在人工智能领域,大语言模型(LLMs)的发展已经取得了显著的进步,它们在处理高资源语言方面表现出色。然而,对于资源较少的语言,尤其是极低资源语言,这些模型的支持却显得力不从心。这些语言往往缺乏足够的训练数据来有效地更新模型参数,从而使得模型难以学习和理解这些语言。这一挑战引发了一个有趣的研究问题:LLMs是否能够仅通过提示(prompting)即时学习一种新的低资源语言?
为了探索这一问题,研究者选择了壮语作为研究对象,这是一种目前没有任何LLM支持的极低资源语言。通过收集壮语的研究套件ZHUANGBENCH,包括字典、平行语料库和机器翻译测试集,研究者引入了DIPMT++框架,旨在通过上下文学习(in-context learning)来适应未见过的语言。仅使用字典和5K平行句子,DIPMT++显著提高了GPT-4在中文到壮语翻译上的表现,从0提升到16 BLEU分,并在壮语到中文翻译上达到了32 BLEU分。此外,研究还展示了该框架在帮助人类翻译完全未见过的语言方面的实际效用,这可能有助于语言多样性的保护。
论文标题:Teaching Large Language Models an Unseen Language on the Fly
论文链接:https://arxiv.org/pdf/2402.19167.pdf
壮语言的挑战与ZHUANGBENCH研究套件的介绍
1. 壮语言的背景和NLP中的地位
壮语是中国南部壮族人使用的语言,拥有超过1600万使用者。它属于Kra–Dai语系,是一种孤立语言,具有很少的屈折变化。尽管使用人数众多,壮语在自然语言处理(NLP)领域却鲜有研究,目前没有开源的壮语NLP数据集,流行的多语言模型如mBERT、BLOOM和NLLB也未包含对壮语的支持。即便是商业模型如GPT-3.5和GPT-4,在处理壮语时也几乎没有能力,这凸显了对低资源语言开发NLP解决方案的挑战。
2. ZHUANGBENCH的组成和目的
为了研究模型如何通过提示学习一种全新的语言,研究者策划了ZHUANGBENCH研究套件,它包括Zhuang-Chinese字典、平行语料库和机器翻译测试集。ZHUANGBENCH不仅是壮语这一极低资源语言的宝贵语言资源,也是一个对LLMs来说具有挑战性的基准测试,可以用来探究模型如何通过提示学习一种全新的语言。
DIPMT++框架的创新之处
1. DIPMT++与传统DIPMT的对比
