目录
- 一、原文
- 二、故事前半段背景内容
- 三、正经的讲点DrissionPage知识
- 四、故事的收尾
一、原文
- 原文来自一个爬虫自动化数据采集的故事~ , 建议点击链接看文章末尾的视频
- 笔者不擅长自动化,一个小小故事分享给大家,仅个人观点
二、故事前半段背景内容
以下文章来自,网友小时投稿,仅供十一姐使用
有时候她幻想自己会幽默点,会成为一个小说家,一个会讲故事的人…
所以那天,她奋笔疾书,用尽她不太多的词汇脑洞写下如下的内容…
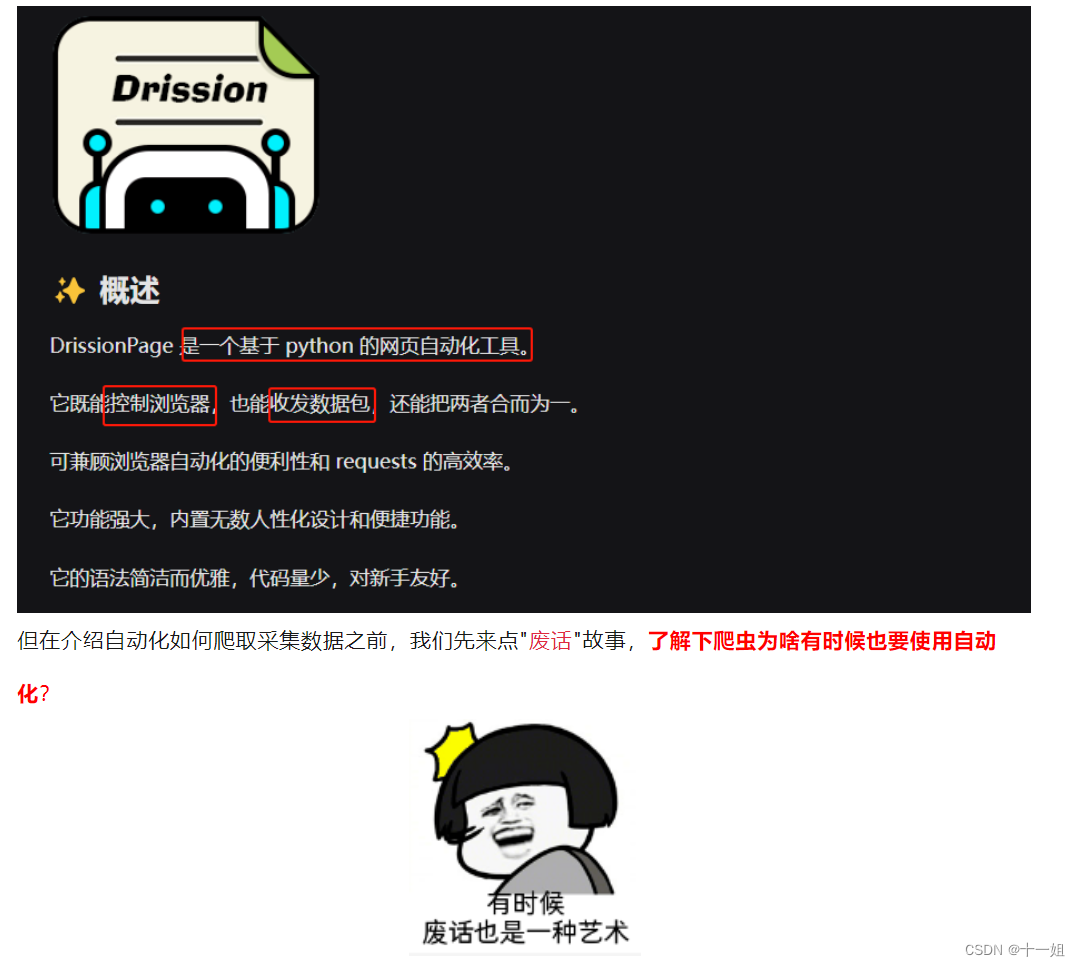
hello, 大家好,我是十一姐,今天和大家分享一个在爬虫圈里,被不少人安利的自动化库Drissionpage,它可以通过控制浏览器跟网页进行交互爬取数据,它的官方使用文档https://g1879.gitee.io/drissionpagedocs/get_start/installation
