存储与弹性伸缩
- 一、介绍
- 二、存储架构图
- 1.CommitLog
- 2.ConsumeQueue
- 3.IndexFile
- 三、消息读写流程
- 1.写入流程
- 1.1 获取Topic元数据
- 1.2 消息投递
- 1.3 消息写入
- 2.读取流程
- 2.1 获取Topic元数据
- 2.2 消息拉取
- 2.3 消息消费
- 四、消息持久化
- 1.页缓存
- 2.刷盘
- 2.1 同步刷盘
- 2.2 异步刷盘
- 五、集群模式
- 1.单Master模式
- 2.多Master模式
- 3.多Master多Slave模式-异步复制
- 4.多Master多Slave模式-同步双写
- 六、弹性伸缩
- 1.NameServer
- 2.Broker
- 2.1 ConsumerQueue伸缩
- 2.2 Broker伸缩
- 3.Producer
- 4.Consumer
- 总结
- 参考链接
一、介绍
主要是对RocketMQ的存储与弹性伸缩做一个学习和总结、加深印象。内容参考RocketMQ官方文档。
二、存储架构图
RocketMQ采用的是混合型存储结构,单个Broker实例将负责的所有队列用同一个日志数据文件(CommiLog)存储。

1.CommitLog
保存消息主体以及元数据,存储Producer端写入的消息主体内容。Broker负责的多个Topic的消息实体内容都存储于一个commitLog中。消息顺序写入commitLog文件,当文件满了,写入到下一个文件。
2.ConsumeQueue
消息消费队列类似kafka中的Topic下的分区,主要是为了提高消息消费的性能。针对主题消费不需要遍历commitLog文件并检索出对应topic消息。ConsumeQueue并不会保存消息主体内容,保存的主要是消息在CommitLog中的物理偏移量offset、消息的大小size、消息Tag的HashCode值。
3.IndexFile
提供一种可以通过key或者时间区间来查询消息的方法。
三、消息读写流程
1.写入流程
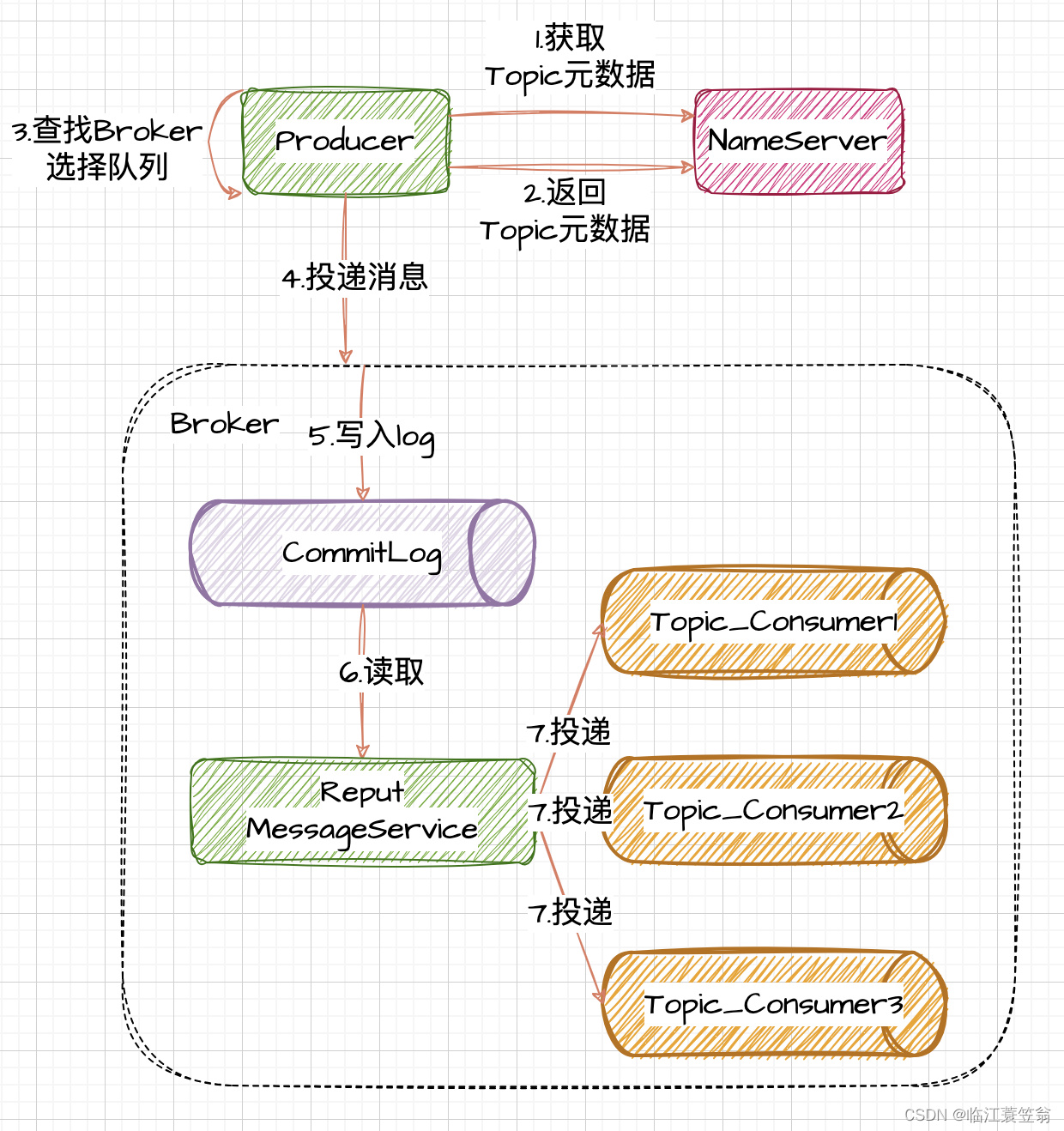
1.1 获取Topic元数据
- 1.Producer与NameServer建立连接,发起获取Topic元数据请求
- 2.Producer获取topic元数据信息
1.2 消息投递
- 3.Producer根据元数据信息选择Broker和需要投递的队列
- 4.Producer发起远程请求投递消息到Broker
1.3 消息写入
- 5.Broker将消息写入到CommitLog文件
- 6.ReputMessageService异步读取CommitLog信息
