Vision Transformer结构解析
- ViT简介
- ViT参数量
- ViT三大模块
- ViT图像预处理模块——PatchEmbed
- 多层Transformer Encoder模块
- MLP(FFN)模块
- 基本的Transformer模块
- Vision Transformer类的实现
- Transformer知识点
- 网络结构
- 计算复杂度对比
- Transformer的参数量和计算量
- Transformer的参数量
- Transformer的计算量
ViT简介
Vision Transformer。transformer于2017年的Attention is all your need提出,该模型最大的创新点就是将transformer应用于cv任务。
论文题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
论文链接:https://arxiv.org/pdf/2010.11929.pdf
代码地址:https://github.com/google-research/vision_transformer
ViT模型整体结构图如下:

ViT三种不同尺寸模型的参数对比:
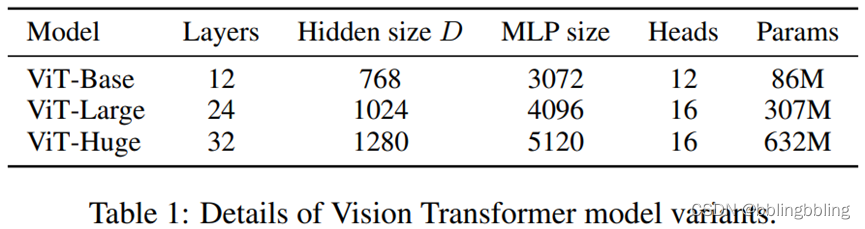
ViT参数量
vit_base_patch16_224,num_classes=5, has_logits=False
Total params: 85,650,437
Trainable params: 85,650,437
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 408.54
Params size (MB): 326.73
Estimated Total Size (MB): 735.84
----------------------------------------------------------------
vit_base_patch32_224,num_classes=5, has_logits=False
Total params: 87,419,909
Trainable params: 87,419,909
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 95.61
Params size (MB): 333.48
Estimated Total Size (MB): 429.66
----------------------------------------------------------------
vit_large_patch32_224,num_classes=5, has_logits=False
Total params: 305,463,301
Trainable params: 305,463,301
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 253.01
Params size (MB): 1165.25
Estimated Total Size (MB): 1418.84
vit_huge_patch14_224,num_classes=5, has_logits=False
Total params: 630,440,965
Trainable params: 630,440,965
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 2358.66
Params size (MB): 2404.94
Estimated Total Size (MB): 4764.17
----------------------------------------------------------------
网络结构打印,以常用的【vit_base_patch32_224,num_classes=5】为例:
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 768, 7, 7] 2,360,064Identity-2 [-1, 49, 768] 0PatchEmbed-3 [-1, 49, 768] 0Dropout-4 [-1, 50, 768] 0LayerNorm-5 [-1, 50, 768] 1,536Linear-6 [-1, 50, 2304] 1,771,776Dropout-7 [-1, 12, 50, 50] 0Linear-8 [-1, 50, 768] 590,592Dropout-9 [-1, 50, 768] 0Attention-10 [-1, 50, 768] 0Identity-11 [-1, 50, 768] 0LayerNorm-12 [-1, 50, 768] 1,536Linear-13 [-1, 50, 3072] 2,362,368GELU-14 [-1, 50, 3072] 0Dropout-15 [-1, 50, 3072] 0Linear-16 [-1, 50, 768] 2,360,064Dropout-17 [-1, 50, 768] 0Mlp-18 [-1, 50, 768] 0Identity-19 [-1, 50, 768] 0Block-20 [-1, 50, 768] 0LayerNorm-21 [-1, 50, 768] 1,536Linear-22 [-1, 50, 2304] 1,771,776Dropout-23 [-1, 12, 50, 50] 0Linear-24 [-1, 50, 768] 590,592Dropout-25 [-1, 50, 768] 0Attention-26 [-1, 50, 768] 0Identity-27 [-1, 50, 768] 0LayerNorm-28 [-1, 50, 768] 1,536Linear-29 [-1, 50, 3072] 2,362,368GELU-30 [-1, 50, 3072] 0Dropout-31 [-1, 50, 3072] 0Linear-32 [-1, 50, 768] 2,360,064Dropout-33 [-1, 50, 768] 0Mlp-34 [-1, 50, 768] 0Identity-35 [-1, 50, 768] 0Block-36 [-1, 50, 768] 0LayerNorm-37 [-1, 50, 768] 1,536Linear-38 [-1, 50, 2304] 1,771,776Dropout-39 [-1, 12, 50, 50] 0Linear-40 [-1, 50, 768] 590,592Dropout-41 [-1, 50, 768] 0Attention-42 [-1, 50, 768] 0Identity-43 [-1, 50, 768] 0LayerNorm-44 [-1, 50, 768] 1,536Linear-45 [-1, 50, 3072] 2,362,368GELU-46 [-1, 50, 3072] 0Dropout-47 [-1, 50, 3072] 0Linear-48 [-1, 50, 768] 2,360,064Dropout-49 [-1, 50, 768] 0Mlp-50 [-1, 50, 768] 0Identity-51 [-1, 50, 768] 0Block-52 [-1, 50, 768] 0LayerNorm-53 [-1, 50, 768] 1,536Linear-54 [-1, 50, 2304] 1,771,776Dropout-55 [-1, 12, 50, 50] 0Linear-56 [-1, 50, 768] 590,592Dropout-57 [-1, 50, 768] 0Attention-58 [-1, 50, 768] 0Identity-59 [-1, 50, 768] 0LayerNorm-60 [-1, 50, 768] 1,536Linear-61 [-1, 50, 3072] 2,362,368GELU-62 [-1, 50, 3072] 0Dropout-63 [-1, 50, 3072] 0Linear-64 [-1, 50, 768] 2,360,064Dropout-65 [-1, 50, 768] 0Mlp-66 [-1, 50, 768] 0Identity-67 [-1, 50, 768] 0Block-68 [-1, 50, 768] 0LayerNorm-69 [-1, 50, 768] 1,536Linear-70 [-1, 50, 2304] 1,771,776Dropout-71 [-1, 12, 50, 50] 0Linear-72 [-1, 50, 768] 590,592Dropout-73 [-1, 50, 768] 0Attention-74 [-1, 50, 768] 0Identity-75 [-1, 50, 768] 0LayerNorm-76 [-1, 50, 768] 1,536Linear-77 [-1, 50, 3072] 2,362,368GELU-78 [-1, 50, 3072] 0Dropout-79 [-1, 50, 3072] 0Linear-80 [-1, 50, 768] 2,360,064Dropout-81 [-1, 50, 768] 0Mlp-82 [-1, 50, 768] 0Identity-83 [-1, 50, 768] 0Block-84 [-1, 50, 768] 0LayerNorm-85 [-1, 50, 768] 1,536Linear-86 [-1, 50, 2304] 1,771,776Dropout-87 [-1, 12, 50, 50] 0Linear-88 [-1, 50, 768] 590,592Dropout-89 [-1, 50, 768] 0Attention-90 [-1, 50, 768] 0Identity-91 [-1, 50, 768] 0LayerNorm-92 [-1, 50, 768] 1,536Linear-93 [-1, 50, 3072] 2,362,368GELU-94 [-1, 50, 3072] 0Dropout-95 [-1, 50, 3072] 0Linear-96 [-1, 50, 768] 2,360,064Dropout-97 [-1, 50, 768] 0Mlp-98 [-1, 50, 768] 0Identity-99 [-1, 50, 768] 0Block-100 [-1, 50, 768] 0LayerNorm-101 [-1, 50, 768] 1,536Linear-102 [-1, 50, 2304] 1,771,776Dropout-103 [-1, 12, 50, 50] 0Linear-104 [-1, 50, 768] 590,592Dropout-105 [-1, 50, 768] 0Attention-106 [-1, 50, 768] 0Identity-107 [-1, 50, 768] 0LayerNorm-108 [-1, 50, 768] 1,536Linear-109 [-1, 50, 3072] 2,362,368GELU-110 [-1, 50, 3072] 0Dropout-111 [-1, 50, 3072] 0Linear-112 [-1, 50, 768] 2,360,064Dropout-113 [-1, 50, 768] 0Mlp-114 [-1, 50, 768] 0Identity-115 [-1, 50, 768] 0Block-116 [-1, 50, 768] 0LayerNorm-117 [-1, 50, 768] 1,536Linear-118 [-1, 50, 2304] 1,771,776Dropout-119 [-1, 12, 50, 50] 0Linear-120 [-1, 50, 768] 590,592Dropout-121 [-1, 50, 768] 0Attention-122 [-1, 50, 768] 0Identity-123 [-1, 50, 768] 0LayerNorm-124 [-1, 50, 768] 1,536Linear-125 [-1, 50, 3072] 2,362,368GELU-126 [-1, 50, 3072] 0Dropout-127 [-1, 50, 3072] 0Linear-128 [-1, 50, 768] 2,360,064Dropout-129 [-1, 50, 768] 0Mlp-130 [-1, 50, 768] 0Identity-131 [-1, 50, 768] 0Block-132 [-1, 50, 768] 0LayerNorm-133 [-1, 50, 768] 1,536Linear-134 [-1, 50, 2304] 1,771,776Dropout-135 [-1, 12, 50, 50] 0Linear-136 [-1, 50, 768] 590,592Dropout-137 [-1, 50, 768] 0Attention-138 [-1, 50, 768] 0Identity-139 [-1, 50, 768] 0LayerNorm-140 [-1, 50, 768] 1,536Linear-141 [-1, 50, 3072] 2,362,368GELU-142 [-1, 50, 3072] 0Dropout-143 [-1, 50, 3072] 0Linear-144 [-1, 50, 768] 2,360,064Dropout-145 [-1, 50, 768] 0Mlp-146 [-1, 50, 768] 0Identity-147 [-1, 50, 768] 0Block-148 [-1, 50, 768] 0LayerNorm-149 [-1, 50, 768] 1,536Linear-150 [-1, 50, 2304] 1,771,776Dropout-151 [-1, 12, 50, 50] 0Linear-152 [-1, 50, 768] 590,592Dropout-153 [-1, 50, 768] 0Attention-154 [-1, 50, 768] 0Identity-155 [-1, 50, 768] 0LayerNorm-156 [-1, 50, 768] 1,536Linear-157 [-1, 50, 3072] 2,362,368GELU-158 [-1, 50, 3072] 0Dropout-159 [-1, 50, 3072] 0Linear-160 [-1, 50, 768] 2,360,064Dropout-161 [-1, 50, 768] 0Mlp-162 [-1, 50, 768] 0Identity-163 [-1, 50, 768] 0Block-164 [-1, 50, 768] 0LayerNorm-165 [-1, 50, 768] 