目录
🧂1.引入缓存的优势
🥓2.哪些数据适合放入缓存
🌭3.使用redis作为缓存组件
🍿4.redis存在的问题
🧈5.添加本地锁
🥞6.添加分布式锁
🥚7.整合redisson作为分布式锁
🚗🚗🚗1.引入缓存的优势
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而db承担数据落盘工作。
🚗🚗🚗2.哪些数据适合放入缓存
- 即时性、数据—致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)
🚗🚗🚗3.使用redis作为缓存组件
先确保reidis正常启动
3.1配置redis
- 1.引入依赖
<!--redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>- 2.配置reids信息
springredis:port: 6379host: ip地址password: XXX3.2优化查询
之前都是从数据库查询的,现在加入缓存逻辑~
/*** 使用redis缓存*/@Overridepublic Map<String, List<Catalog2Vo>> getCatalogJson() {//1.加入缓存,缓存中存的数据全都是jsonString catalogJson = redisTemplate.opsForValue().get("catalogJson");if (StringUtils.isEmpty(catalogJson)) {//2.缓存中如果没有,再去数据库查找Map<String, List<Catalog2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();//3.将数据库查到的数据,将对象转换为json存放到缓存String s = JSON.toJSONString(catalogJsonFromDB);redisTemplate.opsForValue().set("catalogJson", s);}//4.从缓存中获取,转换为我们指定的类型Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {});return result;}/*** 从数据库查询并封装的分类数据** @return*/public Map<String, List<Catalog2Vo>> getCatalogJsonFromDB() {/*** 优化:将数据库查询的多次变为一次*/List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> leve1Categorys = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catalog2Vo>> parentCid = leve1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {//1.每一个一级分类List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());List<Catalog2Vo> catalog2Vos = null;if (categoryEntities != null) {catalog2Vos = categoryEntities.stream().map(l2 -> {Catalog2Vo vo = new Catalog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());//找二级分类的三级分类List<CategoryEntity> categoryEntities3 = getParent_cid(selectList, l2.getCatId());if (categoryEntities3 != null) {List<Catalog2Vo.Catalog3Vo> collect = categoryEntities3.stream().map(l3 -> {Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());return catalog3Vo;}).collect(Collectors.toList());vo.setCatalog3List(collect);}return vo;}).collect(Collectors.toList());}return catalog2Vos;}));return parentCid;}3.3测试
在本地第一次查询后,查看redis,发现redis已经存储

使用JMeter压测一下

🚗🚗🚗4.redis存在的问题
4.1缓存穿透
- 缓存穿透: 查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义
- 解决方案:null结果缓存,并加入短暂过期时间
4.2缓存雪崩
- 缓存雪崩: 在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,大量请求全部转发到DB, DB瞬时压力过重雪崩。
- 解决方案:原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
4.3缓存击穿
缓存击穿 :对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。
解决方案:枷锁 大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db
🚗🚗🚗5.添加本地锁
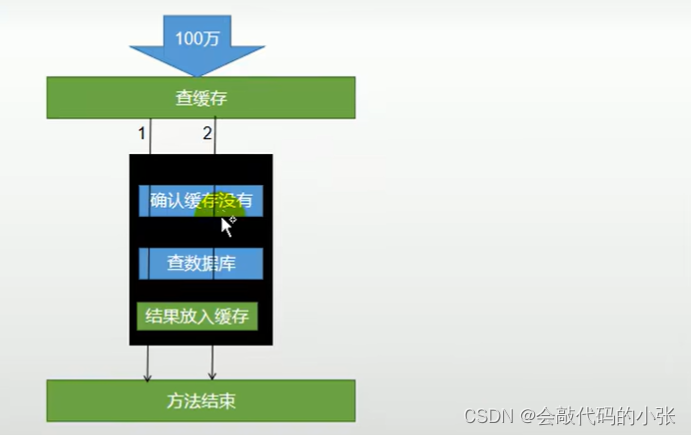
若在缓存redis中没有查到,也去数据库查询,在查询数据库时,添加本地锁,在查之前,再次判断缓存reids中是否有数据,如果有,直接返回,如果没有,在查数据库,在查完数据库后,由于延迟原因,我们查完数据库时,将数据存放到缓存中,然后在释放锁
/*** 使用redis缓存*/@Overridepublic Map<String, List<Catalog2Vo>> getCatalogJson() {//1.使用redis缓存,存储为json对象String catalogJson = redisTemplate.opsForValue().get("catalogJson");//2.判断缓存中是否有if (StringUtils.isEmpty(catalogJson)) {System.out.println("缓存没有命中~查询数据库...");//3.如果缓存中没有,从数据库Map<String, List<Catalog2Vo>> catalogJsonFromDB = getCatalogJsonFromDB();return catalogJsonFromDB;}System.out.println("缓存命中....直接返回");//5.