note
文章目录
- note
- Advanced rag techniques: an illustrated overview
- 基础RAG
- 高级RAG
- 分块和向量化(Chunking & Vectorisation)
- 搜索索引(Search Index)
- 1. 向量存储索引(Vector Store Index)
- 2. 多层索引(Hierarchical Indices)
- 3. 假设问题和HyDE(Hypothetical Questions and HyDE)
- 4. 上下文增强(Context Enrichment)
- (1)句子窗口检索(Sentence Window Retrieval)
- (2)自动合并检索器(Auto-merging Retriever,又称父文档检索器 Parent Document Retriever)
- 5. 融合检索或混合搜索(Fusion Retrieval or Hybrid Search)
- 重新排序和过滤(Reranking & Filtering)
- 查询转换(Query Transformations)
- 聊天引擎(chat engine)
- 查询路由(Query Routing)
- RAG中的智能体(Agents in RAG)
- 响应合成器(Response Synthesiser)
- 编码器和LLM微调(Encoder and LLM Fine-Tuning)
- 评估(Evaluation)
- 总结
- Reference
Advanced rag techniques: an illustrated overview
《Advanced RAG Techniques: an Illustrated Overview》一篇技术博客
简介:文章主要探讨了RAG技术的高级应用和算法,系统化地整理了各种方法,附带了作者知识库中引用的各种实现和研究的链接。文章的目标是概览和解释可用的RAG算法和技术,并不深入代码实现细节。
原文:https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
文章的引言部分提到两个最著名的开源库用于基于LLM的管道和应用是LangChain和LlamaIndex,分别在2022年10月和11月成立,并chatGPT大热的带动下在2023年被大量采用。本文中系统化整理的高级RAG技术,以及提供对它们的实现的参考,也主要在LlamaIndex中进行。
基础RAG
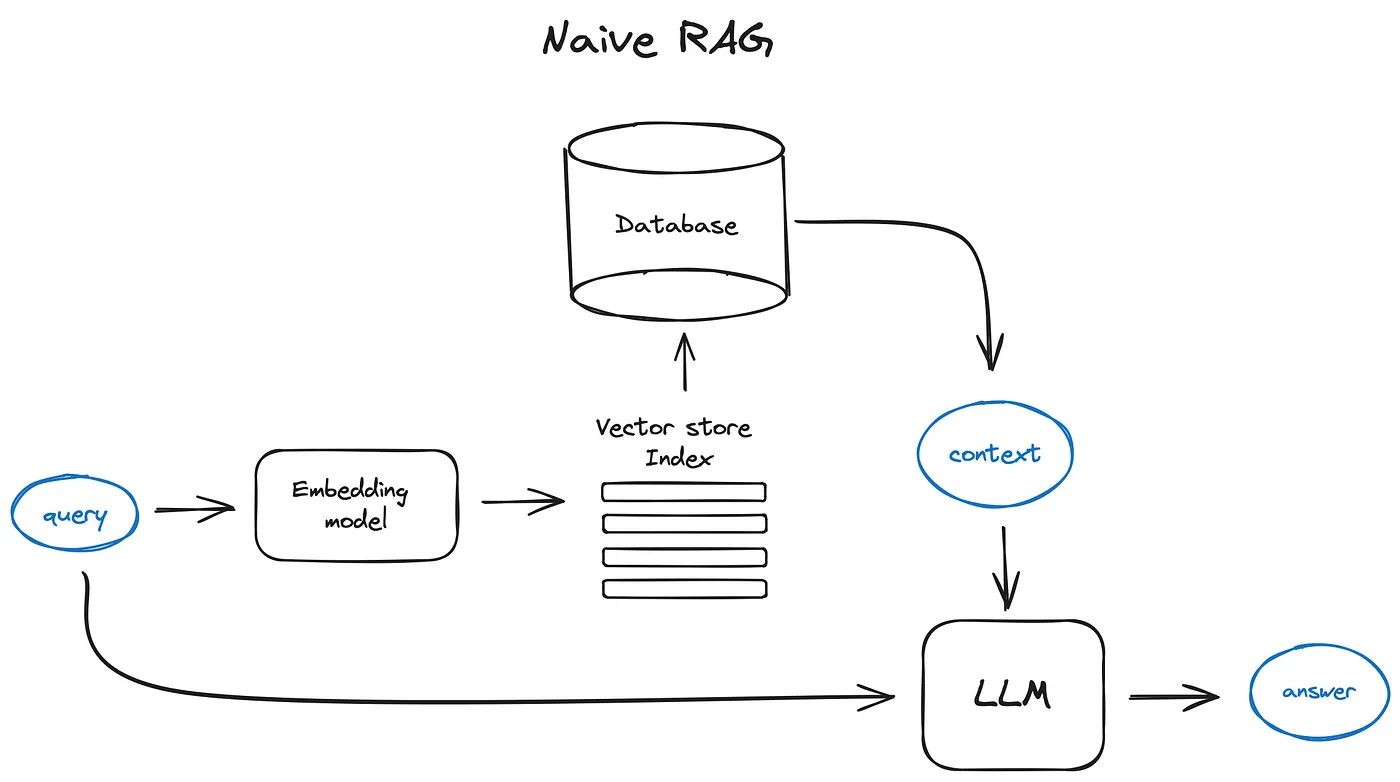
基础RAG:将文本切片并emb后,将所有emb放入索引中,对query进行emb后,根据query emb找到top-k个切片emb,最后query结合top-k个切片一起送入LLM得到结果。
注:除了openai,还可以选择Anthropic 的 Claude,Mistral 的小型但功能强大的模型Mixtral,Microsoft 的Phi-2,以及如Llama2,OpenLLaMA,Falcon等模型。
高级RAG

分块和向量化(Chunking & Vectorisation)
- 块的大小:Sentence Transformers最多处理512个token;OpenAI的ada-002能够处理更长的序列(如8191个token);在 LlamaIndex 中,NodeParser 类很好支持解决这个问题,其中包含一些高级选项,例如定义自己的文本拆分器、元数据、节点/块关系等。