1,536Linear-166 [-1, 50, 2304] 1,771,776Dropout-167 [-1, 12, 50, 50] 0Linear-168 [-1, 50, 768] 590,592Dropout-169 [-1, 50, 768] 0Attention-170 [-1, 50, 768] 0Identity-171 [-1, 50, 768] 0LayerNorm-172 [-1, 50, 768] 1,536Linear-173 [-1, 50, 3072] 2,362,368GELU-174 [-1, 50, 3072] 0Dropout-175 [-1, 50, 3072] 0Linear-176 [-1, 50, 768] 2,360,064Dropout-177 [-1, 50, 768] 0Mlp-178 [-1, 50, 768] 0Identity-179 [-1, 50, 768] 0Block-180 [-1, 50, 768] 0LayerNorm-181 [-1, 50, 768] 1,536Linear-182 [-1, 50, 2304] 1,771,776Dropout-183 [-1, 12, 50, 50] 0Linear-184 [-1, 50, 768] 590,592Dropout-185 [-1, 50, 768] 0Attention-186 [-1, 50, 768] 0Identity-187 [-1, 50, 768] 0LayerNorm-188 [-1, 50, 768] 1,536Linear-189 [-1, 50, 3072] 2,362,368GELU-190 [-1, 50, 3072] 0Dropout-191 [-1, 50, 3072] 0Linear-192 [-1, 50, 768] 2,360,064Dropout-193 [-1, 50, 768] 0Mlp-194 [-1, 50, 768] 0Identity-195 [-1, 50, 768] 0Block-196 [-1, 50, 768] 0LayerNorm-197 [-1, 50, 768] 1,536Identity-198 [-1, 768] 0Linear-199 [-1, 5] 3,845
================================================================
ViT三大模块
ViT主要包含三大模块:PatchEmbed、多层Transformer Encoder、MLP(FFN),下面用结构图和代码解析这第三大模块。
ViT图像预处理模块——PatchEmbed
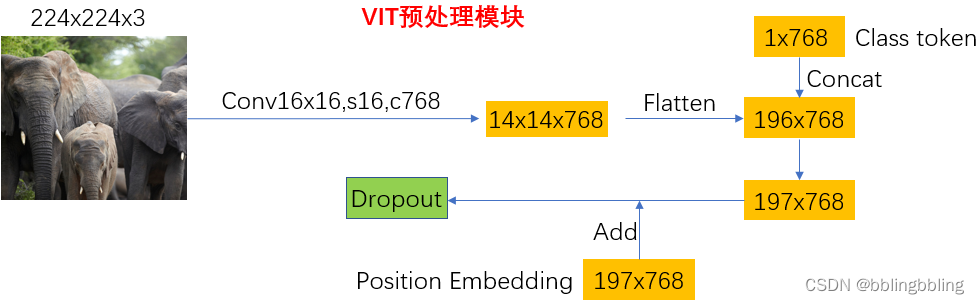
VIT划分patches的原理:
输入图像尺寸(224x224x3),按16x16的大小进行划分,共(224x224) / (16x16) = 196个patches,每个patch的维度为(16x16x3),为满足Transformer的需求,对每个patch进行投影,[16, 16, 3]->[768],这样就将原始的[224, 224, 3]转化为[196, 768]。
代码实现如下:
class PatchEmbed(nn.Module):"""2D Image to Patch Embedding,二维图像patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size) # 图片尺寸224*224patch_size = (patch_size, patch_size) #下采样倍数,一个grid cell包含了16*16的图片信息self.img_size = img_sizeself.patch_size = patch_size# grid_size是经过patchembed后的特征层的尺寸self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1] #path个数 14*14=196# 通过一个卷积,完成patchEmbedself.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)# 如果使用了norm层,如BatchNorm2d,将通道数传入,以进行归一化,否则进行恒等映射self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shape #batch,channels,heigth,weigth# 输入图片的尺寸要满足既定的尺寸assert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# proj: [B, C, H, W] -> [B, C, H,W] , [B,3,224,224]-> [B,768,14,14]# flatten: [B, C, H, W] -> [B, C, HW] , [B,768,14,14]-> [B,768,196]# transpose: [B, C, HW] -> [B, HW, C] , [B,768,196]-> [B,196,768]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