如果缓存中有,转换为我们需要的类型Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {});return result;}/*** 从数据库查询并封装的分类数据** @return*/public Map<String, List<Catalog2Vo>> getCatalogJsonFromDB() {/*** 优化:将数据库查询的多次变为一次*///TODO 本地锁,在分布式下,必须使用分布式锁//加锁,防止缓存击穿,使用同一把锁synchronized (this) {//加所以后,我们还要去缓存中确定一次,如果缓存中没有,才继续查数据库String catalogJson = redisTemplate.opsForValue().get("catalogJson");if (!StringUtils.isEmpty(catalogJson)) {//如果缓存中有,从缓存中获取Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {});return result;}System.out.println("查询了数据库~");List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> leve1Categorys = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catalog2Vo>> parentCid = leve1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {//1.每一个一级分类List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());List<Catalog2Vo> catalog2Vos = null;if (categoryEntities != null) {catalog2Vos = categoryEntities.stream().map(l2 -> {Catalog2Vo vo = new Catalog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());//找二级分类的三级分类List<CategoryEntity> categoryEntities3 = getParent_cid(selectList, l2.getCatId());if (categoryEntities3 != null) {List<Catalog2Vo.Catalog3Vo> collect = categoryEntities3.stream().map(l3 -> {Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());return catalog3Vo;}).collect(Collectors.toList());vo.setCatalog3List(collect);}return vo;}).collect(Collectors.toList());}return catalog2Vos;}));//4.将从数据库中获取的数据,转换为Json存储到redisString s = JSON.toJSONString(parentCid);//设置缓存时间,方式雪崩redisTemplate.opsForValue().set("catalogJson", s, 1, TimeUnit.DAYS);return parentCid;}}🚗🚗🚗6.添加分布式锁
使用分布式锁 步骤
- 1.先去redis中设置一个key,为了保持原子性,同时设置过期时间
- 2.判断是否设置成功,成功则继续业务操作,失败则自选再次获取
- 3.执行业务之后,需要删除key释放锁,为了保持原子性,使用lua脚本
/*** 使用redis缓存*/@Overridepublic Map<String, List<Catalog2Vo>> getCatalogJson() {//1.使用redis缓存,存储为json对象String catalogJson = redisTemplate.opsForValue().get("catalogJson");//2.判断缓存中是否有if (StringUtils.isEmpty(catalogJson)) {System.out.println("缓存没有命中~查询数据库...");//3.如果缓存中没有,从数据库Map<String, List<Catalog2Vo>> catalogJsonFromDB = getCatalogJsonFromDBWithRedisLock();return catalogJsonFromDB;}System.out.println("缓存命中....直接返回");//5.如果缓存中有,转换为我们需要的类型Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {});return result;}/*** 从数据库中获取数据,使用分布所锁** @return*/public Map<String, List<Catalog2Vo>> getCatalogJsonFromDBWithRedisLock() {//1.占分布式锁,去redis占位String uuid = UUID.randomUUID().toString();//2.设置过期时间,必须和加锁同步Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);if (lock) {System.out.println("获取分布式锁成功..." + redisTemplate.opsForValue().get("lock"));//加锁成功...执行业务Map<String, List<Catalog2Vo>> dataFromDb;try {dataFromDb = getDataFromDb();} finally {String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";//删除锁,原子性Long lock1 = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);}return getDataFromDb();} else {//加锁失败...重试//休眠100毫秒try {Thread.sleep(2000);} catch (InterruptedException e) {}return getCatalogJsonFromDBWithRedisLock();//自旋方式}}/*** 提起方法,从数据库中获取** @return*/private Map<String, List<Catalog2Vo>> getDataFromDb() {//加所以后,我们还要去缓存中确定一次,如果缓存中没有,才继续查数据库String catalogJson = redisTemplate.opsForValue().get("catalogJson");if (!StringUtils.isEmpty(catalogJson)) {//如果缓存中有,从缓存中获取Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {});return result;}System.out.println("查询了数据库~");List<CategoryEntity> selectList = baseMapper.selectList(null);//1.