- 向量化:bge-large 或 E5 嵌入系列向量模型(参考MTEB 排行榜)
搜索索引(Search Index)
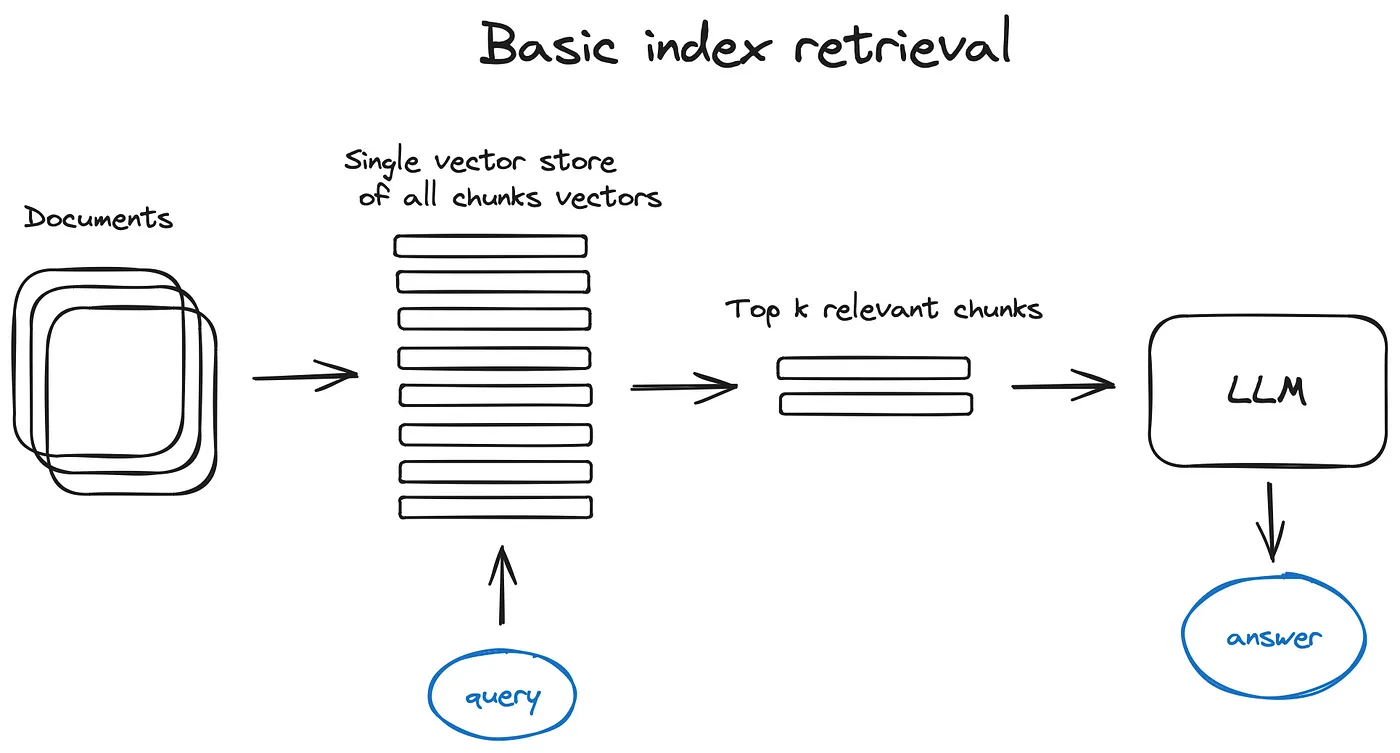
1. 向量存储索引(Vector Store Index)
(1)向量存储索引(Vector Store Index):
- 比如 faiss、nmslib 以及 annoy等是基于最近邻检索的方法,如聚类、树结构或HNSW算法
- 一些托管解决方案:如 OpenSearch、ElasticSearch 以及向量数据库,它们自动处理上面提到的数据摄取流程,例如Pinecone、Weaviate和Chroma
- LlamaIndex支持许多向量存储索引,但也支持其他更简单的索引实现,如列表索引、树索引和关键词表索引
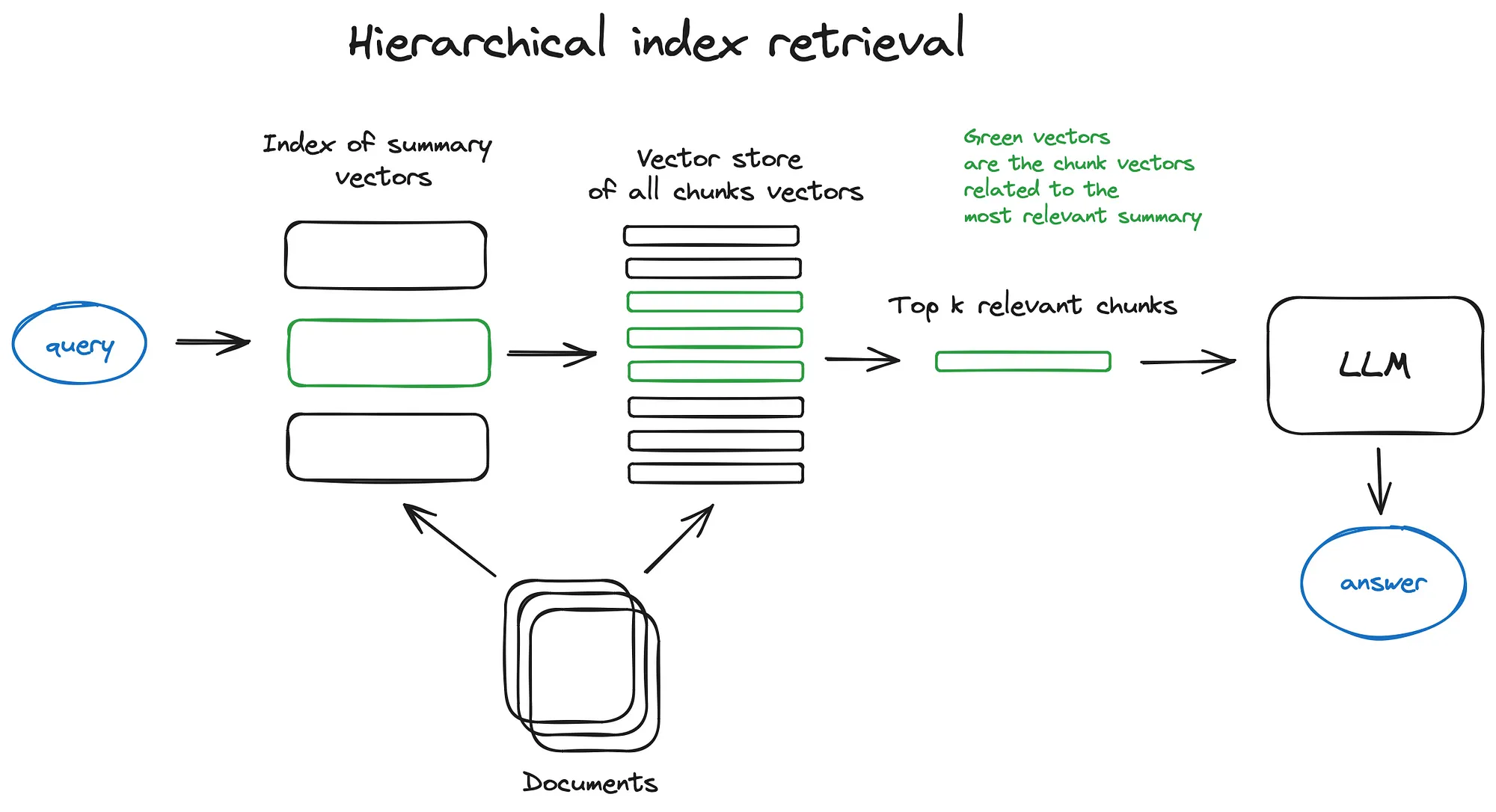
2. 多层索引(Hierarchical Indices)
(2)多层索引(Hierarchical Indices)
如果要从很多文档中检索,可以创建两个索引(一个由摘要组成,另一个由文档块组成),即两步搜索(先通过摘要筛选出满足相关的文档,然后在这些文档中继续搜索)。
3. 假设问题和HyDE(Hypothetical Questions and HyDE)
- 抽q:让LLM给每个块生成问题,将问题emb,实际中query emb和前者每个块对应的问题emb进行求相似度,检索后路由到原始文本块。
- 假设向量文档(Hypothetical Document Embeddings, HyDE)——用户可以让LLM为给定的查询生成一个假设性响应,然后使用它的向量以及查询向量来增强搜索质量。