多层Transformer Encoder模块
该模块的主要结构是Muti-head Attention,也就是self-attention,它能够使得网络看到全局的信息,而不是CNN的局部感受野。
self-attention的结构示例如下:
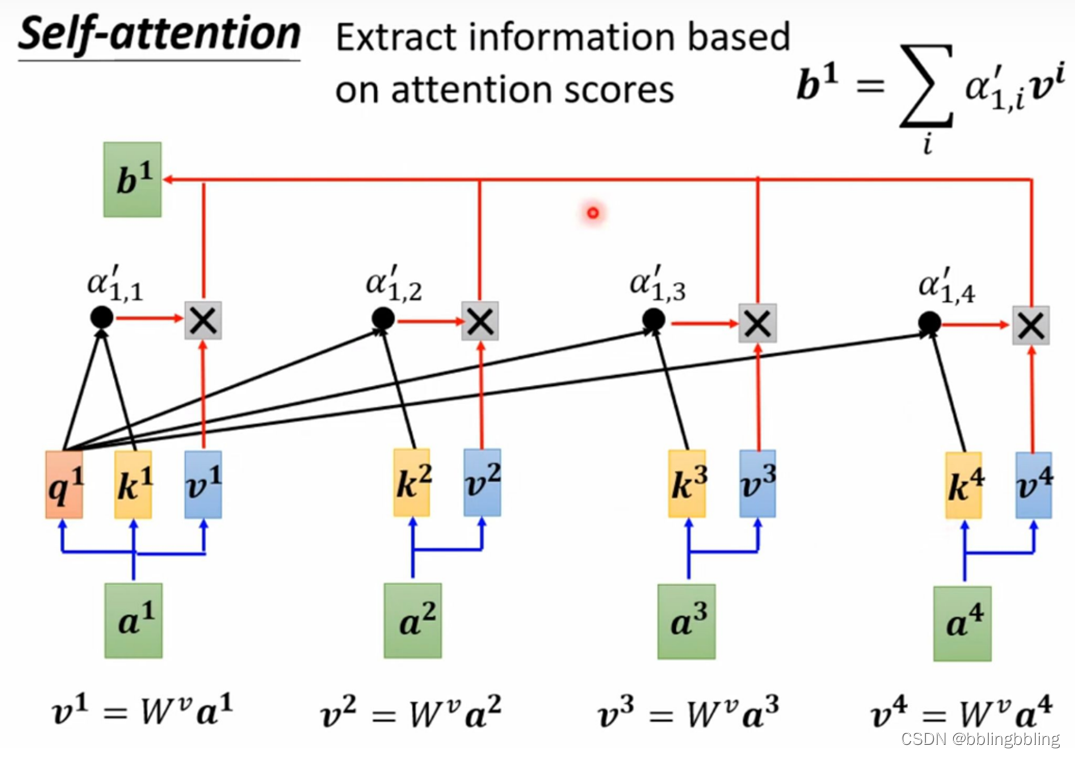
class Attention(nn.Module):"""muti-head attention模块,也是transformer最主要的操作"""def __init__(self,dim, # 输入token的dim,768num_heads=8, #muti-head的head个数,实例化时base尺寸的vit默认为12qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_heads #平均每个head的维度self.scale = qk_scale or head_dim ** -0.5 #进行query操作时,缩放因子# qkv矩阵相乘操作,dim * 3使得一次性进行qkv操作self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim) self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim] 如 [bactn,197,768]B, N, C = x.shape # N:197 , C:768# qkv进行注意力操作,reshape进行muti-head的维度分配,permute维度调换以便后续操作# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim] 如 [b,197,2304]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head] 如 [b,197,3,12,64]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# qkv的维度相同,[batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scale #矩阵相乘操作attn = attn.softmax(dim=-1) #每一path进行softmax操作attn = self.attn_drop(attn)# [b,12,197,197]@[b,12,197,64] -> [b,12,197,64]# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# 维度交换 transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x) #经过一层卷积x = self.proj_drop(x) #Dropoutreturn x
MLP(FFN)模块
一个MLP模块的结构如下:
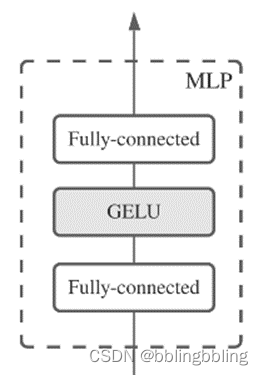
class Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None,act_layer=nn.GELU, # GELU是更加平滑的reludrop=0.):super().__init__()out_features = out_features or in_features #如果out_features不存在,则为in_featureshidden_features = hidden_features or in_features #如果hidden_features不存在,则为in_featuresself.fc1 = nn.Linear(in_features, hidden_features) # fc层1self.act = act_layer() #激活self.fc2 = nn.Linear(hidden_features, out_features) # fc层2self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
基本的Transformer模块
由Self-attention和MLP可以组合成Transformer的基本模块。Transformer的基本模块还使用了残差连接结构。
一个Transformer Block的结构如下:
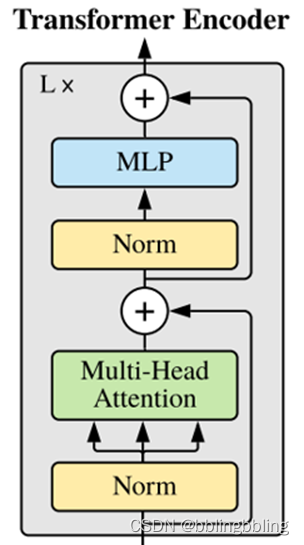
