大家好,我又来写博客了,今天给大家介绍一下MySQL,如果你只想让MySQL作为自己的辅助开发工具,那这一篇文章就够了,如果想作为一门语言来学习,那你可以看此文章了解一些基础。
MySQL介绍
数据库可分为关系型数据库和非关系型数据库,而MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前隶属于 Oracle 公司。它是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,从而增加了速度并提高了灵活性。
MySQL具有开源、高性能、可扩展、多平台支持等特点。
MySQL安装
MySQL的安装是比较简单的,安装时可以择自定义(custom)的方式来装,自带的数据库可视化工具(Workbench)不推荐使用,可以去搜一下Navicat,到处都是破解版。
下面提供一个教你安装MySQL的链接,我就不详述了:点此跳转
终端操作数据库
登录
你在安装MySQL时有一个步骤是让你创建自己的账户的,拿着这个账户就可以去操作数据库啦!
1.win+r键入cm,enter。
2.输入以下代码:
mysql -u root -pu就代表user,就是账户,而p就是password。
当你输入以上指令后,回车,然后会让你输入密码:
输入密码后回车们就是以上界面,会显示数据库的版本,我的是5.7。
还有一种方式是直接输入密码,但密码不会隐藏:

想要推出的话输入exit或quit都可。
其他操作
show tables; ->查看数据库中的所有表
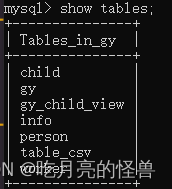
describe user; ->查看表结构 ,describe可缩写为desc

show databases; ->查看所有数据库

还有其他操作,可以自己去搜集。
系统表介绍
有些表不是自己创建的,而是系统的数据库,千万不要随意操作!
就三个数据库需要注意: information_schema、performance_schema、sys。
其实还有一个数据库叫mysql,那是mysql的。里面的表有很多。
里面有一个表叫做user,点进去:

里面是你mysql注册的用户,你创建的用户也可以在这里被删除。
MySQL的操作
MySQL的操作语言可分为四类,DDL、DML、DQL、DCL。
DDL (Data Definition Language,数据定义语言)
- 主要用于维护存储数据的结构,包括数据库、表、视图、索引、同义词、聚簇等。
- 代表指令:
CREATE:创建数据库和数据库对象。DROP:删除数据库、表、索引、条件约束以及数据表的权限等。ALTER:修改数据库表的定义及数据属性。
MySQL的每句代码后都要加分号:“ ; ”。
MySQL不区分大小写。
create
create 可以用来创建数据库,也可以用来创建表,创建用户:
# 创建名为csdn的数据库
create database csdn;如果你插入的数据有中文,那就要设置charset(字符集),否则会报错。
创建表之前需要选择数据库:
# 选择数据库名为csdn的数据库
use csdn;创建名字为user的表:
create table user(id int not null auto_increment primary key, name varchar(20), age int);创建表的时候同时需要输入字段名,也就是列名,代码中创建了三个字段id、name、age。
注意:
- 一个表必须又一个主键,primary key。
- 字段名后面必须跟的是类型。(int、varchar等)。
- 类型后面跟的是约束。(not null、auto_increment等)。
创建一个用户:
# 创建一个名为jack的用户,密码是123456
create user 'jack'@'localhost' identified by '123456';其中,jack是你想要创建的用户名,localhost表示该用户可以从本地主机连接到数据库。如果需要允许从任何主机连接,可以将localhost替换为%。123456是用户的密码。