4. 上下文增强(Context Enrichment)
- 检索较小的块以提高搜索质量:
- 一是利用在较小检索块附件的句子来扩展上下文
- 二是递归地将文档分割成包含更小子块的更大父块
(1)句子窗口检索(Sentence Window Retrieval)
思想:以句子为颗粒度进行emb,从而query emb和所有的句子emb求cos余弦距离,检索到query相关的句子后,将对应句子前后各扩展k个句子来扩展上下文窗口,将拓展后的这坨上下文给LLM。

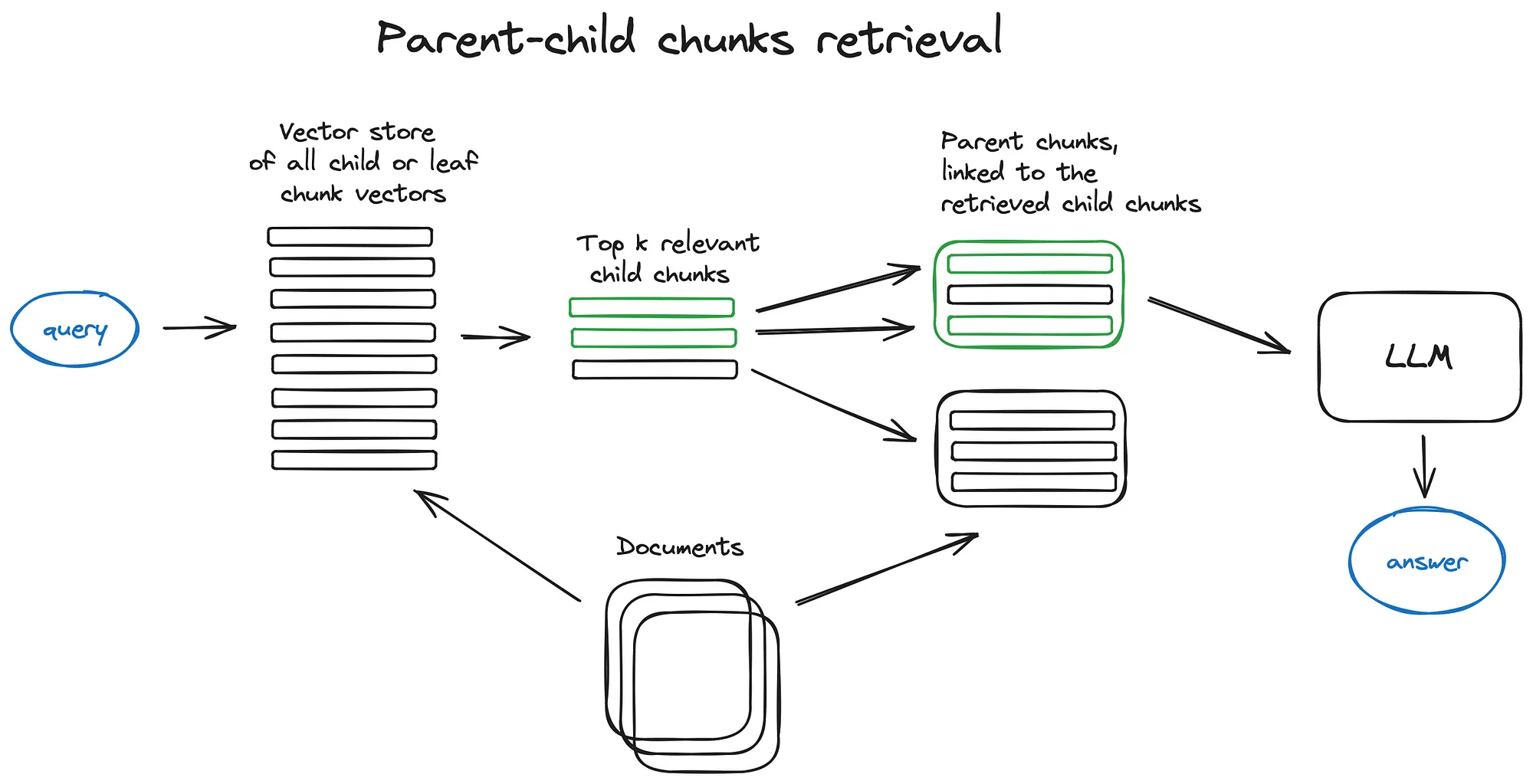
(2)自动合并检索器(Auto-merging Retriever,又称父文档检索器 Parent Document Retriever)
思想:也是搜索颗粒度更细的信息,检索上下文后,文章会被递归地分割为更大父块中更小的字块(子块和较大的父块有引用关系)。
具体:在检索中获得较小的块,如果前k个检索到的块中有超过n个块链接到同一个父节(大块),则将该父节点(大块)替换成给LLM的上下文。
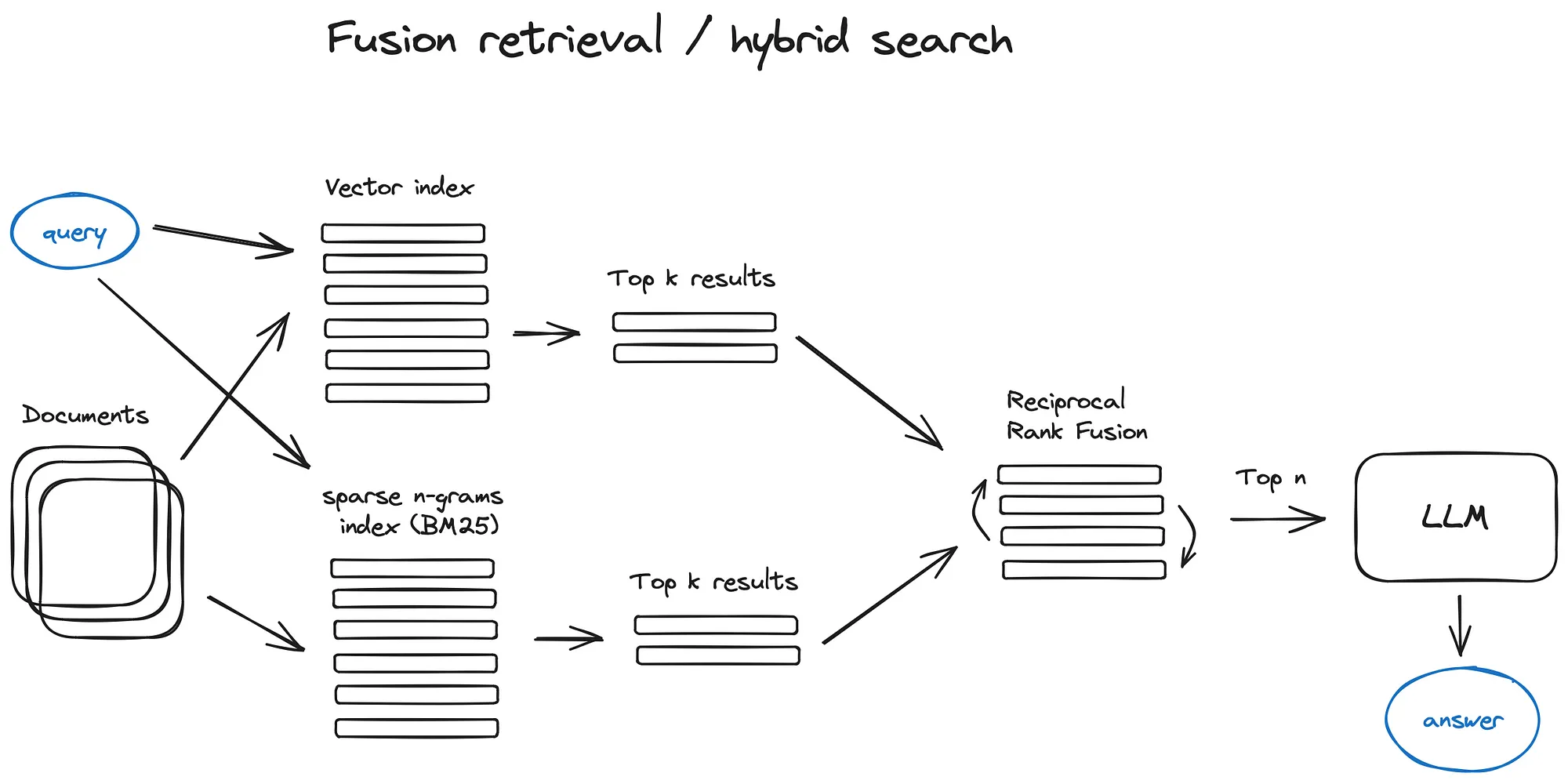
5. 融合检索或混合搜索(Fusion Retrieval or Hybrid Search)
传统思路:结合传统的基于关键字的搜索(稀疏检索算法如tf-idf或者搜索标准BM25)和现代语义或向量搜索,并将其结果组合在一个检索结果中。
关键:
- 如何组合不同相似度分数的检索结果,一般可以通过Reciprocal Rank Fusion算法解决,对检索检索进行重排序。