查出所有1级分类List<CategoryEntity> leve1Categorys = getParent_cid(selectList, 0L);//2.封装数据Map<String, List<Catalog2Vo>> parentCid = leve1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {//1.每一个一级分类List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());List<Catalog2Vo> catalog2Vos = null;if (categoryEntities != null) {catalog2Vos = categoryEntities.stream().map(l2 -> {Catalog2Vo vo = new Catalog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());//找二级分类的三级分类List<CategoryEntity> categoryEntities3 = getParent_cid(selectList, l2.getCatId());if (categoryEntities3 != null) {List<Catalog2Vo.Catalog3Vo> collect = categoryEntities3.stream().map(l3 -> {Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());return catalog3Vo;}).collect(Collectors.toList());vo.setCatalog3List(collect);}return vo;}).collect(Collectors.toList());}return catalog2Vos;}));//4.将从数据库中获取的数据,转换为Json存储到redisString s = JSON.toJSONString(parentCid);//设置缓存时间,方式雪崩redisTemplate.opsForValue().set("catalogJson", s, 1, TimeUnit.DAYS);return parentCid;}
🚗🚗🚗7.整合redisson作为分布式锁
7.1引入依赖
<!--redisson作为所有分布式锁--><dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.12.0</version></dependency>7.2程序化配置
在配置地址时,一定要添加reds://
@Configuration
public class MyRedissonConfig {@Bean(destroyMethod = "shutdown")public RedissonClient redissonClient() throws IOException {//1.创建配置Config config = new Config();config.useSingleServer().setAddress("redis://192.168.20.130:6379");//2.根据config创建redisson实例RedissonClient redissonClient = Redisson.create(config);return redissonClient;}
}7.3实例解析
- 1.锁的自动续期,如果业务超长,运行期间自动给锁续上新的30秒,不用担心业务超长,所自动过期被删除掉
- 2.加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30秒后自动删除
@AutowiredRedissonClient redissonClient;@ResponseBody@GetMapping("/hello")public String hello() {//1.设置redis的key获取一把锁,只要名字相同,就是同一把锁RLock lock = redissonClient.getLock("my-lock");//2.手动枷锁lock.lock();//阻塞式等待,默认30秒try {//3.执行业务System.out.println("枷锁成功!" + Thread.currentThread().getName());//4.模拟业务消耗时间Thread.sleep(20000);} catch (Exception e) {} finally {//3.释放锁System.out.println("释放锁~"+Thread.currentThread().getName());lock.unlock();//不删除,默认30秒后过期,自动删除}return "hello";}
- 3.如果我们传递了锁的超时时间,就发送给redis执行脚本,进行占锁,默认超时就是我们指定的时间
- 4.如果未指定锁的超时时间,就使用30*1000【LockWatchingTimeOut看门狗默认时间】
- 只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔(【LockWatchingTimeOut看门狗默认时间】/3)折磨长时间自动续期;
7.4读写锁
- 1.保证一定能读到最新数据,修改期间,写锁是一个排他锁,读锁是一个共享锁
- 2.读+读:相当于并发,在redis中记录好,都会读取成功
- 3.写+读:等待写锁释放
- 4.写+写:阻塞方式
- 5.读+写:有读锁,写也需要等待
@GetMapping("/write")@ResponseBodypublic String write() {RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("readWrite-lock");String word = "";RLock rLock = readWriteLock.writeLock();try {//该数据加写锁,读数据加读锁rLock.lock();word = UUID.randomUUID().toString();Thread.sleep(3000);redisTemplate.opsForValue().set("writeValue", word);} catch (InterruptedException e) {e.printStackTrace();} finally {rLock.unlock();}return word;}/*** 读写锁* @return*/@GetMapping("/read")@ResponseBodypublic String read() {String word = "";RReadWriteLock readWriteLock = redissonClient.getReadWriteLock("readWrite-lock");//加读锁RLock rLock = readWriteLock.readLock();rLock.lock();try {word = redisTemplate.opsForValue().get("writeValue");} catch (Exception e) {e.printStackTrace();}finally {rLock.unlock();}return word;}