相信绝大多数使用爬虫获取数据的人,他们一贯的方式可能都是直接找数据接口,然后模拟接口请求向服务器发送数据包,最终获得想要的数据
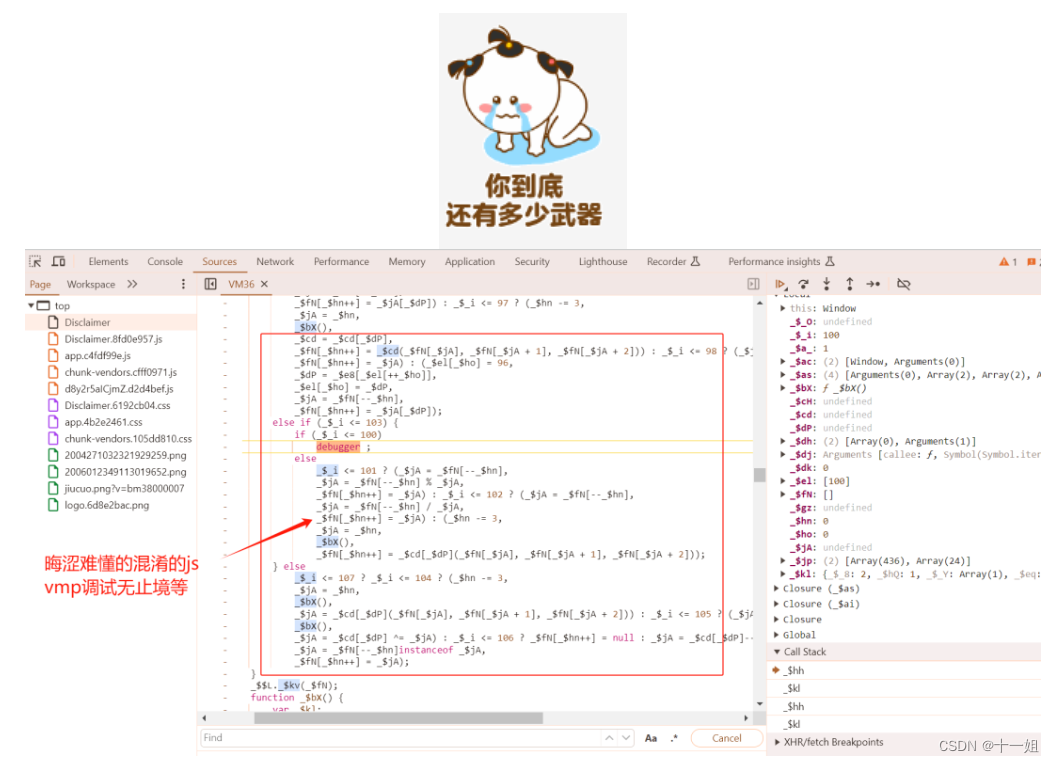
但这也让他们面临着更大的挑战,比如他们时常会遇到各种反爬,如加密/混淆/vmp/反调试/验证码/风控/封ip账号等等,甚至等爬虫人破解完了,后面还有无限的人机风控等着他,封账号/封ip/封指纹, 它到底在哪里埋了蜜罐,哪里设置了陷阱,能够如此精准的识别"我不是个人" (ps: 这里的“我”指的是爬虫代码脚本程序)
举个例子,他们会遇到各种丧心病狂反人类的验证码反爬,如果“我”是个人,“我”都不敢相信“我”这个人可能会选择点击正确,当然,说得有点夸张了,使用这些比较反人类的验证码的网站还是比较少的,实际上大多数网站的验证码还是比较考虑“真实的人”感受的

所以当那些加密算法破解越来越耗时/风控越来越强时,爬虫人的头发似乎可能也开始日渐稀疏时......