- 在langchain中:通过Ensemble Retriever实现,可以将我们定义的多个检索器组合,比如一个基于faiss的向量索引和一个基于BM25的检索器,并利用RRF算法进行重排操作。
- 在llamaindex中:和上面类似。
重新排序和过滤(Reranking & Filtering)
在llamaindex中,有各种可用的后处理器,根据相似性分数、关键字、元数据过滤掉结果,或使用其他模型(如 LLM)、sentence-transformer 交叉编码器,Cohere 重新排名接口或者基于元数据重排它们。
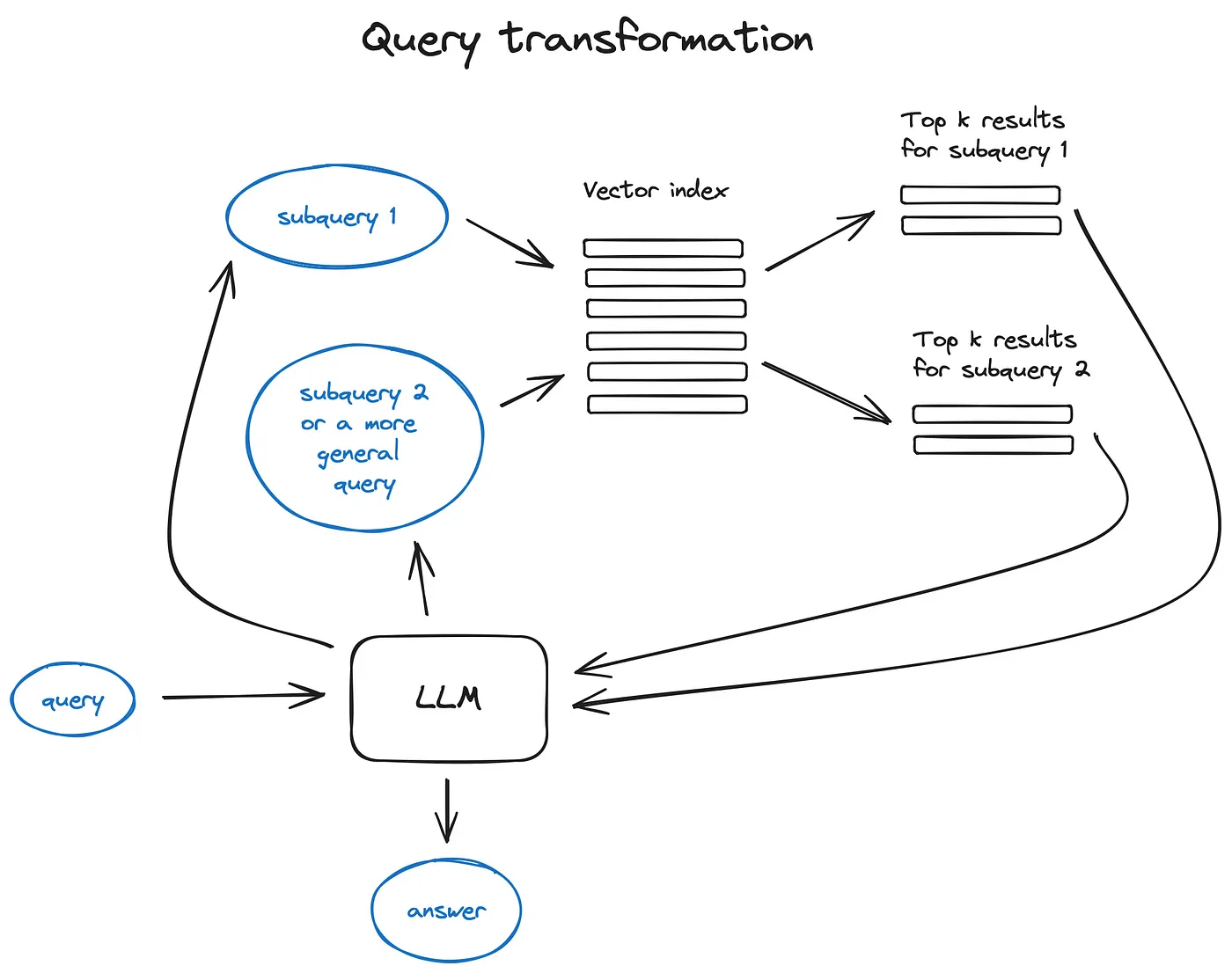
查询转换(Query Transformations)
- 比如复杂的query,可以将其拆为多个子query,比如“在 Github 上,Langchain 和 LlamaIndex 这两个框架哪个更受欢迎?”拆分为:“Langchain 在 Github 上有多少星?”和“Llamaindex 在 Github 上有多少星?”,并且两个子query并行执行,检索得到的信息被汇总到一个prompt。
- 这两个功能分别在 Langchain 中以多查询检索器的形式和在 Llamaindex 中以子问题查询引擎的形式实现。
- Step-back prompting 使用 LLM 生成一个更通用的查询,以此检索到更通用或高层次的上下文,用于为我们的原始查询提供答案。同时执行原始查询的检索,并在最终答案生成步骤中将两个上下文发送到 LLM。
- 查询重写使用 LLM 来重新表述初始查询,以改进检索。LangChain 和 LlamaIndex 都有实现。