DIPMT++ 是基于DIPMT的改进框架,旨在通过上下文学习有效地适应未见过的语言。DIPMT是一种基于提示的低资源语言翻译方法,它通过查找源句中罕见词汇的字典条目,并将其直接添加到提示中。然而,DIPMT主要适用于LLMs已经具备基本能力的语言,对于完全未见过的语言,LLMs需要从头学习其词汇和语法,传统的提示方法几乎无效。DIPMT++通过两项关键改进,使LLMs能够利用有限的资源理解一种全新的语言。
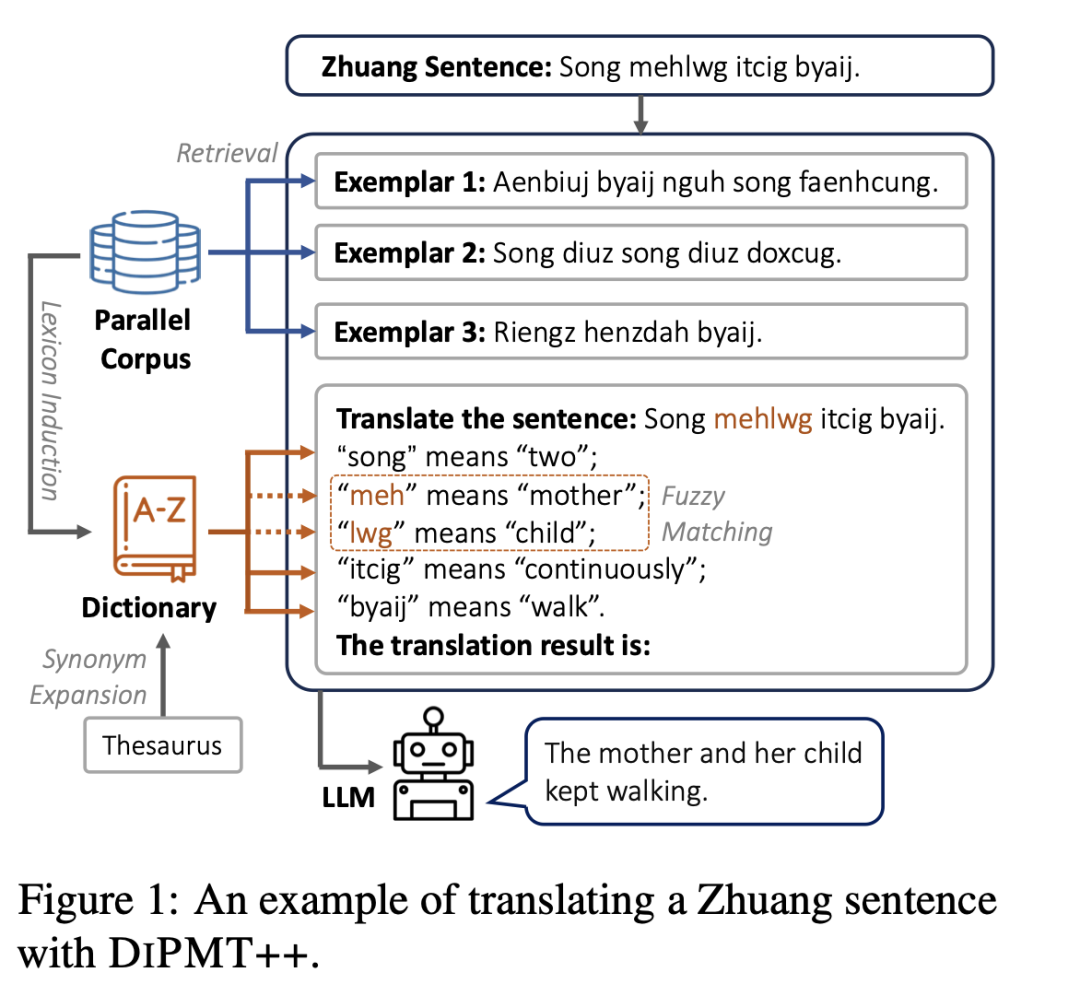
2. 提高词汇覆盖率的策略
DIPMT++通过回顾传统统计方法和语言资源来增强提示中的词汇覆盖率。具体策略包括:
-
复合词处理:对于在字典中直接找不到的词汇,可以使用字符串匹配算法从字典中快速找到相关条目。
-
双语词典归纳:即使是小规模的平行语料库也可能包含字典中没有的词汇。传统的统计方法如GIZA++可以高效地从语料库中挖掘双语词汇,补充字典。
-
同义词扩展:在高资源语言中翻译一个词时,可能找不到字典中的直接翻译,但字典可能包含该词的同义词条目。通过扩展字典来包含同义词列表,可以缓解这个问题。
3. 通过例句提升语法学习的方法
在DIPMT中,示例句子是固定的,与测 试实例的相关性有限,仅用于演示任务。当LLMs对未见过的语言的语法知之甚少时,这种方法几乎无效。DIPMT++尝试动态选择与测试实例更相关的示例句子,并鼓励模型从示例中推断基本的句法信息。
对于测试实例,其示例句子是从平行语料库中检索出来的。尽管有如DPR这样的高级检索器,但它们需要训练且不支持像状语这样的极低资源语言。因此,研究者们采用BM25,一种语言无关的检索算法。
实验设置:模型选择与基准线
1. 选择的模型和它们的特点
在实验中,研究者们选择了三种类型的模型作为DIPMT++ 框架的基础:LLaMA-2-chat,Qwen-chat,以及GPT-3.5-Turbo和GPT-4 。
-
LLaMA-2-chat是一个开源的以英语为中心的模型;
-
Qwen-chat是一个双语模型,支持英语和中文;
-
GPT-3.5-Turbo和GPT-4则是商业化的多语言模型。
这些模型的选择是为了评估DIPMT++在不同能力和规模的模型上的适用性和效果。2. 实验中使用的基准线和评价指标
实验中采用了多种基准线,包括直接微调模型、直接使用LLMs进行翻译(不提供ICL示例),以及使用原始DIPMT进行提示。评价指标方面,使用了BLEU和chrF两种指标,分别关注词级和字符级的翻译质量。
实验结果与分析
