到了CuratorUtils工具类,下面是它的代码,建议学习,以后都可以用:
@Slf4j
public final class CuratorUtils {private static final int BASE_SLEEP_TIME = 1000;// 定义基础睡眠时间private static final int MAX_RETRIES = 3;// 定义最大重试次数public static final String ZK_REGISTER_ROOT_PATH = "/my-rpc";// 定义Zookeeper注册的根路径private static final Map<String, List<String>> SERVICE_ADDRESS_MAP = new ConcurrentHashMap<>();// 定义一个映射来存储服务地址private static final Set<String> REGISTERED_PATH_SET = ConcurrentHashMap.newKeySet();// 定义一个集合来存储已注册的路径private static CuratorFramework zkClient;// 定义一个Zookeeper客户端private static final String DEFAULT_ZOOKEEPER_ADDRESS = "127.0.0.1:2181";// 定义默认的Zookeeper地址private CuratorUtils() {// 私有构造函数,防止外部创建实例}public static void createPersistentNode(CuratorFramework zkClient, String path) {//创建持久节点。try {if (REGISTERED_PATH_SET.contains(path) || zkClient.checkExists().forPath(path) != null) {// 如果路径已经存在log.info("The node already exists. The node is:[{}]", path);} else {//eg: /my-rpc/github.javaguide.HelloService/127.0.0.1:9999zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath(path);// 创建节点log.info("The node was created successfully. The node is:[{}]", path);}REGISTERED_PATH_SET.add(path);// 将路径添加到已注册的路径集合中} catch (Exception e) {log.error("create persistent node for path [{}] fail", path);}}public static List<String> getChildrenNodes(CuratorFramework zkClient, String rpcServiceName) {//获取指定节点下的所有子节点if (SERVICE_ADDRESS_MAP.containsKey(rpcServiceName)) {// 如果服务地址映射中包含rpc服务名return SERVICE_ADDRESS_MAP.get(rpcServiceName);}List<String> result = null;// 定义一个列表来存储结果String servicePath = ZK_REGISTER_ROOT_PATH + "/" + rpcServiceName;// 定义服务路径try {result = zkClient.getChildren().forPath(servicePath);// 获取服务路径下的所有子节点SERVICE_ADDRESS_MAP.put(rpcServiceName, result);// 将结果放入服务地址映射中registerWatcher(rpcServiceName, zkClient);// 注册观察者} catch (Exception e) {log.error("get children nodes for path [{}] fail", servicePath);}return result;}//清空注册的数据public static void clearRegistry(CuratorFramework zkClient, InetSocketAddress inetSocketAddress) {REGISTERED_PATH_SET.stream().parallel().forEach(p -> {// 遍历已注册的路径集合try {if (p.endsWith(inetSocketAddress.toString())) {// 如果路径以指定的地址字符串结束zkClient.delete().forPath(p);// 删除路径}} catch (Exception e) {log.error("clear registry for path [{}] fail", p);}});log.info("All registered services on the server are cleared:[{}]", REGISTERED_PATH_SET.toString());}public static CuratorFramework getZkClient() {//获取Zookeeper客户端// 检查用户是否设置了zk地址Properties properties = PropertiesFileUtil.readPropertiesFile(RpcConfigEnum.RPC_CONFIG_PATH.getPropertyValue());String zookeeperAddress = properties != null && properties.getProperty(RpcConfigEnum.ZK_ADDRESS.getPropertyValue()) != null ? properties.getProperty(RpcConfigEnum.ZK_ADDRESS.getPropertyValue()) : DEFAULT_ZOOKEEPER_ADDRESS;// 如果Zookeeper客户端已经启动 直接返回Zookeeper客户端if (zkClient != null && zkClient.getState() == CuratorFrameworkState.STARTED) {return zkClient;}// 重试策略。重试3次,并将增加重试之间的睡眠时间。