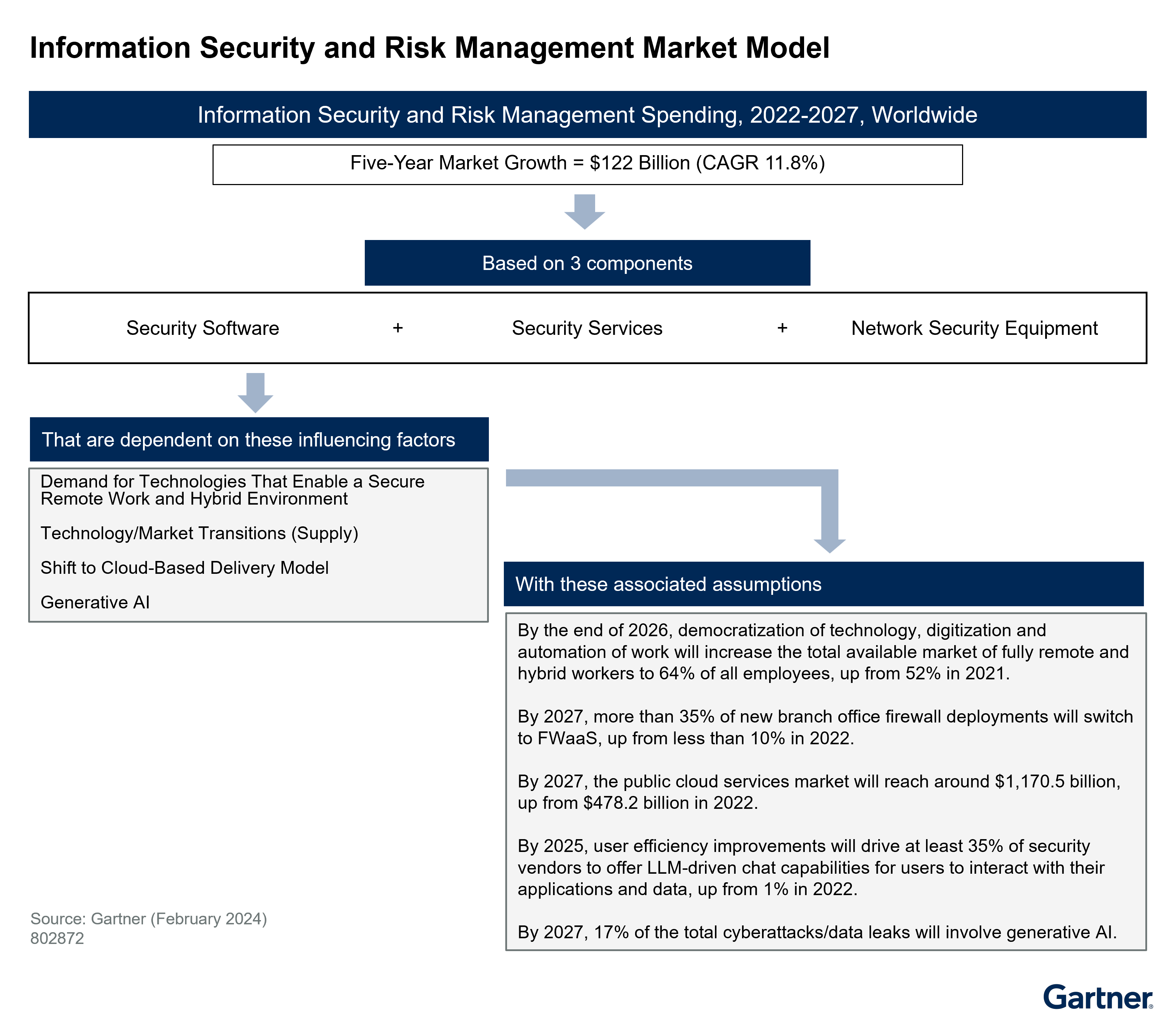
线上问题:新需求放量后频繁发生old gc
- 一、线上问题描述
- 二、处理问题过程
- 1、考虑机器扩容
- 1.1 预发环境复现该问题
- 1.2 预发环境机器扩容
- 1.3 预发环境验证
- 2、堆内存分析
- 2.1 内存分析
- 2.2 问题修复
- 三、复盘
一、线上问题描述
周四上线了一个新需求,该需求需要展示一个店铺下所有需要降价的商品,并且是sku维度展示。
该需求上线后,周四灰度了30%的量。
周五下午放量到50%后,过了半小时,cat 监控上出现了大量异常:
同时看了一下jvm的情况,出现了old gc,并且可以看到老年代内存有明显增加。在old gc 后老年代内存有所下降。