1. DIPMT++在ZHUANGBENCH上的表现
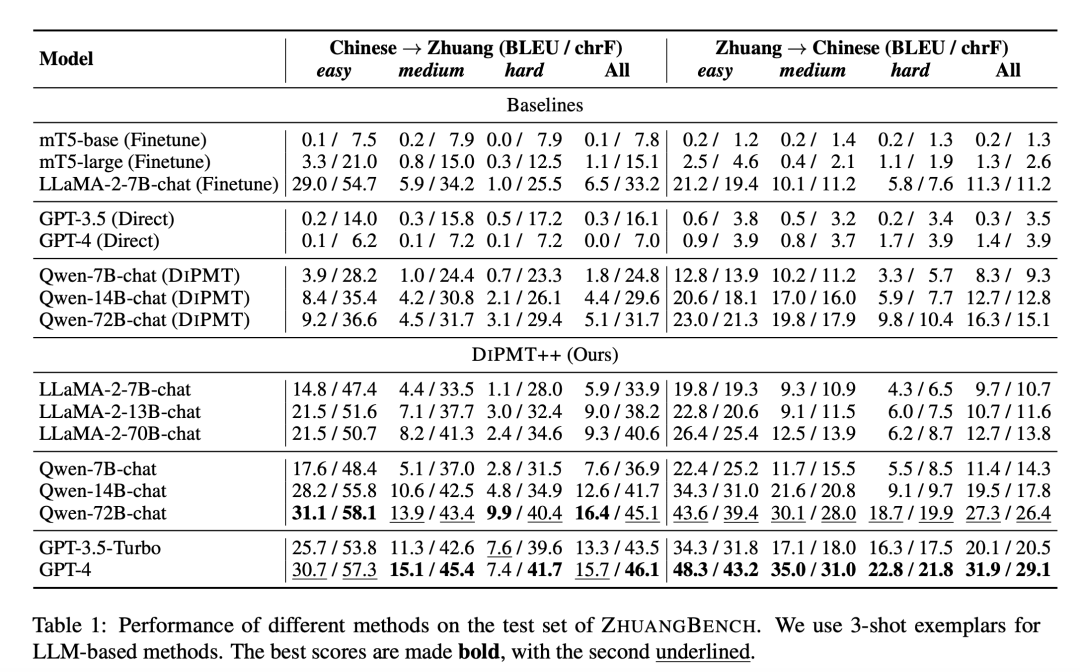
DIPMT++ 在ZHUANGBENCH上的表现显著优于其他提示基线和微调的较小模型。特别是当与GPT-4配对时,DIPMT++从几乎零的基线性能提升到了15.7的BLEU分数,用于中文到壮语的翻译,并且在壮语到中文的翻译中达到了31.9的BLEU分数。
2. DIPMT++在MTOB上的表现
在MTOB上,DIPMT++ 在大多数设置中都超过了原始论文中的基线,进一步证明了DIPMT++作为一个语言不可知的框架,能够适应不同的低资源语言,无需额外的努力。
3. 模型规模对性能的影响
在模型规模方面,研究者们观察到,随着模型参数的增加,性能稳步提升。
由于Qwen比以英语为中心的LLaMA-2具有更好的中文处理能力,一个14B的Qwen模型就能胜过一个70B的LLaMA-2。GPT-4在所有模型中表现最好,展示了其出色的推理能力。
值得注意的是,开源的Qwen-72B-chat在中文到壮语的任务上与封闭源的GPT-4表现相当,这对于更透明的研究是一个鼓舞人心的结果。
讨论:提高词汇覆盖率和语法学习的深入分析
教授LLMs语法规则的可能性
对于极低资源语言,如壮语,既没有大规模单语语料库用于语言建模,也没有现成的形式语法如上下文无关文法(CFG)可供使用。但是,考虑到LLMs强大的推理能力,研究者们探索了通过提示来教授LLMs语法规则的可能性。
DIPMT++通过检索与测试实例高度相关的示例来动态选择示例,希望模型能从示例中推断出基本的句法信息。除了BM25检索算法外,研究者们还尝试了基于词性序列的检索和随机采样,发现BM25检索的示例能够大幅提高翻译质量,因为它们包含与当前测试实例相关的更丰富的句法信息。
人类翻译辅助实验
1. 实验设计与参与者信息
研究者们进行了一项用户研究,以调查DIPMT++在现实场景中的适用性。他们招募了6名没有壮语知识的研究生,并要求他们使用给定的语言资源进行翻译。实验比较了三种设置:仅LLM、仅人类和人类+LLM。使用的模型是Qwen-14B-chat,选择了ZHUANGBENCH的简单子集作为测试实例。
2. 翻译质量和效率的比较
实验结果表明,与提供的语言资源相比,参与者能够正确翻译简单的未知语言句子。LLM在提高人类翻译质量方面表现出了增强效果。
-
例如,在zh2za翻译中,LLM帮助提高了人类性能2.5 BLEU分,而在za2zh翻译中,提高了2.9 BLEU分。