他的眼神开始越来越空洞,不知何时是头,不知何时能破,要一周吗,NoNo,要一个月吗,NoNoNo,到底要多久呀,到底什么才是头呀,这就反爬对爬虫的折磨

于是向天呐喊,有没有大佬指点指点帮助帮助呀…请赐我一个所谓的逆向大神吧, 然而现实中,神面对众多繁星的愿望,虽有心而力不足,他也很无奈,神也有自己想忙的事情

所以,与其继续坚持逆向下去,有时候妥协放弃也是一种勇气,但倔强的我,舍不得,难道之前的努力就白费了吗,就这么隐藏入尘埃了吗,爬虫人儿势必要给反爬点颜色瞧瞧,哪怕是蚊子痛也行
于是,为了短时间的拿到了少量的数据用来应急入库,那个曾经被爬虫一部分人嗤之以鼻的最朴素的方法,并且认为速度太慢的自动化,而现在又回去求”怀抱“, 慢慢爬也未尝不可,真香永不过时

接下来我们要提一提,爬虫程序曾“临幸过”哪些第三方自动化爬取的库/项目,截图来自网站https://spiderbox.cn/, 比如sekiro、jsrpc,大家熟悉的selenium/undetected_selenium/puppeteer , 以及后来大家非常喜欢的playwright 等等
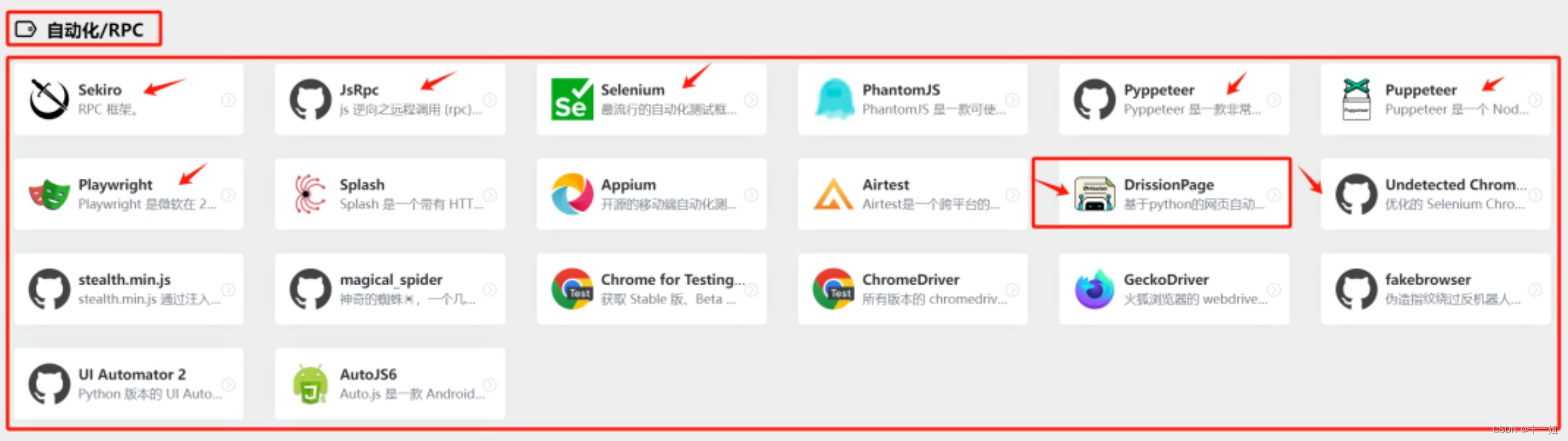
有个伟人讲过,不管黑猫白猫,能抓住老鼠的都是好猫

所以工具不再乎多,只要能用就是好猫,我本身并不擅长自动化,但是在爬虫圈圈里大家都在提drissionpage,可以过国外反爬"五秒盾cloudflare / shape /Google 等人机检测工具"时, 不得不说它此刻确实有点无敌强大

毕竟之前用过的很多老版的自动化会被反爬检测特征指纹什么的,于是作者也感慨到,或许是幸运,大厂们还没意识到”我DrissionPage“的出现,所以还未曾对我实施监控,未曾对我痛下杀手
当然,那只是浅浅的感慨,可能之所以不被检测到,是因为DrissionPage的底层基于cdp协议(Chrome DevTools Protocol),以下是懒神推荐读的cdp代码 https://chromedevtools.github.io/devtools-protocol/

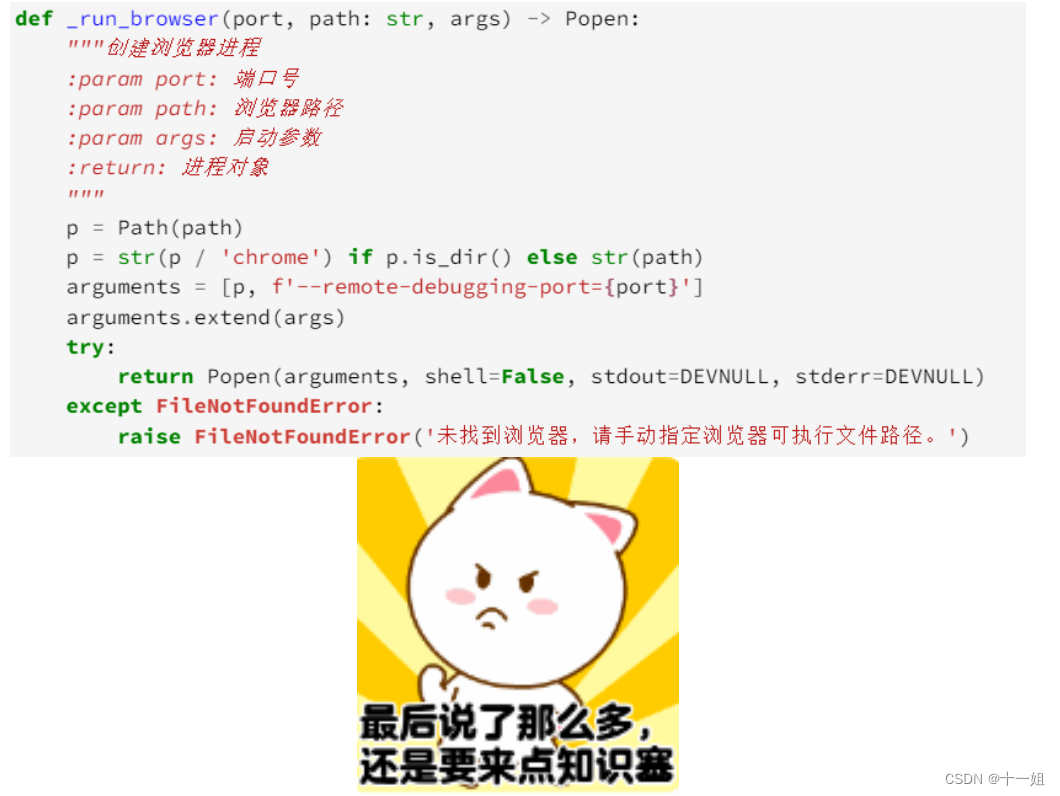
然后据挖哥科普DrissionPage底层源码,如图通过命令chrome.exe --remote-debugging-port=9222 远程调试托管浏览器的源码,这意味着使用dp可以打开我们日常使用的浏览器,继承它已存在的登陆cookie信息/插件信息等
三、正经的讲点DrissionPage知识
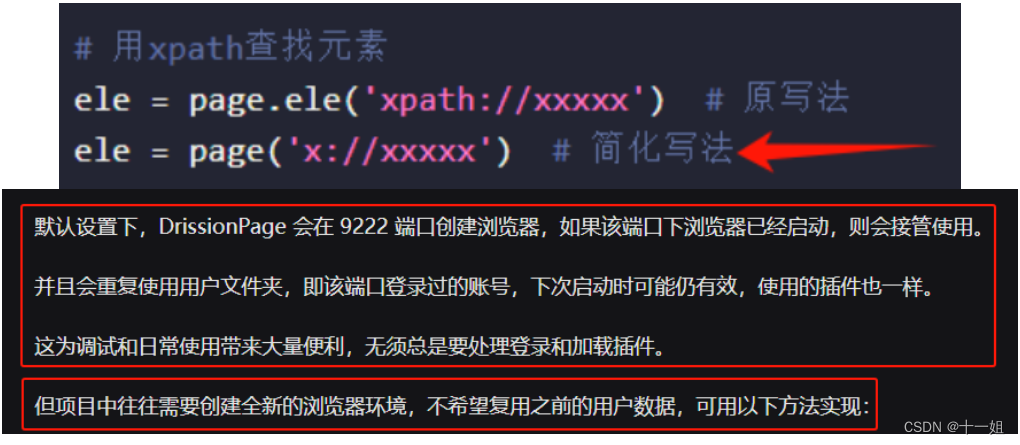
初次如何使用DrissionPage(大家简称dp),先通过pip install DrissionPage --upgrade安装,然后再复制执行如下代码,这里我使用的是xpath语法定位元素
1、如下代码,可以操控浏览器打开一个网页,获取html源码/文本/属性值
