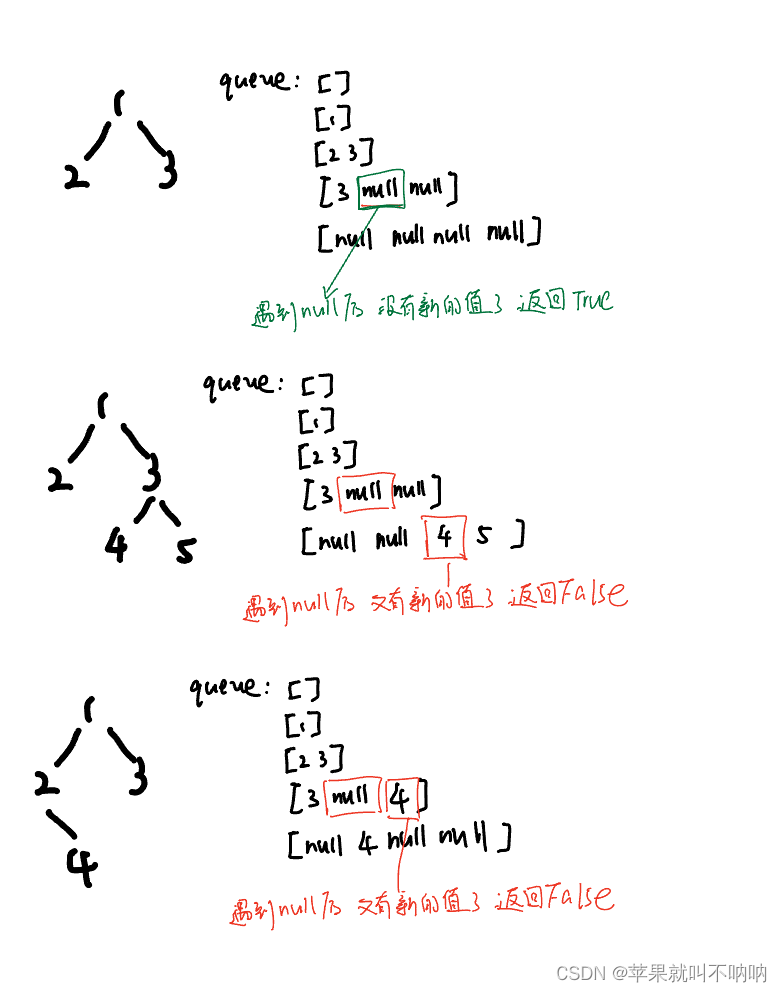
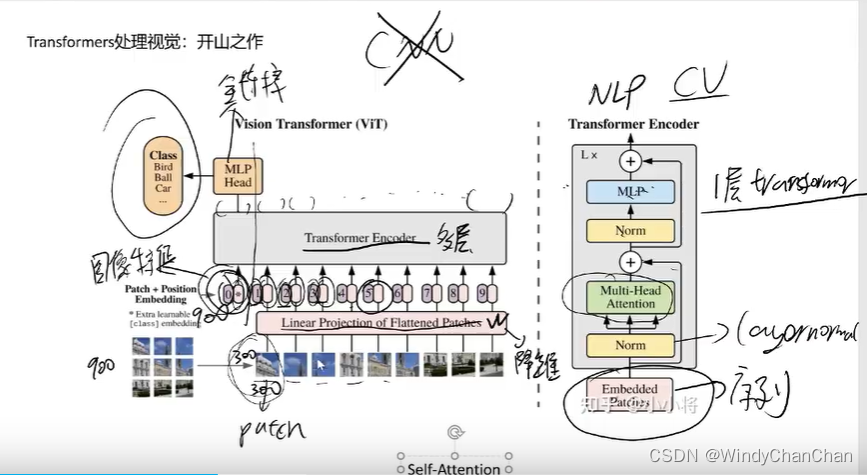
VIT处理图像
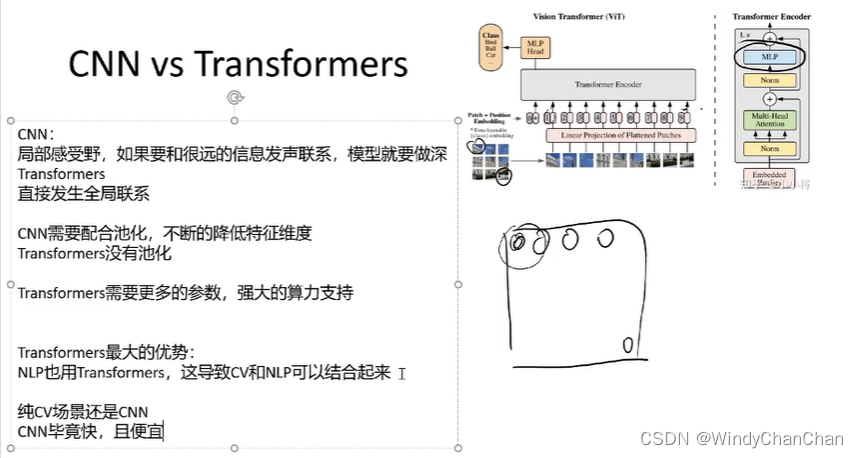
CNN VS Transformer
多模态BLIP模型
网络结构
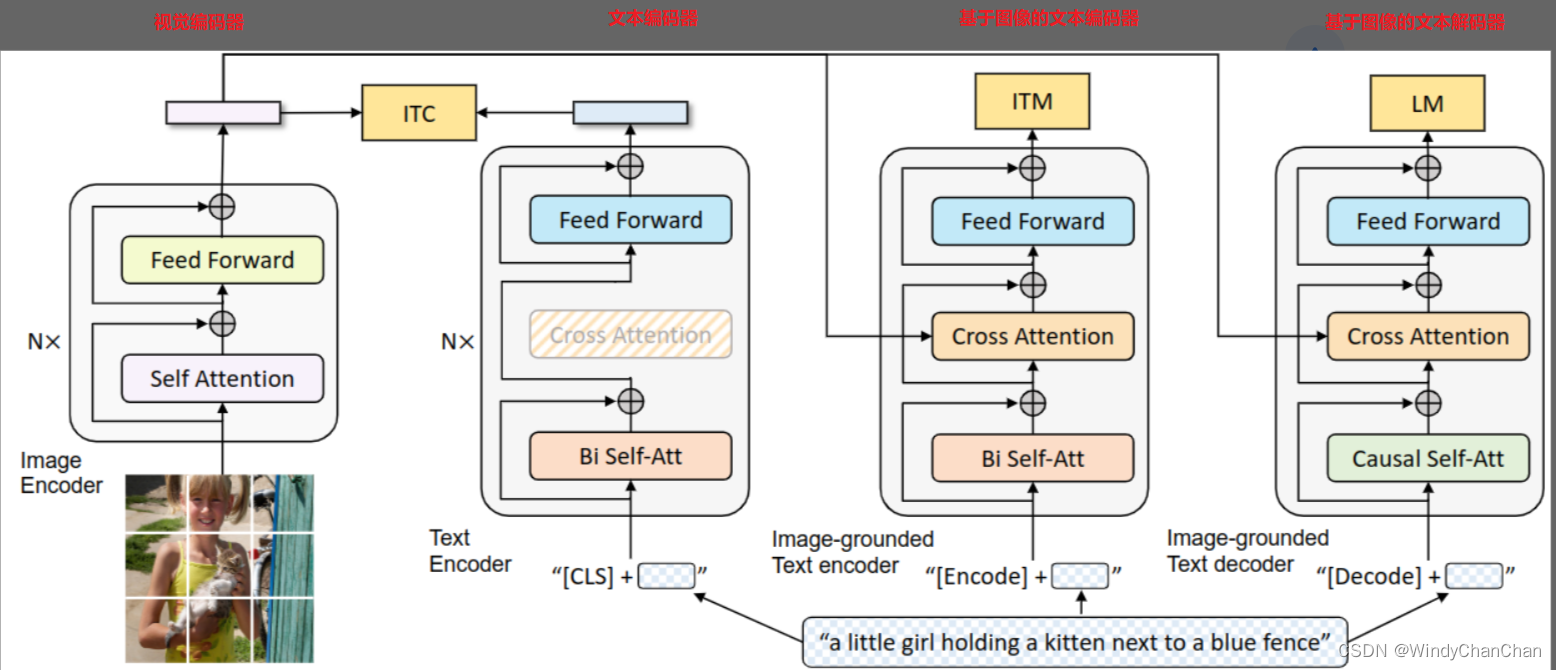
- 视觉编码器: 就是 ViT 的架构。将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征。视觉编码器不采用之前的基于目标检测器的形式,因为 ViLT 和 SimVLM 等工作已经证明了 ViT 计算更加友好。作用提取图像特征。
- 文本编码器:就是 BERT 的架构,其中 [CLS] token 附加到文本输入的开头以总结句子。作用是提取文本特征做对比学习。
- 基于图像的文本编码器:使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做二分类,所以使用的是编码器,且注意力部分是双向的 Self-Attention。添加一个额外的 [Encode] token,作为图像文本的联合表征。