此外,LLM在zh2za翻译的效率上有显著提升,参与者平均节省了17%的时间。
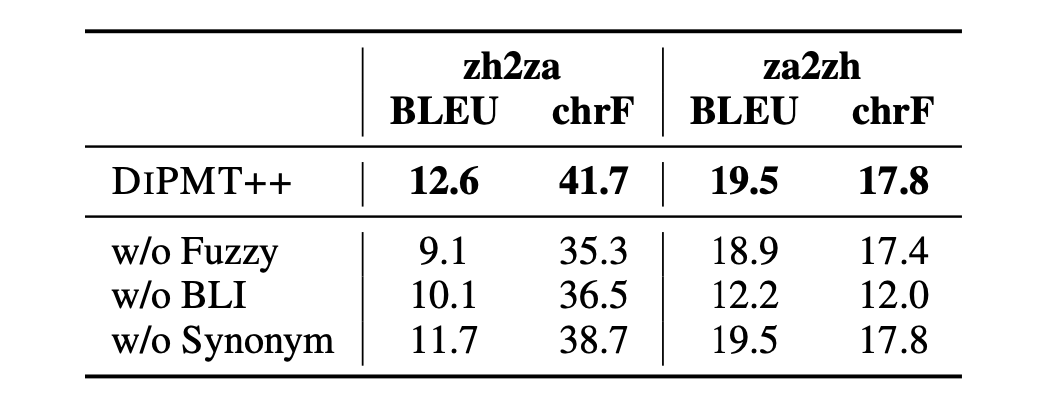
(图为使用Qwen-14B-chat在ZHUANGBENCH上提高词汇覆盖率的三种策略的消融研究)
3. 参与者在翻译过程中的行为分析
在za2zh翻译中,参与者平均每个实例进行了2.1次字典搜索和1.3次语料库搜索。对于更困难的zh2za翻译,搜索频率更高,平均每个实例进行了3.5次字典搜索和5.4次语料库搜索。许多参与者表现出在两种语言之间切换搜索的模式,旨在找到支持特定单词或短语翻译的n-gram证据。
这种策略与检索增强生成(RAG)框架内在一致,后者涉及交替进行检索和生成阶段。这些观察为即时语言学习提供了创新解决方案的见解。
总结与未来展望
1. DIPMT++的贡献和对未来研究的启示
DIPMT++ 作为一种新型的框架,通过上下文学习(ICL)有效地适应了未见过的语言,尤其是资源极其匮乏的壮语。通过使用字典和仅5000个平行句子,DIPMT++显著提高了GPT-4在中文到壮语翻译上的BLEU得分,从0提升至16,并在壮语到中文翻译上实现了32 BLEU的成绩。
此外,DIPMT++在协助人类翻译完全未见过的语言方面展现出了实际应用价值,这对于语言多样性的保护可能具有重要贡献。
DIPMT++的成功为未来的研究提供了启示,表明即使是对于极低资源语言,只要通过合理设计的提示(prompting),大语言模型也有能力进行有效学习。这一发现鼓励研究者们继续探索如何利用有限的资源来提升语言模型对低资源语言的支持,特别是在语言保存和教育等领域。
2. 对评估规模和研究方法的限制进行反思
尽管DIPMT++在实验中取得了显著的成果,但评估规模相对较小,主要基于200个中壮双语测试实例和50个英卡拉曼格语测试实例。未来的工作计划扩大测试集的规模,以便更全面地评估模型性能。
此外,尽管壮语和中文存在许多相似之处,但它们仍属于不同的语言家族,这可能导致对模型性能的过于乐观的结论。未来的研究应该涵盖更多差异性更大的语言对,以便获得更全面的理解。
在研究方法方面,目前对于显式学习句法信息的探索仅限于分析特定的句法现象,并使用链式推理(CoT)来辅助模型学习。尽管这种方法在某些情况下有效,但可能还有其他方法,如使用外部语法书,对于更强大的语言模型可能更为适合。由于预算限制,这些方法尚未得到充分探索。