drop
drop主要删除用户、数据库、表、列。
# 下面使用 DROP USER 语句删除用户 'test1'@'localhost'
DROP USER 'test1'@'localhost';# 删除csdn数据库,如果存在
drop datebase if exists csdn;# 删除表user
drop table user;
alter
alter主要用于修改表:
alter table 表名 drop 列名; # 删除某表某列
alter table 表名 drop foreign key 外键名; # 删除某表外键
alter table 表名 add 字段名 类型 约束; # 添加一个字段
alter table 表名 add primary key(列名); # 添加主键
alter table 表名 add constriant 外键名 foreign key(外键列名) references 关联表名(关联列名) on update cascade on delete restrict; # 添加外键
alter table 表名 change 原列名 新列名 数据类型 约束; # 修改某表某列
alter database 数据库名 charset = utf8; # 修改数据的字符集类型
MySQL中的常用数据类型
- int 代表整数
- float 代表浮点数
- varchar 代表可变字符串
- datetime 代表日期
- enum 枚举类型
介绍一下datetime和enum类型的使用
# create_time列,sex列
create table demo(id int primary key, create_time datetime default current_timestamp on update current_timestamp, sex enum('男',' 女') default '男');default 就代表默认值,current_timestamp代表当前的时间戳,on update代表更新时会修改时间。 enum后面括号里是可选项,默认值只能是括号里的其中一个。
MySQL中的约束
约束只需要写在类型的后面就可。
| not null | 代表不能为空,也就是插入数据的时侯你不能不插入值。 |
| auto_increment | 代表自增长,默认非空,一般用于约束id。 |
| unique | 唯一约束,代表这一列的值不能重复。附带唯一索引。 |
主键:
primary key,这是每一个表必须有的的约束,且不能重复。
在 MySQL 中,主键是用于标识表中每一行数据的唯一标识符。因此,主键必须具有唯一性,不能有重复的值。让我们来详细了解一下主键的作用和规则:
-
唯一性:主键必须包含唯一的值。这意味着在表中,每一行的主键值都不会重复。
-
非空性:主键列不能包含 NULL 值。因此,在定义主键时,您必须使用
NOT NULL属性来声明主键列。 -
单一性:一张表只能有一个主键。主键可以由单个列(字段)或多个列组成。
-
性能优化:设置主键有助于提高查询性能。当您使用主键进行查询时,数据库引擎会自动创建一个索引,从而加速数据检索。如果没有主键,查询可能会进行全表扫描,影响性能。
外键:
外键主要是用于表与表之间的关联。
外键的作用和特点:
-
定义:外键是一种关系,用于连接两个表之间的数据。它建立了一个从一个表到另一个表的引用。
-
关联性:外键用于建立表之间的关联。通常,外键引用另一个表的主键。例如,如果我们有一个订单表和一个客户表,订单表中的客户ID可以作为外键引用客户表的主键。
-
数据完整性:外键有助于维护数据的完整性。通过外键,我们可以确保在关联表之间的数据一致性。例如,如果我们删除了客户表中的某个客户,那么具有相同客户ID的订单也应该被删除,以保持数据的一致性。
-
约束规则:外键可以定义一些约束规则,例如:
- CASCADE:如果主表中的记录被删除或更新,相关的外键记录也会被删除或更新。