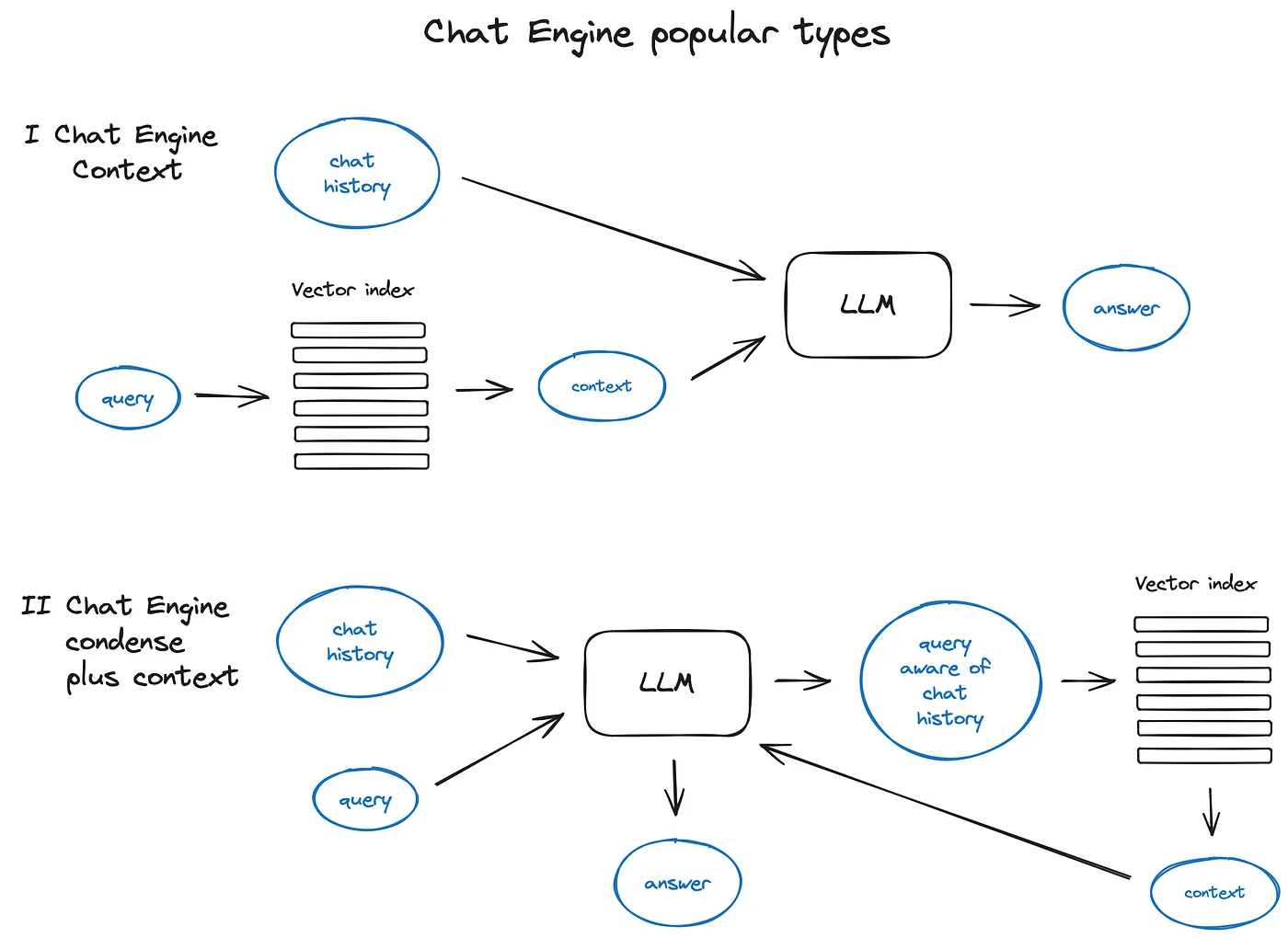
聊天引擎(chat engine)
- 核心是加入上下文,比如ContextChatEngine,首先检索与用户查询相关的上下文,然后将其与内存缓冲区中的聊天记录一起发送到 LLM,以便 LLM 在生成下一个答案时了解上一个上下文。
- 更复杂的情况是
CondensePlusContextMode——在每次交互中,聊天记录和最后一条消息被压缩到一个新的查询中,然后这个查询进入索引,检索到的上下文与原始用户消息一起传递给 LLM 以生成答案。
查询路由(Query Routing)
查询路由是 LLM 驱动的决策步骤,决定在给定用户查询的情况下下一步该做什么——选项通常是总结、对某些数据索引执行搜索或尝试许多不同的路由,然后将它们的输出综合到一个答案中。
- 查询路由还用于选择数据存储位置来处理用户查询。这些数据存储位置可能是多样的,比如传统的向量存储、图形数据库或关系型数据库,或者是不同层级的索引系统。
- 在处理多文档存储时,通常会用到摘要索引和文档块向量索引这两种不同的索引。
RAG中的智能体(Agents in RAG)
- OpenAI 助手基本上整合了开源 LLM 周边工具——聊天记录、知识存储、文档上传界面。最重要的能力还是function call。
- 在 LlamaIndex 中,有一个 OpenAIAgent 类将这种高级逻辑与 ChatEngine 和 QueryEngine 类结合在一起,提供基于知识和上下文感知的聊天,以及在一个对话轮次中调用多个 OpenAI 函数的能力,这真正实现了智能代理行为。
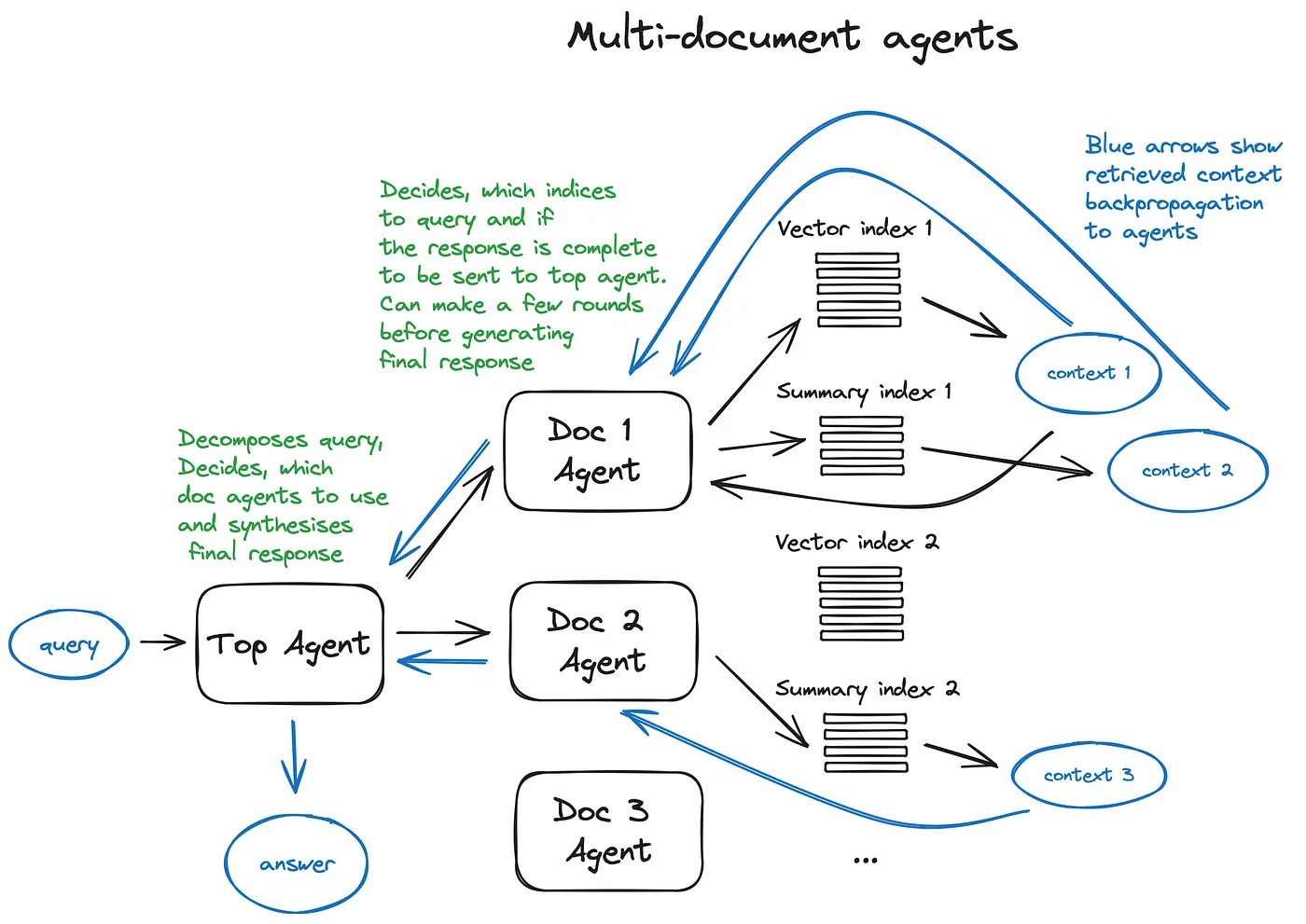
【栗子】多文档智能体