from DrissionPage import ChromiumOptions, ChromiumPageco = ChromiumOptions().use_system_user_path()
print("page1要控制的浏览器地址", co.address)
print("page1浏览器默认可执行文件的路径", co.browser_path)
print("page1用户数据文件夹路径", co.user_data_path)
print("page1用户配置文件夹名称", co.user, "\n")
page = ChromiumPage(co)page.get('http://g1879.gitee.io/DrissionPageDocs', retry=3, interval=2, timeout=15)
print(f">>>>>>>>>>>>>>>>>>>>>>>>\n当前对象控制的页面地址和端口: {page.address}\n浏览器进程id: {page.process_id}\n标签页id: {page.tab_id}")
print(">>>>>>>>>>>>>>>>>>>>>>>>\n当前概述html", page.ele('x://*[@id="️-概述"]').html)
print(">>>>>>>>>>>>>>>>>>>>>>>>\n当前版本信息text", page.ele('x://p[contains(text(),"最新版本")]').text)
print(">>>>>>>>>>>>>>>>>>>>>>>>\ngit链接属性值", page.ele('x://p[contains(text(),"项目地址")]/a').attr('href'))# page.quit() 退出浏览器
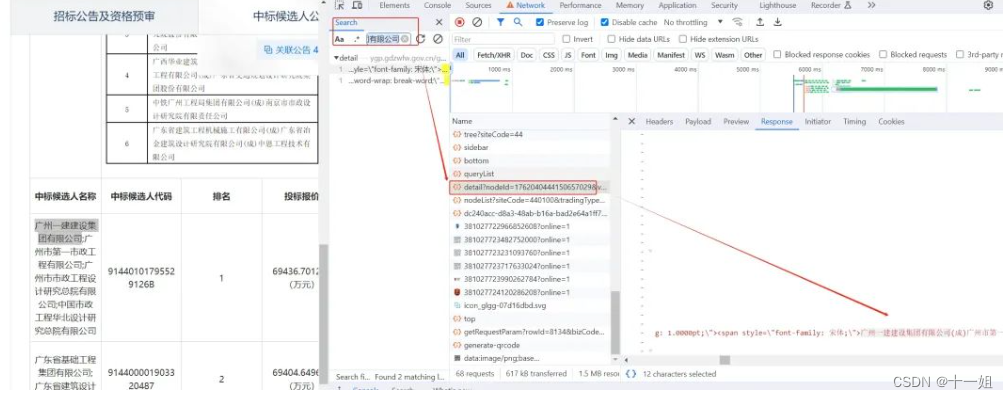
2、如下代码,可以像network/fiddler那样实现数据抓包,获得请求头/响应头/响应文本等
from DrissionPage import ChromiumPage, ChromiumOptionsco = ChromiumOptions().set_paths(browser_path=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe")
page = ChromiumPage(co)
# 开始监听,指定获取包含该文本的数据包
page.listen.start('detail?nodeId=') # 默认不启动正则匹配,这里代表url包含该字符串,启动正则匹配需要配置 is_regex=True
