摘要:本文提出焦调制网络(FocalNets),其中自注意(SA)完全被焦调制模块取代,用于建模视觉中的令牌交互。焦点调制包括三个组成部分:(1)焦点上下文化,使用深度卷积层堆栈实现,从短范围到长范围对视觉上下文进行编码;(2)门控聚合,选择性地将上下文收集到每个查询令牌的调制器中;(3)元素智能仿射变换,将调制器注入查询中。大量的实验表明,FocalNets具有非凡的可解释性,并且在图像分类、目标检测和分割任务上,以相似的计算成本优于SoTA 的自注意力同类(例如Swin和Focal Transformers)。具体来说,小尺寸和基本尺寸的FocalNets在ImageNet-1K上可以达到82.3%和83.9%的top-1精度。在224224分辨率的ImageNet-22K上进行预训练后,以224224和384*384分辨率进行微调时,top-1准确率分别达到86.5%和87.3%。对于Mask R-CNN的目标检测,使用1倍调度训练的FocalNet基比Swin基高出2.1点,并且已经超过使用3倍调度训练的Swin (49.0 vs 48.5)。对于使用UPerNet进行语义分割[90],FocalNet基础在单尺度上的性能比Swin高出2.4,在多尺度上(50.5 v.s 49.7)优于Swin。使用大型FocalNet和Mask2former,我们实现了ADE20K语义分割的58.5 mIoU和COCO全光分割的57.9 PQ。使用巨大的FocalNet和DINO,我们分别在COCO minival和test-dev上实现了64.3和64.4 mAP,在更大的基于注意力的模型(如Swinv2-G和BEIT-3)上建立了新的SoTA。
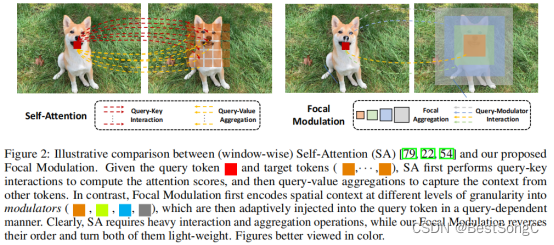