class Block(nn.Module):"""基本的Transformer模块"""def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):super(Block, self).__init__()self.norm1 = norm_layer(dim) #norm层self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here# 代码使用了DropPath,而不是原版的dropoutself.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()self.norm2 = norm_layer(dim) #norm层mlp_hidden_dim = int(dim * mlp_ratio) #隐藏层维度扩张后的通道数# 多层感知机self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x))) # attention后残差连接x = x + self.drop_path(self.mlp(self.norm2(x))) # mlp后残差连接return x
Vision Transformer类的实现
class VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_c (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim ** -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdistilled (bool): model includes a distillation token and head as in DeiT modelsdrop_ratio (float): dropout rateattn_drop_ratio (float): attention dropout ratedrop_path_ratio (float): stochastic depth rateembed_layer (nn.Module): patch embedding layernorm_layer: (nn.Module): normalization layer"""super(VisionTransformer, self).__init__()self.num_classes = num_classes #分类类别数量self.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsself.num_tokens = 2 if distilled else 1 #distilled在vit中没有使用到norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6) #层归一化act_layer = act_layer or nn.GELU #激活函数self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) #[1,1,768],以0填充self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else Noneself.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))self.pos_drop = nn.Dropout(p=drop_ratio)# 按照block数量等间距设置drop率dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay ruleself.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim) # layer_norm# Representation layerif representation_size and not distilled:self.has_logits = Trueself.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:self.has_logits = Falseself.pre_logits = nn.Identity()# Classifier head(s),分类头,self.num_features=768self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight init,权重初始化nn.init.trunc_normal_(self.pos_embed, std=0.02)if self.dist_token is not None:nn.init.trunc_normal_(self.dist_token, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)self.apply(_init_vit_weights)def