RetryPolicy retryPolicy = new ExponentialBackoffRetry(BASE_SLEEP_TIME, MAX_RETRIES);zkClient = CuratorFrameworkFactory.builder()//创建一个CuratorFramework的构建器// the server to connect to (can be a server list).connectString(zookeeperAddress)// 设置连接字符串.retryPolicy(retryPolicy)// 设置重试策略.build();// 构建CuratorFrameworkzkClient.start();// 启动CuratorFrameworktry {// 如果在30秒内无法连接到Zookeeperif (!zkClient.blockUntilConnected(30, TimeUnit.SECONDS)) {throw new RuntimeException("Time out waiting to connect to ZK!");// 抛出运行时异常}} catch (InterruptedException e) {e.printStackTrace();}return zkClient;}/*** 注册以侦听对指定节点的更改** @param rpcServiceName rpc service name eg:github.javaguide.HelloServicetest2version*/private static void registerWatcher(String rpcServiceName, CuratorFramework zkClient) throws Exception {String servicePath = ZK_REGISTER_ROOT_PATH + "/" + rpcServiceName;// 定义服务路径// 创建一个路径子节点缓存PathChildrenCache pathChildrenCache = new PathChildrenCache(zkClient, servicePath, true);// 定义一个路径子节点缓存监听器PathChildrenCacheListener pathChildrenCacheListener = (curatorFramework, pathChildrenCacheEvent) -> {// 这里是当监听到子节点变化时要执行的代码// 获取服务路径下的所有子节点List<String> serviceAddresses = curatorFramework.getChildren().forPath(servicePath);SERVICE_ADDRESS_MAP.put(rpcServiceName, serviceAddresses);// 将子节点放入服务地址映射中};pathChildrenCache.getListenable().addListener(pathChildrenCacheListener);// 将监听器添加到路径子节点缓存的监听器列表中pathChildrenCache.start();// 启动路径子节点缓存}}
负载均衡策略
常见的负载均衡算法有很多,例如轮询法(Round Robin)、随机法(Random)、加权轮询法(Weighted Round Robin)、最少连接数法(Least Connections)等。本框架使用的一致性哈希算法。
一致性哈希算法是一种特殊的哈希算法,主要用于解决分布式系统中的数据分布问题。它的主要优点是在节点数量发生变化时,能够最小化对已有键值映射关系的影响。
一致性哈希算法的基本原理和流程如下:
1.环形空间:一致性哈希算法首先将整个哈希值空间组织成一个虚拟的圆环(假设哈希函数的值域为0~2^32-1),这就是所谓的"哈希环"。
2.数据映射:对于数据项(例如,服务器节点或者数据库的记录),通过哈希函数计算其哈希值,并将其映射到这个哈希环上。
3.查找过程:当需要查找某个数据项时,也会首先计算其哈希值,然后在哈希环上顺时针查找,第一个遇到的数据项就是需要查找的数据项。
4.节点变化:当有新的节点加入或者原有的节点离开时,只需要重新进行哈希映射,而不需要对所有的数据项进行重新映射,大大减少了计算量。
5.虚拟节点:为了解决数据分布不均的问题,一致性哈希算法引入了"虚拟节点"的概念。每一个真实节点对应多个虚拟节点,虚拟节点的哈希值通过哈希函数计算得到。当查找数据时,是在虚拟节点环上进行查找,从而使得数据在各个真实节点上分布更均匀。
在一致性哈希算法中,数据项(例如服务器节点或数据库的记录)通过哈希函数计算其哈希值,并将其映射到哈希环上。当有新的节点加入或者原有的节点离开时,只需要重新计算这些节点的哈希值,并更新哈希环即可。
具体来说,当一个新的节点加入时,它会被映射到哈希环的某个位置,然后它会接管该位置到下一个节点之间的数据项。当一个节点离开时,它的数据项会被其下一个节点接管。这个过程只涉及到哈希环上的一小部分数据项,大部分数据项的映射关系不会受到影响。
因此,一致性哈希算法在节点数量变化时,只需要对受影响的数据项进行重新映射,而不需要对所有的数据项进行重新映射,从而大大减少了计算量。这也是一致性哈希算法在分布式系统中广泛应用的一个重要原因。
下面是本RPC框架的负载均衡代码,在注册服务的代码ZkServiceDiscoveryImpl.java中可以看到其定义了一个LoadBalance对象用于负载均衡。这个LoadBalance对象实现了一个接口:
@SPI
public interface LoadBalance {/*** Choose one from the list of existing service addresses list** @param serviceUrlList Service address list* @param rpcRequest* @return target service address*/String selectServiceAddress(List<String> serviceUrlList, RpcRequest rpcRequest);
}
这个接口定义了一个方法selectServiceAddress,这个方法的作用是从提供的服务地址列表中选择一个服务地址。这个方法需要两个参数,一个是服务地址列表,另一个是RPC请求。
然后有个AbstractLoadBalance类实现了他:
public abstract class AbstractLoadBalance implements LoadBalance {@Overridepublic String selectServiceAddress(List<String> serviceAddresses, RpcRequest rpcRequest) {if (CollectionUtil.isEmpty(serviceAddresses)) {return null;}if (serviceAddresses.size() == 1) {return serviceAddresses.get(0);}return doSelect(serviceAddresses, rpcRequest);}protected abstract String doSelect(List<String> serviceAddresses, RpcRequest rpcRequest);}