- 在每个文档上初始化一个Agent(OpenAIAgent),该智能体能进行文档摘要制作和传统问答机制的操作,还有一个顶层智能体,负责将查询分配到各个文档智能体,并综合形成最终的答案。
- 每个文档智能体都有两个工具:向量存储索引和摘要索引,它根据路由查询决定使用哪一个。对于顶级智能体来说,所有文档智能体都是其工具。
优缺点:
- 优点:方案中每个智能体都做路由许多决策。这种方法的好处是能够比较不同的解决方案或实体在不同的文档及其摘要中描述,以及经典的单个文档摘要和 QA 机制。
- 缺点:由于需要在智能体内部的大语言模型之间进行多次往返迭代,其运行速度较慢。LLM 调用通常是 RAG 管道中耗时最长的操作,而搜索则是出于设计考虑而优化了速度。
响应合成器(Response Synthesiser)
- 一般就将检索到的上下文和query拼接
- 也可以先优化(如概括等)检索到的上下文,再和query拼接
编码器和LLM微调(Encoder and LLM Fine-Tuning)
- 微调LLM
- 微调emb模型:如bge-large-en-v1.5等
- 微调rank模型:可以使用交叉编码器进行重排操作,如下操作
- 把查询和每个前 k 个检索到的文本块一起送入交叉编码器,中间用 SEP (分隔符) Token 分隔,并对它进行微调,使其对相关的文本块输出 1,对不相关的输出 0。
评估(Evaluation)
- RAG一般指标:例如总体答案相关性、答案基础性、忠实度和检索到的上下文相关性。
- 常见的如Ragas,使用真实性和答案相关性来评价生成答案的质量,并使用经典的上下文精准度和召回率来评估 RAG 方案的检索性能。
