数据库与内存、文件的比较
内存:
优点:存取速度快
缺点:-容量小
-断电后,数据不会保存
文件:
优点:数据可以持久化保存
缺点:-读取速度慢
-编码格式不好控制
数据库:
优点:-容量大
-读取速度快
-统一的编码格式
缺点:使用难度较高
SqlServer是一个关系型数据库
优点:性能高。相较于Mysql,SqlServer支持更大的数据量和更高的并发性能,可以更好的处理复杂的查询,提供更好的安全性和可靠性
关系模型概念:以行和列的形式进行数据的存储(二维表),便于用户理解
登录数据库
1、通过客户端软件登录 [.][127.0.0.1][ip地址]
-- .:本机
--127.0.0.1本机默认ip
--网络ip+SqlServer身份验证
• SQLServer 中 4 个系统数据库: Master 、 Model 、 Msdb 、 Tempdb 。
• 1 、 Master 数据库是 SQLServer 系统最重要的数据库,它记录了 SQLServer 系统的所有系统信息。
• 2 、 model 数据库用作在 SQLServer 实例上创建的所有数据库的模板。
• 3 、 Msdb 数据库是代理服务数据库,为其报警、任务调度和记录操作员的操作提供存储空间。
• 4 、 Tempdb 是一个临时数据库,它为所有的临时表、临时存储过程及其他临时操作提供存储空间。
数据类型


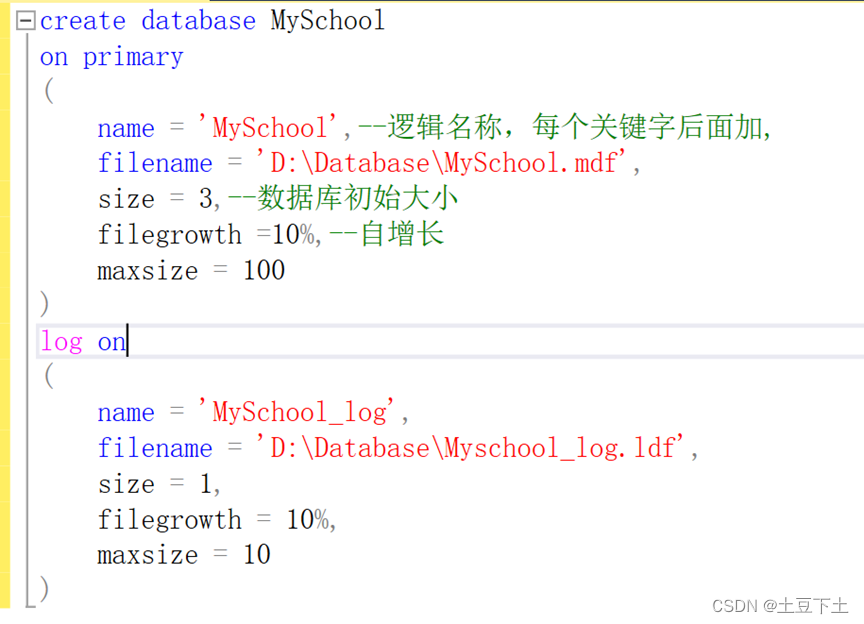
使用SQL语句创建数据库
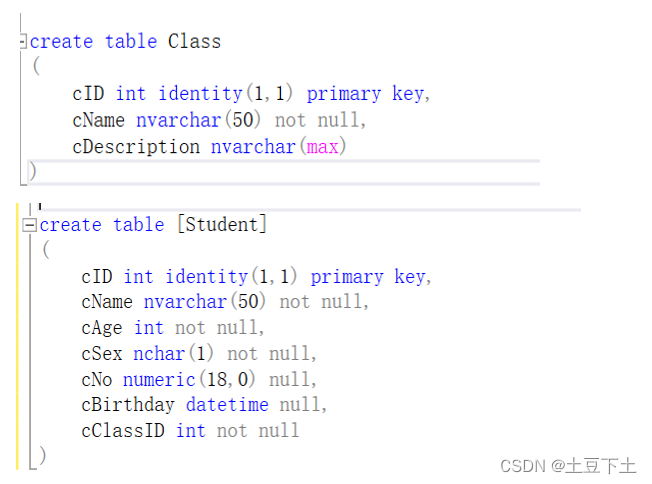
使用SQL语句创建数据表
插入数据
插入一条数据:insert into Class(cid,cname,cdescription) values(8,'八班','张三')
一次性插入多条数据:
insert into Class(cName)
select 'bbb' union all
select 'ccc' union all
select 'ddd' union all
更新数据
更新一个列:update Student set sSex = ‘男’
更新多个列: update Student set sSex ='女',sAge = 18,sBirthday='1989-8-8'
更新一部分数据: update Student set sClassId= 4 where sClassId = 1,用where语句表示只更新Name是’tom’的行,注意SQL中等于判断用单个=,而不是==。
Where中还可以使用复杂的逻辑判断update Student set sAge=30 where sName='华佗' or sAge<25 ,or相当于C#中的||(或者)
所有学生的年龄加1update Student set sAge = sAge + 1
update Student set sClassId=6
where (sAge>20 and sAge<30) or(sAge=50)
Where中可以使用的其他逻辑运算符:or、and、not、<、>、>=、<=、!=(或<>)等
删除数据
删除表中全部数据:DELETE FROM Student。
Delete只是删除数据,表还在,和Drop Table不同。
Delete 也可以带where子句来删除一部分数据:DELETE FROM Student WHERE sAge > 20
==========================
truncate table student 的作用与delete from student一样,都是删除student表中的全部数据,区别在于:
1.truncate语句非常高效。由于truncate操作采用按最小方式来记录日志,所以效率非常高。对于数百万条数据使用truncate删除只要几秒钟,而使用delete则可能耗费几小时。
2.truncate语句会把表中的自动编号重置为默认值。
3.truncate语句不触发delete触发器。
约束
数据库约束是为了保证数据的完整性(正确性)而实现的一套机制
• 非空约束
• 主键约束 (PK) primary key constraint 唯一且不为空
• 唯一约束 (UQ)unique constraint 唯一,允许为空,但只能出现一次
• 默认约束 (DF)default constraint 默认值
• 检查约束 (CK)check constraint 范围以及格式限制