AbstractLoadBalance类。这个类实现了LoadBalance接口,并提供了一个默认的selectServiceAddress方法的实现。如果服务地址列表为空,那么这个方法就返回null。如果服务地址列表只有一个地址,那么这个方法就返回这个地址。如果服务地址列表有多个地址,那么这个方法就调用doSelect方法来选择一个地址。doSelect方法是一个抽象方法,需要子类来提供具体的实现。所以核心的负载均衡代码在继承了它的子类ConsistentHashLoadBalance.java中:
@Slf4j
public class ConsistentHashLoadBalance extends AbstractLoadBalance {// 用于存储每个服务名对应的一致性哈希选择器private final ConcurrentHashMap<String, ConsistentHashSelector> selectors = new ConcurrentHashMap<>();@Overrideprotected String doSelect(List<String> serviceAddresses, RpcRequest rpcRequest) {// 获取服务地址列表的哈希码int identityHashCode = System.identityHashCode(serviceAddresses);// 获取rpc请求的服务名String rpcServiceName = rpcRequest.getRpcServiceName();// 从选择器映射中获取对应服务名的选择器ConsistentHashSelector selector = selectors.get(rpcServiceName);// 如果选择器不存在或者选择器的哈希码与服务地址列表的哈希码不同,则创建新的选择器if (selector == null || selector.identityHashCode != identityHashCode) {selectors.put(rpcServiceName, new ConsistentHashSelector(serviceAddresses, 160, identityHashCode));selector = selectors.get(rpcServiceName);}return selector.select(rpcServiceName + Arrays.stream(rpcRequest.getParameters()));}static class ConsistentHashSelector {//每个服务名对应的一致性哈希选择器// 用于存储虚拟节点的有序映射,键是虚拟节点的哈希值,值是对应的服务地址private final TreeMap<Long, String> virtualInvokers;// 服务地址列表的哈希码private final int identityHashCode;ConsistentHashSelector(List<String> invokers, int replicaNumber, int identityHashCode) {this.virtualInvokers = new TreeMap<>();this.identityHashCode = identityHashCode;// 对每个服务地址,创建指定数量的虚拟节点,并将虚拟节点添加到有序映射中for (String invoker : invokers) {for (int i = 0; i < replicaNumber / 4; i++) {byte[] digest = md5(invoker + i);for (int h = 0; h < 4; h++) {long m = hash(digest, h);virtualInvokers.put(m, invoker);}}}}// 使用MD5算法计算字符串的哈希值static byte[] md5(String key) {MessageDigest md;try {md = MessageDigest.getInstance("MD5");byte[] bytes = key.getBytes(StandardCharsets.UTF_8);md.update(bytes);} catch (NoSuchAlgorithmException e) {throw new IllegalStateException(e.getMessage(), e);}return md.digest();}// 将字节数组的一部分转换为长整型数值static long hash(byte[] digest, int idx) {return ((long) (digest[3 + idx * 4] & 255) << 24 | (long) (digest[2 + idx * 4] & 255) << 16 | (long) (digest[1 + idx * 4] & 255) << 8 | (long) (digest[idx * 4] & 255)) & 4294967295L;}// 选择一个服务地址public String select(String rpcServiceKey) {byte[] digest = md5(rpcServiceKey);return selectForKey(hash(digest, 0));}// 根据给定的哈希值,在有序映射中选择一个服务地址public String selectForKey(long hashCode) {Map.Entry<Long, String> entry = virtualInvokers.tailMap(hashCode, true).firstEntry();if (entry == null) {entry = virtualInvokers.firstEntry();}return entry.getValue();}}
}
这个代码参考了dubbo的一致性哈希负载均衡算法,有兴趣可以学习一下。
动态代理屏蔽网络传输细节
在RpcClientProxy.java中使用到了动态代理来屏蔽网络传输的细节。当我们去调用一个远程的方法的时候,实际上是通过代理对象调用的。网络传输细节都被封装在了 invoke() 方法中。
这个RpcClientProxy类的主要作用是实现RPC客户端的代理。当你使用代理对象调用一个方法时,实际上调用的是invoke方法。在invoke方法中,它首先创建一个RpcRequest,然后通过RpcRequestTransport发送这个请求,并获取一个RpcResponse。最后,它返回RpcResponse中的数据。
@Slf4j