- LlamaIndex 和评估框架Truelens,他们提出了RAG 三元组评估模式 — 分别是对问题的检索内容相关性、答案的基于性(即大语言模型的答案在多大程度上被提供的上下文的支持)和答案对问题的相关性
- 考虑命中率,还包括了常用的搜索引擎评估指标平均倒数排名 (Mean Reciprocal Rank),以及生成答案的质量指标,如真实性和相关性
- 评估框架:LangChain使用的评估框架 LangSmith可以实现自定义的评估器,还能监控 RAG 管道内的运行,进而增强系统的透明度。如果是LlamaIndex可以使用
rag_evaluator llama pack。
总结
- rag的难点:响应速度
- 未来:小参数的LLM
Reference
[1] 【AI论文学习笔记】链式验证减少了大型语言模型中的幻觉
[2] 学习检索增强生成(RAG)技术,看这篇就够了——热门RAG文章摘译(9篇)
[3] Advanced RAG Techniques: an Illustrated Overview.科学之眼
[4] 再看大模型幻觉问题如何缓解 :Chain-of-Verification-一种基于链式验证思想的自我修正工作解读
[5] MetaAI提出全新验证链框架CoVE,大模型也可以通过“三省吾身”来缓解幻觉现象
[6] 《高级 RAG 技术:图解概述》精华摘译
[7] https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
[8] RA-DIT:Retrieval Augmented Dual Instruction Tuning
[9] 使用Llama index构建多代理 RAG
[10] 前沿重器[40] | 高级RAG技术——博客阅读