forward_features(self, x):# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# cls_token类别token [1, 1, 768] -> [B, 1, 768],扩张为batch个cls_tokencls_token = self.cls_token.expand(x.shape[0], -1, -1)if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 196, 768]-> [B, 197, 768],维度1上的catelse:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_drop(x + self.pos_embed) #添加位置嵌入信息x = self.blocks(x) #通过attention堆叠模块(12个)x = self.norm(x) #layer_normif self.dist_token is None:return self.pre_logits(x[:, 0]) #返回第一层特征,即为分类值else:return x[:, 0], x[:, 1]def forward(self, x):# 分类头x = self.forward_features(x) # 经过att操作,但是没有进行分类头的前传if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return x
Transformer知识点
论文:Attention Is All You Need
论文地址:https://arxiv.org/pdf/1706.03762.pdf
Transformer由Attention和Feed Forward Neural Network(也称FFN)组成,其中Attention包含self Attention与Mutil-Head Attention。
网络结构
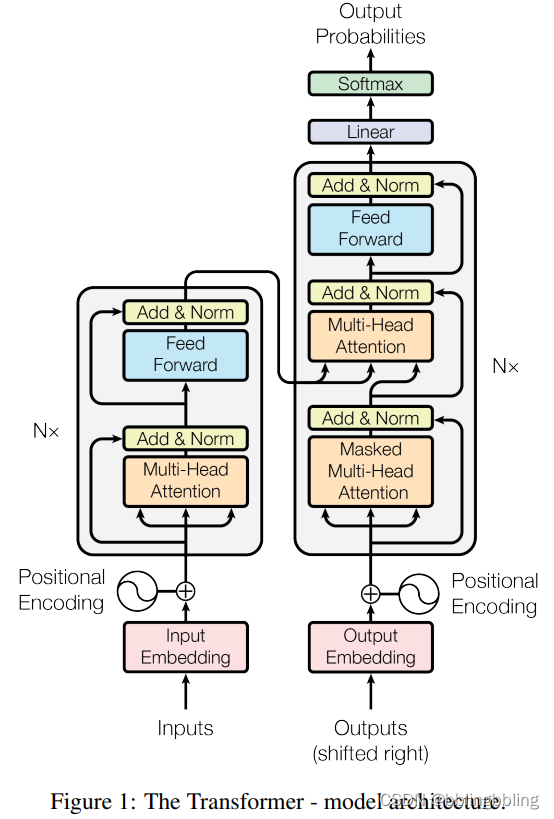
attention和multi-head-attention结构:
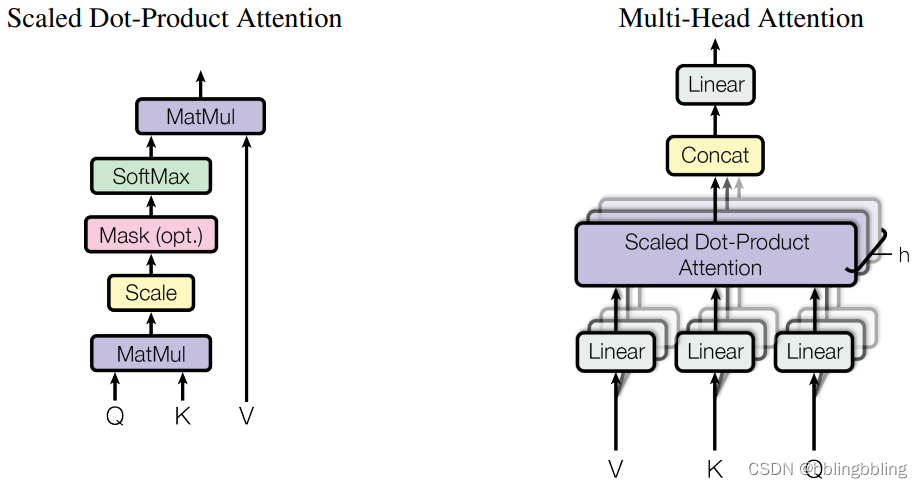
计算过程:

计算复杂度对比

Transformer的参数量和计算量
transformer模型由L个相同的层组成,每个层分为两部分:self-attention块和MLP块。
为表示方便,下面统一记transformer模型的层数为 l l l,隐藏层维度为 h h h,注意力头数为 a a a。词表大小为 V V V,训练数据的批次大小为 b b b,序列长度为 s s s。
Transformer的参数量
self-attention块的模型参数有Q、K、V的权重矩阵Wq、Wk、Wv和偏置,输出权重矩阵Wo和偏置,4个权重矩阵的形状为 [ h , h ] [h,h] [h,h],4个偏置的形状为 [ h ] [h] [h]。所以self- attention块的参数量为 4 h 2 + 4 h 4h^{2}+4h 4h2+4h。
MLP块由2个线性层组成,一般地,第一个线性层是先将维度从 h h h映射到 4 h 4h 4h,第二个线性层再将维度从 4 h 4h 4h映射到 h h h。第一个线性层的权重矩阵W1的形状为 [ h , 4 h ] [h,4h] [h,4h],偏置的形状为 [ 4 h ] [4h] [4h]。第二个线性层权重矩阵W2的形状为 [ 4 h , h ] [4h,h] [4h,h],偏置形状为 [ h ] [h] [h]。MLP块的参数量为 8 h 2 + 5 h 8h^{2}+5h 8h2+5h。
self-attention块和MLP块各有一个layer normalization,包含了2个可训练模型参数:缩放参数 γ \gamma γ和平移参数 β \beta β,形状都是 [ h ] [h] [h]。2个layer normalization的参数量为 4 h 4h 4h。
所以,每个transformer层的参数量为 4 h 2 + 4 h + 8 h 2 + 5 h + 4 h = 12 h 2 + 13 h 4h^{2}+4h+ 8h^{2}+5h+4h=12h^{2}+13h 4h2+4h+8h2+5h+4h=12h2+13h。
除此之外,词嵌入矩阵的参数量也较多,词向量维度通常等于隐藏层维度 h h h,词嵌入矩阵的参数量为 V h Vh Vh。最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的。
综上, 层transformer模型的可训练模型参数量为 l ( 12 h 2 + 13 h ) + V h l(12h^{2}+13h)+Vh l(12h2+13h)+Vh。当隐藏维度 h h h较大时,可以忽略一次项,模型参数量近似为 12 l h 2 12lh^{2} 12lh2。