- SET NULL:如果主表中的记录被删除或更新,相关的外键记录的值将被设置为 NULL。
- RESTRICT:阻止对主表的删除或更新操作,如果存在相关的外键记录。
-
性能优化:外键还有助于性能优化。通过外键,数据库引擎可以更快地定位到关联表中的数据。
外键的创建比较复杂,下面是代码示例。create table test(id int primary key, demo_id int, constraint test_fk foreign key(demo_id) references demo(id) on update cascade on delete cascade); -
constraint后面跟的是你创建的外键的名字,如果没有则系统自动创建外键名。
-
references 后面跟的是关联表的名和列,demo(id),代表demo表的id列。
-
on update cascade 代表关联更新。有兴趣自己查。
DML (Data Manipulation Language,数据操纵语言)
- 主要用于对数据库对象中包含的数据进行操作。
- 代表指令:
INSERT:向数据库中插入一条数据。DELETE:删除表中的一条或多条记录。UPDATE:修改表中的数据。
insert
insert用于插入数据,插入数据有三种方式。
1.一次插入多行
insert into user values(1,'张无忌', 34),(2,'金毛狮王',67);这句是插入了两行数据,如果要插入多行,往后加括号就行。但要注意,插入数据个数要和字段名对应,不能少。
2.缺省插入
有两种方式:
# 一次只能插入一行
insert into user (name,age) values('范德华', 22);上面这种插入方式只需要写不能为空的相关的数据,像id这种设置了自增长的字段,会自动填充。不为主键的字段若不插入数据会为null,有默认值的填充默认值。
# 一次只能插入一行
insert into user set name = '罗华', age = '21';上面这种跟第一种效果相同,注意事项相同,只是写法不同。
delete
delete主要用于操作表,但也可以用来删除数据库用户(自己搜索喽)。一般可以来删除表中的行。
# 删除age字段值小于18的行
delete from user where age < 18;注意:如果后面不跟where限制条件的话,会把表中的数据都删除,我没试过,你试试😜。
update
update主要用于改数据,例如:
update user set name = '嘉文四世' where id = 101;这句是把id是101的行的name改为“嘉文四世”。
DQL (Data Query Language,数据查询语言)
- 主要用于查询数据库中的数据。
- 代表指令:
SELECT:查询表中的数据。FROM:指定查询哪张表或视图。WHERE:设置约束条件。
select和from
直接上代码:
# * 代表所有字段
select * from gy where name = 'gy';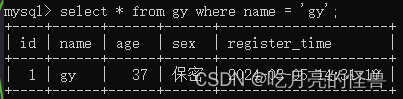
上面的操作就是查询name为gy的行的所有数据。
# 仅查询id和name
select id as '学号',name as '名字' from gy where age > 24; 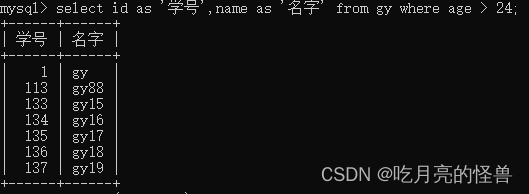
上面的SQL代码是仅查询了gy表中的id和name,并通过 as 起了别名(as不在单独介绍),条件是age大于24的。
where
前面已经用过很多次where,其主要作用就是设置查询时的约束条件。不再多写。
and、or 、in、not in、between and、is null、is not null
上面这些都可以添加到where中,很简单,如果不懂可以查下。
模糊查询:
模糊查询的方式有很多,通配符查询、内置函数检索、则这匹配查询。下面介绍一下通配符查询:
%百分号通配符:表示任何字符出现任意次数(可以是 0 次)。- 例如,
SELECT * FROM app_info WHERE appName LIKE '%网%'可以模糊匹配包含“网”字的数据。
- 例如,
_下划线通配符:表示只能匹配单个字符,不能多也不能少,就是一个字符。- 例如,
SELECT * FROM app_info WHERE appName LIKE '__网'可以查询以“网”为结尾的长度为三个字的数据。
- 例如,
想多了解可以点击链接![]() https://blog.csdn.net/qq_39390545/article/details/106414765
https://blog.csdn.net/qq_39390545/article/details/106414765
DCL (Data Control Language,数据控制语言)
- 主要用于控制数据库对象的权限管理、事务和实时监视。
- 代表指令:
GRANT:分配权限给用户。REVOKE:废除数据库中某用户的权限。ROLLBACK:退回到某一点(回滚)。COMMIT:提交。
grant
grant可以给部分权限,也可以给全部权限,权限有很多,数据库名为mysql中的user表的列名就是权限。
 Y代表有这个全限,N就是没有。
Y代表有这个全限,N就是没有。
# 分配操作所有数据库的所有表的权限给jack
grant all on *.* to 'jack'@'loaclhost';在MySQL中,*.*表示对所有数据库和所有表的所有权限进行授权。具体来说:
*表示所有数据库或所有表。.是分隔符,用于区分数据库名和表名。
# 分配查询和插入权限于csdn数据库给jack
# 可以操作所有表
grant select,insert on csdn.* to 'jack'@'localhost';revoke、rollback、commit
这几个用的不多,想了解可以问一下ai,其中roolback和commit一般都是用在事务中,用于回滚和提交,事务在下面介绍。
事务
在MySQL中事务是一组sql语句组成的单元,这些语句要么全部执行成功提交(commit),要么有语句执行失败回滚(roolback)。
MySQL有很多存储引擎(下边介绍),但并不是所有的存储引擎都支持事务。 一般默认的引擎就是InnoDB,它是支持事物的。
事务处理
开启事务:start transaction; 默认不会提交。
结束事务:commit; 或 roolback;
事务特性
事务的特性:ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
简单描述:
- 原子性:事务不可再分,一个小操作单元。
- 一致性:事务执行后数据库的状态不变。不因事务出现的错误破环数据的完整性。
- 隔离性:事务之间互补影响。
- 持久性:事务一旦提交,所作的修改永远保存在数据库中。
设置变量:
在事务的这组sql语句中,可以创建变量,供后面的代码使用。
select @n_id:= id from 表名 ; # 创建了n_id变量
存储引擎
常用引擎
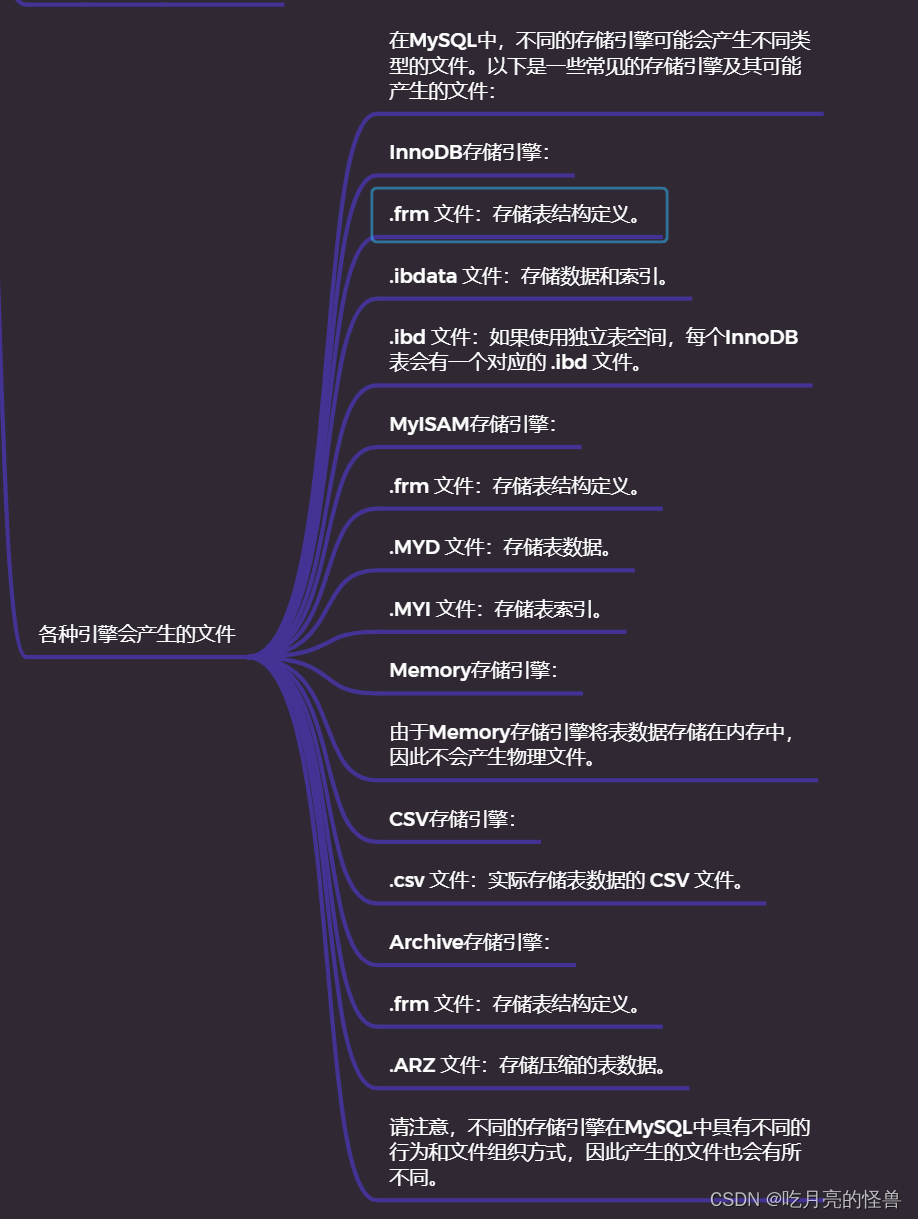
InnoDB
默认存储引擎,支持事务,支持外键,综合能力强,适用于大多数场景,使用后最为ibd的文件存储数据。
MyISAM
查询、排序速度非常快,不支持外键,不支持事务。
Memory
读写内存速度最快,但不能持久化,不可存储于本地,一旦断开连接,数据清除。
CSV
存储文件按格式为csv可直接在excel中查看,适合导入导出操作。
修改引擎
alter table user engine=MyISAM;上面的代码代表修改user的存储引擎为MyISAM。所以存储引擎是针对于表的,不同的表可以有不同的存储引擎。
指定引擎
创建表时,存储引擎默认为InnoDDB,但如果按下面的代码可以 指定存储引擎:
create table worker(id int primary key, name varchar(20)) engine = Memory;也就是直接在后面加上 engine = 引擎名。
最后,每种引擎的存储文件是不同的,有兴趣的话可以搜索一下:
函数和存储过程
这里对于仅有开发需求的人来说,无需深究,想了解自己查询吧。

索引
索引是一种查询优化技术,可以提升查询效率,实现的本质就是预先存储一些额外数据,牺牲存储空间,提升查询效率。
索引类型
- 主键索引:表创建时自动创建,用在主键上。
- 唯一索引:存在于设置了唯一约束(unique)字段。
- 普通索引:手动创建的,可以存在于任何字段。
何时创建索引
创建索引
CREATE INDEX index_name ON table_name(column_name);
其中,index_name是要创建的索引的名称,table_name是要在其上创建索引的表名,column_name是要为其创建索引的列名。
何时创建
- 查询频率高,几乎不修改,适合创建索引
- 修改频率高不适合
- 索引不是创建的越多越好
索引方式
两种:
- btree 适合大数据量,范围比较
- hash 适合小数据量,精准值的等值比较
关联查询
嵌套查询
一个语句的查询结果作为另一个语句的条件
select * from user where age > (select age from user where name = '张三');如果你都看到这了,那上面的代码你应该能看懂。
连接查询
这部分不是很重要,是一种查询方式,我这台电脑出了点状况,操作不了,附赠介绍截图:

感兴趣可以去了解下,比较简单。
常用技术
系统函数调用
调用系统函数使用select
# 当前选择数据库
select database();# 当前mysql版本
select version();# 当前用户
select user();
还有其他函数:
聚合函数
就是max()、min()、avg()、sum()、count() 这些。
括号里面放的时列名,count(name)可以统计name列有多少行。
max(age) 代表最大的年龄,可以用于查询,但不能用作where后的条件。它们通常与group by(分组)子句一起使用,以对分组后的数据进行聚合计算,having 后面可以跟聚合函数。
排序
order by:
order by用于对查询结果进行排序,通常按照一个或多个列的值进行升序或降序排序。
当使用order by时,查询结果会按照指定的列的值进行排序,以便以特定的顺序呈现结果。
例如,下面的示例将查询结果按照 `salary` 列的值降序排序:
SELECT employee_name, salary
FROM employees
ORDER BY salary DESC;desc代表降序,默认时升序的(asc)。 order by 后面跟的列名的数据类型可以是任何类型,不单是int型。
分组
group by:
针对查询结果进行分组,通常与聚合函数一起使用:
select count(*) from user where age > 20 group by name;count(*)代表计算每个分组中的行数。
group by 后的列名可以有多个,逗号隔开。
having:
针对分组结果进行处理,后面跟列名条件,与group by 在一起使用。
select sex, count (*) from teacher where id > 3 group by sex having sex in ('男', '女');分页
limit :
查询数据的前五行:
select * from worker limit 5;按照某个字段排序后,跳过前5条记录,返回接下来的10条记录:
select * from user order by age desc limit 5, 10;去重
distinct:
select distinct name from user;显示user表中的所有名字,不会重复。
这是我写过的最长的一篇博客,真长,但是仍有很多不完善的地方,还请见谅🌹🌹🌹
但是看到这里的人应该不多.........