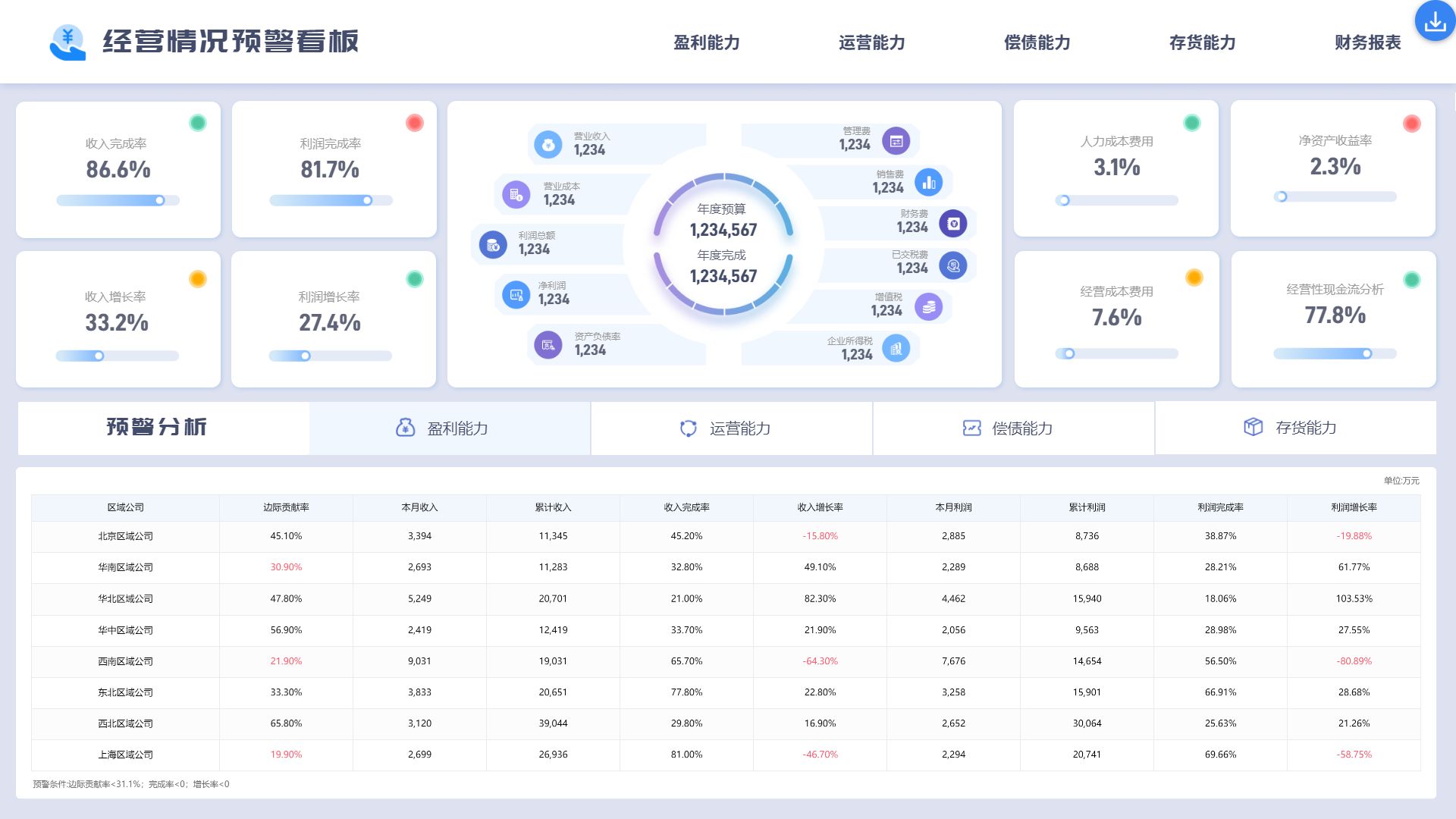
文章目录
- 一、概率问题
- 二、令牌(分词)
- 三、预测
一、概率问题
像 GPT 这样的大型语言模型接收一个提示,并返回通常在上下文中有意义的输出。例如,提示可以是“今天天气很好,所以我决定”(“The weather is nice today,so I decided to”),而模型输出可能是“去散步”。你可能想知道 LLM 模型是如何从输入提示构建这个输出文本的。正如你将看到的,这主要只是一个概率问题。
二、令牌(分词)
当将提示发送给一个LLM时,它首先将输入分解成称为令牌的较小部分。这些令牌代表单个单词或单词的一部分。例如,前面的提示可以分解如下:[“The”, “wea”, “ther”, “is”, “nice”, “today”, “,”, “so”, “I”, “de”, “ci”, “ded”, “to”]。每个语言模型都有自己的分词器。截至撰写本文时,尚无GPT-4的分词器可用,但您可以测试GPT-3的分词器。
提示:在估计单词长度方面理解令牌的一个经验法则是,对于英文文本,100个令牌大约相当于75个单词。
由于注意力机制和之前介绍的变换器架构,LLM可以处理这些令牌并解释它们之间的关系以及提示的整体含义。这种变换器架构使得模型能够高效地识别文本中的关键信息和上下文。
三、预测
为了创建一个新的句子,LLM根据提示的上下文预测最有可能的下一个令牌。OpenAI发布了两个版本的GPT-4,分别具有8,192个令牌和32,768个令牌的上下文窗口。与以前的循环模型不同,它们难以处理长输入序列,具有注意力机制的变换器架构使得现代LLM能够将整个上下文作为一个整体考虑。基于这个上下文,模型为每个可能的下一个令牌分配一个概率分数,并根据这个分数选择其中一个作为下一个令牌。在我们的例子中,在“今天天气很好,所以我决定”之后,下一个最佳令牌可能是“出去”。
然后这个过程会重复进行,但现在上下文变为“今天天气很好,所以我决定出去”,之前预测的令牌“出去”被添加到原始提示中。模型可能预测的第二个令牌可能是“散步”。这个过程会一直重复,直到形成完整的句子:“出去散步”。这个过程依赖于LLM从大量文本数据中学习下一个最可能的单词的能力。下图说明了这个过程。