本文介绍了使用Focal Modulation替代自注意力(self-attention)的FocalNet(Focal Modulation Network)网络,新模块具有更好的token交互效果。给定查询令牌和目标令牌,SA首先执行查询键交互以计算注意分数,然后执行查询值聚合以从其他令牌中捕获上下文。相比之下,Focal Modulation首先将不同粒度级别的空间上下文编码为调制器,然后以查询相关的方式自适应地注入查询令牌。显然,SA需要大量的交互和聚合操作,而Focal Modulation颠倒了它们的顺序,使它们都变得轻量级。
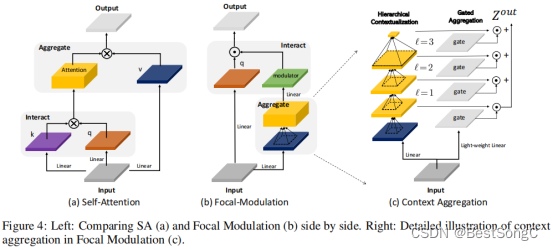
自注意力中,key和query是密集的矩阵相乘,Attention也是和value的密集矩阵乘积。而FocalNet中分别采用Depth-Wise Conv和Point-Wise Conv,计算更轻量化
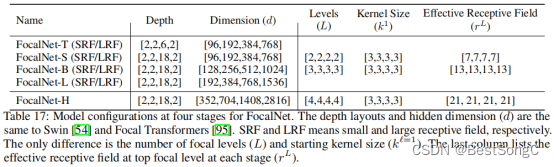
FocalNet模型的变体配置信息如下表:
在YOLOv5项目中添加模型作为Backbone使用的教程:
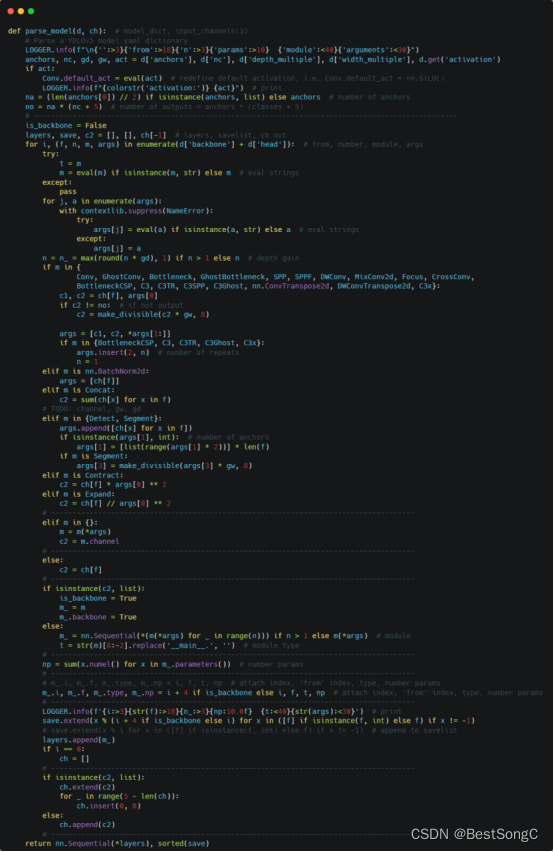
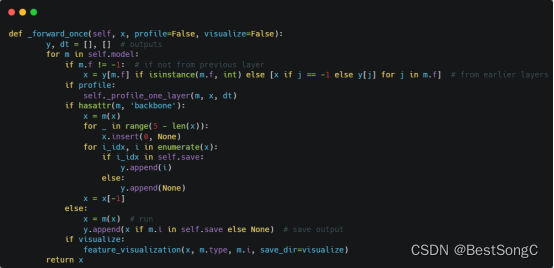
(1)将YOLOv5项目的models/yolo.py修改parse_model函数以及BaseModel的_forward_once函数
(2)在models/backbone(新建)文件下新建FocalNet.py,添加如下的代码:

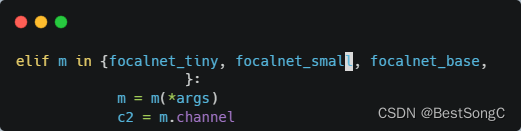
(3)在models/yolo.py导入模型并在parse_model函数中修改如下(先导入文件):
(4)在model下面新建配置文件:yolov5_focalnet.yaml
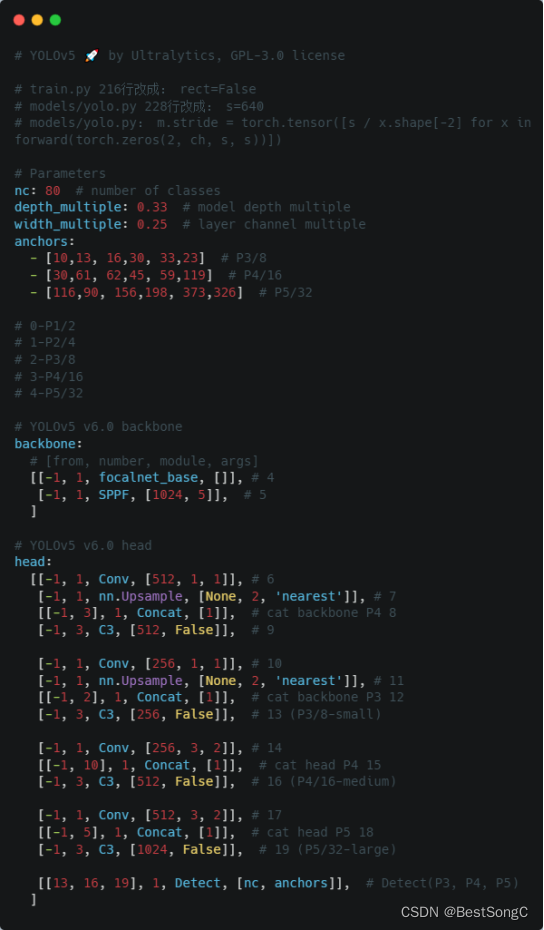
(5)运行验证:在models/yolo.py文件指定–cfg参数为新建的yolov5_focalnet.yaml

![[100个Linux常用指令]-吐血推荐,收藏关注](https://img-blog.csdnimg.cn/direct/543e9cf30b054a89a3593bc0e4eb46c0.png)