- 7.ReputMessageService根据消息的topic和队列信息,将消息的offset、size、消息Tag的HashCode值写入到对应队列
2.读取流程
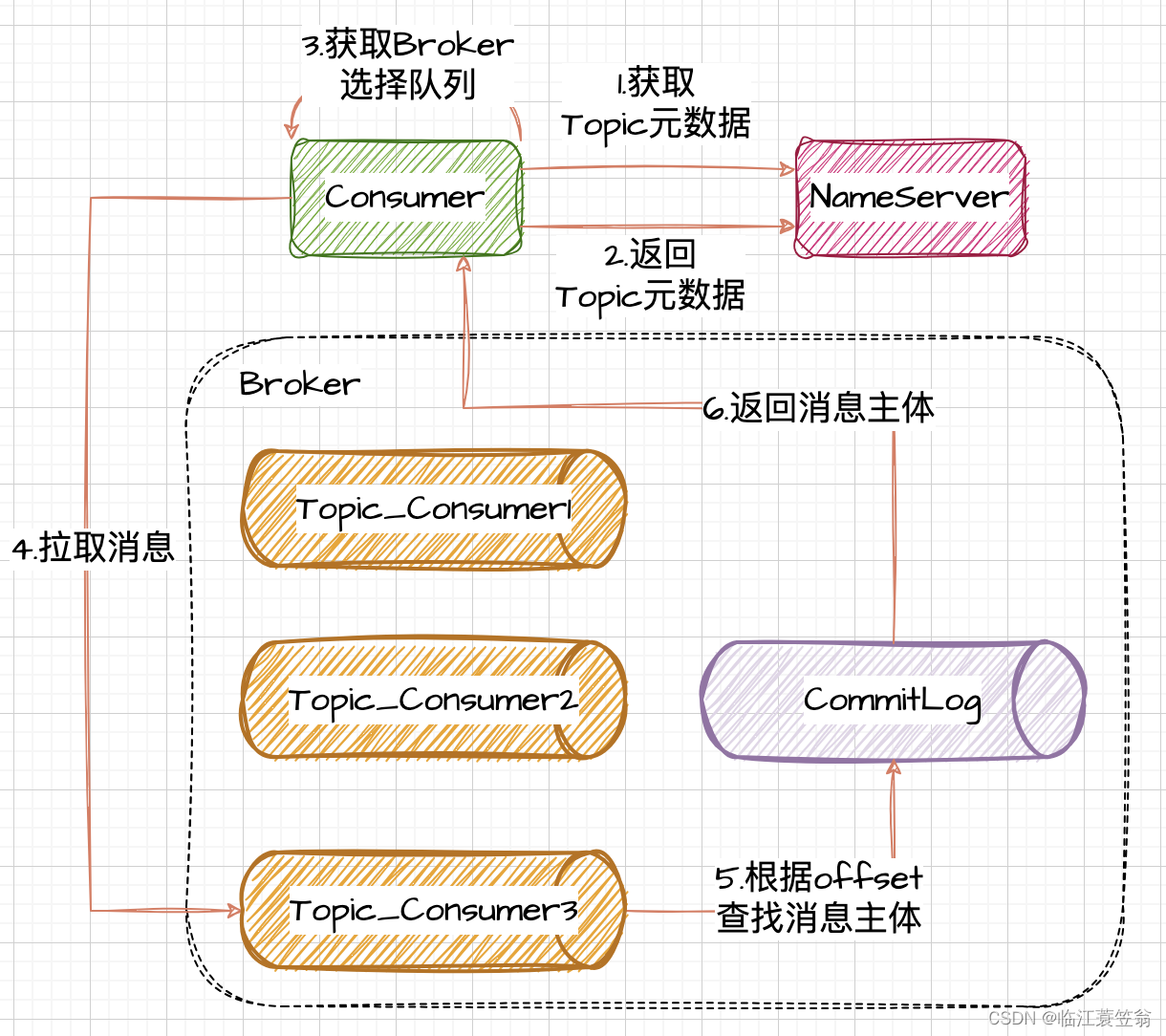
2.1 获取Topic元数据
- 1.Consumer与NameServer建立连接,发起获取Topic元数据请求
- 2.Consumer获取topic元数据信息
2.2 消息拉取
- 3.Consumer根据元数据信息选择Broker和需要消费的队列
- 4.Consumer发起远程消费请求到Broker
2.3 消息消费
- 5.Broker根据上次Offset从消费队列查找消息检索信息
- 6.Broker从CommitLog查询到消息主体,然后返回消息主体信息给Consumer
四、消息持久化
对于单个Broker的消息持久化,主要是需要知道OS对文件的缓存和刷盘机制。如果只选择单个机器模式,一旦Broker重启或宕机会导致服务不可用,Broker磁盘损坏也会导致消息丢失,所以需要选择适合的机器模式来解决单点故障。
1.页缓存
操作系统为了加速对文件的读写,采用了页缓存机制(PageCache)。对于数据的写入,OS会先将内容写入到Cache内,随后才会将Cache内的数据刷盘至物理磁盘上。对于数据的读取,如果一次读取文件时未命中PageCache,OS会从物理磁盘上读取文件并加载到PageCache。
RocketMQ采用混合存储,ConsumerQueue逻辑消费队列存储内容比较少,而CommitLog存储所有Topic信息主体,也就是文件数量不会随着Topic线性增长,可以充分利用页缓存机制来加快消息的消费和写入。
2.刷盘
消息发送到Broker后,是先写入到OS内存,然后将内存中数据刷盘到物理磁盘,才能保证消息不丢失。
2.1 同步刷盘
同步刷盘是指只有Broker将消息持久化到磁盘后,Broker端才会返回给Producer端一个ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障。
2.2 异步刷盘
异步刷盘是指只要Broker将消息写入到PageCache,Broker端就会返回Producer端一个ACK响应。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。
五、集群模式
1.单Master模式
单个Master一旦Broker重启或者宕机时,会导致服务不可用,不建议生产环境使用。
2.多Master模式
一个集群全是Master,配置简单,单个Maste宕机或重启对应用无影响。但是宕机机器在恢复之前,消息无法消费。
3.多Master多Slave模式-异步复制
每个Master配置一个Slave,有多对Master-Slave,采用异步复制方式,主备有短暂消息延迟(毫秒级)