public class RpcClientProxy implements InvocationHandler {private static final String INTERFACE_NAME = "interfaceName";// 定义一个常量,表示接口名/*** 用于向服务器发送请求。有两种实现:socket和netty*/private final RpcRequestTransport rpcRequestTransport;// 定义一个RpcRequestTransport对象,用于向服务器发送请求private final RpcServiceConfig rpcServiceConfig;// 定义一个RpcServiceConfig对象,用于存储RPC服务的配置public RpcClientProxy(RpcRequestTransport rpcRequestTransport, RpcServiceConfig rpcServiceConfig) {this.rpcRequestTransport = rpcRequestTransport;this.rpcServiceConfig = rpcServiceConfig;}public RpcClientProxy(RpcRequestTransport rpcRequestTransport) {this.rpcRequestTransport = rpcRequestTransport;this.rpcServiceConfig = new RpcServiceConfig();}@SuppressWarnings("unchecked")public <T> T getProxy(Class<T> clazz) {// 获取代理对象// 返回一个新的代理实例return (T) Proxy.newProxyInstance(clazz.getClassLoader(), new Class<?>[]{clazz}, this);}@SneakyThrows@SuppressWarnings("unchecked")@Overridepublic Object invoke(Object proxy, Method method, Object[] args) {// 当使用代理对象调用方法时,实际上调用的是这个方法log.info("invoked method: [{}]", method.getName());RpcRequest rpcRequest = RpcRequest.builder().methodName(method.getName())// 创建一个RpcRequest的构建器,并设置方法名.parameters(args).interfaceName(method.getDeclaringClass().getName()).paramTypes(method.getParameterTypes()).requestId(UUID.randomUUID().toString()).group(rpcServiceConfig.getGroup()).version(rpcServiceConfig.getVersion()).build();RpcResponse<Object> rpcResponse = null;// 定义一个RpcResponse对象if (rpcRequestTransport instanceof NettyRpcClient) {// 如果RpcRequestTransport是NettyRpcClient的实例// 发送RPC请求,并获取一个CompletableFutureCompletableFuture<RpcResponse<Object>> completableFuture = (CompletableFuture<RpcResponse<Object>>) rpcRequestTransport.sendRpcRequest(rpcRequest);rpcResponse = completableFuture.get();// 从CompletableFuture中获取RpcResponse}if (rpcRequestTransport instanceof SocketRpcClient) {// 如果RpcRequestTransport是SocketRpcClient的实例 发送RPC请求,并获取RpcResponserpcResponse = (RpcResponse<Object>) rpcRequestTransport.sendRpcRequest(rpcRequest);}this.check(rpcResponse, rpcRequest);// 检查RpcResponse和RpcRequestreturn rpcResponse.getData();// 返回RpcResponse中的数据}private void check(RpcResponse<Object> rpcResponse, RpcRequest rpcRequest) {if (rpcResponse == null) {throw new RpcException(RpcErrorMessageEnum.SERVICE_INVOCATION_FAILURE, INTERFACE_NAME + ":" + rpcRequest.getInterfaceName());}if (!rpcRequest.getRequestId().equals(rpcResponse.getRequestId())) {// 如果RpcRequest的请求ID和RpcResponse的请求ID不相等throw new RpcException(RpcErrorMessageEnum.REQUEST_NOT_MATCH_RESPONSE, INTERFACE_NAME + ":" + rpcRequest.getInterfaceName());}// 如果RpcResponse的响应码为空,或者RpcResponse的响应码不为成功响应码if (rpcResponse.getCode() == null || !rpcResponse.getCode().equals(RpcResponseCodeEnum.SUCCESS.getCode())) {throw new RpcException(RpcErrorMessageEnum.SERVICE_INVOCATION_FAILURE, INTERFACE_NAME + ":" + rpcRequest.getInterfaceName());}}
}
通过spring注解注册/消费服务
这部分借用了 Spring 容器相关的功能来自动扫描项目中的注解,没学过spring的可以先去学一下再看代码。这里是通过给类加注解的方式标记该类是需要注册服务还是消费服务,并在spring的自动扫描中去完成相应的操作。
核心代码如下:
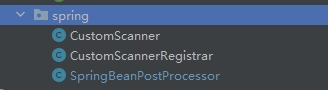
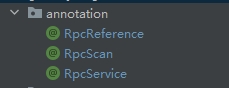
核心思想如下:
1.@RpcScan注解用于标记需要进行RPC服务扫描的包路径。这个注解通常会放在Spring的配置类上,在我们的项目中将其放置在客户端和服务端的启动类NettyClientMain和NettyServerMain上。
2.当Spring容器启动时,由于@RpcScan注解中使用了@Import(CustomScannerRegistrar.class),所以CustomScannerRegistrar类中的registerBeanDefinitions方法会被调用。这个方法会创建CustomScanner实例,并启动对指定包路径的扫描。
3.在扫描过程中,CustomScanner会找出所有带有@RpcService和@Component注解的类,并将这些类注册为Spring Bean。在本项目中我们将@Component放置在了客户端启动类的服务调用者类上比如HelloController,还有NettyRpcServer。