page.get('https://ygp.gdzwfw.gov.cn/#/44/new/jygg/v3/A?noticeId=dc240acc-d8a3-48ab-b16a-bad2e64a1ff7&projectCode=E4401000002400710001&bizCode=3C51&siteCode=440100&publishDate=20240302000028&source=%E5%B9%BF%E4%BA%A4%E6%98%93%E6%95%B0%E5%AD%97%E4%BA%A4%E6%98%93%E5%B9%B3%E5%8F%B0&titleDetails=%E5%B7%A5%E7%A8%8B%E5%BB%BA%E8%AE%BE&classify=A02&nodeId=1762040444150657029') # 访问网址
data_packet = page.listen.wait()
print(">>>>本标签页id与框架id ", data_packet.tab_id, data_packet.frameId)
print(">>>>数据包请求网址 ", data_packet.method, data_packet.url)
print(">>>>响应文本 ", data_packet.response.body, data_packet.response.raw_body)
print(">>>>响应头 ", data_packet.response.headers)
print(">>>>请求头信息 ", data_packet.request.headers)
for key, value in data_packet.request.headers.items():print(f"\t【name】 {key} 【value】 {value}")
print(">>>>请求头表单信息 ", data_packet.request.postData)
print(">>>>连接失败信息 ", data_packet.fail_info.errorText)
3、如下代码,可以启动两个互不相干的全新的浏览器,auto_port会生成随机的端口和临时用户文件夹
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
co.auto_port(True)
page1 = ChromiumPage(co)
print("page1要控制的浏览器地址", co.address)
print("page1浏览器默认可执行文件的路径", co.browser_path)
print("page1用户数据文件夹路径", co.user_data_path)
print("page1用户配置文件夹名称", co.user, "\n")
page2 = ChromiumPage(co)
print("page2要控制的浏览器地址", co.address)
print("page2浏览器默认可执行文件的路径", co.browser_path)