• 外键约束 (FK)foreign key constraint 表关系
– -on delete cascade 级联删除
数据检索-查询
执行备注中的代码创建测试数据表。
简单的数据检索 : SELECT * FROM Student
只检索需要的列 : SELECT sName FROM Student 、 SELECT sName,sAge FROM Student( select 执行过程 )
列别名: SELECT sName AS 姓名 , sAge AS 年龄 , sBirthday AS 出生日期 FROM Student
使用 where 检索符合条件的数据: SELECT sName FROM Student WHERE sSex =‘ 女 ’ 。
还可以检索不与任何表关联的数据: select 1+1;select select getdate ();
Top 获取前几条数据
• 获得年纪最小的 5 个学生
• 获得年纪最大的 10% 的学生
Distinct 去除重复数据
• select distinct sName from student
• select distinct sName,sAge from student
DISTINCT 是对整个结果集进行数据重复处理的,而不是针对某一个列
distinct&top 配合使用
模糊查询:
查询所有姓张的同学
• Select * from student where left(sName,1)=‘ 张 ‘ 看上去很美 , 如果改成查询名字中带亮的学生怎么做?
换一种做法 like
• Select * from student where sName like ‘ 张 %’ 会吧所有姓张的都查询到,现在我想查询姓张并且名字是一个字的学生?
• Select * from student where sName like ‘% 亮 %’
通配符 % 多字符匹配的通配符,它匹配任意次数(零或多个)出现的任意字符
通配符 _ 单字符匹配,它匹配单个出现的字符
[] 只匹配一个字符 并且这个字符必须是 [] 范围内的 [0-9] [a-z] [ a,b,c ]
查询姓张或者姓关的同学
not 与 like 一起使用: not like ….
空值处理:
l 数据库中,一个列如果没有指定值,那么值就为 null ,这个 null 和 C# 中的 null ,数据库中的 null 表示“ 不知道 ”,而不是表示没有。因此 select null+1 结果是 null ,因为“不知道”加 1 的结果还是“不知道”。
l select * from score where english = null ;
l select * from score where english != null ; 都没有任何返回结果,因为数据库也“不知道”。
l SQL 中使用 is null 、 is not null 来进行空值判断: select * from score where english is null ; select * from score where english is not null ;
l ISNULL ( check_expression , replacement_value )
数据排序:
ORDER BY 子句位于 SELECT 语句的末尾,它允许指定按照一个列或者多个列进行排序,还可以指定排序方式是升序(从小到大排列, ASC )还是降序(从大到小排列, DESC )。
按照年龄升序排序所有学生信息的列表: SELECT * FROM Student ORDER BY sAge ASC
l 查询班级中年龄最大的前三个学生。
按照英语成绩从大到小排序,如果英语成绩相同则按照数学成绩从大到小排序 : SELECT * FROM Score ORDER BY english DESC,math DESC
ORDER BY 子句要放到 WHERE 子句之后 : SELECT * FROM Score where english >=60 and math>=60 ORDER BY english DESC,math DESC
Order by 语句一般要放到所有语句的后面,就是先让其他语句进行筛选,全部筛选完成后,最后排序一下。
数据分组:
select 语句中可以使用 group by 子句将行划分成较小的组,然后,使用聚组函数返回每一个组的汇总信息
按照班级进行分组统计各个班级的人数
每个班级的平均年龄
男生有多少个?女生有多少个人?