4.在Spring Bean的实例化过程中,SpringBeanPostProcessor类中的postProcessBeforeInitialization和postProcessAfterInitialization方法会被调用。
5.postProcessBeforeInitialization方法会在Bean实例化之前被调用,如果一个Bean被@RpcService注解标记,那么这个Bean会被发布为RPC服务。
6.postProcessAfterInitialization方法会在Bean实例化之后被调用,如果一个Bean的字段被@RpcReference注解标记,那么这个字段会被注入RPC服务。
首先是三个注解:
- RcpService :注册服务
- RpcReference :消费服务
- RpcScan:启动RPC服务的自动扫描
/*** RpcService注解用于标记一个类提供RPC服务。** @author shuang.kou* @createTime 2020年07月21日 13:11:00*/
@Documented// 表明这个注解应该被 javadoc工具记录
@Retention(RetentionPolicy.RUNTIME)// 注解会在class字节码文件中存在,在运行时可以通过反射获取到
@Target({ElementType.TYPE})// 目标是接口、类、枚举、注解
@Inherited// 说明子类可以继承父类中的该注解
public @interface RpcService {String version() default "";// 服务版本String group() default "";// 服务组}/*** RpcReference注解用于标记一个字段,该字段需要注入RPC服务。** @author smile2coder* @createTime 2020年09月16日 21:42:00*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD})// 目标是字段(类的属性或者变量)
@Inherited
public @interface RpcReference {/*** Service version, default value is empty string*/String version() default "";/*** Service group, default value is empty string*/String group() default "";}/*** RpcScan注解用于启动RPC服务的自动扫描。basePackage属性用于指定需要扫描的包路径。** @author shuang.kou* @createTime 2020年08月10日 21:42:00*/
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Import(CustomScannerRegistrar.class)// Spring容器加载时,会将CustomScannerRegistrar一起加载进来
// 即带有RpcScan的属性或者方法会触发CustomScannerRegistrar.class中的registerBeanDefinitions方法去执行
@Documented
public @interface RpcScan {String[] basePackage();// 需要扫描的包路径}
然后是CustomScannerRegistrar和CustomScanner
@Slf4j
public class CustomScannerRegistrar implements ImportBeanDefinitionRegistrar, ResourceLoaderAware {private static final String SPRING_BEAN_BASE_PACKAGE = "github.javaguide";// Spring Bean的基础包名private static final String BASE_PACKAGE_ATTRIBUTE_NAME = "basePackage";// RpcScan注解的basePackage属性名private ResourceLoader resourceLoader;// 资源加载器@Overridepublic void setResourceLoader(ResourceLoader resourceLoader) {this.resourceLoader = resourceLoader;}@Overridepublic void registerBeanDefinitions(AnnotationMetadata annotationMetadata, BeanDefinitionRegistry beanDefinitionRegistry) {// 获取RpcScan注解的属性和值AnnotationAttributes rpcScanAnnotationAttributes = AnnotationAttributes.fromMap(annotationMetadata.getAnnotationAttributes(RpcScan.class.getName()));String[] rpcScanBasePackages = new String[0];if (rpcScanAnnotationAttributes != null) {// 获取basePackage属性的值rpcScanBasePackages = rpcScanAnnotationAttributes.getStringArray(BASE_PACKAGE_ATTRIBUTE_NAME);}if (rpcScanBasePackages.length == 0) {// 如果没有指定basePackage,那么使用当前类(使用了RpcScan注解的类)的包名作为basePackagerpcScanBasePackages = new String[]{((StandardAnnotationMetadata) annotationMetadata).getIntrospectedClass().getPackage().getName()};}// 创建一个CustomScanner对象,用于扫描RpcService注解CustomScanner rpcServiceScanner = new CustomScanner(beanDefinitionRegistry, RpcService.class);// 创建一个CustomScanner对象,用于扫描Component注解CustomScanner springBeanScanner = new CustomScanner(beanDefinitionRegistry, Component.class);if (resourceLoader != null) {// 设置资源加载器rpcServiceScanner.setResourceLoader(resourceLoader);springBeanScanner.setResourceLoader(resourceLoader);}// 扫描Spring Bean(@Component),并记录扫描到的数量int springBeanAmount = springBeanScanner.scan(SPRING_BEAN_BASE_PACKAGE);log.info("springBeanScanner扫描的数量 [{}]", springBeanAmount);// 扫描RpcService,并记录扫描到的数量int rpcServiceCount = rpcServiceScanner.scan(rpcScanBasePackages);log.info("rpcServiceScanner扫描的数量 [{}]", rpcServiceCount);