print("page2用户数据文件夹路径", co.user_data_path)
print("page2用户配置文件夹名称", co.user)
# 每个页面对象控制一个浏览器
page1.get('https://www.baidu.com')
page2.get('http://www.163.com')
4、当然,你也可以指定固定的端口和用户目录,来创建两个全新的浏览器
from DrissionPage import ChromiumPage, ChromiumOptions# 创建多个配置对象,每个指定不同的端口号和用户文件夹路径
do1 = ChromiumOptions().set_paths(local_port=9111, user_data_path=r'D:\data1')
do2 = ChromiumOptions().set_paths(local_port=9223, user_data_path=r'D:\data2')# 创建多个页面对象
page1 = ChromiumPage(addr_or_opts=do1)
print("page1要控制的浏览器地址", do1.address)
print("page1浏览器默认可执行文件的路径", do1.browser_path)
print("page1用户数据文件夹路径", do1.user_data_path)
print("page1用户配置文件夹名称", do1.user, "\n")
page2 = ChromiumPage(addr_or_opts=do2)
print("page2要控制的浏览器地址", do2.address)
print("page2浏览器默认可执行文件的路径", do2.browser_path)
print("page2用户数据文件夹路径", do2.user_data_path)
print("page2用户配置文件夹名称", do2.user)
# 每个页面对象控制一个浏览器
page1.get('https://www.baidu.com')
page2.get('http://www.163.com')
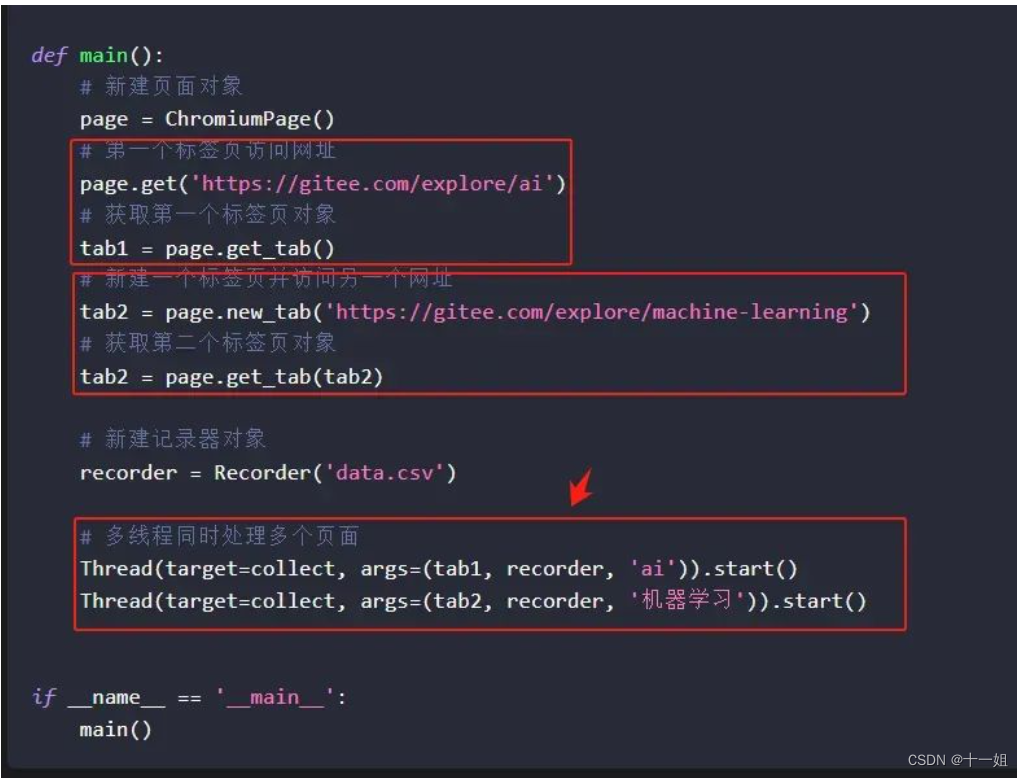
5、如果你要多线程并发的开不同的标签页/浏览器等,page.get_tab()是获取当前标签页对象, 而page.new_tab()是打开另一个标签页,直接看作者提供的官方源码案例 , https://g1879.gitee.io/drissionpagedocs/demos/actual/multithread
6、在作者的官方文档里面提供了更多的实战案例,大家可以多多试试,比如可以携带插件自动切换代理,可以执行js脚本,可以截图,录像等 , https://g1879.gitee.io/drissionpagedocs/demos/functions/new_browser
四、故事的收尾
- 文章的末尾