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,同时Master宕机后,消费者仍然可以从Slave消费,而且此过程对应用透明,不需要人工干预,性能同多Master模式几乎一样;
- 缺点:Master宕机,磁盘损坏情况下会丢失少量消息。
4.多Master多Slave模式-同步双写
每个Master配置一个Slave,有多对Master-Slave,采用同步双写方式,即只有主备都写成功,才向应用返回成功。
- 优点:数据与服务都无单点故障,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高;
- 缺点:性能比异步复制模式略低,发送单个消息的RT会略高
六、弹性伸缩
1.NameServer
通过HTTP服务来设置NameServer地址,可以支持动态增加NameServer。
2.Broker
2.1 ConsumerQueue伸缩
如果消息积压并且Consumer实例数量已经提升到与消息队列一致的情况下,可以通过同步增加ConsumerQueue与Consumer实例数量来减少消息的积压。增加ConsumerQueue后会触发所有Consumer实例的负载均衡。
2.2 Broker伸缩
如果Broker有性能瓶颈,可以通过新增Broker。在新的Broker进行新Topic创建或者已有Topic消费队列的创建来分担原有Broker的压力。
3.Producer
Producer发送消息的时候,默认会轮询消费队列进行消息发送。新增的Producer会从NameServer获取Topic的元数据从而选择对应的消费队列进行消息发送,删除的Producer不会有任何影响。
4.Consumer
在集群消费模式下,如果消费能力不足,可以通过增加消费组下的Consumer实例来增加消费能力。但是此模式下,每个消费队列只能由消费组下的一个Consumer实例来进行消费,也就是如果消费实例数量大于消费队列数量的消费实例不会进行消费,属于浪费资源。
消费组下的Consumer实例增加或者减少都会触发所有实例的负载均衡,将消费队列分配到对应的Consumer实例。
总结
RocketMQ采用的是混合存储,将Broker上的所有Topic信息主体保存到同一个文件中。特别适合内部消息队列的场景,即Topic数量多、但是每个Topic的消息量较少的场景。采用多种集群部署模式,可以适用多种可靠性场景。具有很强的弹性伸缩能力来满足业务波动的场景。
参考链接
1.RocketMQ存储架构
2.GitHub RocketMQ中文文档
3.Apache RocketMQ开发者指南
4.Apache RocketMQ 集群部署