// RpcReference注解是用于标记需要注入RPC服务的字段,
// 这个注解的处理逻辑是在SpringBeanPostProcessor类中实现的,而不是在包扫描阶段。所以,这里没有扫描带有RpcReference注解的类。}}/*** CustomScanner类继承了Spring的ClassPathBeanDefinitionScanner类,用于扫描指定包下的类,并将包含指定注解的类注册为Bean。** @author shuang.kou* @createTime 2020年08月10日 21:42:00*/
public class CustomScanner extends ClassPathBeanDefinitionScanner {public CustomScanner(BeanDefinitionRegistry registry, Class<? extends Annotation> annoType) {super(registry);// 调用父类构造方法,传入Bean定义注册表super.addIncludeFilter(new AnnotationTypeFilter(annoType));// 添加包含过滤器,只包含指定注解类型annoType的类}@Overridepublic int scan(String... basePackages) {//String...表示此处接收的参数为0到多个String或者是一个String数组return super.scan(basePackages);}
}
最后是SpringBeanPostProcessor
@Slf4j
@Component
public class SpringBeanPostProcessor implements BeanPostProcessor {private final ServiceProvider serviceProvider;// 服务提供者private final RpcRequestTransport rpcClient;// RPC客户端public SpringBeanPostProcessor() {this.serviceProvider = SingletonFactory.getInstance(ZkServiceProviderImpl.class);this.rpcClient = ExtensionLoader.getExtensionLoader(RpcRequestTransport.class).getExtension(RpcRequestTransportEnum.NETTY.getName());}//这个方法在Spring Bean实例化之前被调用。如果一个Bean被RpcService注解标记,那么这个Bean会被发布为RPC服务。@SneakyThrows// Lombok库的注解,用于处理所有受检异常@Overridepublic Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {if (bean.getClass().isAnnotationPresent(RpcService.class)) {// 判断Bean是否有RpcService注解log.info("[{}] is annotated with [{}]", bean.getClass().getName(), RpcService.class.getCanonicalName());// 获取RpcService注解RpcService rpcService = bean.getClass().getAnnotation(RpcService.class);// 构建RpcServicePropertiesRpcServiceConfig rpcServiceConfig = RpcServiceConfig.builder().group(rpcService.group()).version(rpcService.version()).service(bean).build();serviceProvider.publishService(rpcServiceConfig);}return bean;}//这个方法在Spring Bean实例化之后被调用。如果一个Bean的字段被RpcReference注解标记,那么这个字段会被注入RPC服务。@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {Class<?> targetClass = bean.getClass();// 获取Bean的类对象Field[] declaredFields = targetClass.getDeclaredFields();// 获取Bean的所有字段(类的属性或变量) 不包括其父类的字段for (Field declaredField : declaredFields) {// 遍历所有字段RpcReference rpcReference = declaredField.getAnnotation(RpcReference.class);// 获取字段上的RpcReference注解if (rpcReference != null) {// 如果字段有RpcReference注解RpcServiceConfig rpcServiceConfig = RpcServiceConfig.builder()// 构建RpcServiceProperties.group(rpcReference.group()).version(rpcReference.version()).build();RpcClientProxy rpcClientProxy = new RpcClientProxy(rpcClient, rpcServiceConfig);// 创建RPC客户端代理Object clientProxy = rpcClientProxy.getProxy(declaredField.getType());// 获取代理对象declaredField.setAccessible(true);// 设置字段可访问try {// 将代理对象注入到字段declaredField.set(bean, clientProxy);} catch (IllegalAccessException e) {e.printStackTrace();}}}return bean;}
}完结。