GROUP BY 子句必须放到 WHERE 语句的之后
每个班男同学的个数
没有出现在 GROUP BY 子句中的列是不能放到 SELECT 语句后的列名列表中的 (聚合函数中除外)
• 错误: select sClassId,count ( sName ), sAge from student group by sClassId
• 正确: select sClassId,count ( sName ),avg( sAge ) from student group by sClassId
Having语句:
查询班级人数大于 3 的班级
Having 是 Group By 的条件对分组后的数据进行筛选
在 Where 中不能使用聚合函数,必须使用 Having , Having 要位于 Group By 之后,
查询班级人数超过三个人的班级
select sClassId,count ( sName ) from student group by sClassId having count( sName )>3
注意 Having 中不能使用未参与分组的列, Having 不能替代 where 。作用不一样, Having 是对组进行过滤。
查询男生个数大于 5 的班级
select sClassId,count(sName) from student where count(sName)>3 group by sClassId
聚合函数不应出现在WHERE 子句中select sClassId,count(sName) from student group by sClassId having count(sName)>3Group by 前可以有where,是对筛选过后的数据进行分组
select sClassId,count(sName) from student where sSex='男' group by sClassId select sClassId,count(sName) from student group by sClassId having sAge>30
//错,having是对分组后信息的过滤,能用的列和select中能用的列是一样。
//having无法代替where。
SQL语句的执行顺序
5>…Select 5-1> 选择列 ,5-2>distinct,5-3>top
1>…From 表
2>…Where 条件
3>…Group by 列
4>…Having 筛选条件
6>…Order by 列
select sclassid , count (*) from student where ssex = ' 男 ' group by sclassid having count (*) > 2
联合结果集:
简单的结果集联合:
• select tName,tSex from teacher union
• select sName,sSex from student
合并老师表和学生表
基本的原则:每个结果集必须有相同的列数;每个结果集的列必须类型相容。
• select tName,tSex,-1 from teacher union
• select sName,sSex,sClassId from student
联合:将多个结果集合并成一个结果集。 union( 去除重复 ) 、 union all
Union all:
• select tName,tSex from teacher union
• select sName,sSex from student
UNION合并两个查询结果集,并且将其中完全重复的数据行合并为一条
• select tName,tSex from teacher union all
• select sName,sSex from student
Union因为要进行重复值扫描,所以效率低,因此如果不是确定要合并重复行,那么就用UNION ALL
一次插入多条数据
insert into Score(studentId,english,math)
select 1,80,100 union
select 2,60,80 union
select 3,50,59 union
select 4,66,89 union
select 5,59,100--把现有表的数据插入到新表(表不能存在)
--select * into newStudent from student
--把现有表的数据复制到一个已存在的表(backupStudent 表必须已经存在)
--insert into backupStudent select * from students
字符串函数
LEN() :计算字符串长度 查询名字大于 2 的人
LOWER() 、 UPPER () :转小写、大写
LTRIM() :字符串左侧的空格去掉
RTRIM () :字符串右侧的空格去掉
LTRIM(RTRIM(' bb '))
LEFT() 、 RIGHT() 截取取字符串
SUBSTRING( string,start_position,length )
参数string为主字符串,start_position为子字符串在主字符串中的起始位置,length为子字符串的最大长度。SELECT SUBSTRING('abcdef111',2,3)
Replace
日期函数
GETDATE() :取得当前日期时间
DATEADD ( datepart , number, date ) ,计算增加以后的日期。参数 date 为待计算的日期;参数 number 为增量;参数 datepart 为计量单位,可选值见备注。 DATEADD(DAY, 3,date) 为计算日期 date 的 3 天后的日期,而 DATEADD(MONTH ,-8,date) 为计算日期 date 的 8 个月之前的日期
DATEDIFF ( datepart , startdate , enddate ) :计算两个日期之间的差额。 datepart 为计量单位,可取值参考 DateAdd 。
统计不同入学年数的学生个数: select DateDiff(year,sInDate,getdate())
,count(*) from student Group by DateDiff(year,sInDate,getdate())
DATEPART ( datepart,date ) :返回一个日期的特定部分
Select Year( getdate ())/Month()/Day
求本月出生的学生
统计学生的生日年份个数: select DatePart(year,sBirthday),count(*)
from student
group by DatePart(year, sBirthday)
空值处理函数:
执行备注中的代码
如果是 null 则用 value 来代替。
ISNULL( expression,value ) :如果 expression 不为空则返回 expression ,否则返回 value 。
select studentId,isnull (english,0) from score
类型转换函数:
Select ‘您的班级编号’ + 1 错误这里 + 是数学运算符
CAST ( expression AS data_type )
CONVERT ( data_type , expression)
Round() 、 Ceiling() 、 numeric(18,4) 保留两位小数
截取日期
对日期的转换。转换成各种国家格式的日期。
• select convert(varchar( 20 ),getdate(), 104 )
• Style 的格式,查 sql 帮助。(输入 convert 函数查询)
• 将日期转换为指定格式的字符串。 日期→字符串