二、处理问题过程
1、考虑机器扩容
看了下异常类型,主要是dubbo接口服务超时,或者消费者超时(超过3s未响应),联想到上面出现的old gc,因此准备通过处理掉old gc来解决大量异常报错问题。
目前线上机器是4核12G,jvm配置的垃圾收集器是G1, jvm设置的堆内存大小是6G。
因此优先考虑的是内存扩容,所以准备先在预发环境上进行验证。
1.1 预发环境复现该问题
由于灰度30%时,集群qps是1000,因此预估线上全量灰度后的集群qps式3300。由于线上机器共12台,因此预估线上灰度100%后,单机qps预估是3300/12=275。
因此构建了一个线程数为275的线程池,在预发的单台机器上模拟该线上该接口的调用情况。
预发环境一调用该接口,果然马上由出现了old gc的现象。
1.2 预发环境机器扩容
- 预发环境机器扩容:4核12G --> 4核24G
- 预发环境jvm对内存参数变更:-xms=6g -xmx=6g --> -xms=12g -xmx=12g
1.3 预发环境验证
扩容后开始验证扩容是否有效,再次在预发环境调用该接口,一会儿还是出现了old gc问题。
2、堆内存分析
由于在预发环境扩容了机器内存,并且增加了堆内存大小,还是出现old gc的问题。因此不能简单地通过扩容来解决该问题,还是要分析清楚产生old gc的原因。
因此又回去看了下这个接口的相关代码,该接口返回的sku vo的个数虽然非常多,有1w+,但是sku vo单个对象并不大,该对象中只有5个long类型的字段和一个string类型的字段。算了一下,一个sku vo对象的大小也就大约60B(5个long类型字段大小40B,1个string类型字段预估大小20B)。
因此不太明白为什么会保存到老年代中。所以准备使用内存分析来分析下堆内存中的对象。
2.1 内存分析
由于线上还有30%的流量,因此准备直接来分析线上的对象。
1、开启dump内存
公司发布机器的流水线上提供dump内存的命令,点击开启后,过了大约5分钟,dump好了文件:
1)执行命令:heapdump
2)dump保存结果:xxx.hprof
2、分析内存
使用的是工具是visual vm 2.1.4
1)打开文件:
file -> load -> xxx.hprof
2)可以看到字符数组占了堆内存的37.9%,因此重点分析这块内存。

3)首先选择了排在前面的一个字符数组,然后点下References和GC Root分析。
在References窗口,一路往下点依赖,可以看到最终的依赖是Log4j组建。因此推测是因为打印日志时存在大对象,导致了old gc。然后在代码里搜了下这块业务的代码,确实有很多大对象的日志打印。

2.2 问题修复
通过内存分析出了问题后,首先把这块业务相关的大对象的日志打印都加了灰度(默认不打印),然后发上线。发上线之后半小时内,可以看到老年代里的内存明显开始下降,从2.3G下降到300M左右了。
随后开始继续放量,直至放量到100%,也没有再出现old gc了,且老年代的内存也维持在了300M左右。
至此,该问题彻底解决了!

三、复盘
遇到线上old gc问题,不能盲目内存扩容,更不能直接在线上机器上做操作。
本次遇到问题,先是在预发环境机器上做了内存扩容操作,但是并没有效果,浪费了0.5天的时间。
遇到old gc问题,还是要通过内存工具分析堆内存中最大的一些对象,通过对象产生的原因来分析如何处理。
经过本次经验,下次再有old gc的情况,可以优先考虑:
1、是否有大对象的日志打印
2、是否有内存泄漏的情况



![[C语言]——分支和循环(4)](https://img-blog.csdnimg.cn/direct/d0a718175c6245c2a7094d5c2b9fbc19.png)